Data warehouse running on file system
We know that the data warehouse appeared later than the database. When TP database could not meet the growing data analysis needs, people built a separate database to separate the AP business, this database is called the data warehouse (logical concept), and then came the dedicated data warehouse products to serve AP business. Since the data warehouse itself is technically a database, it inherits many characteristics of database, such as metadata and data constraints, which makes the transition from TP database to AP data warehouse relatively smooth.
However, the goals of TP and AP are not the same, for example, some useful characteristics in TP business are useless or even disadvantageous in AP business, such as the closeness.
The so-called closeness means that the data to be calculated and processed by the database must be loaded into database in advance, and managed centrally by the database, and it specifies what data needs to be loaded into the database.
Then, what problems does closeness pose?
A typical problem is that ETL is often done as ELT or even LET. The E and T steps in ETL are actually two kinds of calculations. If the computing ability is enclosed within the database, we have to load the data into the database first before we can perform calculation, as we cannot compute the data outside the database. However, the raw data in the ETL process is often not in the database, or at least not in the data warehouse, and may exist in multiple databases. In short, an action of loading data into one database is a must before computing, which is time-consuming and labor-intensive.
Diverse data sources are becoming increasingly common in today’s applications, often including data from external services. It is very cumbersome to import these data into the database in order to calculate them. The efficiency of temporarily importing data is low (because of the high IO cost of the database), which may not be able to keep up with the access requirements, while scheduled batch importing is difficult to obtain the latest data, which also affects the real-time of calculation result.
The disadvantages of closeness go beyond this.
Closeness also makes real-time data computation difficult. There are many types of data sources in today’s applications, and each data source plays a specific role in a certain scenario. However, for OLAP business, it is often necessary to count global data, which involves computing across multiple data sources. If we have to import data of other data sources before every computing, it will be very inefficient, and will also make it impossible to obtain real-time data, because this requires real-time calculation across data sources, but the current data warehouses do not have this ability.
Another problem with closedness is that it imposes constraints on the data, only allowing data that meets the requirements to be loaded into the database. While this can ensure data quality to some extent, on the other hand, it will make it difficult for non-compliant data to be included in calculation, which is not beneficial to analyze certain raw data as well as build a data lake.
A relevant characteristic is the wholeness. The data in the database is logically a whole and cannot be split. If there are too many kinds of data (data tables), it will cause problems such as bloated metadata, difficult O&M and management, and high coupling. In practice, the number of tables in the data warehouse is usually large, sometimes as high as tens of thousands. Why does this happen?
Most of these tables are the intermediate tables processed in advance after the adoption of the method of trading space for time to improve query efficiency. Once such tables are generated, it is difficult to delete(deletion will affect other applications because they are shared between multiple applications). Eventually tens of thousands of intermediate tables are accumulated.
Since the intermediate table will consume the computing resources of database to update data regularly, the resource consumption will increase as the number of intermediate tables grows. Many of these tables cannot be deleted even if they expire, wasting resources in vain. The storage and computing pressure will cause the data warehouse to face expansion, resulting in an increase in cost.
Sharing the intermediatetable between multiple applications will cause tight coupling between applications, which is mutually causal with the increasing number of intermediate tables. Too high coupling will result in difficulty in application expansion and inconvenience in operation and maintenance.
**Splitting database and splitting table** are also very common methods for data warehouse with a large amount of data. A large number of split tables will further increase the number of tables, while splitting database will face the problem of cross-database calculation.
We know that the structure of database is linear, and too many tables will make it difficult to manage and complicated to operate and maintain. Although the database is a schema-assisted database, it can only be split into two layers at most, which is not comparable to the convenience of many tree-like structures (e.g., file system).
Judging from the name of “data warehouse” alone, it seems that its main function is storage, but actually the calculation. It makes no sense to just store data, and only by using them can their value be exerted. The closeness of the database is equivalent to a “city wall”, we have to import and export the data through the “city gate” of database, and some checks need to be carried out during the import/export process. For OLTP business, these checks are necessary in order to ensure consistency, though it will loss the IO efficiency of database. For computing-based businesses such as OLAP, however, such checks make little sense, and are just a waste of time and resources. Fortunately, modern cities (data warehouses) do not need walls.
