kernel oops. #31
Comments
|
I can't find how to attach files here, so I'll have to host the file myself: http://prive.bitwizard.nl/DSC04643.JPG |
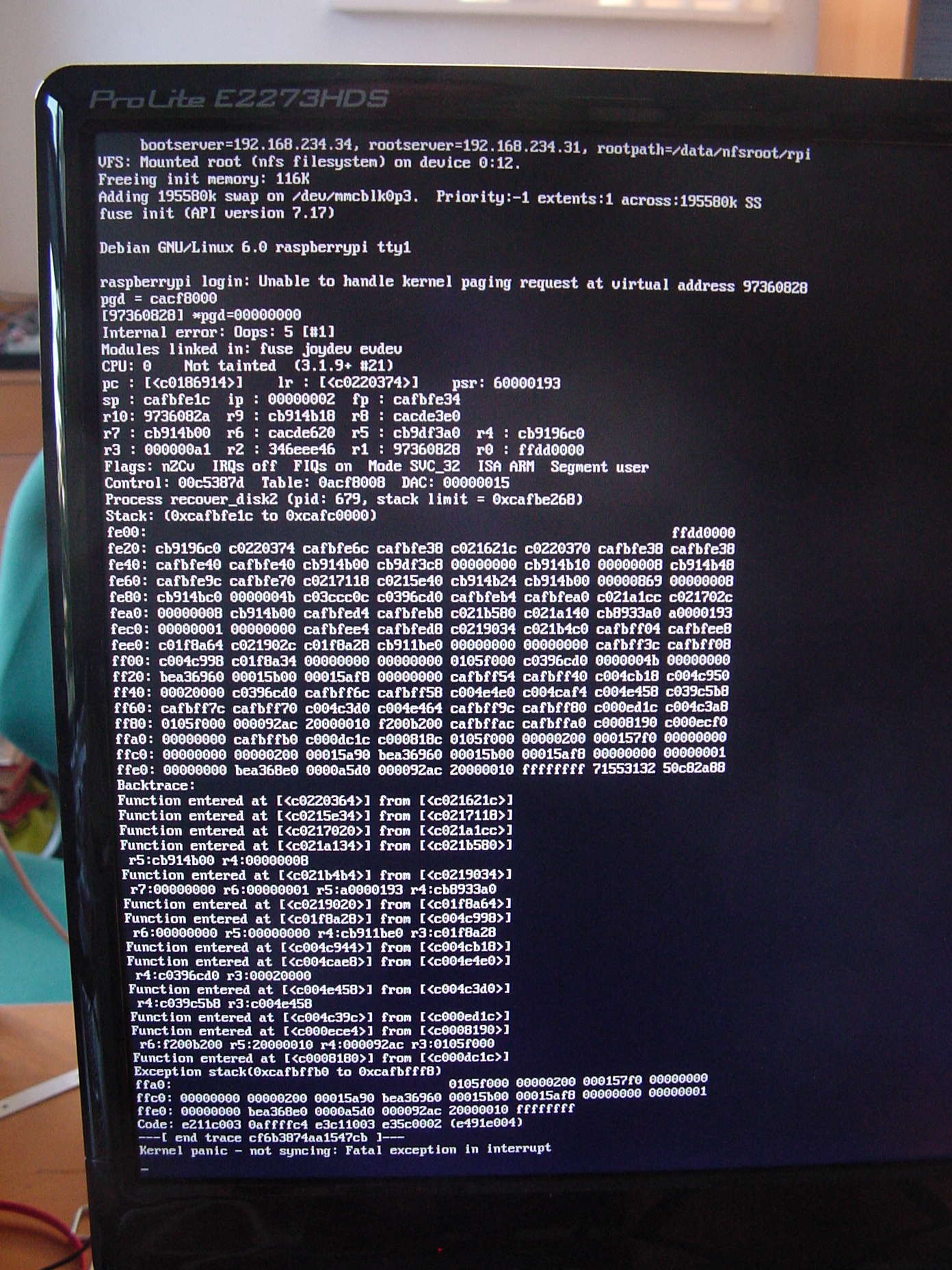{kind=link}
|
I checked my current copy of system.map. I did recompile the kernel adding a few modules, so I don't think the symbols moved, but I can't be sure. Crash occurred in memcpy (sounds reasonable). |
|
Can you reproduce this on latest 3.2.27 kernel? |
|
Closing since there's been no further investigation |
|
Sounds like a plan. It was hard for me to reproduce. I was hoping the report might fit into a pattern or something like that. |
popcornmix
pushed a commit
that referenced
this issue
Oct 13, 2012
Printing the "start_ip" for every secondary cpu is very noisy on a large system - and doesn't add any value. Drop this message. Console log before: Booting Node 0, Processors #1 smpboot cpu 1: start_ip = 96000 #2 smpboot cpu 2: start_ip = 96000 #3 smpboot cpu 3: start_ip = 96000 #4 smpboot cpu 4: start_ip = 96000 ... #31 smpboot cpu 31: start_ip = 96000 Brought up 32 CPUs Console log after: Booting Node 0, Processors #1 #2 #3 #4 #5 #6 #7 Ok. Booting Node 1, Processors #8 #9 #10 #11 #12 #13 #14 #15 Ok. Booting Node 0, Processors #16 #17 #18 #19 #20 #21 #22 #23 Ok. Booting Node 1, Processors #24 #25 #26 #27 #28 #29 #30 #31 Brought up 32 CPUs Acked-by: Borislav Petkov <[email protected]> Signed-off-by: Tony Luck <[email protected]> Link: http://lkml.kernel.org/r/[email protected] Signed-off-by: H. Peter Anvin <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Aug 4, 2014
Non-DT irq handlers were working through irq causes from most-significant to least-significant bit, while DT irqchip driver does it the other way round. This revealed some more HW issues on Kirkwood peripheral IP, where spurious sdio irqs can happen although irqs are masked. Also, the generated binaries show that original non-DT order compared to DT order save two instructions for each bit count check: irqchip DT order with ffs(): 60: e3a06001 mov r6, #1 64: e2643000 rsb r3, r4, #0 68: e0033004 and r3, r3, r4 6c: e16f3f13 clz r3, r3 70: e263301f rsb r3, r3, #31 74: e1c44316 bic r4, r4, r6, lsl r3 78: e5971004 ldr r1, [r7, #4] Original non-DT order with fls(): 60: e3a07001 mov r7, #1 64: e16f3f14 clz r3, r4 68: e263301f rsb r3, r3, #31 6c: e1c44317 bic r4, r4, r7, lsl r3 70: e5951004 ldr r1, [r5, #4] Therefore, reverse irq bit handling back to original order by replacing ffs() with fls(). Signed-off-by: Sebastian Hesselbarth <[email protected]> Link: https://lkml.kernel.org/r/1398719528-23607-1-git-send-email-sebastian.hesselbarth@gmail.com Acked-by: Jason Cooper <[email protected]> Signed-off-by: Jason Cooper <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Aug 4, 2014
Function rt2800usb_autorun_detect() passes the address of a variable allocated onto the stack to be used for DMA by the USB layer. This has been caught by my debugging-enabled kernel. This patch change things in order to allocate that variable via kmalloc, and it adjusts things to handle the kmalloc failure case, propagating the error. [ 7363.238852] ------------[ cut here ]------------ [ 7363.243529] WARNING: CPU: 1 PID: 5235 at lib/dma-debug.c:1153 check_for_stack+0xa4/0xf0() [ 7363.251759] ehci-pci 0000:00:04.1: DMA-API: device driver maps memory fromstack [addr=ffff88006b81bad4] [ 7363.261210] Modules linked in: rt2800usb(O+) rt2800lib(O) rt2x00usb(O) rt2x00lib(O) rtl818x_pci(O) rtl8187 led_class eeprom_93cx6 mac80211 cfg80211 [last unloaded: rt2x00lib] [ 7363.277143] CPU: 1 PID: 5235 Comm: systemd-udevd Tainted: G O 3.16.0-rc3-wl+ #31 [ 7363.285546] Hardware name: System manufacturer System Product Name/M3N78 PRO, BIOS ASUS M3N78 PRO ACPI BIOS Revision 1402 12/04/2009 [ 7363.297511] 0000000000000009 ffff88006b81b710 ffffffff8175dcad ffff88006b81b758 [ 7363.305062] ffff88006b81b748 ffffffff8106d372 ffff88006cf10098 ffff88006cead6a0 [ 7363.312622] ffff88006b81bad4 ffffffff81c1e7c0 ffff88006cf10098 ffff88006b81b7a8 [ 7363.320161] Call Trace: [ 7363.322661] [<ffffffff8175dcad>] dump_stack+0x4d/0x6f [ 7363.327847] [<ffffffff8106d372>] warn_slowpath_common+0x82/0xb0 [ 7363.333893] [<ffffffff8106d3e7>] warn_slowpath_fmt+0x47/0x50 [ 7363.339686] [<ffffffff813a93b4>] check_for_stack+0xa4/0xf0 [ 7363.345298] [<ffffffff813a995c>] debug_dma_map_page+0x10c/0x150 [ 7363.351367] [<ffffffff81521bd9>] usb_hcd_map_urb_for_dma+0x229/0x720 [ 7363.357890] [<ffffffff8152256d>] usb_hcd_submit_urb+0x2fd/0x930 [ 7363.363929] [<ffffffff810eac31>] ? irq_work_queue+0x71/0xd0 [ 7363.369617] [<ffffffff810ab5a7>] ? wake_up_klogd+0x37/0x50 [ 7363.375219] [<ffffffff810ab7a5>] ? console_unlock+0x1e5/0x420 [ 7363.381081] [<ffffffff810abc25>] ? vprintk_emit+0x245/0x530 [ 7363.386773] [<ffffffff81523d3c>] usb_submit_urb+0x30c/0x580 [ 7363.392462] [<ffffffff81524295>] usb_start_wait_urb+0x65/0xf0 [ 7363.398325] [<ffffffff815243ed>] usb_control_msg+0xcd/0x110 [ 7363.404014] [<ffffffffa005514d>] rt2x00usb_vendor_request+0xbd/0x170 [rt2x00usb] [ 7363.411544] [<ffffffffa0074292>] rt2800usb_autorun_detect+0x32/0x50 [rt2800usb] [ 7363.418986] [<ffffffffa0074aa1>] rt2800usb_read_eeprom+0x11/0x70 [rt2800usb] [ 7363.426168] [<ffffffffa0063ffd>] rt2800_probe_hw+0x11d/0xf90 [rt2800lib] [ 7363.432989] [<ffffffffa0074b7d>] rt2800usb_probe_hw+0xd/0x50 [rt2800usb] [ 7363.439808] [<ffffffffa00453d8>] rt2x00lib_probe_dev+0x238/0x7c0 [rt2x00lib] [ 7363.446992] [<ffffffffa00bfa48>] ? ieee80211_led_names+0xb8/0x100 [mac80211] [ 7363.454156] [<ffffffffa0056116>] rt2x00usb_probe+0x156/0x1f0 [rt2x00usb] [ 7363.460971] [<ffffffffa0074250>] rt2800usb_probe+0x10/0x20 [rt2800usb] [ 7363.467616] [<ffffffff8152799e>] usb_probe_interface+0xce/0x1c0 [ 7363.473651] [<ffffffff81480c20>] really_probe+0x70/0x240 [ 7363.479079] [<ffffffff81480f01>] __driver_attach+0xa1/0xb0 [ 7363.484682] [<ffffffff81480e60>] ? __device_attach+0x70/0x70 [ 7363.490461] [<ffffffff8147eef3>] bus_for_each_dev+0x63/0xa0 [ 7363.496146] [<ffffffff814807c9>] driver_attach+0x19/0x20 [ 7363.501570] [<ffffffff81480468>] bus_add_driver+0x178/0x220 [ 7363.507270] [<ffffffff8148151b>] driver_register+0x5b/0xe0 [ 7363.512874] [<ffffffff815271b0>] usb_register_driver+0xa0/0x170 [ 7363.518905] [<ffffffffa007a000>] ? 0xffffffffa0079fff [ 7363.524074] [<ffffffffa007a01e>] rt2800usb_driver_init+0x1e/0x20 [rt2800usb] [ 7363.531247] [<ffffffff810002d4>] do_one_initcall+0x84/0x1b0 [ 7363.536932] [<ffffffff8113aa60>] ? kfree+0xd0/0x110 [ 7363.541931] [<ffffffff8112730a>] ? __vunmap+0xaa/0xf0 [ 7363.547538] [<ffffffff810ca07e>] load_module+0x1aee/0x2040 [ 7363.553141] [<ffffffff810c6f10>] ? store_uevent+0x50/0x50 [ 7363.558676] [<ffffffff810ca66e>] SyS_init_module+0x9e/0xc0 [ 7363.564285] [<ffffffff81764012>] system_call_fastpath+0x16/0x1b [ 7363.570338] ---[ end trace 01ef5f822bea9882 ]--- Signed-off-by: Andrea Merello <[email protected]> Acked-by: Helmut Schaa <[email protected]> Signed-off-by: John W. Linville <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Jan 28, 2015
commit f89f46c upstream. If the userspace passes a malformed sched scan request (or a net detect wowlan configuration) by adding a NL80211_ATTR_SCHED_SCAN_MATCH attribute without any nested matchsets, a NULL pointer dereference will occur. Fix this by checking that we do have matchsets in our array before trying to access it. BUG: unable to handle kernel NULL pointer dereference at 0000000000000024 IP: [<ffffffffa002fd69>] nl80211_parse_sched_scan.part.67+0x6e9/0x900 [cfg80211] PGD 865c067 PUD 865b067 PMD 0 Oops: 0002 [#1] SMP Modules linked in: iwlmvm(O) iwlwifi(O) mac80211(O) cfg80211(O) compat(O) [last unloaded: compat] CPU: 2 PID: 2442 Comm: iw Tainted: G O 3.17.2 #31 Hardware name: Bochs Bochs, BIOS Bochs 01/01/2011 task: ffff880013800790 ti: ffff880008d80000 task.ti: ffff880008d80000 RIP: 0010:[<ffffffffa002fd69>] [<ffffffffa002fd69>] nl80211_parse_sched_scan.part.67+0x6e9/0x900 [cfg80211] RSP: 0018:ffff880008d838d0 EFLAGS: 00010293 RAX: 0000000000000000 RBX: 0000000000000000 RCX: 0000000000000000 RDX: 000000000000143c RSI: 0000000000000000 RDI: ffff880008ee8dd0 RBP: ffff880008d83948 R08: 0000000000000002 R09: 0000000000000019 R10: ffff88001d1b3c40 R11: 0000000000000002 R12: ffff880019e85e00 R13: 00000000fffffed4 R14: ffff880009757800 R15: 0000000000001388 FS: 00007fa3b6d13700(0000) GS:ffff88003e200000(0000) knlGS:0000000000000000 CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 CR2: 0000000000000024 CR3: 0000000008670000 CR4: 00000000000006e0 Stack: ffff880009757800 ffff880000000001 0000000000000000 ffff880008ee84e0 0000000000000000 ffff880009757800 00000000fffffed4 ffff880008d83948 ffffffff814689c9 ffff880009757800 ffff880008ee8000 0000000000000000 Call Trace: [<ffffffff814689c9>] ? nla_parse+0xb9/0x120 [<ffffffffa00306de>] nl80211_set_wowlan+0x75e/0x960 [cfg80211] [<ffffffff810bf3d5>] ? mark_held_locks+0x75/0xa0 [<ffffffff8161a77b>] genl_family_rcv_msg+0x18b/0x360 [<ffffffff810bf66d>] ? trace_hardirqs_on+0xd/0x10 [<ffffffff8161a9d4>] genl_rcv_msg+0x84/0xc0 [<ffffffff8161a950>] ? genl_family_rcv_msg+0x360/0x360 [<ffffffff81618e79>] netlink_rcv_skb+0xa9/0xd0 [<ffffffff81619458>] genl_rcv+0x28/0x40 [<ffffffff816184a5>] netlink_unicast+0x105/0x180 [<ffffffff8161886f>] netlink_sendmsg+0x34f/0x7a0 [<ffffffff8105a097>] ? kvm_clock_read+0x27/0x40 [<ffffffff815c644d>] sock_sendmsg+0x8d/0xc0 [<ffffffff811a75c9>] ? might_fault+0xb9/0xc0 [<ffffffff811a756e>] ? might_fault+0x5e/0xc0 [<ffffffff815d5d26>] ? verify_iovec+0x56/0xe0 [<ffffffff815c73e0>] ___sys_sendmsg+0x3d0/0x3e0 [<ffffffff810a7be8>] ? sched_clock_cpu+0x98/0xd0 [<ffffffff810611b4>] ? __do_page_fault+0x254/0x580 [<ffffffff810bb39f>] ? up_read+0x1f/0x40 [<ffffffff810611b4>] ? __do_page_fault+0x254/0x580 [<ffffffff812146ed>] ? __fget_light+0x13d/0x160 [<ffffffff815c7b02>] __sys_sendmsg+0x42/0x80 [<ffffffff815c7b52>] SyS_sendmsg+0x12/0x20 [<ffffffff81751f69>] system_call_fastpath+0x16/0x1b Fixes: ea73cbc ("nl80211: fix scheduled scan RSSI matchset attribute confusion") Signed-off-by: Luciano Coelho <[email protected]> Signed-off-by: Johannes Berg <[email protected]> Signed-off-by: Greg Kroah-Hartman <[email protected]>
