Open source SPL improves bank’s self service analysis from 5 concurrency to 100 concurrency
Bank B’s e-banking self-service analysis system (“the system” for short) needs to query the customer transaction details on the specified date, and the business personnel can set the filtering condition on the interface at will to filter and query in tens of millions of data per day. The query results are used to find the target customer, formulate the marketing plan and evaluate the effect of campaign and so on. However, the existing system can only support five concurrent accesses, which is far from meeting the access needs of a large number of business personnel.
Why does this happen? The reason is that the backend of the system is unable to support more concurrency accesses. The system is directly connected to its backend, i.e., bank B’s central data warehouse. The data warehouse, however, is not specially for the system but shared by the whole bank, and also undertakes other application tasks such as batch running. Since the data warehouse has 48 cluster nodes, almost reaching its upper limit, and cannot be expanded any more, it can only provide the system with five connections, and it is impossible to provide more. Moreover, despite there are five connections, it is difficult to ensure smooth use. Once the data warehouse performs other important tasks, the operation of the system will be very laggy.
The architecture of the system is shown as below:
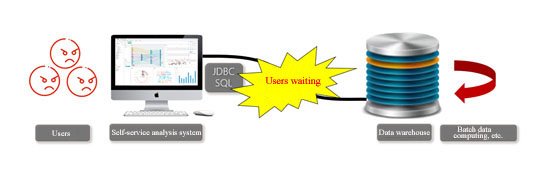
Since the data warehouse cannot be expanded, can we consider changing to other data warehouses? No, it is infeasible, the reason is that the data warehouse involves many applications in many departments, and thus the changing cost is too high, and there is stability hazard. Furthermore, even if the data warehouse is replaced, it's not necessarily faster, and it also needs a lot of testing and optimization.
In this case, an easy way to think of is to put a front-end database before the data warehouse to share the burden of the system. However, the conventional relational database is incompetent, for the reason that the self-service analysis needs to query all historical detail data, if the front-end database had the same scale of data as data warehouse, it would need to build the same scale clusters, and the bank would not tolerate the cost of repeated construction; moreover, the conventional row-based storage database cannot achieve the second-level response speed in the face of tens of millions of data volume under multiple-concurrency scenario.
First of all, analyze the characteristics of business and requirements. The calculations and data of self-service analysis are rules-based, and the SQL submitted by the system is relatively simple, including only the clause: select, from and where, and no complex window functions. The clause “from” is based on a wide table, and there is no join to associate tables. In addition, there are dozens of fields in a wide table, but only a few fields need to be queried in general. In the Where condition, the date is a required condition, which means, only the data of one day can be queried. Other filter conditions are selected and combined by customers themselves.
Upon further analysis, we found that more than 90% of the query requests are concentrated on about a dozen dates: the day before the query, and the last day of month-end for 13 consecutive months. For the data outside this date range, the query volume is less than 10%. Thus, we can define the data in this range as hot data, and other data as cold data.
Second, design the optimization scheme and determine the technical requirements. According to actual situation and business requirements, we still decide to adopt the front-end computation layer scheme. In this scheme, the front-end layer is used to save the hot data, performs the corresponding queries, and undertakes over 90% of calculation amount; while for the query of cold data, it is still performed on the central data warehouse, but the amount of calculation is decreased to less than 10% of that in original method. In this way, the front-end computation layer only needs to save a small amount of hot data, hereby avoiding repeated construction.
The key to this scheme is the technology for the implementation of front-end computation layer. To implement this scheme, the technology must have enough high performance to deal with 90% of query volume, and the capability to perform routing. Since the front-end of self-service analysis is a packaged software, and the SQL query can only be sent with a JDBC interface to back-end data warehouse, the front-end computation layer needs to be able to decide whether to do the query itself or send the query to the central data warehouse according to the date condition in SQL. The architecture of the optimization scheme is shown as below:
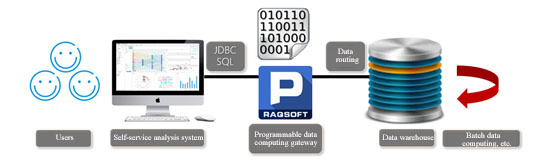
It can be found from the figure that, after the system submits SQL query, the front-end computation layer needs to judge whether the date condition is for hot data, if so, it will query the data directly and return the result; if not, the SQL will be transmitted to the data warehouse and the result will be returned to the system. Therefore, the computation layer plays a role of a gateway, as it can select the path for data computing, and thus we call it data computing routing.
