HTAP database cannot handle HTAP requirements
HTAP (Hybrid Transaction and Analytical Process) has become the direction of effort of many database vendors since it was explicitly proposed in 2014. In fact, HATP is not new because when RDB began to emerge in the early years, it was exactly to use one database to perform transaction and analysis at the same time. However, as the data scale continues to grow, if the analysis is still done directly based on business database, the business will be affected. In order to solve this problem, the data warehouse appeared, which works in such a way that it imports the business data into data warehouse to specially handle analysis requirements, and isolates data warehouse from business database. In this way, not only is the analysis scenario performed more efficiently, but it does not affect the business system. This stage was the “long united, must divide” stage (sourcing from a Chinese idiom “The empire, long divided, must unite; long united, must divide). But, because the data warehouse separates historical data from real-time data, and different types of databases (or big data platform) are often used, it will be very difficult to perform the real-time full data analysis (T+0), yet it is a must to perform T+0 for many timely businesses, this results in a premature abandonment of data warehouse in this regard. To cope with this problem, a solution that can perform both AP and TP in a single database is desired. As a result, HTAP emerged. From then on, it moved to the stage of “long divided, must unite”.
We know that, however, there are significant differences between AP and TP scenarios. Specifically, AP involves a large amount of data, and is complex in calculation logic, but the concurrency number is often not large, and there is no requirement for data consistency, and it often does not even need to meet the database norm for the convenience of use; TP is just the opposite, it involves a small amount of data, and has simple data processing logic, but the concurrency number is very large, and there is high requirement for data consistency. In terms of function, TP database itself is able to execute SQL, and has a certain AP function. The reason why TP was separated from AP is that when the amount of data is huge, AP requirement cannot be handled efficiently if the technology that pays more attention to TP is still used (for example, AP requires high performance, it needs to use the columnar storage, while TP requires writing the updates conveniently, it needs to use the row-based storage). These big differences between TP and AP make it impossible to meet their requirements at the same time with only a single technology architecture, this problem has not been solved substantially until now.
Even so, some vendors still attempt to solve this problem in a single storage engine, and they use a few methods to implement. The first method is to use multiple copies, one of which (possibly use the columnar storage) is used specially to meet AP requirement; The second method is to use the mixed storage way (row-based storage and columnar storage), which stores one copy of data in row-based storage, and one copy of data in columnar storage, the two kinds of storages are converted automatically; The third method does not make a distinction between row-based storage and columnar storage, and supports TP and AP scenarios through a single storage engine, and the common engines are some in-memory databases. This type of HTAP database will give priority to meet TP requirement, based on which the functions of AP are developed. Therefore, compared with generally special AP products, there is often a big gap in meeting AP requirements.
The practice of another type of HTAP database is that it still separates the two scenarios at the base layer, and designs the storage in a “modular” way. After the business data is generated, it will be duplicated in two copies, one copy still uses row-based storage for transaction and another copy uses columnar storage for analysis. Moreover, the corresponding storages and calculations are encapsulated and optimized with the aid of the technologies that are already mature in TP and AP fields, and a unified external access driver is designed to allow the differences at the base layer completely transparent to the application layer. In this way, a usable HTAP product is formed.
No matter which method is used to design HTAP database, it always encounters a problem in practice that if the original business database is not a HTAP database (high probability), it will involve migrating the database, which will face a high risk and high cost. In this case, it not only needs to consider the modification and processing of data structure during migration as a result of the difference of data types, but it also involves modifying the views, stored procedures and complex SQL. Moreover, various problems encountered in migration need to be solved, therefore, there are many difficulties and big troubles, and the resulting business impact may lead to great value loss.
In addition, modern business system involves not only RDB but also NoSQL like MongoDB and InfluxDB, and a variety of self-encapsulated business data sources. It is not easy to migrate these data sources to a new database. For example, you will find it difficult to move the data of MongoDB to RDB, for the reason that many data types and set relationships in MongoDB does not exist in RDB, such as the nested data structure, array and hash set, as well as the implementation of many-to-many relationship. Such problems cannot be solved simply by moving the data, and instead, it needs to reconstruct the structure of some data before moving, which requires a considerable high labor and time costs to sort out the business, and design the organization method for target data. Even if the business data source is finally moved to HTAP at a high cost, it loses the original advantages of diverse data sources themselves, and it is sometimes difficult to balance the gains and losses.