davet321
pushed a commit
to davet321/rpi-linux
that referenced
this issue
Aug 17, 2015
commit ecf5fc6 upstream. Nikolay has reported a hang when a memcg reclaim got stuck with the following backtrace: PID: 18308 TASK: ffff883d7c9b0a30 CPU: 1 COMMAND: "rsync" #0 __schedule at ffffffff815ab152 raspberrypi#1 schedule at ffffffff815ab76e raspberrypi#2 schedule_timeout at ffffffff815ae5e5 raspberrypi#3 io_schedule_timeout at ffffffff815aad6a raspberrypi#4 bit_wait_io at ffffffff815abfc6 raspberrypi#5 __wait_on_bit at ffffffff815abda5 raspberrypi#6 wait_on_page_bit at ffffffff8111fd4f raspberrypi#7 shrink_page_list at ffffffff81135445 raspberrypi#8 shrink_inactive_list at ffffffff81135845 raspberrypi#9 shrink_lruvec at ffffffff81135ead raspberrypi#10 shrink_zone at ffffffff811360c3 raspberrypi#11 shrink_zones at ffffffff81136eff raspberrypi#12 do_try_to_free_pages at ffffffff8113712f raspberrypi#13 try_to_free_mem_cgroup_pages at ffffffff811372be raspberrypi#14 try_charge at ffffffff81189423 raspberrypi#15 mem_cgroup_try_charge at ffffffff8118c6f5 raspberrypi#16 __add_to_page_cache_locked at ffffffff8112137d raspberrypi#17 add_to_page_cache_lru at ffffffff81121618 raspberrypi#18 pagecache_get_page at ffffffff8112170b raspberrypi#19 grow_dev_page at ffffffff811c8297 raspberrypi#20 __getblk_slow at ffffffff811c91d6 raspberrypi#21 __getblk_gfp at ffffffff811c92c1 raspberrypi#22 ext4_ext_grow_indepth at ffffffff8124565c raspberrypi#23 ext4_ext_create_new_leaf at ffffffff81246ca8 raspberrypi#24 ext4_ext_insert_extent at ffffffff81246f09 raspberrypi#25 ext4_ext_map_blocks at ffffffff8124a848 raspberrypi#26 ext4_map_blocks at ffffffff8121a5b7 raspberrypi#27 mpage_map_one_extent at ffffffff8121b1fa raspberrypi#28 mpage_map_and_submit_extent at ffffffff8121f07b raspberrypi#29 ext4_writepages at ffffffff8121f6d5 raspberrypi#30 do_writepages at ffffffff8112c490 raspberrypi#31 __filemap_fdatawrite_range at ffffffff81120199 raspberrypi#32 filemap_flush at ffffffff8112041c raspberrypi#33 ext4_alloc_da_blocks at ffffffff81219da1 raspberrypi#34 ext4_rename at ffffffff81229b91 raspberrypi#35 ext4_rename2 at ffffffff81229e32 raspberrypi#36 vfs_rename at ffffffff811a08a5 raspberrypi#37 SYSC_renameat2 at ffffffff811a3ffc raspberrypi#38 sys_renameat2 at ffffffff811a408e raspberrypi#39 sys_rename at ffffffff8119e51e raspberrypi#40 system_call_fastpath at ffffffff815afa89 Dave Chinner has properly pointed out that this is a deadlock in the reclaim code because ext4 doesn't submit pages which are marked by PG_writeback right away. The heuristic was introduced by commit e62e384 ("memcg: prevent OOM with too many dirty pages") and it was applied only when may_enter_fs was specified. The code has been changed by c3b94f4 ("memcg: further prevent OOM with too many dirty pages") which has removed the __GFP_FS restriction with a reasoning that we do not get into the fs code. But this is not sufficient apparently because the fs doesn't necessarily submit pages marked PG_writeback for IO right away. ext4_bio_write_page calls io_submit_add_bh but that doesn't necessarily submit the bio. Instead it tries to map more pages into the bio and mpage_map_one_extent might trigger memcg charge which might end up waiting on a page which is marked PG_writeback but hasn't been submitted yet so we would end up waiting for something that never finishes. Fix this issue by replacing __GFP_IO by may_enter_fs check (for case 2) before we go to wait on the writeback. The page fault path, which is the only path that triggers memcg oom killer since 3.12, shouldn't require GFP_NOFS and so we shouldn't reintroduce the premature OOM killer issue which was originally addressed by the heuristic. As per David Chinner the xfs is doing similar thing since 2.6.15 already so ext4 is not the only affected filesystem. Moreover he notes: : For example: IO completion might require unwritten extent conversion : which executes filesystem transactions and GFP_NOFS allocations. The : writeback flag on the pages can not be cleared until unwritten : extent conversion completes. Hence memory reclaim cannot wait on : page writeback to complete in GFP_NOFS context because it is not : safe to do so, memcg reclaim or otherwise. Cc: [email protected] # 3.9+ [[email protected]: corrected the control flow] Fixes: c3b94f4 ("memcg: further prevent OOM with too many dirty pages") Reported-by: Nikolay Borisov <[email protected]> Signed-off-by: Michal Hocko <[email protected]> Signed-off-by: Hugh Dickins <[email protected]> Signed-off-by: Linus Torvalds <[email protected]> Signed-off-by: Greg Kroah-Hartman <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Aug 20, 2015
Nikolay has reported a hang when a memcg reclaim got stuck with the following backtrace: PID: 18308 TASK: ffff883d7c9b0a30 CPU: 1 COMMAND: "rsync" #0 __schedule at ffffffff815ab152 #1 schedule at ffffffff815ab76e #2 schedule_timeout at ffffffff815ae5e5 #3 io_schedule_timeout at ffffffff815aad6a #4 bit_wait_io at ffffffff815abfc6 #5 __wait_on_bit at ffffffff815abda5 #6 wait_on_page_bit at ffffffff8111fd4f #7 shrink_page_list at ffffffff81135445 #8 shrink_inactive_list at ffffffff81135845 #9 shrink_lruvec at ffffffff81135ead #10 shrink_zone at ffffffff811360c3 #11 shrink_zones at ffffffff81136eff #12 do_try_to_free_pages at ffffffff8113712f #13 try_to_free_mem_cgroup_pages at ffffffff811372be #14 try_charge at ffffffff81189423 #15 mem_cgroup_try_charge at ffffffff8118c6f5 #16 __add_to_page_cache_locked at ffffffff8112137d #17 add_to_page_cache_lru at ffffffff81121618 #18 pagecache_get_page at ffffffff8112170b #19 grow_dev_page at ffffffff811c8297 #20 __getblk_slow at ffffffff811c91d6 #21 __getblk_gfp at ffffffff811c92c1 #22 ext4_ext_grow_indepth at ffffffff8124565c #23 ext4_ext_create_new_leaf at ffffffff81246ca8 #24 ext4_ext_insert_extent at ffffffff81246f09 #25 ext4_ext_map_blocks at ffffffff8124a848 #26 ext4_map_blocks at ffffffff8121a5b7 #27 mpage_map_one_extent at ffffffff8121b1fa #28 mpage_map_and_submit_extent at ffffffff8121f07b #29 ext4_writepages at ffffffff8121f6d5 #30 do_writepages at ffffffff8112c490 #31 __filemap_fdatawrite_range at ffffffff81120199 #32 filemap_flush at ffffffff8112041c #33 ext4_alloc_da_blocks at ffffffff81219da1 #34 ext4_rename at ffffffff81229b91 #35 ext4_rename2 at ffffffff81229e32 #36 vfs_rename at ffffffff811a08a5 #37 SYSC_renameat2 at ffffffff811a3ffc #38 sys_renameat2 at ffffffff811a408e #39 sys_rename at ffffffff8119e51e #40 system_call_fastpath at ffffffff815afa89 Dave Chinner has properly pointed out that this is a deadlock in the reclaim code because ext4 doesn't submit pages which are marked by PG_writeback right away. The heuristic was introduced by commit e62e384 ("memcg: prevent OOM with too many dirty pages") and it was applied only when may_enter_fs was specified. The code has been changed by c3b94f4 ("memcg: further prevent OOM with too many dirty pages") which has removed the __GFP_FS restriction with a reasoning that we do not get into the fs code. But this is not sufficient apparently because the fs doesn't necessarily submit pages marked PG_writeback for IO right away. ext4_bio_write_page calls io_submit_add_bh but that doesn't necessarily submit the bio. Instead it tries to map more pages into the bio and mpage_map_one_extent might trigger memcg charge which might end up waiting on a page which is marked PG_writeback but hasn't been submitted yet so we would end up waiting for something that never finishes. Fix this issue by replacing __GFP_IO by may_enter_fs check (for case 2) before we go to wait on the writeback. The page fault path, which is the only path that triggers memcg oom killer since 3.12, shouldn't require GFP_NOFS and so we shouldn't reintroduce the premature OOM killer issue which was originally addressed by the heuristic. As per David Chinner the xfs is doing similar thing since 2.6.15 already so ext4 is not the only affected filesystem. Moreover he notes: : For example: IO completion might require unwritten extent conversion : which executes filesystem transactions and GFP_NOFS allocations. The : writeback flag on the pages can not be cleared until unwritten : extent conversion completes. Hence memory reclaim cannot wait on : page writeback to complete in GFP_NOFS context because it is not : safe to do so, memcg reclaim or otherwise. Cc: [email protected] # 3.9+ [[email protected]: corrected the control flow] Fixes: c3b94f4 ("memcg: further prevent OOM with too many dirty pages") Reported-by: Nikolay Borisov <[email protected]> Signed-off-by: Michal Hocko <[email protected]> Signed-off-by: Hugh Dickins <[email protected]> Signed-off-by: Linus Torvalds <[email protected]>
anholt
referenced
this issue
in anholt/linux
Oct 12, 2015
