Split rv32i_m/F/fnmadd_b15.S, fnmsub_b15.S, fmadd_b15.S, fmsub_b15.S into multiple smaller tests #461
Conversation
Sorry, PMP tests were in a different branch, it got synced while cleaning up my branches. I have removed all pmp related stuff from this PR. |
There was a problem hiding this comment.
This reduces the size of fm[n][add/sub] tests by splitting them into individual test cases (using a custom python tool) each of which contain 256 tests (roughly 12KB instructions and 6.4KB data) and updating them to work with RV32E/RV64E architectures. No tests were changed, so the exact same test cases are still present, with the same coveragem but now in nearly 300 different test files instead of 4 monolithic test files
|
now merged!
…On Fri, Apr 26, 2024 at 12:10 PM Umer Shahid ***@***.***> wrote:
Hm, I don't think we should be lumping the FMA splitting into the same PR
as PMP tests; unless there's a really good reason, those should be a
different PR.
Sorry, PMP tests were in a different branch, it got synced while cleaning
up my branches. I have removed all pmp related stuff from this PR.
—
Reply to this email directly, view it on GitHub
<#461 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AHPXVJTIFKAHMFFW7L5Y6KLY7KRA7AVCNFSM6AAAAABG2WO6MSVHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMZDANZZHE3TONRUGM>
.
You are receiving this because you commented.Message ID:
***@***.***>
|
|
Thanks for doing this! Unfortunately it looks like there are still some really big tests that have been missed:
Also I am not sure a Python script to split up the tests like this is a good long term solution. As soon as someone tries to regenerate them they will have this problem again and your script is unlikely to work at that point. I may still try my approach which is to post-process the normalised cgf YAML file just before generation. Let me know if you are going to fix the above issues though - if so I probably wont bother! Finally, I highly recommend you use |
|
Separately, I had suggested splitting into 10 files, not 300. We just added thousands of tests to riscv-arch-test. There are so many that github won't show the full directory. In some methodologies such as ImperasDV, the simulator has to launch separately on each file, creating an enormous overhead to start up thousands of times. |
|
I think 10 files would still be too big. Based on the file sizes 50 would bring them in line with the other files. |
|
The script could probably be adapted without too much trouble to any size
we wanted.
Splitting each into 128 test cases turned about to be easy, as would any
multiple of that.
I suspect we could pretty much use the same script for the missing tests.
*Discussion topic for the next meeting:*
Talk about that what size code or data region should we choose as a test
limit (e.g.a range from X to 2X bytes for code/data/sum of code+data)
(and I think that should be the measure, and not the number of files)
(I would like the files be named with constant sized , so they are listed
in numerical order instead of alphabetical order though)
Long term, you are correct that it isn't an ideal solution, but I suspect
it will work for quite a while until we have resource to do it correctly.
This effort took a only matter of hours (the structure of the tests made
that possible, as well as a talented programmer).
I don't know of any other tests that wouldn't have similar structures, so a
python script might be the easiest solution for some time to come.
It won't work for more unstructured tests, but I don't know of or
contemplate any large ones.
…On Wed, May 1, 2024 at 9:31 AM Tim Hutt ***@***.***> wrote:
I think 10 files would still be too big. Based on the file sizes 50 would
bring them in line with the other files.
—
Reply to this email directly, view it on GitHub
<#461 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AHPXVJQK3CG3T262XBRQ23DZAEKF7AVCNFSM6AAAAABG2WO6MSVHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMZDAOBYG4ZTANZRGI>
.