If we adopt an open storage system to build data warehouse, such as storing the data directly in files, many of the above problems can be effectively solved.
Since there are no restrictions on file storage, the “city wall” is eliminated, and any type of data can be imported (or even without the concept of “data importing”). In this way, the data can be retained “as is”, and it is more in line with the original intention of data lake. In addition, files are more flexible and efficient in use because file’s tree-like directory structure allows us to manage data tables (files) by category, which won’t cause coupling problem between applications, and also makes it very convenient to manage and use, no matter how many tables there are.
Moreover, the cost of file storage is very low. Low cost is a key factor that cannot be ignored in the construction of big data.
Of course, files are less capable of modifying data than database, but since the historical data in data warehouse usually does not need to be modified, it is usually worthwhile to sacrifice the less costly data update (which means overwriting) ability in exchange for higher computing efficiency (utilizing the code compression and columnar storage mechanisms). Therefore, the file-based computing performance will be higher and, the file system has higher IO performance than database.
Another advantage of file storage is that it is easy to implement the separation between storage and computation. Specifically, the database storage often bypasses the file system to directly access hard disk. To adapt it to implement separation between storage and computation, using the NFS (Network File System) storage and cloud object storage, reconstructing from the base-level is necessary, it is a complex task and will lead to a lot of risks. In contrast, the file storage naturally supports the separation between storage and computation (professional storage can ensure data security, and professional computing engine can ensure performance), and it is easier to implement cloud storage.
Although the file storage does have many advantages, it lacks a key ability: computing. As mentioned earlier, just storing data does not make sense, but using them. While file storage works well in every aspect, the lack of computing ability reaches nothing for the goal of data warehouse.
With the assistance of esProc SPL, files are given computing ability, thereby implementing an open, flexible and efficient file-based data warehouse.
esProc is a computing engine specifically for structured data, and has the same complete computing ability as database. Unlike database, however, esProc calculates directly based on files, supports many file formats, such as CSV, Excel and JSON, and offers a proprietary high-performance file format. Besides, esProc has good openness, it supports not only file-type data sources but multiple other types of data sources (RDB/NoSQL/RESTful), and meanwhile, it has the cross-source mixed computing ability.
As we’ve mentioned above, storing the data in files can reduce cost, make it more flexible in use and easier in management. Moreover, writing/reading data directly on files (system) can get much higher efficiency than database. By calculating directly on files, esProc can implement all functionalities (storage + computation) of a data warehouse.However, the direct use of open file formats, such as text, is still inefficient. To solve this problem, esProc designs a proprietary binary file format, and offers many mechanisms to fully ensure computing performance, such as compression, columnar storage, ordering, and parallel segmentation.
Based on the high-performance file storage, esProc also designs many high-performance algorithms (it should be noted that some algorithms work only with the aid of storage), among which the ordered cursor, multipurpose traversal, foreign key pointer, one-side partitioning, double increment segmentation and parallel computing algorithms are the original inventions of SPL.