As we know that the data computing performance is closely related to data organization. In AP scenario, the columnar storage is usually used to give full play to computing advantage. However, columnar storage alone is far from enough, and for some complex calculations, it requires designing specialized data storage methods (such as ordered storage, data type conversion, pre-calculation) based on computing characteristics. These complex calculations that require high performance are common in AP scenarios. But, no matter what type of HTAP is used, a relatively "personalized" effect cannot be achieved by simply "automatic" row-to-column converting, and the performance often fails to meet the expectation. The reason is very simple, there is no one thing that performs perfectly in every respect in the world. If you want to combine row-based storage with columnar storage in one database, you have to tolerate deficiencies in one or some aspects.
Considering these deficiencies, i.e., high migration risk, high cost, value loss, and possibly unable to meet performance expectation, we can't help but ask: Is the technical route (HTAP database) correct?
Speaking of this, let's look back at the purpose of HTAP. Why do we use HTAP?
In fact, the target of HTAP is to perform the real-time querying and counting for full data, that is, T+0!
If the data warehouse and other related technologies have the ability to solve this problem, then HTAP is not needed naturally. However, it is a pity that the data warehouse still uses RDB's closed system. This system only allows the calculation to be performed after the data is imported into database, and importing into database is highly restricted. As a result, the data warehouse does not work well to achieve mixed computing across the data sources, especially different types of data sources and non-relational data sources, so it is difficult to achieve the goal of T+0.
Fortunately, esProc SPL does.
esProc SPL (Structured Process Language) is an open-source computing engine and programming language specially for computing the structured data. In addition to providing rich computing library that enables it to have independent computing ability that does not depend on database, SPL can connect to multiple data sources to accomplish multi-source mixed computing, thereby easily implementing the cross-data source real-time query.
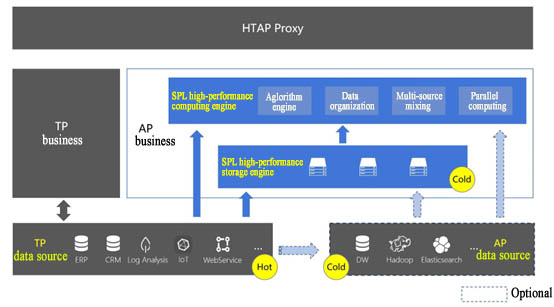
SPL implements HTAP in a way that combines with the existing system. In this way, it only needs to make a few modifications to the original system, and TP part can almost remain unchanged. SPL can even continue to use original AP data source, and gradually take over AP business. Having partially or completely taken over AP business, the historical cold data is stored in SPL high-performance file, and the original ETL process that moves the data from business database to data warehouse can be directly migrated to SPL. When the cold data is large in amount, and no longer changes, storing them in the high-performance file of SPL can obtain higher computing performance; when the hot data is small in amount, they are still stored in original TP data source so as to allow SPL to read and calculate them directly. Since the amount of hot data is not large, querying directly based on TP data source will not have much impact on them, and the access time will not be too long. Depending on SPL’s cold and hot data mixed computing ability, we can obtain T+0 real-time query for full data. After that, the only thing we need to do is to periodically store cold data in SPL's high-performance file, and keep the small amount of recently generated hot data in original data source. In this way, not only is HTAP implemented, but it is implemented in a high-performance way, and there is little impact on the application architecture.
In modern information system, it is very common to build the data warehouse and related technologies to provide specialized service for analysis scenario. However, since there are so many kinds of data sources, and moving all data to one place requires very high cost, as we've already discussed above. If the cross-data source real-time mixed computing ability can be added to the existing architecture, it is equivalent to providing wings for HTAP. In this way, HTAP requirement can be quickly implemented without changing the existing architecture. Fortunately, this ability is exactly a strength of SPL.
SPL supports a variety of data sources such as RDB, NoSQL, and RESTful, the data of which can be directly used in SPL. Moreover, SPL has the ability to parse JSON/XML and other types of data, and can also connect to other data sources like Elasticsearch and Kafka. Furthermore, SPL can fetch the data for calculation from traditional/emerging data warehouses, big data platforms, etc.

While connecting to other data sources, SPL has the ability to perform mixed computing for any number of data source types, thereby implementing T+0 real-time query for full data in a way that reads the real-time data from production database and fetches the cold data from the historical database/data warehouse/big data platform. In this way, the desired effect of HTAP (at the architectural level) can be achieved with little change to the original application architecture (especially the production database), and the cost is extremely low.
Another advantage of using SPL on existing architecture to implement HTAP is that the advantages of original data source can be fully retained. Specifically, we can continue to use NoSQL, and don’t have to change the data structure to that of RDB, and don’t have to make self-encapsulated data access and interaction interfaces yieldto new database as well. Therefore, the original advantages and personalized characteristics still remain. As a result, the risk is very low and the value loss is little.