You are receiving this because you modified the open/close state.Message
ID: ***@***.***>
|
|
@Timmmm other tests can also be split into multiple files but first we need to discuss what should be the optimal file size vs number of files. It is a good thing that Allen has added this point as the agenda item for next week's meeting, we will update the script and will split the test files after converging to a conclusion in the next meeting |
|
Sounds good. Which meeting is it? |
|
I agree that the size of the b_15 files before the split was the bottleneck on running regressions. However, even a 3-way split would be enough in my context to break the bottleneck. There's overhead launching each simulation job that has to balance against the parallelism of the jobs. A 10ish way split would be a reasonable sweet spot so that the simulations run fast without greatly increasing the total number of simulations required to regress the riscv-arch-tests. Moreover, there are 4 fma-type instructions in each of f, d, and Zfh, so the number of files is 12x the number of splits. A large number of splits also leads to a huge number of files in the riscv-arch-test repository and in the regression logs. That can make directories cumbersome and can lead to real problems getting hidden in a sea of reports. For example, for fma-type instructions, I counted 102005 cases in _b15 tests. I count 13,835 for _b1, 1684 for b8, 280 for _b5, and so forth. Integer tests have 1-819 cases each. I can see a benefit getting down to below _b1. Unless we also split _b1, why go much lower? And what metric are we optimizing to choose the number of splits? @Timmmm, what is driving the desire to make the _b15 splits in line with the other test cases? Please help me understand why that is beneficial rather than overkill? |
|
We discussed how to write a simply python tool that will split a test up into multiple tests, based on parameters passed to it. |
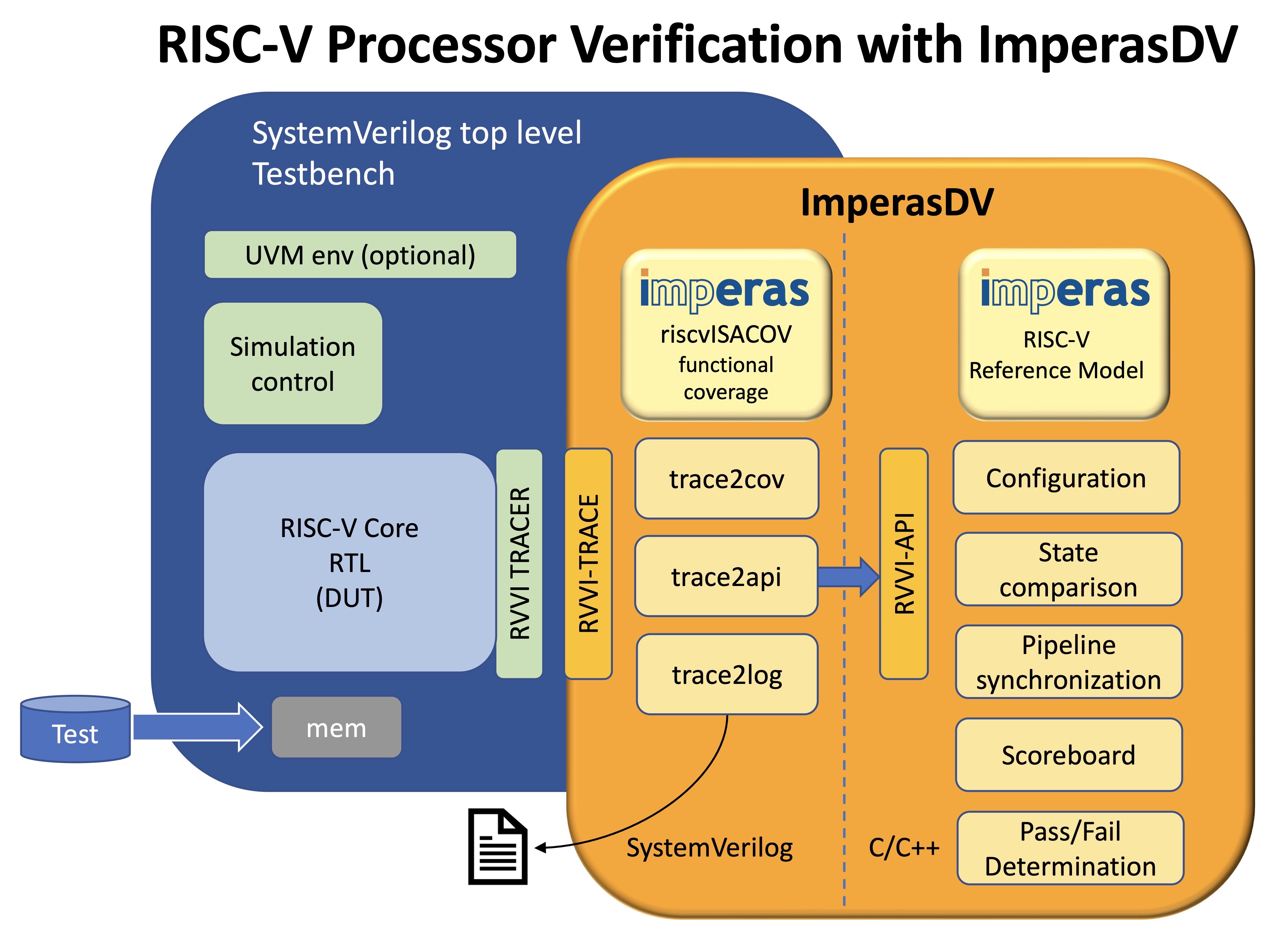
I definitely agree! Our overhead for each job is only 15 seconds though (see below), which is very small compared to the actual runtime of the tests in our case. I haven't used ImperasDV but I have briefly used their reference model and we use it in a similar way to this diagram but with a custom trace system. I don't remember it having a long startup time - just the normal time of running the RTL simulator which is pretty fast.
