Data storing using file or database, which is more suitable?
It is common to use the database to store the data for the reason that the database not only provides a variety of storage strategies but also meets the requirements of data consistency. Moreover, it is convenient to do data calculation based on the database. However, this storage way has some disadvantages, and it is not the best option in some scenarios. Another way to store the data is the file. The file system is more open and flexible, but the file itself has no computing power and cannot ensure the data consistency; nevertheless, using files to store data is more suitable in some scenarios.
Let's compare the two technologies in the following aspects to see which technology is more suitable for use in which scenarios?
The purpose of data storing is to use the data to create value. Reading and writing here refers to the process that the application needs to take data out from, or write data into the file system or database when using the data. We know that the data of database needs to be exported through the database’s access driver, usually JDBC and ODBC, and the exporting efficiency is closely related to the database driver. Actual test shows that it takes 518 seconds for MySQL to read a table with 30 million rows (about 4.9G in physical size) for the first time, while it takes only 42 seconds to read a text file with same size, a difference of more than 12 times. Similarly, the difference also exists in data writing, and the writing time of database is 50 times slower than that of text.
Therefore, the file is much faster than database from the perspective of reading and writing performance alone.
The structure of the database is flat, and the tables are all at the same level (linear structure) after they are created. If the schema was regarded as one layer, it could be counted as two layers at most. In this case, it is more difficult to manage when there are a large number of tables. To distinguish these tables, it needs to use strict naming rules, such as naming by project, module, year and version, and such rules require a strong management mechanism. In practice, however, since the project is usually very urgent and needs to be launched quickly, the naming rules cannot be strictly followed. As a result, the database management is very chaotic over time, and sometimes it's not easy to delete even if you want to delete the data table, often resulting in the permanent existence of data table after it is created (as it is not known which program is still using it, you have to keep it).
On the contrary, the file system can manage files with its tree-like directory. Different projects and modules can be stored according to the tree-like structure, which is very convenient in both management and usage. When the project is offline, you can safely and boldly delete the corresponding directory without worrying about tight coupling with other programs.
In addition, using the database to store data are under some restrictions. For example, it needs to create the tables before storing the data; the data types are too rigid to store the data that does not meet the conditions, and hence the flexibility is very poor; sometimes some temporary calculations need to be performed over and over again, resulting in the inconvenience to use the database anymore. Conversely, no such problems exist in a file system. File can store any type of data, which is very flexible and easy to use.
Compared with database, the file is superior whether in data reading/writing or management, but it is not the case in terms of data computing. As mentioned earlier, the value is created only by using the data, and in a broad sense, using the data is the calculation. In addition to capability to store the data, the database has the capability to compute the data very conveniently. It is very convenient to use SQL, a specialized database computing language, to process data. For example, the grouping and aggregating or the association operation can be done by just one simple statement. The file, however, does not have such capability. To calculate the data of file, other programming languages need to be used. The difficulty of implementing operations in different languages is also different, but most of them are more complicated than SQL.
Some business scenarios will involve data modification. Modifying the data of database is relatively simple and can be done easily with SQL statement. But, modifying the data of file is much more troublesome; neither finding the records to modify nor updating the data is easy, and in most cases, it's not as efficient as rewriting the file. Nevertheless, for scenarios like data analysis (OLAP), which mostly face with historical data that is no longer changing, and do not involve data modification and deletion (just data appending in most cases), using the file works.
In addition, some scenarios like the transaction system requires the data consistency. Since the database has the transaction management mechanism, it can meet this requirement, but the file cannot. For the scenario that does not require data consistency such as OLAP, the file can be used.
On the whole, if there are frequent modification requirements to data, especially for scenarios (such as transaction system) that require data consistency, it is more appropriate to use the database; while for scenarios without data consistency requirements (like analytical system), file system can be used. Since the file does not have computing power, it will be more complicated to use conventional hard-coding method. If the computing power is enhanced, and with the aid of the efficient reading and writing capabilities of the file as well as its flexibility & manageability features, then file storage method will have more advantages.
Now then, is there a method to enhance the computing power of file?
Yes, this can be achieved by using the open-source esProc SPL.
SPL is a professional open-source data computing engine, which provides an independent computing syntax, and its computing power does not depend on the database. SPL can perform the calculations based on the file to make the file have computing power. In this way, it can effectively solve the problem of insufficient file computing power; in addition, SPL supports multiple data sources and can perform the mixed calculation.