The same goes for analysis side. Using SPL on the existing architecture also enables the originally built analysis platform to be continuously used. However, as mentioned earlier, analysis scenario involves a large amount of data and complex computing logic, and requires high performance in particular. To cope with this situation, SPL provides a high-performance computing mechanism, which can fully take over the business of original analysis side (AP) to implement high-performance data computing.
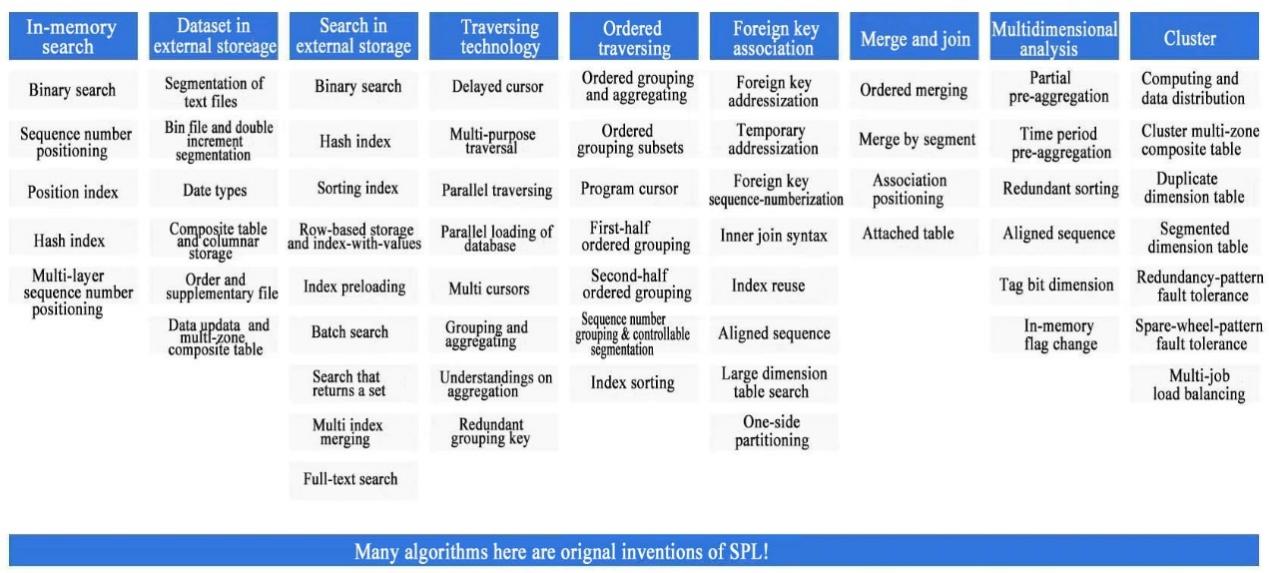
We know that two aspects are involved to obtain a high-performance computing. One is the data organization schema i.e., the data storage, and the other is the algorithm. The two aspects are inseparable. To make many high-performance algorithms work, there is a need to organize the data to corresponding format (such as, storing them in an ordered manner). In order to solve this problem, SPL provides its own storage mechanism, that is, it directly adopts a file system to store data into the file with specific format. Through this system, not only can a higher IO access efficiency, and the flexible management ability of file system be obtained, but the data storage advantages of own format can be fully utilized such as columnar storage, ordering, compression, and parallel segmentation, thereby efficiently giving play to the effect of high-performance algorithm.
In terms of algorithm, SPL provides a very rich high-performance algorithm library, including the multipurpose traversal, ordered merge, foreign key pre-association, tag bit dimension, parallel computing, etc., which have already been encapsulated, and can be used directly. Using these algorithms together with SPL’s storage mechanism make it possible to obtain high performance, and many of them are the original inventions of SPL and proposed for the first time in the industry.
If you simply convert the row-based storage in TP to the columnar storage in SPL, the workload is not high. However, in order to achieve high performance, it often needs to carefully design the storage schema, in which case there will be a certain amount of ETL work, but this work is basically the same as that of moving data from original business system to data warehouse, it won’t be more complex, and it is very necessary for high performance. Compared with general HTAP database that is difficult to conduct an effective designed storage schema, SPL can easily conduct a more efficient storage organization schema after the separation of hot and cold data, just like the previous TP/AP separation. In this way, the performance of both TP and AP can be maximized. The work of organizing data is often worthwhile since it can improve the performance significantly.
In practice, there are already many cases that use SPL storage schema and algorithms to improve performance by several times or tens of times. For example, in the case of batch operating of vehicle insurance policies of an insurance company (Open-source SPL optimizes batch operating of insurance company from 2 hours to 17 minutes), using SPL reduces the computation time from 2 hours to 17 minutes. In this case, the access amount to external storage is effectively reduced after taking over the storage, and using SPL’s unique multi-purpose traversal technology (this technology performs multiple operations in one traversal of big data). At the same time, in SPL, it only needs to traverse the large table once to perform three association and aggregation operations (If SQL is used, the large table needs to be traversed three times). Moreover, different algorithms are used in association operation in this case, a huge performance improvement is thus obtained.