I don't really understand how this can be a real problem to be honest. Anyone properly verifying a chip will be running tens of thousands of tests. No testing system I've ever used has required you to manually look through a list of pass/fails to find the failures. Maybe I'm misunderstanding you here though?
There are two reasons:
I did some measurements and actually the b1 tests are only slightly over that 2GB limit so maybe it's not worth splitting those and we'll just increase our limit slightly. But I definitely wouldn't want anything bigger than that. Here's some examples:
|
{kind=link}
|
I'm missing something here. How is the test size being calculated?
For fmul.d, 38k ops is ~5.5K tests, each test case is
8B/op * 7ops * ~5.5k tests = ~308KB (each tests is CSRW Fcsr, Flw Src1,
Flw Src2, Mul, Fsw rd, CSRr Fcsr, stw Fcsr)
8B/op * 2Src * ~5.5k tests = ~88KB
8B/dst * 2dst * ~5.5 tests = ~88KB
18B /sig * 2sig * ~5.5 signature entries = ~198KB
Total is 682KB How did that become 2GB, >150x larger?
…On Tue, May 7, 2024 at 2:16 AM Tim Hutt ***@***.***> wrote:
There's overhead launching each simulation job that has to balance against
the parallelism of the jobs.
I definitely agree! Our overhead for each job is only 15 seconds though
(see below), which is very small compared to the actual runtime of the
tests in our case. I haven't used ImperasDV but I have briefly used their
reference model and we use it in a similar way to this diagram
<https://www.imperas.com/sites/default/files/inline-images/ImperasDV_diagram_May_2023.jpg>
but with a custom trace system. I don't remember it having a long startup
time - just the normal time of running the RTL simulator which is pretty
fast.
A large number of splits also leads to a huge number of files in the
riscv-arch-test repository and in the regression logs. That can make
directories cumbersome and can lead to real problems getting hidden in a
sea of reports.
I don't really understand how this can be a real problem to be honest.
Anyone properly verifying a chip will be running tens of thousands of
tests. No testing system I've ever used has required you to manually look
through a list of pass/fails to find the failures. Maybe I'm
misunderstanding you here though?
what is driving the desire to make the _b15 splits in line with the other
test cases? Please help me understand why that is beneficial rather than
overkill?
There are two reasons:
1. Total runtime. It's preferable to keep the total runtime of the
tests under 10-20 minutes so we can run them in CI. We use test ranking to
decide which tests to run in CI but if they take longer than this then they
aren't eligible at all. We do have tests that run longer but given 15
second overhead it's nice if they are around ~10 minutes.
2. Memory use. Since we run thousands of jobs on a shared compute
cluster, we reserve each job some memory. Currently 2 GB, but these jobs go
over that limit during compilation (although only very slightly for the b01
tests).
I did some measurements and actually the b1 tests are only *slightly*
over that 2GB limit so maybe it's not worth splitting those and we'll just
increase our limit slightly. But I definitely wouldn't want anything bigger
than that.
Here's some examples:
- Hello world: 1k instructions, 15s, max RSS 200 MB
- rv32i_m/D/fmul.d_b9-1 (the largest of the non-problematic tests):
38k instructions, 2m40s, max RSS 230 MB
- rv32i_m/D/fnmadd.d_b1-01: 253k instructions, 44m20s, max RSS 2.1 GB
—
Reply to this email directly, view it on GitHub
<#461 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AHPXVJXR434QZKICHEXOAVLZBCLX3AVCNFSM6AAAAABG2WO6MSVHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMZDAOJXHAZTCMJYG4>
.
You are receiving this because you modified the open/close state.Message
ID: ***@***.***>
|
|
2.1GB is the maximum memory usage when compiling, not the size of the test. |
|
Ok, thanks for the clarification - I thought that might be the case.
For splitting up tests, though, we can't use RSS as a metric for splitting
up tests;
We can only use (#tests*test_size ) + (#data loads/tests) + (#signature
stores/test) to estimate the amount of memory that will be used to run the
test,
and the amount of disk space of the stored signature.
…On Wed, May 8, 2024 at 1:07 AM Tim Hutt ***@***.***> wrote:
2.1GB is the maximum memory usage when compiling, not the size of the test.
—
Reply to this email directly, view it on GitHub
<#461 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AHPXVJULANJWX7POY7LA5L3ZBHML3AVCNFSM6AAAAABG2WO6MSVHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMZDAOJZHE4TGNRQGM>
.