SPL provides an independent calculation syntax and a rich calculation class library, and can quickly implement the structured data calculation. Here are some conventional operations:
| A | B | |
| 1 | =T("/data/scores.txt") | |
| 2 | =A1.select(CLASS==10) | filtering |
| 3 | =A1.groups(CLASS;min(English),max(Chinese),sum(Math)) | grouping and aggregating |
| 4 | =A1.sort(CLASS:-1) | sorting |
| 5 | =T("/data/students.txt").keys(SID) | |
| 6 | =A1.join(STUID,A5,SNAME) | association |
| 7 | =A6.derive(English+ Chinese+ Math:TOTLE) | appending of column |
In addition to the native syntax, SPL provides SQL support equivalent to SQL92 standard, and hence those who are familiar with SQL can directly use SQL to query files.
$select * from d:/Orders.csv where Client in ('TAS','KBRO','PNS')
It even supports the more complex with:
$with t as (select Client ,sum(amount) s from d:/Orders.csv group by Client)
select t.Client, t.s, ct.Name, ct.address from t
left join ClientTable ct on t.Client=ct.Client
SPL is also advantageous in processing multi-layer data (files) such as JSON/XML. For example, the following code is a calculation based on employee order information (JSON).
| A | ||
| 1 | =json(file("/data/EO.json").read()) | |
| 2 | =A1.conj(Orders) | |
| 3 | =A2.select(Amount>1000 && Amount<=3000 && like@c(Client,"*s*")) | conditional filtering |
| 4 | =A2.groups(year(OrderDate);sum(Amount)) | grouping and aggregating |
| 5 | =A1.new(Name,Gender,Dept,Orders.OrderID,Orders.Client,Orders.Client,Orders.SellerId,Orders.Amount,Orders.OrderDate) | association calculation |
As you can see that this SPL code is more concise compared to other JSON libraries (such as JsonPath).
Likewise, using SQL can also query JSON data:
$select * from {json(file("/data/EO.json").read())}
where Amount>=100 and Client like 'bro' or OrderDate is null
SPL's agile syntax and procedural calculation are also well suited for complex computing. For example, to calculate the maximum consecutive rising days of a stock based on the stock record (txt), you can write:
| A | |
| 1 | =T("/data/stock.txt") |
| 2 | =A1.group@i(price<price[-1]).max(~.len())-1 |
Another example: list the last login interval of each user according to user login records (csv):
| A | ||
| 1 | =T(“/data/ulogin.csv”) | |
| 2 | =A1.groups(uid;top(2,-logtime)) | last 2 login records |
| 3 | =A2.new(uid,#2(1).logtime-#2(2).logtime:interval) | calculate the interval |
For such calculation, it is also difficult to use SQL to code even based on database, but it is very convenient to implement in SPL.
Text is a very common form of data storage, which is widely used for its advantages like universality and readability. However, the text is very poor in performance! The reasons are as follows:
Text characters cannot be operated directly, and need to be converted to the data type in memory such as integer, real number, date and string before further processing. However, the text parsing is a very complicated task, and it will consume a lot of time on CPU. Generally, the time to access the data in the external storage is mainly spent on reading the hard disk itself, while the performance bottleneck of text file often occurs in the CPU. Due to the complexity of the parsing, the time spent on CPU is likely to exceed that spent on hard disk (especially when using high-performance SSDs). Therefore, the text is generally not used when processing a large amount of data at high performance is required.
SPL provides two high-performance data storage formats, bin file and composite table. The bin file is a binary data format, which not only adopts the compression technology (faster reading due to less space occupation,), stores the data types (faster reading due to no need to parse the data type), but also supports the double increment segmentation mechanism that can append the data. Since it is easy to implement parallel computing by using the segmentation strategy, the computing performance is further improved.
The composite table is a file storage format that SPL provides columnar storage and index mechanism. When the number of columns (fields) involved in the calculation is small, the columnar storage will have great advantages. In addition to supporting columnar storage and implementing minmax index, the composite table supports the double increment segmentation mechanism, therefore, it not only benefits from the advantages of columnar storage, but also makes it easier to perform the parallel computing to improve the performance.
The use of SPL storage is also very convenient, which is basically the same as the use of text, such as reading the bin file and calculating:
| A | B | |
| 1 | =T("/data/scores.btx") | reading the bin file |
| 2 | =A1.select(CLASS==10) | filtering |
| 3 | =A1.groups(CLASS;min(English),max(Chinese),sum(Math)) | grouping and aggregating |
If the amount of data is larger, it also supports the cursor batch reading and multi-CPUs parallel computing:
=file("/data/scores.btx").cursor@bm()
When using the file to store the data, no matter what format the raw data is, it will eventually be converted to at least the binary format (such as bin file) and stored. In this way, it will be more advantageous whether in space occupation or computing performance.
With the complete computing power and high-performance storage, SPL provides capability equivalent to (or exceeding) the data warehouse, and can even replace data warehouses in many scenarios.
In addition to supporting file computing, SPL supports a variety of other data sources, whether you think of it or not.

In this way, SPL is able to implement multi-source mixed computation, especially suitable for T+0 query. As mentioned earlier, you can use the file to store a large amount of historical data that is no longer modified, and use the database to store a small amount of hot data that may be modified in real-time. However, it will involve querying across file and database when you want to query all data. In this case, you can use the cross-source computing capability and data routing function of SPL to select the corresponding data source and perform the cross-data source mixed computing according to the computing requirements. For example, after the separation of hot and cold data, you can perform the hot and cold data mixed query based on SPL, and at the same time, make it transparent to the upper-layer application to implement T+0 query.
| A | ||
| 1 | =cold=file(“/data/orders.ctx”).open().cursor(area,customer,amount) | / take cold data from file system (SPL high-performance storage), i.e., yesterday's and previous data |
| 2 | =hot=db.cursor(“select area,customer,amount from orders where odate>=?”,date(now())) | / take hot data from production database, i.e., today's data |
| 3 | =[cold,hot].conjx() | |
| 4 | =A3.groups(area,customer;sum(amout):amout) | / mixed computing to implement T+0 |
SPL provides standard JDBC and ODBC drivers for applications to call. In particular, for Java applications, SPL can be integrated into the application as an embedded engine so that the application itself has file-based strong computing capability.
An SPL code example for JDBC calling:
...
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
Statement st = connection.();
CallableStatement st = conn.prepareCall("{call splscript(?, ?)}");
st.setObject(1, 3000);
st.setObject(2, 5000);
ResultSet result=st.execute();
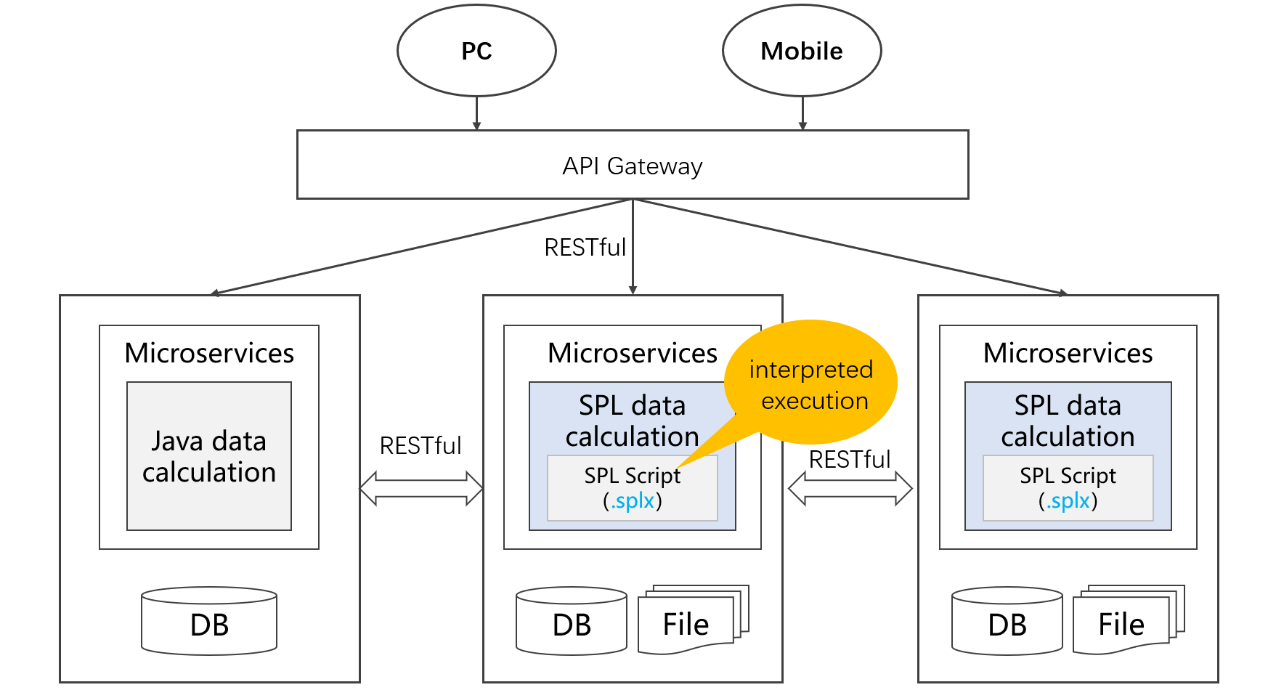
...Since SPL is the interpreted-execution, and naturally supports hot-swap, it is a great benefit for applications under the Java system. The writing, modification, operation and maintenance based on SPL data calculation logic do not require restarting and take effect in real-time, hereby making development, operation and maintenance more convenient.