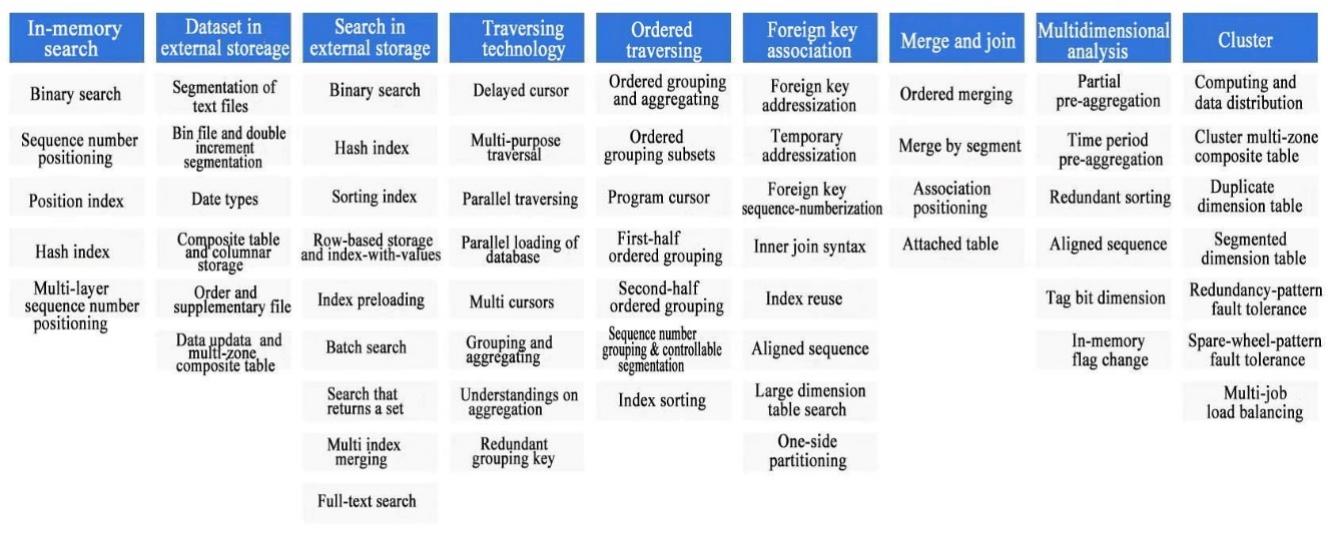
This figure shows part of SPL high-performance algorithms
High-performance file storage as well as the high-performance algorithms give esProc the ability to improve the performance by order of magnitude. For example, in an e-commerce funnel analysis scenario for calculating user churn rate, the user did not get result after **3 minutes** running on Snowflake's Medium server (equivalent to 4*8=32 cores), while the user ran the SPL code on a 12-core, 1.7G low-end server and got the result in less than **10 seconds**. Another example, in a computing scenario of NAOC on clustering the celestial bodies, esProc's performance is **2000 times** faster than other implementation way (distributed database). Due to its good openness, esProc **naturally supports cross-source computing**.
esProc, as an open computing engine, supports dozens of data sources, and any type of data source can participate in computing as long as it is accessible to esProc, the only difference is the access performance (maximum efficiency can be got using esProc's own binary file format). In addition, not only can esProc access a separate data source, but it can also perform mixed computingof multiple data sources, i.e., cross-source computing. Many problems caused by requiring previous ETL to implement cross-source computing for database can be completely solved in esProc. esProc provides stronger data real-time, and can fully retain respective advantage of various data sources.
With the support of file storage, high-performance algorithms and cross-source computing ability, it is easy for esProc to implement HTAP. HTAP requirements are essentially the result of the inability to perform real-time query after a large amount of data is stored in different databases. esProc supports mixed computing on diverse data sources and has a natural ability to perform real-time analysis. For more information, refer to: HTAP database cannot handle HTAP requirements
Under this mechanism, it is also easy to implement a real Lakehouse. Lakehouse requires both the storing and computing abilities, in other words, it requires the ability to fully retain raw data as well as the strong computing ability, only in this way can the data value be brought into full play. But, implementing Lakehouse on database will face an awkward situation that can only calculate not store (House only, no Lake), which is caused by its closeness and strong constraints. In contrast, file storage is naturally a lake where we can store the non-conforming data, and with the help of esProc with strong computing ability, any type of data can be computed. If we want to achieve high performance, we can organize the data. In this way, it naturally implements Lakehouse that can be gradually perfected. For more information, refer to: The current Lakehouse is like a false propositionThe application goal of data warehouse is quite different from that of database. In this case, constructing data warehouse based on database will inevitably cause a lot of problems. For example, the closeness mentioned in this article is like a city wall lying across the inside and outside of computing system, which not only wastes the time and space, but makes it difficult to meet the requirements of the new generation of applications (such as real-time data, separation of storage and computation). In contrast, the file-based data warehouse is more open, and more flexible and efficient as a result of eliminating the “city wall”. And, with the aid of esProc’s strong computing ability, the file-based data warehouse can achieve more efficient computing while being easy to use, which is what a modern data warehouse should be.