You are receiving this because you modified the open/close state.Message
ID: ***@***.***>
|
|
I think that's fine. I would expect that that is probably a pretty good proxy for memory use during compilation. |
|
@Timmmm there is something funny going on for your memory requirements to scale with the length of the test. Is it possible that the testbench is logging too much history of state in RAM? I agree with Allen that even the biggest tests should add less than 1 MB of memory to model. I accept your argument that full verification of a large system involves a large number of test files. However, splitting up riscv-arch-test in this way exploded the number of tests in this suite. I may be biased focusing on just riscv-arch-test, but I feel it's gotten out of hand. For example, when I go to https://github.com/riscv-non-isa/riscv-arch-test/tree/main/riscv-test-suite/rv32i_m/F/src I get a message There's also some baggage related to the CORE-V Wally flow. Presently, we list each test set individually in a file, so this involves adding thousand of lines to the file. We print each set when it runs successfully, which had been dozens and becomes thousands in the logs. Debug occasionally involves scanning the logs, and this is more cumbersome when they explode in size. None of this is showstoppers, but it affects our viewpoint. As a simple heuristic, how about splitting the _b15 tests into 10 files instead of 300, to get their runtime below _b1? |
|
So, we can have tests that are too big, or directories that are too big.
One "simple" fix is probably to put each test that is broken up this way
into its own subdirectory
(and while we're at it, make the numbering be 3 digits with leading zeroes
so it sorts correctly)
I don't think there is any particular limit on directory levels in Riscof
…On Thu, May 9, 2024 at 6:54 AM David Harris ***@***.***> wrote:
@Timmmm <https://github.com/Timmmm> there is something funny going on for
your memory requirements to scale with the length of the test. Is it
possible that the testbench is logging too much history of state in RAM? I
agree with Allen that even the biggest tests should add less than 1 MB of
memory to model.
I accept your argument that full verification of a large system involves a
large number of test files. However, splitting up riscv-arch-test in this
way exploded the number of tests in this suite. I may be biased focusing on
just riscv-arch-test, but I feel it's gotten out of hand. For example, when
I go to
https://github.com/riscv-non-isa/riscv-arch-test/tree/main/riscv-test-suite/rv32i_m/F/src
I get a message
Sorry, we had to truncate this directory to 1,000 files. 334 entries were omitted from the list. Latest commit info may be omitted.
There's also some baggage related to the CORE-V Wally flow. Presently, we
list each test set individually in a file, so this involves adding thousand
of lines to the file. We print each set when it runs successfully, which
had been dozens and becomes thousands in the logs. Debug occasionally
involves scanning the logs, and this is more cumbersome when they explode
in size. None of this is showstoppers, but it affects our viewpoint.
As a simple heuristic, how about splitting the _b15 tests into 10 files
instead of 300, to get their runtime below _b1?
—
Reply to this email directly, view it on GitHub
<#461 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AHPXVJUA6TGKTJDAZU3XJ3DZBN5ZXAVCNFSM6AAAAABG2WO6MSVHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMZDCMBSG4YDSOBQGE>
.
You are receiving this because you modified the open/close state.Message
ID: ***@***.***>
|
The 2.1 GB memory is when compiling the test. I.e. when running GCC to turn the assembly into an ELF file. Seems reasonable that that would scale with the size of the test.
Yeah that is annoying to be fair. |
|
fmadd.d_b15-01.S/ref/ref.elf is 15 MB. Something still seems funny that it would take 2 GB of memory to produce a 15 MB executable. Even the Sail log fmadd.d_b15-01.log is 365 MB. I'm not disputing the hassle of this file being 10x longer to simulate than all the others, but I'm still postulating that a 10x split of _b15 might be sufficient, even if the tools have weird issues that consume excessive memory. |
|
I don't know what causes it, but I think I shouldn't have to care.
I just need a rule of thumb for how big a test can be in terms of bytes of
code, data, and signature -
but it can't be in terms of the amount of memory the compilation needs
unless that can be easily predicted from an examination of the source.
Emphasis on "easily".
…On Sat, May 11, 2024 at 7:34 PM David Harris ***@***.***> wrote:
fmadd.d_b15-01.S/ref/ref.elf is 15 MB. Something still seems funny that it
would take 2 GB of memory to produce a 15 MB executable. Even the Sail log
fmadd.d_b15-01.log is 365 MB.
I'm not disputing the hassle of this file being 10x longer to simulate
than all the others, but I'm still postulating that a 10x split of _b15
might be sufficient, even if the tools have weird issues that consume
excessive memory.
—
Reply to this email directly, view it on GitHub
<#461 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AHPXVJW4TJZEQYQPEOEYRVLZB3ILZAVCNFSM6AAAAABG2WO6MSVHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMZDCMBWGA4TKNJRGQ>
.
You are receiving this because you modified the open/close state.Message
ID: ***@***.***>
|
Description
List Extensions
Reference Model Used
Mandatory Checklist:
Optional Checklist: