SPL:Reading, writing, and parsing of unstructured text
A text file can be structured or unstructured, for instance an article, a log, or a payroll. Unstructured text can not be applied directly to operations like SQL, but rather to more basic word-processing operations.
Let’s sort the text files of different contents and analyze the relevant calculations of different contents.
SPL opens a text file with the file function, which can be read as a sequence or cursor, and is then ready for further calculation. When the file data is small enough to be fully loaded into memory, the read function reads the data into a string or sequence; when the file data is too big to be fully loaded into memory, the cursor function reads the data into a cursor.
What follows is some methods to read them.
There is now one file named novel.txt, the following expression reads the entire file as a text string:
=file("novel.txt").read()
The file function opens the specified file, which can take either an absolute path or a relative path. For the latter, it is relative to the main path of esProc environment. The read function is then used to read the file contents as a big string and return.
The file function defaults to use the operating system’s default charset, and if the text needs a specified charset, we can use:
=file("novel.txt":"UTF-8").read()
That is to separate the file name at the back with a colon and add the name of the specified charset.
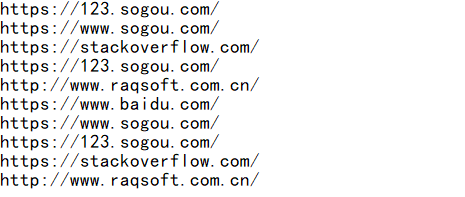
This is the kind of content separated by line, and the method to read each line as a sequence member is as follows:
=file("urls.txt").read@n()
The read function uses the option @n to put each row of data into a sequence member, returning the different value than that in Section 1.1, which is a sequence object. The red box in the variable viewing panel is Member, indicating that the current object is a sequence, as shown below:
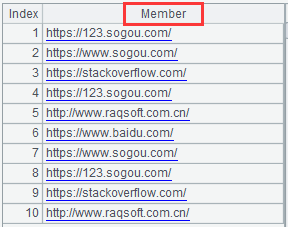
If each member is a date or a numeric value described by a string, the corresponding member can be parsed to the corresponding type of data with the option @v.
The example data are as follow:

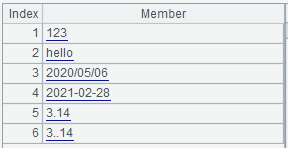
When reading directly with =file("data.txt").read@n(), each data defaults to a string:
After reading with the option @v of the =file("data.txt").read@nv() expression, we can see that the values that can be parsed as data become the corresponding types of data:
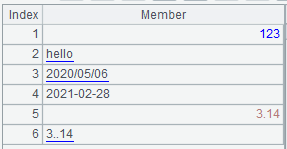
In the numeric value viewing panel, the strings are underlined to distinguish types. Note, however, that the date format needs to be set in the application environment, and only date written in the same format of the environment settings can be parsed correctly. For example, 2020/05/06 in the image above can not be parsed to a date type because it is not in the same format as the environment.
For large files, use the cursor function to read, and read the data in Section 1.2 with the method of cursor is as follows:
=file("urls.txt").cursor@s().fetch(10)
Cursor will be read as a table sequence with multiple columns by default. In the example above, each row corresponds to a member without splitting, then use the option @s to specify not to split by field and directly return the table sequence containing each member. The red box in the picture is the default field name that generates the table sequence, as shown below:
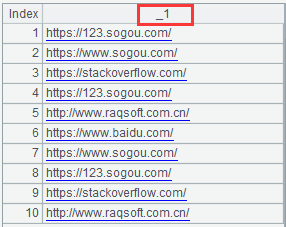
If we don’t want to return a table sequence, but a sequence like Section1.2, we need to go with the option @i, as follows:
=file("urls.txt").cursor@si().fetch(10)
Take a look at some stock index data:
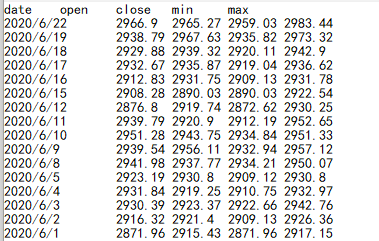
The data is multi-column data separated by Tab values, and the default way of the cursor function is to return a table sequence of multiple columns, so use the expression of no option:
=file("d:/stock.txt").cursor().fetch(10)
The result is already a table sequence with multiple rows and columns:
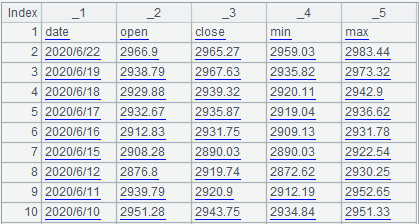
For this kind of multi-column data, use the option @s if we don’t want to split it into a table sequence:
=file("d:/stock.txt").cursor@s().fetch(10)
The result at this point is a table sequence containing only one column, with the default field name circled in red:
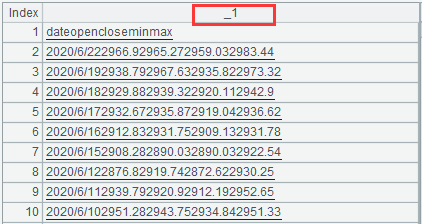
if there is only one column of data in the current table sequence, the option @i can be used to return the result as a sequence. When the table sequence of multiple columns is already imported, the option @i alone fails to enable a sequence return. The option @i is usually used with the option @s to take effect at this point.