The following call trace is seen when generic/095 test is executed, WARNING: CPU: 3 PID: 2769 at /home/chandan/code/repos/linux/fs/btrfs/inode.c:8967 btrfs_destroy_inode+0x284/0x2a0() Modules linked in: CPU: 3 PID: 2769 Comm: umount Not tainted 4.2.0-rc5+ #31 Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS 1.7.5-20150306_163512-brownie 04/01/2014 ffffffff81c08150 ffff8802ec9cbce8 ffffffff81984058 ffff8802ffd8feb0 0000000000000000 ffff8802ec9cbd28 ffffffff81050385 ffff8802ec9cbd38 ffff8802d12f8588 ffff8802d12f8588 ffff8802f15ab000 ffff8800bb96c0b0 Call Trace: [<ffffffff81984058>] dump_stack+0x45/0x57 [<ffffffff81050385>] warn_slowpath_common+0x85/0xc0 [<ffffffff81050465>] warn_slowpath_null+0x15/0x20 [<ffffffff81340294>] btrfs_destroy_inode+0x284/0x2a0 [<ffffffff8117ce07>] destroy_inode+0x37/0x60 [<ffffffff8117cf39>] evict+0x109/0x170 [<ffffffff8117cfd5>] dispose_list+0x35/0x50 [<ffffffff8117dd3a>] evict_inodes+0xaa/0x100 [<ffffffff81165667>] generic_shutdown_super+0x47/0xf0 [<ffffffff81165951>] kill_anon_super+0x11/0x20 [<ffffffff81302093>] btrfs_kill_super+0x13/0x110 [<ffffffff81165c99>] deactivate_locked_super+0x39/0x70 [<ffffffff811660cf>] deactivate_super+0x5f/0x70 [<ffffffff81180e1e>] cleanup_mnt+0x3e/0x90 [<ffffffff81180ebd>] __cleanup_mnt+0xd/0x10 [<ffffffff81069c06>] task_work_run+0x96/0xb0 [<ffffffff81003a3d>] do_notify_resume+0x3d/0x50 [<ffffffff8198cbc2>] int_signal+0x12/0x17 This means that the inode had non-zero "outstanding extents" during eviction. This occurs because, during direct I/O a task which successfully used up its reserved data space would set BTRFS_INODE_DIO_READY bit and does not clear the bit after finishing the DIO write. A future DIO write could actually fail and the unused reserve space won't be freed because of the previously set BTRFS_INODE_DIO_READY bit. Clearing the BTRFS_INODE_DIO_READY bit in btrfs_direct_IO() caused the following issue, |-----------------------------------+-------------------------------------| | Task A | Task B | |-----------------------------------+-------------------------------------| | Start direct i/o write on inode X.| | | reserve space | | | Allocate ordered extent | | | release reserved space | | | Set BTRFS_INODE_DIO_READY bit. | | | | splice() | | | Transfer data from pipe buffer to | | | destination file. | | | - kmap(pipe buffer page) | | | - Start direct i/o write on | | | inode X. | | | - reserve space | | | - dio_refill_pages() | | | - sdio->blocks_available == 0 | | | - Since a kernel address is | | | being passed instead of a | | | user space address, | | | iov_iter_get_pages() returns | | | -EFAULT. | | | - Since BTRFS_INODE_DIO_READY is | | | set, we don't release reserved | | | space. | | | - Clear BTRFS_INODE_DIO_READY bit.| | -EIOCBQUEUED is returned. | | |-----------------------------------+-------------------------------------| Hence this commit introduces "struct btrfs_dio_data" to track the usage of reserved data space. The remaining unused "reserve space" can now be freed reliably. Signed-off-by: Chandan Rajendra <[email protected]> Reviewed-by: Liu Bo <[email protected]> Signed-off-by: Chris Mason <[email protected]>
davet321
pushed a commit
to davet321/rpi-linux
that referenced
this issue
May 16, 2016
------------[ cut here ]------------ WARNING: CPU: 0 PID: 16 at kernel/workqueue.c:4559 rebind_workers+0x1c0/0x1d0 Modules linked in: CPU: 0 PID: 16 Comm: cpuhp/0 Not tainted 4.6.0-rc4+ raspberrypi#31 Hardware name: IBM IBM System x3550 M4 Server -[7914IUW]-/00Y8603, BIOS -[D7E128FUS-1.40]- 07/23/2013 0000000000000000 ffff881037babb58 ffffffff8139d885 0000000000000010 0000000000000000 0000000000000000 0000000000000000 ffff881037babba8 ffffffff8108505d ffff881037ba0000 000011cf3e7d6e60 0000000000000046 Call Trace: dump_stack+0x89/0xd4 __warn+0xfd/0x120 warn_slowpath_null+0x1d/0x20 rebind_workers+0x1c0/0x1d0 workqueue_cpu_up_callback+0xf5/0x1d0 notifier_call_chain+0x64/0x90 ? trace_hardirqs_on_caller+0xf2/0x220 ? notify_prepare+0x80/0x80 __raw_notifier_call_chain+0xe/0x10 __cpu_notify+0x35/0x50 notify_down_prepare+0x5e/0x80 ? notify_prepare+0x80/0x80 cpuhp_invoke_callback+0x73/0x330 ? __schedule+0x33e/0x8a0 cpuhp_down_callbacks+0x51/0xc0 cpuhp_thread_fun+0xc1/0xf0 smpboot_thread_fn+0x159/0x2a0 ? smpboot_create_threads+0x80/0x80 kthread+0xef/0x110 ? wait_for_completion+0xf0/0x120 ? schedule_tail+0x35/0xf0 ret_from_fork+0x22/0x50 ? __init_kthread_worker+0x70/0x70 ---[ end trace eb12ae47d2382d8f ]--- notify_down_prepare: attempt to take down CPU 0 failed This bug can be reproduced by below config w/ nohz_full= all cpus: CONFIG_BOOTPARAM_HOTPLUG_CPU0=y CONFIG_DEBUG_HOTPLUG_CPU0=y CONFIG_NO_HZ_FULL=y As Thomas pointed out: | If a down prepare callback fails, then DOWN_FAILED is invoked for all | callbacks which have successfully executed DOWN_PREPARE. | | But, workqueue has actually two notifiers. One which handles | UP/DOWN_FAILED/ONLINE and one which handles DOWN_PREPARE. | | Now look at the priorities of those callbacks: | | CPU_PRI_WORKQUEUE_UP = 5 | CPU_PRI_WORKQUEUE_DOWN = -5 | | So the call order on DOWN_PREPARE is: | | CB 1 | CB ... | CB workqueue_up() -> Ignores DOWN_PREPARE | CB ... | CB X ---> Fails | | So we call up to CB X with DOWN_FAILED | | CB 1 | CB ... | CB workqueue_up() -> Handles DOWN_FAILED | CB ... | CB X-1 | | So the problem is that the workqueue stuff handles DOWN_FAILED in the up | callback, while it should do it in the down callback. Which is not a good idea | either because it wants to be called early on rollback... | | Brilliant stuff, isn't it? The hotplug rework will solve this problem because | the callbacks become symetric, but for the existing mess, we need some | workaround in the workqueue code. The boot CPU handles housekeeping duty(unbound timers, workqueues, timekeeping, ...) on behalf of full dynticks CPUs. It must remain online when nohz full is enabled. There is a priority set to every notifier_blocks: workqueue_cpu_up > tick_nohz_cpu_down > workqueue_cpu_down So tick_nohz_cpu_down callback failed when down prepare cpu 0, and notifier_blocks behind tick_nohz_cpu_down will not be called any more, which leads to workers are actually not unbound. Then hotplug state machine will fallback to undo and online cpu 0 again. Workers will be rebound unconditionally even if they are not unbound and trigger the warning in this progress. This patch fix it by catching !DISASSOCIATED to avoid rebind bound workers. Cc: Tejun Heo <[email protected]> Cc: Lai Jiangshan <[email protected]> Cc: Thomas Gleixner <[email protected]> Cc: Peter Zijlstra <[email protected]> Cc: Frédéric Weisbecker <[email protected]> Cc: [email protected] Suggested-by: Lai Jiangshan <[email protected]> Signed-off-by: Wanpeng Li <[email protected]>
davet321
pushed a commit
to davet321/rpi-linux
that referenced
this issue
May 16, 2016
Original implementation commit e54bcde ("arm64: eBPF JIT compiler") had the relevant code paths, but due to an oversight always fail jiting. As a result, we had been falling back to BPF interpreter whenever a BPF program has JMP_JSET_{X,K} instructions. With this fix, we confirm that the corresponding tests in lib/test_bpf continue to pass, and also jited. ... [ 2.784553] test_bpf: raspberrypi#30 JSET jited:1 188 192 197 PASS [ 2.791373] test_bpf: raspberrypi#31 tcpdump port 22 jited:1 325 677 625 PASS [ 2.808800] test_bpf: raspberrypi#32 tcpdump complex jited:1 323 731 991 PASS ... [ 3.190759] test_bpf: raspberrypi#237 JMP_JSET_K: if (0x3 & 0x2) return 1 jited:1 110 PASS [ 3.192524] test_bpf: raspberrypi#238 JMP_JSET_K: if (0x3 & 0xffffffff) return 1 jited:1 98 PASS [ 3.211014] test_bpf: raspberrypi#249 JMP_JSET_X: if (0x3 & 0x2) return 1 jited:1 120 PASS [ 3.212973] test_bpf: raspberrypi#250 JMP_JSET_X: if (0x3 & 0xffffffff) return 1 jited:1 89 PASS ... Fixes: e54bcde ("arm64: eBPF JIT compiler") Signed-off-by: Zi Shen Lim <[email protected]> Acked-by: Will Deacon <[email protected]> Acked-by: Yang Shi <[email protected]> Signed-off-by: David S. Miller <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
May 19, 2016
commit f7c17d2 upstream. ------------[ cut here ]------------ WARNING: CPU: 0 PID: 16 at kernel/workqueue.c:4559 rebind_workers+0x1c0/0x1d0 Modules linked in: CPU: 0 PID: 16 Comm: cpuhp/0 Not tainted 4.6.0-rc4+ #31 Hardware name: IBM IBM System x3550 M4 Server -[7914IUW]-/00Y8603, BIOS -[D7E128FUS-1.40]- 07/23/2013 0000000000000000 ffff881037babb58 ffffffff8139d885 0000000000000010 0000000000000000 0000000000000000 0000000000000000 ffff881037babba8 ffffffff8108505d ffff881037ba0000 000011cf3e7d6e60 0000000000000046 Call Trace: dump_stack+0x89/0xd4 __warn+0xfd/0x120 warn_slowpath_null+0x1d/0x20 rebind_workers+0x1c0/0x1d0 workqueue_cpu_up_callback+0xf5/0x1d0 notifier_call_chain+0x64/0x90 ? trace_hardirqs_on_caller+0xf2/0x220 ? notify_prepare+0x80/0x80 __raw_notifier_call_chain+0xe/0x10 __cpu_notify+0x35/0x50 notify_down_prepare+0x5e/0x80 ? notify_prepare+0x80/0x80 cpuhp_invoke_callback+0x73/0x330 ? __schedule+0x33e/0x8a0 cpuhp_down_callbacks+0x51/0xc0 cpuhp_thread_fun+0xc1/0xf0 smpboot_thread_fn+0x159/0x2a0 ? smpboot_create_threads+0x80/0x80 kthread+0xef/0x110 ? wait_for_completion+0xf0/0x120 ? schedule_tail+0x35/0xf0 ret_from_fork+0x22/0x50 ? __init_kthread_worker+0x70/0x70 ---[ end trace eb12ae47d2382d8f ]--- notify_down_prepare: attempt to take down CPU 0 failed This bug can be reproduced by below config w/ nohz_full= all cpus: CONFIG_BOOTPARAM_HOTPLUG_CPU0=y CONFIG_DEBUG_HOTPLUG_CPU0=y CONFIG_NO_HZ_FULL=y As Thomas pointed out: | If a down prepare callback fails, then DOWN_FAILED is invoked for all | callbacks which have successfully executed DOWN_PREPARE. | | But, workqueue has actually two notifiers. One which handles | UP/DOWN_FAILED/ONLINE and one which handles DOWN_PREPARE. | | Now look at the priorities of those callbacks: | | CPU_PRI_WORKQUEUE_UP = 5 | CPU_PRI_WORKQUEUE_DOWN = -5 | | So the call order on DOWN_PREPARE is: | | CB 1 | CB ... | CB workqueue_up() -> Ignores DOWN_PREPARE | CB ... | CB X ---> Fails | | So we call up to CB X with DOWN_FAILED | | CB 1 | CB ... | CB workqueue_up() -> Handles DOWN_FAILED | CB ... | CB X-1 | | So the problem is that the workqueue stuff handles DOWN_FAILED in the up | callback, while it should do it in the down callback. Which is not a good idea | either because it wants to be called early on rollback... | | Brilliant stuff, isn't it? The hotplug rework will solve this problem because | the callbacks become symetric, but for the existing mess, we need some | workaround in the workqueue code. The boot CPU handles housekeeping duty(unbound timers, workqueues, timekeeping, ...) on behalf of full dynticks CPUs. It must remain online when nohz full is enabled. There is a priority set to every notifier_blocks: workqueue_cpu_up > tick_nohz_cpu_down > workqueue_cpu_down So tick_nohz_cpu_down callback failed when down prepare cpu 0, and notifier_blocks behind tick_nohz_cpu_down will not be called any more, which leads to workers are actually not unbound. Then hotplug state machine will fallback to undo and online cpu 0 again. Workers will be rebound unconditionally even if they are not unbound and trigger the warning in this progress. This patch fix it by catching !DISASSOCIATED to avoid rebind bound workers. Cc: Tejun Heo <[email protected]> Cc: Lai Jiangshan <[email protected]> Cc: Thomas Gleixner <[email protected]> Cc: Peter Zijlstra <[email protected]> Cc: Frédéric Weisbecker <[email protected]> Suggested-by: Lai Jiangshan <[email protected]> Signed-off-by: Wanpeng Li <[email protected]> Signed-off-by: Greg Kroah-Hartman <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
