Drawbacks of Using Stored Procedures to Compute Data
SQL focuses on structured data computations, yet it lacks procedural control syntax for handling procedure-oriented computations. The SQL-based Stored procedure (SP) is created to make up for this absence by supporting the much-needed syntax. SP also features a series of merits, including code encapsulation, injection prevention and dynamic syntax. In practical use, however, its demerits are unignorable.
SP provides services for the front-end applications. They, in theory, should be packaged to form a functional ensemble. SP, in fact, gets tightly coupled with the database and is physically separated from the front-end application, making it impossible to apply a same technical approach on them. Both SP and the corresponding front-end application targeted at a same functionality should be maintained if necessary, but this is made difficult by their physical separation and even harder by the use of different techniques.
SP’s high coupling with the database and separation from the front-end application make it liable to get into a messy share by multiple front-end applications. The invocations will become more and more tangled as time goes on. If the algorithm in a certain application is changed, the administrator, facing such a chaotic jumble of shared invocations, chooses to create a new SP rather than take the risk of modifying the existing one. As there is a growing number of SPs, the tangle becomes more and more terrible, and then unmanageable.
There is not a SP standard as ANSI 2003. Database vendors implement the library as individual as possible, which results in diverse SPL syntax that are difficult to migrate across database products. High development costs are needed to achieve migration, which becomes the unbearable weight of a project. Even a rewrite on the target database is cheaper. The SPL migration difficulty is genetic and cannot be addressed through management improvement measures.
Unlike the tree-structured file system, the SP directory is flat. It is not a big problem when there are only a few scripts, but chaos happens when there are many, particularly when SPs for multiple projects, for different modules under the same project, and of different years or different versions for the same module are mixedly stored under one directory. Differentiation is hard. The only way out is to upgrade management by naming scripts by project, module, year, and version.
SPs of query analysis need frequent modification of code. Each modification needs to be submitted to the database administrator for compilation and publishment thanks to SP’s tight coupling with the database. This adds a lot of extra work to the database administrator. The usual alternative is to grant programmers certain permissions, like the advanced permission or, at least, the privilege of creating SP, to avoid putting more workload on database administrators. It is convenient but poses potential security risks. The SP compilation privilege is too important to afford abuse. One misuse may accidentally delete related data, even data in the other applications.
Though SP includes the logic-control syntax on basis of SQL syntax, it does not make effort to enhance SQL’s structured data computing ability. The SQL headaches, such as order-based calculations, post-grouping calculations, multilayer joins, and mixed computations, are just passed onto SP as they are. Moreover, SP’s debugging functionality is far from being practical though picked up a little.
As SP has so many weaknesses, some are fatal, is there any way to overcome them?
An external computing engine is the solution.
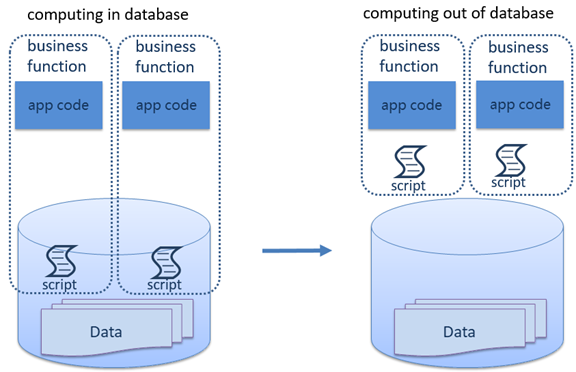
An external computing engine should meet certain standards. Independent of database, integration-friendly and interpreted execution reduce coupling and increase security. Scripts stored outside database make migration easy. The tree-structured script storage make management convenient. And rich library functions and easy to use debugging functionality let users write code easily and smoothly.
esProc SPL is the right external computing engine. The tool is stand-alone, integration-friendly and supports interpretedly executed, database-independent scripts. It stores scripts in tree-structured directories and boasts a wealth of library functions and easy to use debugging functionality. See https://www.scudata.com/html/java-computing-layer.html to learn more esProc SPL.