When writing the calculated strings and sequences in SPL to a text file, the file function is used to open the file for writing, and then the value is written by the write function. For the big data in cursor, fetch batches data in loop and write with the method of appending.
Here are some examples of writing.
A text string can be directly written to a file with the write function, as shown in the example below:
| A | B | |
|---|---|---|
| 1 | William Shakespeare (baptised 26 April 1564; died 23 April 1616) was an English poet and playwright, widely regarded as the greatest writer in the English language and the world's pre-eminent dramatist. | A paragraph of text |
| 2 | =file("d:/paragraph.txt").write(A1) | Write the whole paragraph in A1 to paragraph.txt |
The result of writing:

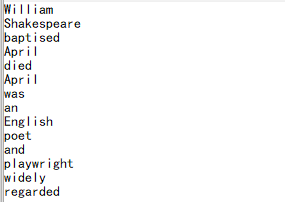
When the data to be written is a sequence object, the write function writes each member in a line. Slightly change the example in Section 2.1 as follows:
| A | B | |
|---|---|---|
| 1 | William Shakespeare (baptised 26 April 1564; died 23 April 1616) was an English poet and playwright, widely regarded as the greatest writer in the English language and the world's pre-eminent dramatist. | A paragraph of text |
| 2 | =A1.words() | split the text in A1 into a word sequence |
| 3 | =file("d:/words.txt").write(A2) | write the word sequence in A2 to the file words.txt |
We can see that the usage of the write function has no difference from Section 2.1, where A2 is a sequence of strings, and the write function automatically identifies it based on the objects to be written, if it is a sequence, each member will be written as a line. Compare the contents of the file written by line:
Note that when written by line, the newline character defaults to the newline character of the operating system. If we force a windows newline character (including carriage return and newline, also known as \r\n), we need to use the option @w.
Suppose the urls.txt file above is very large (which can not read in memory at a time), now to copy the file, we need to use the cursor to read the source file, and use the appending method, at this point the option @a of the write function is needed. Example code for copying large files:
| A | B | |
|---|---|---|
| 1 | =file("d:/urls.txt").cursor@si() | open the source file as a cursor and return the contents as a sequence using the si option |
| 2 | for A1,1000 | traverse the cursor and fetch data, takes 1000 lines every time until all are fetched |
| 3 | =file("d:/urlCopy.txt").write@a(A2) |
B3 uses the write@a function to append the result of each batch to urlCopy.txt.
The content of the text takes many forms and can be processed in a variety of ways. Here are some of the most common text processing methods.
To search for the text content, the grep command is the most common used, for example:
grep magic /usr/src finds contents include magic in all text files of the /usr/src directory.
SPL has rich and ready-to-use functions. It takes just two lines of code to spot something like grep:
| A | B | |
|---|---|---|
| 1 | =directory@ps(path+"/*.txt") | list all the text files (including subdirectories) in the search directory |
| 2 | =A1.run(file( |
read the contents of each file, and compare the key words line by line, output the corresponding information |
The parameters path and key are used in the above table, which needs to be defined in the script file in advance and enter them when executing.
Additional notes:
A2 run is loop execution function, traversing all the files in the root directory. Then there’s run, which is a traversal search for the contents of the file.
The logic of output is simple: once found, print out the information like row content, row number, and so on. Note that in SPL, when the integer row number is concatenated with the string, use/ instead of + .
The pos function is the function of searching.