May 19, 2016
commit f7c17d2 upstream. ------------[ cut here ]------------ WARNING: CPU: 0 PID: 16 at kernel/workqueue.c:4559 rebind_workers+0x1c0/0x1d0 Modules linked in: CPU: 0 PID: 16 Comm: cpuhp/0 Not tainted 4.6.0-rc4+ #31 Hardware name: IBM IBM System x3550 M4 Server -[7914IUW]-/00Y8603, BIOS -[D7E128FUS-1.40]- 07/23/2013 0000000000000000 ffff881037babb58 ffffffff8139d885 0000000000000010 0000000000000000 0000000000000000 0000000000000000 ffff881037babba8 ffffffff8108505d ffff881037ba0000 000011cf3e7d6e60 0000000000000046 Call Trace: dump_stack+0x89/0xd4 __warn+0xfd/0x120 warn_slowpath_null+0x1d/0x20 rebind_workers+0x1c0/0x1d0 workqueue_cpu_up_callback+0xf5/0x1d0 notifier_call_chain+0x64/0x90 ? trace_hardirqs_on_caller+0xf2/0x220 ? notify_prepare+0x80/0x80 __raw_notifier_call_chain+0xe/0x10 __cpu_notify+0x35/0x50 notify_down_prepare+0x5e/0x80 ? notify_prepare+0x80/0x80 cpuhp_invoke_callback+0x73/0x330 ? __schedule+0x33e/0x8a0 cpuhp_down_callbacks+0x51/0xc0 cpuhp_thread_fun+0xc1/0xf0 smpboot_thread_fn+0x159/0x2a0 ? smpboot_create_threads+0x80/0x80 kthread+0xef/0x110 ? wait_for_completion+0xf0/0x120 ? schedule_tail+0x35/0xf0 ret_from_fork+0x22/0x50 ? __init_kthread_worker+0x70/0x70 ---[ end trace eb12ae47d2382d8f ]--- notify_down_prepare: attempt to take down CPU 0 failed This bug can be reproduced by below config w/ nohz_full= all cpus: CONFIG_BOOTPARAM_HOTPLUG_CPU0=y CONFIG_DEBUG_HOTPLUG_CPU0=y CONFIG_NO_HZ_FULL=y As Thomas pointed out: | If a down prepare callback fails, then DOWN_FAILED is invoked for all | callbacks which have successfully executed DOWN_PREPARE. | | But, workqueue has actually two notifiers. One which handles | UP/DOWN_FAILED/ONLINE and one which handles DOWN_PREPARE. | | Now look at the priorities of those callbacks: | | CPU_PRI_WORKQUEUE_UP = 5 | CPU_PRI_WORKQUEUE_DOWN = -5 | | So the call order on DOWN_PREPARE is: | | CB 1 | CB ... | CB workqueue_up() -> Ignores DOWN_PREPARE | CB ... | CB X ---> Fails | | So we call up to CB X with DOWN_FAILED | | CB 1 | CB ... | CB workqueue_up() -> Handles DOWN_FAILED | CB ... | CB X-1 | | So the problem is that the workqueue stuff handles DOWN_FAILED in the up | callback, while it should do it in the down callback. Which is not a good idea | either because it wants to be called early on rollback... | | Brilliant stuff, isn't it? The hotplug rework will solve this problem because | the callbacks become symetric, but for the existing mess, we need some | workaround in the workqueue code. The boot CPU handles housekeeping duty(unbound timers, workqueues, timekeeping, ...) on behalf of full dynticks CPUs. It must remain online when nohz full is enabled. There is a priority set to every notifier_blocks: workqueue_cpu_up > tick_nohz_cpu_down > workqueue_cpu_down So tick_nohz_cpu_down callback failed when down prepare cpu 0, and notifier_blocks behind tick_nohz_cpu_down will not be called any more, which leads to workers are actually not unbound. Then hotplug state machine will fallback to undo and online cpu 0 again. Workers will be rebound unconditionally even if they are not unbound and trigger the warning in this progress. This patch fix it by catching !DISASSOCIATED to avoid rebind bound workers. Cc: Tejun Heo <[email protected]> Cc: Lai Jiangshan <[email protected]> Cc: Thomas Gleixner <[email protected]> Cc: Peter Zijlstra <[email protected]> Cc: Frédéric Weisbecker <[email protected]> Suggested-by: Lai Jiangshan <[email protected]> Signed-off-by: Wanpeng Li <[email protected]> Signed-off-by: Greg Kroah-Hartman <[email protected]>
davet321
pushed a commit
to davet321/rpi-linux
that referenced
this issue
Jun 8, 2016
commit 7ccca1d upstream. Fix possible out of bounds read, by adding missing comma. The code may read pass the end of the dsi_errors array when the most significant bit (bit raspberrypi#31) in the intr_stat register is set. This bug has been detected using CppCheck (static analysis tool). Signed-off-by: Itai Handler <[email protected]> Signed-off-by: Patrik Jakobsson <[email protected]> Signed-off-by: Greg Kroah-Hartman <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Jun 8, 2016
commit 7ccca1d upstream. Fix possible out of bounds read, by adding missing comma. The code may read pass the end of the dsi_errors array when the most significant bit (bit #31) in the intr_stat register is set. This bug has been detected using CppCheck (static analysis tool). Signed-off-by: Itai Handler <[email protected]> Signed-off-by: Patrik Jakobsson <[email protected]> Signed-off-by: Greg Kroah-Hartman <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Jun 8, 2016
commit 7ccca1d upstream. Fix possible out of bounds read, by adding missing comma. The code may read pass the end of the dsi_errors array when the most significant bit (bit #31) in the intr_stat register is set. This bug has been detected using CppCheck (static analysis tool). Signed-off-by: Itai Handler <[email protected]> Signed-off-by: Patrik Jakobsson <[email protected]> Signed-off-by: Greg Kroah-Hartman <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Jan 8, 2018
This resolves a crash if loaded under qemu + haxm under windows. See https://www.spinics.net/lists/kernel/msg2689835.html for details. Here is a boot log (the log is from chromeos-4.4, but Tao Wu says that the same log is also seen with vanilla v4.4.110-rc1). [ 0.712750] Freeing unused kernel memory: 552K [ 0.721821] init: Corrupted page table at address 57b029b332e0 [ 0.722761] PGD 80000000bb238067 PUD bc36a067 PMD bc369067 PTE 45d2067 [ 0.722761] Bad pagetable: 000b [#1] PREEMPT SMP [ 0.722761] Modules linked in: [ 0.722761] CPU: 1 PID: 1 Comm: init Not tainted 4.4.96 #31 [ 0.722761] Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS rel-1.7.5.1-0-g8936dbb-20141113_115728-nilsson.home.kraxel.org 04/01/2014 [ 0.722761] task: ffff8800bc290000 ti: ffff8800bc28c000 task.ti: ffff8800bc28c000 [ 0.722761] RIP: 0010:[<ffffffff83f4129e>] [<ffffffff83f4129e>] __clear_user+0x42/0x67 [ 0.722761] RSP: 0000:ffff8800bc28fcf8 EFLAGS: 00010202 [ 0.722761] RAX: 0000000000000000 RBX: 00000000000001a4 RCX: 00000000000001a4 [ 0.722761] RDX: 0000000000000000 RSI: 0000000000000008 RDI: 000057b029b332e0 [ 0.722761] RBP: ffff8800bc28fd08 R08: ffff8800bc290000 R09: ffff8800bb2f4000 [ 0.722761] R10: ffff8800bc290000 R11: ffff8800bb2f4000 R12: 000057b029b332e0 [ 0.722761] R13: 0000000000000000 R14: 000057b029b33340 R15: ffff8800bb1e2a00 [ 0.722761] FS: 0000000000000000(0000) GS:ffff8800bfb00000(0000) knlGS:0000000000000000 [ 0.722761] CS: 0010 DS: 0000 ES: 0000 CR0: 000000008005003b [ 0.722761] CR2: 000057b029b332e0 CR3: 00000000bb2f8000 CR4: 00000000000006e0 [ 0.722761] Stack: [ 0.722761] 000057b029b332e0 ffff8800bb95fa80 ffff8800bc28fd18 ffffffff83f4120c [ 0.722761] ffff8800bc28fe18 ffffffff83e9e7a1 ffff8800bc28fd68 0000000000000000 [ 0.722761] ffff8800bc290000 ffff8800bc290000 ffff8800bc290000 ffff8800bc290000 [ 0.722761] Call Trace: [ 0.722761] [<ffffffff83f4120c>] clear_user+0x2e/0x30 [ 0.722761] [<ffffffff83e9e7a1>] load_elf_binary+0xa7f/0x18f7 [ 0.722761] [<ffffffff83de2088>] search_binary_handler+0x86/0x19c [ 0.722761] [<ffffffff83de389e>] do_execveat_common.isra.26+0x909/0xf98 [ 0.722761] [<ffffffff844febe0>] ? rest_init+0x87/0x87 [ 0.722761] [<ffffffff83de40be>] do_execve+0x23/0x25 [ 0.722761] [<ffffffff83c002e3>] run_init_process+0x2b/0x2d [ 0.722761] [<ffffffff844fec4d>] kernel_init+0x6d/0xda [ 0.722761] [<ffffffff84505b2f>] ret_from_fork+0x3f/0x70 [ 0.722761] [<ffffffff844febe0>] ? rest_init+0x87/0x87 [ 0.722761] Code: 86 84 be 12 00 00 00 e8 87 0d e8 ff 66 66 90 48 89 d8 48 c1 eb 03 4c 89 e7 83 e0 07 48 89 d9 be 08 00 00 00 31 d2 48 85 c9 74 0a <48> 89 17 48 01 f7 ff c9 75 f6 48 89 c1 85 c9 74 09 88 17 48 ff [ 0.722761] RIP [<ffffffff83f4129e>] __clear_user+0x42/0x67 [ 0.722761] RSP <ffff8800bc28fcf8> [ 0.722761] ---[ end trace def703879b4ff090 ]--- [ 0.722761] BUG: sleeping function called from invalid context at /mnt/host/source/src/third_party/kernel/v4.4/kernel/locking/rwsem.c:21 [ 0.722761] in_atomic(): 0, irqs_disabled(): 1, pid: 1, name: init [ 0.722761] CPU: 1 PID: 1 Comm: init Tainted: G D 4.4.96 #31 [ 0.722761] Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS rel-1.7.5.1-0-g8936dbb-20141113_115728-nilsson.home.kraxel.org 04/01/2014 [ 0.722761] 0000000000000086 dcb5d76098c89836 ffff8800bc28fa30 ffffffff83f34004 [ 0.722761] ffffffff84839dc2 0000000000000015 ffff8800bc28fa40 ffffffff83d57dc9 [ 0.722761] ffff8800bc28fa68 ffffffff83d57e6a ffffffff84a53640 0000000000000000 [ 0.722761] Call Trace: [ 0.722761] [<ffffffff83f34004>] dump_stack+0x4d/0x63 [ 0.722761] [<ffffffff83d57dc9>] ___might_sleep+0x13a/0x13c [ 0.722761] [<ffffffff83d57e6a>] __might_sleep+0x9f/0xa6 [ 0.722761] [<ffffffff84502788>] down_read+0x20/0x31 [ 0.722761] [<ffffffff83cc5d9b>] __blocking_notifier_call_chain+0x35/0x63 [ 0.722761] [<ffffffff83cc5ddd>] blocking_notifier_call_chain+0x14/0x16 [ 0.800374] usb 1-1: new full-speed USB device number 2 using uhci_hcd [ 0.722761] [<ffffffff83cefe97>] profile_task_exit+0x1a/0x1c [ 0.802309] [<ffffffff83cac84e>] do_exit+0x39/0xe7f [ 0.802309] [<ffffffff83ce5938>] ? vprintk_default+0x1d/0x1f [ 0.802309] [<ffffffff83d7bb95>] ? printk+0x57/0x73 [ 0.802309] [<ffffffff83c46e25>] oops_end+0x80/0x85 [ 0.802309] [<ffffffff83c7b747>] pgtable_bad+0x8a/0x95 [ 0.802309] [<ffffffff83ca7f4a>] __do_page_fault+0x8c/0x352 [ 0.802309] [<ffffffff83eefba5>] ? file_has_perm+0xc4/0xe5 [ 0.802309] [<ffffffff83ca821c>] do_page_fault+0xc/0xe [ 0.802309] [<ffffffff84507682>] page_fault+0x22/0x30 [ 0.802309] [<ffffffff83f4129e>] ? __clear_user+0x42/0x67 [ 0.802309] [<ffffffff83f4127f>] ? __clear_user+0x23/0x67 [ 0.802309] [<ffffffff83f4120c>] clear_user+0x2e/0x30 [ 0.802309] [<ffffffff83e9e7a1>] load_elf_binary+0xa7f/0x18f7 [ 0.802309] [<ffffffff83de2088>] search_binary_handler+0x86/0x19c [ 0.802309] [<ffffffff83de389e>] do_execveat_common.isra.26+0x909/0xf98 [ 0.802309] [<ffffffff844febe0>] ? rest_init+0x87/0x87 [ 0.802309] [<ffffffff83de40be>] do_execve+0x23/0x25 [ 0.802309] [<ffffffff83c002e3>] run_init_process+0x2b/0x2d [ 0.802309] [<ffffffff844fec4d>] kernel_init+0x6d/0xda [ 0.802309] [<ffffffff84505b2f>] ret_from_fork+0x3f/0x70 [ 0.802309] [<ffffffff844febe0>] ? rest_init+0x87/0x87 [ 0.830559] Kernel panic - not syncing: Attempted to kill init! exitcode=0x00000009 [ 0.830559] [ 0.831305] Kernel Offset: 0x2c00000 from 0xffffffff81000000 (relocation range: 0xffffffff80000000-0xffffffffbfffffff) [ 0.831305] ---[ end Kernel panic - not syncing: Attempted to kill init! exitcode=0x00000009 The crash part of this problem may be solved with the following patch (thanks to Hugh for the hint). There is still another problem, though - with this patch applied, the qemu session aborts with "VCPU Shutdown request", whatever that means. Cc: lepton <[email protected]> Signed-off-by: Guenter Roeck <[email protected]> Signed-off-by: Greg Kroah-Hartman <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
May 21, 2018
[ Upstream commit af50e4b ] syzbot caught an infinite recursion in nsh_gso_segment(). Problem here is that we need to make sure the NSH header is of reasonable length. BUG: MAX_LOCK_DEPTH too low! turning off the locking correctness validator. depth: 48 max: 48! 48 locks held by syz-executor0/10189: #0: (ptrval) (rcu_read_lock_bh){....}, at: __dev_queue_xmit+0x30f/0x34c0 net/core/dev.c:3517 #1: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #1: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #2: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #2: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #3: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #3: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #4: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #4: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #5: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #5: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #6: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #6: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #7: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #7: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #8: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #8: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #9: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #9: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #10: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #10: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #11: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #11: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #12: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #12: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #13: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #13: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #14: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #14: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #15: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #15: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #16: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #16: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #17: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #17: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #18: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #18: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #19: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #19: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #20: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #20: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #21: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #21: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #22: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #22: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #23: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #23: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #24: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #24: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #25: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #25: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #26: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #26: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #27: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #27: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #28: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #28: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #29: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #29: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #30: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #30: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #31: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #31: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 dccp_close: ABORT with 65423 bytes unread #32: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #32: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #33: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #33: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #34: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #34: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #35: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #35: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #36: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #36: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #37: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #37: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #38: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #38: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #39: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #39: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #40: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #40: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #41: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #41: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #42: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #42: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #43: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #43: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #44: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #44: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #45: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #45: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #46: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #46: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #47: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #47: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 INFO: lockdep is turned off. CPU: 1 PID: 10189 Comm: syz-executor0 Not tainted 4.17.0-rc2+ #26 Hardware name: Google Google Compute Engine/Google Compute Engine, BIOS Google 01/01/2011 Call Trace: __dump_stack lib/dump_stack.c:77 [inline] dump_stack+0x1b9/0x294 lib/dump_stack.c:113 __lock_acquire+0x1788/0x5140 kernel/locking/lockdep.c:3449 lock_acquire+0x1dc/0x520 kernel/locking/lockdep.c:3920 rcu_lock_acquire include/linux/rcupdate.h:246 [inline] rcu_read_lock include/linux/rcupdate.h:632 [inline] skb_mac_gso_segment+0x25b/0x720 net/core/dev.c:2789 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 __skb_gso_segment+0x3bb/0x870 net/core/dev.c:2865 skb_gso_segment include/linux/netdevice.h:4025 [inline] validate_xmit_skb+0x54d/0xd90 net/core/dev.c:3118 validate_xmit_skb_list+0xbf/0x120 net/core/dev.c:3168 sch_direct_xmit+0x354/0x11e0 net/sched/sch_generic.c:312 qdisc_restart net/sched/sch_generic.c:399 [inline] __qdisc_run+0x741/0x1af0 net/sched/sch_generic.c:410 __dev_xmit_skb net/core/dev.c:3243 [inline] __dev_queue_xmit+0x28ea/0x34c0 net/core/dev.c:3551 dev_queue_xmit+0x17/0x20 net/core/dev.c:3616 packet_snd net/packet/af_packet.c:2951 [inline] packet_sendmsg+0x40f8/0x6070 net/packet/af_packet.c:2976 sock_sendmsg_nosec net/socket.c:629 [inline] sock_sendmsg+0xd5/0x120 net/socket.c:639 __sys_sendto+0x3d7/0x670 net/socket.c:1789 __do_sys_sendto net/socket.c:1801 [inline] __se_sys_sendto net/socket.c:1797 [inline] __x64_sys_sendto+0xe1/0x1a0 net/socket.c:1797 do_syscall_64+0x1b1/0x800 arch/x86/entry/common.c:287 entry_SYSCALL_64_after_hwframe+0x49/0xbe Fixes: c411ed8 ("nsh: add GSO support") Signed-off-by: Eric Dumazet <[email protected]> Cc: Jiri Benc <[email protected]> Reported-by: syzbot <[email protected]> Acked-by: Jiri Benc <[email protected]> Signed-off-by: David S. Miller <[email protected]> Signed-off-by: Greg Kroah-Hartman <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
May 21, 2018