Also, the features of easy integration and hot-swap make it easy to combine with the mainstream microservice framework to implement data processing inside the service, which can also effectively relieve the burden of data computing implemented in Java in the past.
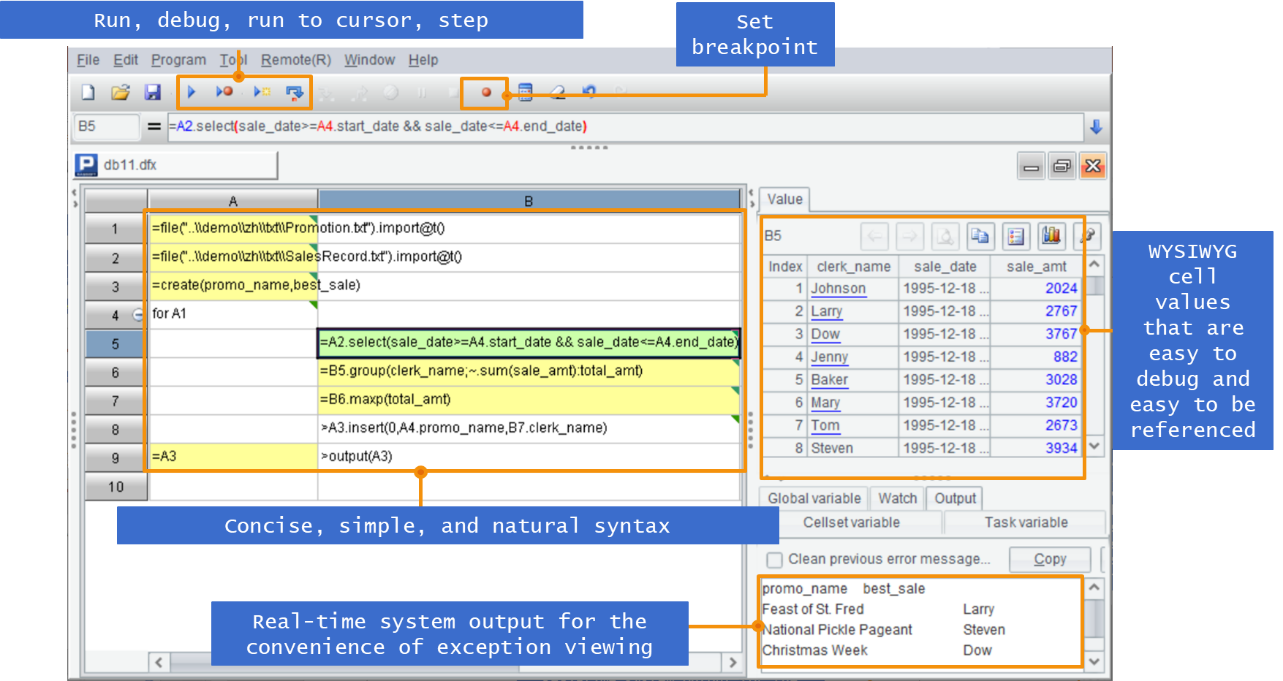
In addition to the advantages described above, the simple and easy-to-use development environment provided by SPL is remarkable such as single-step execution, setting breakpoint, and WYSIWYG result preview window, and thus the development efficiency is higher.
With the support of SPL’s file computing, high development efficiency and high computing performance, using file to store data can obtain better experience (when data consistency is not required), and can combine other data sources to implement the mixed computing, which is a good choice in the post-database era.