The replace function provided by SPL enables word substitution of text strings. The replaced contents needs to be written again, so perform reading the content, replacing, and writing respectively:
| A | B | C | |
|---|---|---|---|
| 1 | =directory@ps(path+"/*.txt") | list all text files (including subdirectories) in the path directory | |
| 2 | for A1 | =file(A2).read@n() | loop through all the files in the directory |
| 3 | =B2.run( |
the contents each file are read and performed replacement | |
| 4 | =file(A2).write(B3) | write the replaced content to the original file |
To count the words, a sentence needs to be split into individual words, and SPL provides the words function for word splitting. The code is as follows:
| A | B | |
|---|---|---|
| 1 | =file("novel.txt").read() | read the text contents of the given file |
| 2 | =A1.words() | split contents into word sequences |
| 3 | =A2.groups(lower( |
turn the words into lowercase, group and count them |
Similar to word counting, the text string can be split directly into individual letters using the split function. The code is as follows:
| A | B | |
|---|---|---|
| 1 | =file("novel.txt").read() | read the text contents of the given file |
| 2 | =A1.split() | split contents into letter sequences |
| 3 | =A2.groups( |
group the characters and count |
The text in Section 1.2 is a collection of duplicate urls, which can be easily deleted by the group function. The code is as follows:
| A | B | |
|---|---|---|
| 1 | =file("d:/urls.txt") | open the specified file |
| 2 | =A1.read@n() | read the contents of the file as a sequence by line |
| 3 | =A2.group@1() | group by sequence members |
| 4 | =A1.write(A3) | get all the row sequences |
The group function in A3 provides plenty of options, using the option @1 to remove redundant url strings.
Some text content is a little bit complex, containing both structured content and a lot of unstructured information. At this point we need to remove the unstructured information and parse out the structured data, so that such files (also known as semi-structured files) can also be calculated in SQL.
The following is a partial screenshot of a software log file (QQLive.log):

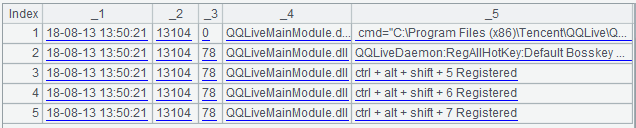
After removing the extra brackets and characters, each line can be parsed into a fixed field record. To get rid of the extra characters, we can use the regular expression and the regex function in SPL, which looks as follows:
| A | B | |
|---|---|---|
| 1 | [(.*)][(.*)]-[(.*)ms][(.*)](.*) | define the regular expression |
| 2 | =file("D:/QQLive.log").read@n() | open the log file and read the contents as a sequence by line |
| 3 | =A2.regex(A1) | use the sequence’s regular parsing function regex to split the fields out. |
The results of parsing are as follows:
The contents of the log file are various. Take the following data as an example, since the debugging information is not fixed, we need to read an unfixed number of lines to parse a record:
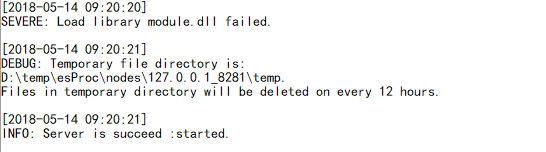
Parsing the same record can be defined by left bracket, where the like function is used as a grouping criterion so that multiple lines of the same record can be grouped into the same group. The code is as follows:
| A | B | |
|---|---|---|
| 1 | =file("D:/raq.log").read@n() | open the log file and read the contents as a sequence by line |
| 2 | =A1.select(~!="") | remove the empty lines |
| 3 | =A2.group@i(like(~,"[*")).(~.concat()) | group by record content, and concatenate group members to strings |
| 4 | [(.*)]([A-Z]+):(.*) | define regular expression |
| 5 | =A3.regex(A4) | perform regular parsing |
The group function has many options, where the option @i allows subsequent lines of the same record to be assigned to the current group.
The results of parsing are as follows:

The following data, in which fixed number of lines is parsed to records, can be filled directly with the record function.