[ Upstream commit af50e4b ] syzbot caught an infinite recursion in nsh_gso_segment(). Problem here is that we need to make sure the NSH header is of reasonable length. BUG: MAX_LOCK_DEPTH too low! turning off the locking correctness validator. depth: 48 max: 48! 48 locks held by syz-executor0/10189: #0: (ptrval) (rcu_read_lock_bh){....}, at: __dev_queue_xmit+0x30f/0x34c0 net/core/dev.c:3517 #1: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #1: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #2: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #2: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #3: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #3: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #4: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #4: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #5: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #5: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #6: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #6: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #7: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #7: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #8: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #8: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #9: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #9: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #10: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #10: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #11: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #11: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #12: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #12: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #13: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #13: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #14: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #14: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #15: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #15: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #16: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #16: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #17: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #17: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #18: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #18: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #19: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #19: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #20: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #20: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #21: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #21: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #22: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #22: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #23: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #23: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #24: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #24: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #25: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #25: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #26: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #26: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #27: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #27: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #28: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #28: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #29: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #29: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #30: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #30: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #31: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #31: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 dccp_close: ABORT with 65423 bytes unread #32: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #32: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #33: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #33: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #34: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #34: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #35: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #35: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #36: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #36: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #37: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #37: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #38: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #38: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #39: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #39: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #40: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #40: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #41: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #41: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #42: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #42: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #43: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #43: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #44: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #44: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #45: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #45: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #46: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #46: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 #47: (ptrval) (rcu_read_lock){....}, at: __skb_pull include/linux/skbuff.h:2080 [inline] #47: (ptrval) (rcu_read_lock){....}, at: skb_mac_gso_segment+0x221/0x720 net/core/dev.c:2787 INFO: lockdep is turned off. CPU: 1 PID: 10189 Comm: syz-executor0 Not tainted 4.17.0-rc2+ #26 Hardware name: Google Google Compute Engine/Google Compute Engine, BIOS Google 01/01/2011 Call Trace: __dump_stack lib/dump_stack.c:77 [inline] dump_stack+0x1b9/0x294 lib/dump_stack.c:113 __lock_acquire+0x1788/0x5140 kernel/locking/lockdep.c:3449 lock_acquire+0x1dc/0x520 kernel/locking/lockdep.c:3920 rcu_lock_acquire include/linux/rcupdate.h:246 [inline] rcu_read_lock include/linux/rcupdate.h:632 [inline] skb_mac_gso_segment+0x25b/0x720 net/core/dev.c:2789 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 nsh_gso_segment+0x405/0xb60 net/nsh/nsh.c:107 skb_mac_gso_segment+0x3ad/0x720 net/core/dev.c:2792 __skb_gso_segment+0x3bb/0x870 net/core/dev.c:2865 skb_gso_segment include/linux/netdevice.h:4025 [inline] validate_xmit_skb+0x54d/0xd90 net/core/dev.c:3118 validate_xmit_skb_list+0xbf/0x120 net/core/dev.c:3168 sch_direct_xmit+0x354/0x11e0 net/sched/sch_generic.c:312 qdisc_restart net/sched/sch_generic.c:399 [inline] __qdisc_run+0x741/0x1af0 net/sched/sch_generic.c:410 __dev_xmit_skb net/core/dev.c:3243 [inline] __dev_queue_xmit+0x28ea/0x34c0 net/core/dev.c:3551 dev_queue_xmit+0x17/0x20 net/core/dev.c:3616 packet_snd net/packet/af_packet.c:2951 [inline] packet_sendmsg+0x40f8/0x6070 net/packet/af_packet.c:2976 sock_sendmsg_nosec net/socket.c:629 [inline] sock_sendmsg+0xd5/0x120 net/socket.c:639 __sys_sendto+0x3d7/0x670 net/socket.c:1789 __do_sys_sendto net/socket.c:1801 [inline] __se_sys_sendto net/socket.c:1797 [inline] __x64_sys_sendto+0xe1/0x1a0 net/socket.c:1797 do_syscall_64+0x1b1/0x800 arch/x86/entry/common.c:287 entry_SYSCALL_64_after_hwframe+0x49/0xbe Fixes: c411ed8 ("nsh: add GSO support") Signed-off-by: Eric Dumazet <[email protected]> Cc: Jiri Benc <[email protected]> Reported-by: syzbot <[email protected]> Acked-by: Jiri Benc <[email protected]> Signed-off-by: David S. Miller <[email protected]> Signed-off-by: Greg Kroah-Hartman <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Aug 7, 2018
[ Upstream commit 4b19067 ] When attempt to read tpc_stats for the chipsets which support more than 3 tx chain will trigger kernel panic(kernel stack is corrupted) due to writing values on rate_code array out of range. This patch changes the array size depends on the WMI_TPC_TX_N_CHAIN and added check to avoid write values on the array if the num tx chain get in tpc config event is greater than WMI_TPC_TX_N_CHAIN. Tested on QCA9984 with firmware-5.bin_10.4-3.5.3-00057 Kernel panic log : [ 323.510944] Kernel panic - not syncing: stack-protector: Kernel stack is corrupted in: bf90c654 [ 323.510944] [ 323.524390] CPU: 0 PID: 1908 Comm: cat Not tainted 3.14.77 #31 [ 323.530224] [<c021db48>] (unwind_backtrace) from [<c021ac08>] (show_stack+0x10/0x14) [ 323.537941] [<c021ac08>] (show_stack) from [<c03c53c0>] (dump_stack+0x80/0xa0) [ 323.545146] [<c03c53c0>] (dump_stack) from [<c022e4ac>] (panic+0x84/0x1e4) [ 323.552000] [<c022e4ac>] (panic) from [<c022e61c>] (__stack_chk_fail+0x10/0x14) [ 323.559350] [<c022e61c>] (__stack_chk_fail) from [<bf90c654>] (ath10k_wmi_event_pdev_tpc_config+0x424/0x438 [ath10k_core]) [ 323.570471] [<bf90c654>] (ath10k_wmi_event_pdev_tpc_config [ath10k_core]) from [<bf90d800>] (ath10k_wmi_10_4_op_rx+0x2f0/0x39c [ath10k_core]) [ 323.583047] [<bf90d800>] (ath10k_wmi_10_4_op_rx [ath10k_core]) from [<bf8fcc18>] (ath10k_htc_rx_completion_handler+0x170/0x1a0 [ath10k_core]) [ 323.595702] [<bf8fcc18>] (ath10k_htc_rx_completion_handler [ath10k_core]) from [<bf961f44>] (ath10k_pci_hif_send_complete_check+0x1f0/0x220 [ath10k_pci]) [ 323.609421] [<bf961f44>] (ath10k_pci_hif_send_complete_check [ath10k_pci]) from [<bf96562c>] (ath10k_ce_per_engine_service+0x74/0xc4 [ath10k_pci]) [ 323.622490] [<bf96562c>] (ath10k_ce_per_engine_service [ath10k_pci]) from [<bf9656f0>] (ath10k_ce_per_engine_service_any+0x74/0x80 [ath10k_pci]) [ 323.635423] [<bf9656f0>] (ath10k_ce_per_engine_service_any [ath10k_pci]) from [<bf96365c>] (ath10k_pci_napi_poll+0x44/0xe8 [ath10k_pci]) [ 323.647665] [<bf96365c>] (ath10k_pci_napi_poll [ath10k_pci]) from [<c0599994>] (net_rx_action+0xac/0x160) [ 323.657208] [<c0599994>] (net_rx_action) from [<c02324a4>] (__do_softirq+0x104/0x294) [ 323.665017] [<c02324a4>] (__do_softirq) from [<c0232920>] (irq_exit+0x9c/0x11c) [ 323.672314] [<c0232920>] (irq_exit) from [<c0217fc0>] (handle_IRQ+0x6c/0x90) [ 323.679341] [<c0217fc0>] (handle_IRQ) from [<c02084e0>] (gic_handle_irq+0x3c/0x60) [ 323.686893] [<c02084e0>] (gic_handle_irq) from [<c02095c0>] (__irq_svc+0x40/0x70) [ 323.694349] Exception stack(0xdd489c58 to 0xdd489ca0) [ 323.699384] 9c40: 00000000 a0000013 [ 323.707547] 9c60: 00000000 dc4bce40 60000013 ddc1d800 dd488000 00000990 00000000 c085c800 [ 323.715707] 9c80: 00000000 dd489d44 0000092d dd489ca0 c026e664 