In addition, since the memory capacity of bank B’s general servers is 128G, there is no way to achieve all-in-memory operation in the face of more than ten consecutive days and tens of millions of data per day. Therefore, this front-end computation layer needs to adopt a high-performance columnar storage scheme, only in this way can it provide a second-level response to cope with tens of millions of data volume under multiple-concurrency scenario.
Furthermore, the front-end computation layer also needs to provide a standard JDBC interface for the system, so as to support at least the simple SQL statements mentioned above, that is, it needs to have the ability to parse and execute SQL.
Thirdly, determine the technical selection. Having obtained the optimization scheme, we also need to select an appropriate tool. After the preliminary analysis, we know that we can't use conventional relational database to build the front-end computation layer.
Since the server does not have much memory capacity to hold all data, we cannot use the all-in-memory computing technology (including various in-memory databases). Using the existing columnar storage database can generally meet the performance requirements; however, it not only costs much, but it also is the relational database system that cannot achieve routing, and thus it is infeasible. If the high-level language such as Java, C++ is used, the above algorithm can be implemented, but it is also infeasible due to too large amount of coding, too long project period, prone to a hidden trouble with code errors, and difficult to debug and maintain.
Fortunately, the open-source esProc SPL language provides all the above algorithm support, including the high-performance columnar storage file, JDBC and SQL execution. In addition, it provides the basic functions for parsing and converting SQL statements to implement data calculation routing, which allows us to quickly implement this personalized calculation with less amount of code.
The esProc SPL language provides powerful script functions, which can be used to define and adjust the routing rules for data calculation. In this way, routing logs can also be recorded to analyze the temporal and spatial distribution of hot data, and to continuously optimize routing rules.
Finally, implement the front-end computation layer and gateway scheme. When the front-end computation layer is initialized, it needs to export the hot data of more than ten days from data warehouse, and cache them in the local high-performance columnar storage file. According to the method before optimization, the latest data of the previous day pushed from the production database is imported into the central data warehouse with ETL tool every day. After optimization, the pushed data will be saved as file in the esProc at the same time. Since the data is originally pushed, it does not increase the export burden of production database.
In the system, it needs to replace the JDBC driver of data warehouse with the JDBC driver of esProc, and adjust the data connection parameters accordingly. No other changes are required for maximum compatibility.
After receiving the query request submitted by the system, esProc will first parse SQL to split out all SQL clause, and determine the calculation path based on the date condition in the where clause. If it is hot data, access the locally cached high-performance columnar storage file; if it is cold data, convert the standard SQL to the SQL statements of data warehouse, and then transmit the converted statements to the data warehouse for execution, and return the results to the system, at the same time, the log of data routing is recorded.
In order to share the load during parallel access, esProc adopts a two-node cluster deployment method. In doing so, it can avoid single node failure and achieve high availability. The final system architecture built with esProc is as follows:
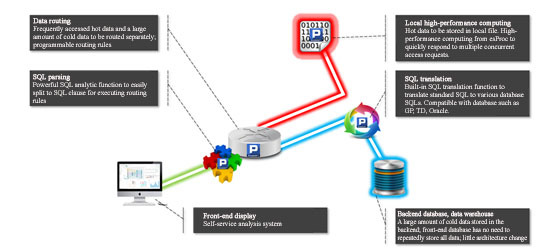
After optimization, the system has been officially run online, achieving very remarkable effect.
Viewing from a single query request test, when the esProc and the professional data warehouse execute the same conditional query in case of 30 million rows of detail data per day, the results are as follows: esProc executes the query in only 2 seconds, while the data warehouse takes 5 seconds. In addition, the hardware environment of the two is also different. The data warehouse uses a 5-node cluster, each node is a physical machine with 26-core CPUs and 96G memory; while the server where esProc is located is only a virtual machine with 12-core CPU and 16G memory.
From the perspective of concurrent requests, each front-end server supports 50 concurrent requests, all of which are returned within 5 seconds. The cluster with two servers support hundreds of users to access without pressure. That is to say, just adding two low-end PC servers increases the concurrency by more than 10 times, and the whole process operation is smooth.
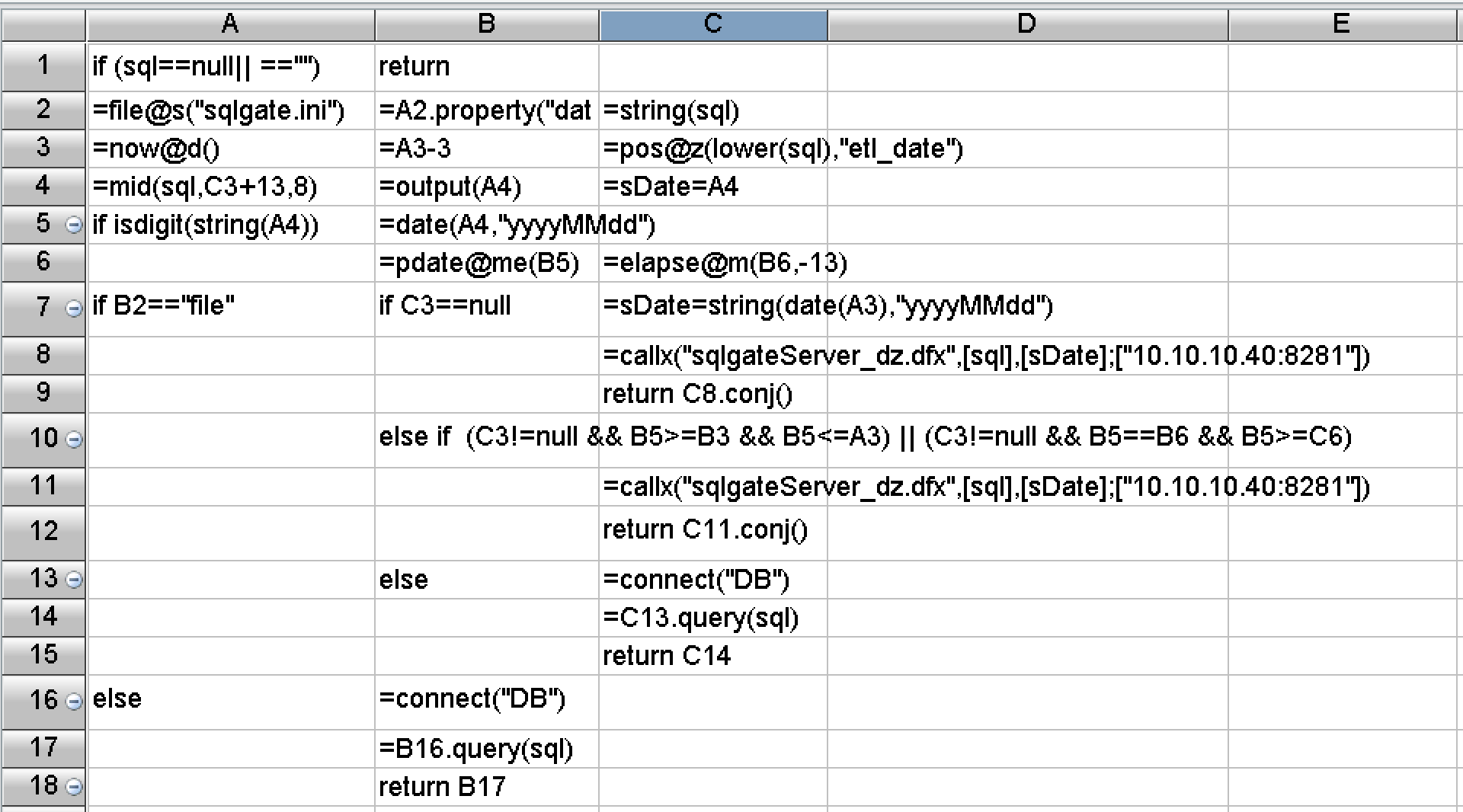
In terms of development difficulty, SPL has made a lot of encapsulations, provided rich functions, and built-in the basic algorithms and storage mechanisms required by the above optimization scheme. The SPL code corresponding to the data calculation routing mentioned above is as follows:
To solve the performance optimization problem, the most important thing is to design a high-performance computing scheme to effectively reduce the computational complexity, thereby ultimately increasing the speed. Therefore, on the one hand, we should fully understand the characteristics of calculation and data, and on the other hand, we should have an intimate knowledge of common high-performance algorithms, only in this way can we design a reasonable optimization scheme according to local conditions. The basic high-performance algorithms used herein can be found at the course: Performance Optimization, where you can find what you are interested in.
Unfortunately, the current mainstream big data systems in the industry are still based on relational databases. Whether it is the traditional MPP or HADOOP system, or some new technologies, they are all trying to make the programming interface closer to SQL. Being compatible with SQL does make it easier for users to get started. However, SQL, subject to theoretical limitations, cannot implement most high-performance algorithms, and can only face helplessly without any way to improve as hardware resources are wasted. Therefore, SQL should not be the future of big data computing.
After the optimization scheme is obtained, we also need to use a good programming language to efficiently implement the algorithms. Although the common high-level programming languages can implement most optimization algorithms, the code is too long and the development efficiency is too low, which will seriously affect the maintainability of the program. In this case, the open-source SPL is a good choice, because it has enough basic algorithms, and its code is very concise, in addition, SPL also provides a friendly visual debugging mechanism, which can