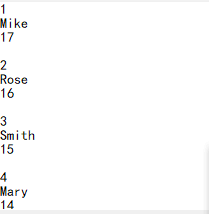
The code is as follows:
| A | B | |
|---|---|---|
| 1 | =file("D:\student.txt") | open the student file |
| 2 | =A1.read@n() | read the data as a sequence by line |
| 3 | =A2.select(~!="") | remove the empty lines |
| 4 | =create(ID,Name,Age) | create table structure |
| 5 | =A4.record(A3) | fill the table structure with the A3 sequence |
The results of parsing are as follows:

The following content of the mail is not fixed, so the non-fixed data lines need to be parsed to a mail record:
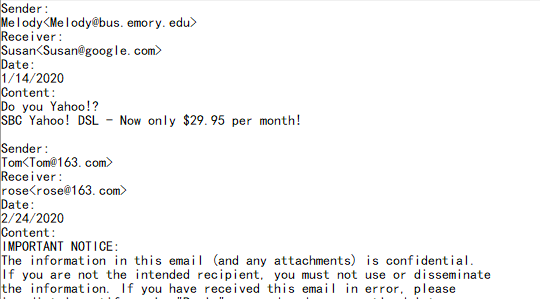
| A | B | |
|---|---|---|
| 1 | =file("D:\mail.txt") | open the mail file |
| 2 | =A1.read@n().select(~!="") | import the sequence and remove the empty lines |
| 3 | =A2.group@i(like(~,"Sender:*")) | each Sender: initial and subsequent lines as a group |
| 4 | =A3.new(~(2):Sender,~(4):Receiver,~(6):Date,~.to(8,).concat():Content) | retrieve the record value, concatenate the main body, and create a new structure table |
Similar to fixed number of lines parsing, mails need to be grouped together using the option @i of the group function. Then on the basis that the main body of the mails in each group starts at the 8th line, use the to function to set all mail bodies after 8th line to the Content field. The code is as follows:
The result is shown as follows:

The following is a textual customer quote sheet item.txt, as shown in the picture:
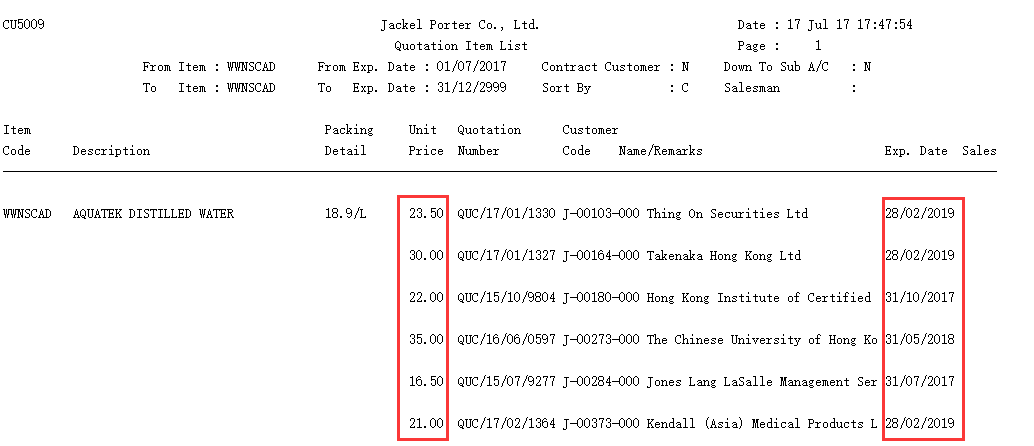
The lines before the horizontal line are complex table headers, and each line after that is a quote record with blank lines between them. What the picture shows are just a table header and quotation record area, which is repeated over and over again in a text file. The red boxes are field column Unit Price and Exp. Date respectively, with the Quotation Number, Customer Code, Customer Name field columns in the middle, all separated by spaces.
Observe and find patterns of the text as follows:
(1) lines of less than 136 characters have no valid information and can be skipped
(2) the required data is in columns from 59 to 136 per line
(3) split the information portion of each line by taking spaces as delimiters. If the first split value is numeric, this line is the quotation record; otherwise, skip it. The first split value is the Unit Price column, the second is the Quotation Number column, the third is the Customer Code column, the last one is the Contract Expiry Date column, and the fourth to penultimate columns connected by spaces is the Customer Name column.
After finding out the patterns, the code in SPL is as follows:
| A | B | C | |
|---|---|---|---|
| 1 | =create(Customer_Code,Customer_Name,Quotation_No,Unit_Price,Contract_Expiry_Date) | ||
| 2 | =file("D:/item.txt").read@n() | ||
| 3 | for A2 | if len(A3)<136 | next |
| 4 | =right(left(A3,136),-58) | =B4.split@tp() | |
| 5 | if !ifnumber(C4(1)) | next | |
| 6 | =C4.m(4:C4.len()-1).concat("") | ||
| 7 | >A1.insert(0,C4(3),B6,C4(2),C4(1),C4(C4.len())) | ||
| 8 | =file("D:/item.xlsx").xlsexport@t(A1) |
Notes to the code:
A1 create the target data set
A 2 open the quote sheet file item.txt, read the contents of the file, the option @n means that each line is read as a string
A3 loop through each line of the text, apply the rules found earlier in B3C3. If the line is less than 136, it is skipped
B4 retrieve the data from the 59 to 136 columns in this line
C4 split the data retrieved from B4 by space characters, with option t to remove the spaces at both ends, and option p to parse the split string into its corresponding data type
B5C5 if the first value that C4 splits is not a numeric type, this line is skipped
B6 concatenate the values from the fourth to penultimate split in C4 with spaces
B7 insert the third value of C4, B6, the second value of C4, the first value, and the last value into the new record of A1 in order
A8 save all the retrieved data to the Excel file item.xlsx