c026e668 60000013 ffffffff [ 323.723877] [<c02095c0>] (__irq_svc) from [<c026e668>] (rcu_note_context_switch+0x170/0x184) [ 323.732298] [<c026e668>] (rcu_note_context_switch) from [<c020e928>] (__schedule+0x50/0x4d4) [ 323.740716] [<c020e928>] (__schedule) from [<c020e490>] (schedule_timeout+0x148/0x178) [ 323.748611] [<c020e490>] (schedule_timeout) from [<c020f804>] (wait_for_common+0x114/0x154) [ 323.756972] [<c020f804>] (wait_for_common) from [<bf8f6ef0>] (ath10k_tpc_stats_open+0xc8/0x340 [ath10k_core]) [ 323.766873] [<bf8f6ef0>] (ath10k_tpc_stats_open [ath10k_core]) from [<c02bb598>] (do_dentry_open+0x1ac/0x274) [ 323.776741] [<c02bb598>] (do_dentry_open) from [<c02c838c>] (do_last+0x8c0/0xb08) [ 323.784201] [<c02c838c>] (do_last) from [<c02c87e4>] (path_openat+0x210/0x598) [ 323.791408] [<c02c87e4>] (path_openat) from [<c02c9d1c>] (do_filp_open+0x2c/0x78) [ 323.798873] [<c02c9d1c>] (do_filp_open) from [<c02bc85c>] (do_sys_open+0x114/0x1b4) [ 323.806509] [<c02bc85c>] (do_sys_open) from [<c0208c80>] (ret_fast_syscall+0x0/0x44) [ 323.814241] CPU1: stopping [ 323.816927] CPU: 1 PID: 0 Comm: swapper/1 Not tainted 3.14.77 #31 [ 323.823008] [<c021db48>] (unwind_backtrace) from [<c021ac08>] (show_stack+0x10/0x14) [ 323.830731] [<c021ac08>] (show_stack) from [<c03c53c0>] (dump_stack+0x80/0xa0) [ 323.837934] [<c03c53c0>] (dump_stack) from [<c021cfac>] (handle_IPI+0xb8/0x140) [ 323.845224] [<c021cfac>] (handle_IPI) from [<c02084fc>] (gic_handle_irq+0x58/0x60) [ 323.852774] [<c02084fc>] (gic_handle_irq) from [<c02095c0>] (__irq_svc+0x40/0x70) [ 323.860233] Exception stack(0xdd499fa0 to 0xdd499fe8) [ 323.865273] 9fa0: ffffffed 00000000 1d3c9000 00000000 dd498000 dd498030 10c0387d c08b62c8 [ 323.873432] 9fc0: 4220406a 512f04d0 00000000 00000000 00000001 dd499fe8 c021838c c0218390 [ 323.881588] 9fe0: 60000013 ffffffff [ 323.885070] [<c02095c0>] (__irq_svc) from [<c0218390>] (arch_cpu_idle+0x30/0x50) [ 323.892454] [<c0218390>] (arch_cpu_idle) from [<c026500c>] (cpu_startup_entry+0xa4/0x108) [ 323.900690] [<c026500c>] (cpu_startup_entry) from [<422085a4>] (0x422085a4) Signed-off-by: Tamizh chelvam <[email protected]> Signed-off-by: Kalle Valo <[email protected]> Signed-off-by: Sasha Levin <[email protected]> Signed-off-by: Greg Kroah-Hartman <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Nov 13, 2018
Increase kasan instrumented kernel stack size from 32k to 64k. Other architectures seems to get away with just doubling kernel stack size under kasan, but on s390 this appears to be not enough due to bigger frame size. The particular pain point is kasan inlined checks (CONFIG_KASAN_INLINE vs CONFIG_KASAN_OUTLINE). With inlined checks one particular case hitting stack overflow is fs sync on xfs filesystem: #0 [9a0681e8] 704 bytes check_usage at 34b1fc #1 [9a0684a8] 432 bytes check_usage at 34c710 #2 [9a068658] 1048 bytes validate_chain at 35044a #3 [9a068a70] 312 bytes __lock_acquire at 3559fe #4 [9a068ba8] 440 bytes lock_acquire at 3576ee #5 [9a068d60] 104 bytes _raw_spin_lock at 21b44e0 #6 [9a068dc8] 1992 bytes enqueue_entity at 2dbf72 #7 [9a069590] 1496 bytes enqueue_task_fair at 2df5f0 #8 [9a069b68] 64 bytes ttwu_do_activate at 28f438 #9 [9a069ba8] 552 bytes try_to_wake_up at 298c4c #10 [9a069dd0] 168 bytes wake_up_worker at 23f97c #11 [9a069e78] 200 bytes insert_work at 23fc2e #12 [9a069f40] 648 bytes __queue_work at 2487c0 #13 [9a06a1c8] 200 bytes __queue_delayed_work at 24db28 #14 [9a06a290] 248 bytes mod_delayed_work_on at 24de84 #15 [9a06a388] 24 bytes kblockd_mod_delayed_work_on at 153e2a0 #16 [9a06a3a0] 288 bytes __blk_mq_delay_run_hw_queue at 158168c #17 [9a06a4c0] 192 bytes blk_mq_run_hw_queue at 1581a3c #18 [9a06a580] 184 bytes blk_mq_sched_insert_requests at 15a2192 #19 [9a06a638] 1024 bytes blk_mq_flush_plug_list at 1590f3a #20 [9a06aa38] 704 bytes blk_flush_plug_list at 1555028 #21 [9a06acf8] 320 bytes schedule at 219e476 #22 [9a06ae38] 760 bytes schedule_timeout at 21b0aac #23 [9a06b130] 408 bytes wait_for_common at 21a1706 #24 [9a06b2c8] 360 bytes xfs_buf_iowait at fa1540 #25 [9a06b430] 256 bytes __xfs_buf_submit at fadae6 #26 [9a06b530] 264 bytes xfs_buf_read_map at fae3f6 #27 [9a06b638] 656 bytes xfs_trans_read_buf_map at 10ac9a8 #28 [9a06b8c8] 304 bytes xfs_btree_kill_root at e72426 #29 [9a06b9f8] 288 bytes xfs_btree_lookup_get_block at e7bc5e #30 [9a06bb18] 624 bytes xfs_btree_lookup at e7e1a6 #31 [9a06bd88] 2664 bytes xfs_alloc_ag_vextent_near at dfa070 #32 [9a06c7f0] 144 bytes xfs_alloc_ag_vextent at dff3ca #33 [9a06c880] 1128 bytes xfs_alloc_vextent at e05fce #34 [9a06cce8] 584 bytes xfs_bmap_btalloc at e58342 #35 [9a06cf30] 1336 bytes xfs_bmapi_write at e618de #36 [9a06d468] 776 bytes xfs_iomap_write_allocate at ff678e #37 [9a06d770] 720 bytes xfs_map_blocks at f82af8 #38 [9a06da40] 928 bytes xfs_writepage_map at f83cd6 #39 [9a06dde0] 320 bytes xfs_do_writepage at f85872 #40 [9a06df20] 1320 bytes write_cache_pages at 73dfe8 #41 [9a06e448] 208 bytes xfs_vm_writepages at f7f892 #42 [9a06e518] 88 bytes do_writepages at 73fe6a #43 [9a06e570] 872 bytes __writeback_single_inode at a20cb6 #44 [9a06e8d8] 664 bytes writeback_sb_inodes at a23be2 #45 [9a06eb70] 296 bytes __writeback_inodes_wb at a242e0 #46 [9a06ec98] 928 bytes wb_writeback at a2500e #47 [9a06f038] 848 bytes wb_do_writeback at a260ae #48 [9a06f388] 536 bytes wb_workfn at a28228 #49 [9a06f5a0] 1088 bytes process_one_work at 24a234 #50 [9a06f9e0] 1120 bytes worker_thread at 24ba26 #51 [9a06fe40] 104 bytes kthread at 26545a #52 [9a06fea8] kernel_thread_starter at 21b6b62 To be able to increase the stack size to 64k reuse LLILL instruction in __switch_to function to load 64k - STACK_FRAME_OVERHEAD - __PT_SIZE (65192) value as unsigned. Reported-by: Benjamin Block <[email protected]> Reviewed-by: Heiko Carstens <[email protected]> Signed-off-by: Vasily Gorbik <[email protected]> Signed-off-by: Martin Schwidefsky <[email protected]>
sigmaris
pushed a commit
to sigmaris/linux
that referenced
this issue
May 12, 2019
When using direct commands (DCMDs) on an RK3399, we get spurious CQE completion interrupts for the DCMD transaction slot (raspberrypi#31): [ 931.196520] ------------[ cut here ]------------ [ 931.201702] mmc1: cqhci: spurious TCN for tag 31 [ 931.206906] WARNING: CPU: 0 PID: 1433 at /usr/src/kernel/drivers/mmc/host/cqhci.c:725 cqhci_irq+0x2e4/0x490 [ 931.206909] Modules linked in: [ 931.206918] CPU: 0 PID: 1433 Comm: irq/29-mmc1 Not tainted 4.19.8-rt6-funkadelic raspberrypi#1 [ 931.206920] Hardware name: Theobroma Systems RK3399-Q7 SoM (DT) [ 931.206924] pstate: 40000005 (nZcv daif -PAN -UAO) [ 931.206927] pc : cqhci_irq+0x2e4/0x490 [ 931.206931] lr : cqhci_irq+0x2e4/0x490 [ 931.206933] sp : ffff00000e54bc80 [ 931.206934] x29: ffff00000e54bc80 x28: 0000000000000000 [ 931.206939] x27: 0000000000000001 x26: ffff000008f217e8 [ 931.206944] x25: ffff8000f02ef030 x24: ffff0000091417b0 [ 931.206948] x23: ffff0000090aa000 x22: ffff8000f008b000 [ 931.206953] x21: 0000000000000002 x20: 000000000000001f [ 931.206957] x19: ffff8000f02ef018 x18: ffffffffffffffff [ 931.206961] x17: 0000000000000000 x16: 0000000000000000 [ 931.206966] x15: ffff0000090aa6c8 x14: 0720072007200720 [ 931.206970] x13: 0720072007200720 x12: 0720072007200720 [ 931.206975] x11: 0720072007200720 x10: 0720072007200720 [ 931.206980] x9 : 0720072007200720 x8 : 0720072007200720 [ 931.206984] x7 : 0720073107330720 x6 : 00000000000005a0 [ 931.206988] x5 : ffff00000860d4b0 x4 : 0000000000000000 [ 931.206993] x3 : 0000000000000001 x2 : 0000000000000001 [ 931.206997] x1 : 1bde3a91b0d4d900 x0 : 0000000000000000 [ 931.207001] Call trace: [ 931.207005] cqhci_irq+0x2e4/0x490 [ 931.207009] sdhci_arasan_cqhci_irq+0x5c/0x90 [ 931.207013] sdhci_irq+0x98/0x930 [ 931.207019] irq_forced_thread_fn+0x2c/0xa0 [ 931.207023] irq_thread+0x114/0x1c0 [ 931.207027] kthread+0x128/0x130 [ 931.207032] ret_from_fork+0x10/0x20 [ 931.207035] ---[ end trace 0000000000000002 ]--- The driver shows this message only for the first spurious interrupt by using WARN_ONCE(). Changing this to WARN() shows, that this is happening quite frequently (up to once a second). Since the eMMC 5.1 specification, where CQE and CQHCI are specified, does not mention that spurious TCN interrupts for DCMDs can be simply ignored, we must assume that using this feature is not working reliably. The current implementation uses DCMD for REQ_OP_FLUSH only, and I could not see any performance/power impact when disabling this optional feature for RK3399. Therefore this patch disables DCMDs for RK3399. Signed-off-by: Christoph Muellner <[email protected]> Signed-off-by: Philipp Tomsich <[email protected]> Fixes: 84362d7 ("mmc: sdhci-of-arasan: Add CQHCI support for arasan,sdhci-5.1") Cc: [email protected] [the corresponding code changes are queued for 5.2 so doing that as well] Signed-off-by: Heiko Stuebner <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
May 28, 2019