Another case (Open-source SPL turns pre-association of query on bank mobile account into real-time association), using SPL turns the mobile account query that can only be pre-associated originally into real-time association, while reducing the number of servers from 6 to 1. This case makes full use of SPL's ordered storage mechanism. Reading all data of one account in one go effectively reduces the hard disk access time (physical continuous storage), and with the aid of the foreign key real-time association technology that distinguishes dimension table from fact table, it implements real-time association query by just using a single machine. As a result, the performance is improved significantly, and the number of hardware required is greatly reduced.
The SPL-based HTAP is not limited to T+0 and high performance only.
In data computing (mainly referring to OLAP scenarios), there are always two difficulties, one is to make the running speed faster (performance), and the other is to code in a simpler way (development efficiency). The former has been discussed, and the latter can be greatly improved by using SPL.
Today, SQL is still the main language to process data (other high-level languages are too troublesome), but it is still difficult for SQL to describe many operations. This is mainly due to the theoretical limitations of SQL, which will not be discussed in this article. If you’re interested in that, visit: SPL: a database language featuring easy writing and fast running.
In view of the poor description ability (development efficiency) of SQL in complex computing, SPL does not continue to use SQL system. Instead, it redesigns a set of agile computing syntax based on new theory, and it will be more advantageous and easier to write based on the agile syntax in implementing the calculation, especially the complex calculations.
Let's experience the simplicity of SPL through the funnel operation commonly used in e-commerce system.
SQL (oracle) code:
with e1 as (
select gid,1 as step1,min(etime) as t1
from T
where etime>= to_date('2021-01-10', 'yyyy-MM-dd') and etime<to_date('2021-01-25', 'yyyy-MM-dd')
and eventtype='eventtype1' and …
group by 1
),
with e2 as (
select gid,1 as step2,min(e1.t1) as t1,min(e2.etime) as t2
from T as e2
inner join e1 on e2.gid = e1.gid
where e2.etime>= to_date('2021-01-10', 'yyyy-MM-dd') and e2.etime<to_date('2021-01-25', 'yyyy-MM-dd')
and e2.etime > t1
and e2.etime < t1 + 7
and eventtype='eventtype2' and …
group by 1
),
with e3 as (
select gid,1 as step3,min(e2.t1) as t1,min(e3.etime) as t3
from T as e3
inner join e2 on e3.gid = e2.gid
where e3.etime>= to_date('2021-01-10', 'yyyy-MM-dd') and e3.etime<to_date('2021-01-25', 'yyyy-MM-dd')
and e3.etime > t2
and e3.etime < t1 + 7
and eventtype='eventtype3' and …
group by 1
)
Select
sum(step1) as step1,
sum(step2) as step2,
sum(step3) as step3
from
e1
left join e2 on e1.gid = e2.gid
left join e3 on e2.gid = e3.gid
SPL code:
| A | B | |
| 1 | =["etype1","etype2","etype3"] | =file("event.ctx").open() |
| 2 | =B1.cursor(id,etime,etype;etime>=date("2021-01-10") && etime<date("2021-01-25") && A1.contain(etype) && …) | |
| 3 | =A2.group(id).(~.sort(etime)) | =A3.new(~.select@1(etype==A1(1)):first,~:all).select(first) |
| 4 | =B3.(A1.(t=if(#==1,t1=first.etime,if(t,all.select@1(etype==A1.~ && etime>t && etime<t1+7).etime, null)))) | |
| 5 | =A4.groups(;count(~(1)):STEP1,count(~(2)):STEP2,count(~(3)):STEP3) |
As we can see that it needs to write more than 30 lines of code when using oracle's SQL, which is quite difficult to understand. Moreover, this code is related to the number of steps of funnel, every extra step needs to add one sub-query. For such complex SQL code, it is very difficult to write, let alone performance optimization.
In contrast, using SPL is much simpler, and the same SPL code can handle any number of steps.
Well, at this point you should know that SPL is not an HTAP database, but provides a new idea to meet HTAP requirement. HTAP database is popular, and the promotional slogan of vendors easily makes us get caught up in the hedge that we know nothing in addition to using one kind of database to solve HTAP problem. However, if we think a little more, we will find that HTAP is only a reasonable business requirement, and it may not be necessary to use a new database but a new technology and architecture to meet this requirement, and SPL provides this possibility.