commit a3eec13 upstream. When using direct commands (DCMDs) on an RK3399, we get spurious CQE completion interrupts for the DCMD transaction slot (#31): [ 931.196520] ------------[ cut here ]------------ [ 931.201702] mmc1: cqhci: spurious TCN for tag 31 [ 931.206906] WARNING: CPU: 0 PID: 1433 at /usr/src/kernel/drivers/mmc/host/cqhci.c:725 cqhci_irq+0x2e4/0x490 [ 931.206909] Modules linked in: [ 931.206918] CPU: 0 PID: 1433 Comm: irq/29-mmc1 Not tainted 4.19.8-rt6-funkadelic #1 [ 931.206920] Hardware name: Theobroma Systems RK3399-Q7 SoM (DT) [ 931.206924] pstate: 40000005 (nZcv daif -PAN -UAO) [ 931.206927] pc : cqhci_irq+0x2e4/0x490 [ 931.206931] lr : cqhci_irq+0x2e4/0x490 [ 931.206933] sp : ffff00000e54bc80 [ 931.206934] x29: ffff00000e54bc80 x28: 0000000000000000 [ 931.206939] x27: 0000000000000001 x26: ffff000008f217e8 [ 931.206944] x25: ffff8000f02ef030 x24: ffff0000091417b0 [ 931.206948] x23: ffff0000090aa000 x22: ffff8000f008b000 [ 931.206953] x21: 0000000000000002 x20: 000000000000001f [ 931.206957] x19: ffff8000f02ef018 x18: ffffffffffffffff [ 931.206961] x17: 0000000000000000 x16: 0000000000000000 [ 931.206966] x15: ffff0000090aa6c8 x14: 0720072007200720 [ 931.206970] x13: 0720072007200720 x12: 0720072007200720 [ 931.206975] x11: 0720072007200720 x10: 0720072007200720 [ 931.206980] x9 : 0720072007200720 x8 : 0720072007200720 [ 931.206984] x7 : 0720073107330720 x6 : 00000000000005a0 [ 931.206988] x5 : ffff00000860d4b0 x4 : 0000000000000000 [ 931.206993] x3 : 0000000000000001 x2 : 0000000000000001 [ 931.206997] x1 : 1bde3a91b0d4d900 x0 : 0000000000000000 [ 931.207001] Call trace: [ 931.207005] cqhci_irq+0x2e4/0x490 [ 931.207009] sdhci_arasan_cqhci_irq+0x5c/0x90 [ 931.207013] sdhci_irq+0x98/0x930 [ 931.207019] irq_forced_thread_fn+0x2c/0xa0 [ 931.207023] irq_thread+0x114/0x1c0 [ 931.207027] kthread+0x128/0x130 [ 931.207032] ret_from_fork+0x10/0x20 [ 931.207035] ---[ end trace 0000000000000002 ]--- The driver shows this message only for the first spurious interrupt by using WARN_ONCE(). Changing this to WARN() shows, that this is happening quite frequently (up to once a second). Since the eMMC 5.1 specification, where CQE and CQHCI are specified, does not mention that spurious TCN interrupts for DCMDs can be simply ignored, we must assume that using this feature is not working reliably. The current implementation uses DCMD for REQ_OP_FLUSH only, and I could not see any performance/power impact when disabling this optional feature for RK3399. Therefore this patch disables DCMDs for RK3399. Signed-off-by: Christoph Muellner <[email protected]> Signed-off-by: Philipp Tomsich <[email protected]> Fixes: 84362d7 ("mmc: sdhci-of-arasan: Add CQHCI support for arasan,sdhci-5.1") Cc: [email protected] [the corresponding code changes are queued for 5.2 so doing that as well] Signed-off-by: Heiko Stuebner <[email protected]> Signed-off-by: Greg Kroah-Hartman <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
May 28, 2019
commit a3eec13 upstream. When using direct commands (DCMDs) on an RK3399, we get spurious CQE completion interrupts for the DCMD transaction slot (#31): [ 931.196520] ------------[ cut here ]------------ [ 931.201702] mmc1: cqhci: spurious TCN for tag 31 [ 931.206906] WARNING: CPU: 0 PID: 1433 at /usr/src/kernel/drivers/mmc/host/cqhci.c:725 cqhci_irq+0x2e4/0x490 [ 931.206909] Modules linked in: [ 931.206918] CPU: 0 PID: 1433 Comm: irq/29-mmc1 Not tainted 4.19.8-rt6-funkadelic #1 [ 931.206920] Hardware name: Theobroma Systems RK3399-Q7 SoM (DT) [ 931.206924] pstate: 40000005 (nZcv daif -PAN -UAO) [ 931.206927] pc : cqhci_irq+0x2e4/0x490 [ 931.206931] lr : cqhci_irq+0x2e4/0x490 [ 931.206933] sp : ffff00000e54bc80 [ 931.206934] x29: ffff00000e54bc80 x28: 0000000000000000 [ 931.206939] x27: 0000000000000001 x26: ffff000008f217e8 [ 931.206944] x25: ffff8000f02ef030 x24: ffff0000091417b0 [ 931.206948] x23: ffff0000090aa000 x22: ffff8000f008b000 [ 931.206953] x21: 0000000000000002 x20: 000000000000001f [ 931.206957] x19: ffff8000f02ef018 x18: ffffffffffffffff [ 931.206961] x17: 0000000000000000 x16: 0000000000000000 [ 931.206966] x15: ffff0000090aa6c8 x14: 0720072007200720 [ 931.206970] x13: 0720072007200720 x12: 0720072007200720 [ 931.206975] x11: 0720072007200720 x10: 0720072007200720 [ 931.206980] x9 : 0720072007200720 x8 : 0720072007200720 [ 931.206984] x7 : 0720073107330720 x6 : 00000000000005a0 [ 931.206988] x5 : ffff00000860d4b0 x4 : 0000000000000000 [ 931.206993] x3 : 0000000000000001 x2 : 0000000000000001 [ 931.206997] x1 : 1bde3a91b0d4d900 x0 : 0000000000000000 [ 931.207001] Call trace: [ 931.207005] cqhci_irq+0x2e4/0x490 [ 931.207009] sdhci_arasan_cqhci_irq+0x5c/0x90 [ 931.207013] sdhci_irq+0x98/0x930 [ 931.207019] irq_forced_thread_fn+0x2c/0xa0 [ 931.207023] irq_thread+0x114/0x1c0 [ 931.207027] kthread+0x128/0x130 [ 931.207032] ret_from_fork+0x10/0x20 [ 931.207035] ---[ end trace 0000000000000002 ]--- The driver shows this message only for the first spurious interrupt by using WARN_ONCE(). Changing this to WARN() shows, that this is happening quite frequently (up to once a second). Since the eMMC 5.1 specification, where CQE and CQHCI are specified, does not mention that spurious TCN interrupts for DCMDs can be simply ignored, we must assume that using this feature is not working reliably. The current implementation uses DCMD for REQ_OP_FLUSH only, and I could not see any performance/power impact when disabling this optional feature for RK3399. Therefore this patch disables DCMDs for RK3399. Signed-off-by: Christoph Muellner <[email protected]> Signed-off-by: Philipp Tomsich <[email protected]> Fixes: 84362d7 ("mmc: sdhci-of-arasan: Add CQHCI support for arasan,sdhci-5.1") Cc: [email protected] [the corresponding code changes are queued for 5.2 so doing that as well] Signed-off-by: Heiko Stuebner <[email protected]> Signed-off-by: Greg Kroah-Hartman <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Jun 4, 2019
commit a3eec13 upstream. When using direct commands (DCMDs) on an RK3399, we get spurious CQE completion interrupts for the DCMD transaction slot (#31): [ 931.196520] ------------[ cut here ]------------ [ 931.201702] mmc1: cqhci: spurious TCN for tag 31 [ 931.206906] WARNING: CPU: 0 PID: 1433 at /usr/src/kernel/drivers/mmc/host/cqhci.c:725 cqhci_irq+0x2e4/0x490 [ 931.206909] Modules linked in: [ 931.206918] CPU: 0 PID: 1433 Comm: irq/29-mmc1 Not tainted 4.19.8-rt6-funkadelic #1 [ 931.206920] Hardware name: Theobroma Systems RK3399-Q7 SoM (DT) [ 931.206924] pstate: 40000005 (nZcv daif -PAN -UAO) [ 931.206927] pc : cqhci_irq+0x2e4/0x490 [ 931.206931] lr : cqhci_irq+0x2e4/0x490 [ 931.206933] sp : ffff00000e54bc80 [ 931.206934] x29: ffff00000e54bc80 x28: 0000000000000000 [ 931.206939] x27: 0000000000000001 x26: ffff000008f217e8 [ 931.206944] x25: ffff8000f02ef030 x24: ffff0000091417b0 [ 931.206948] x23: ffff0000090aa000 x22: ffff8000f008b000 [ 931.206953] x21: 0000000000000002 x20: 000000000000001f [ 931.206957] x19: ffff8000f02ef018 x18: ffffffffffffffff [ 931.206961] x17: 0000000000000000 x16: 0000000000000000 [ 931.206966] x15: ffff0000090aa6c8 x14: 0720072007200720 [ 931.206970] x13: 0720072007200720 x12: 0720072007200720 [ 931.206975] x11: 0720072007200720 x10: 0720072007200720 [ 931.206980] x9 : 0720072007200720 x8 : 0720072007200720 [ 931.206984] x7 : 0720073107330720 x6 : 00000000000005a0 [ 931.206988] x5 : ffff00000860d4b0 x4 : 0000000000000000 [ 931.206993] x3 : 0000000000000001 x2 : 0000000000000001 [ 931.206997] x1 : 1bde3a91b0d4d900 x0 : 0000000000000000 [ 931.207001] Call trace: [ 931.207005] cqhci_irq+0x2e4/0x490 [ 931.207009] sdhci_arasan_cqhci_irq+0x5c/0x90 [ 931.207013] sdhci_irq+0x98/0x930 [ 931.207019] irq_forced_thread_fn+0x2c/0xa0 [ 931.207023] irq_thread+0x114/0x1c0 [ 931.207027] kthread+0x128/0x130 [ 931.207032] ret_from_fork+0x10/0x20 [ 931.207035] ---[ end trace 0000000000000002 ]--- The driver shows this message only for the first spurious interrupt by using WARN_ONCE(). Changing this to WARN() shows, that this is happening quite frequently (up to once a second). Since the eMMC 5.1 specification, where CQE and CQHCI are specified, does not mention that spurious TCN interrupts for DCMDs can be simply ignored, we must assume that using this feature is not working reliably. The current implementation uses DCMD for REQ_OP_FLUSH only, and I could not see any performance/power impact when disabling this optional feature for RK3399. Therefore this patch disables DCMDs for RK3399. Signed-off-by: Christoph Muellner <[email protected]> Signed-off-by: Philipp Tomsich <[email protected]> Fixes: 84362d7 ("mmc: sdhci-of-arasan: Add CQHCI support for arasan,sdhci-5.1") Cc: [email protected] [the corresponding code changes are queued for 5.2 so doing that as well] Signed-off-by: Heiko Stuebner <[email protected]> Signed-off-by: Greg Kroah-Hartman <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Jul 1, 2019
Setting invalid value to /sys/devices/system/cpu/cpuX/hotplug/fail can control `struct cpuhp_step *sp` address, results in the following global-out-of-bounds read. Reproducer: # echo -2 > /sys/devices/system/cpu/cpu0/hotplug/fail KASAN report: BUG: KASAN: global-out-of-bounds in write_cpuhp_fail+0x2cd/0x2e0 Read of size 8 at addr ffffffff89734438 by task bash/1941 CPU: 0 PID: 1941 Comm: bash Not tainted 5.2.0-rc6+ #31 Call Trace: write_cpuhp_fail+0x2cd/0x2e0 dev_attr_store+0x58/0x80 sysfs_kf_write+0x13d/0x1a0 kernfs_fop_write+0x2bc/0x460 vfs_write+0x1e1/0x560 ksys_write+0x126/0x250 do_syscall_64+0xc1/0x390 entry_SYSCALL_64_after_hwframe+0x49/0xbe RIP: 0033:0x7f05e4f4c970 The buggy address belongs to the variable: cpu_hotplug_lock+0x98/0xa0 Memory state around the buggy address: ffffffff89734300: fa fa fa fa 00 00 00 00 00 00 00 00 00 00 00 00 ffffffff89734380: fa fa fa fa 00 00 00 00 00 00 00 00 00 00 00 00 >ffffffff89734400: 00 00 00 00 fa fa fa fa 00 00 00 00 fa fa fa fa ^ ffffffff89734480: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ffffffff89734500: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 Add a sanity check for the value written from user space. Fixes: 1db4948 ("smp/hotplug: Hotplug state fail injection") Signed-off-by: Eiichi Tsukata <[email protected]> Signed-off-by: Thomas Gleixner <[email protected]> Cc: [email protected] Link: https://lkml.kernel.org/r/[email protected]
popcornmix
pushed a commit
that referenced
this issue
May 19, 2021
[ Upstream commit 0f20615 ] Fix BPF_CORE_READ_BITFIELD() macro used for reading CO-RE-relocatable bitfields. Missing breaks in a switch caused 8-byte reads always. This can confuse libbpf because it does strict checks that memory load size corresponds to the original size of the field, which in this case quite often would be wrong. After fixing that, we run into another problem, which quite subtle, so worth documenting here. The issue is in Clang optimization and CO-RE relocation interactions. Without that asm volatile construct (also known as barrier_var()), Clang will re-order BYTE_OFFSET and BYTE_SIZE relocations and will apply BYTE_OFFSET 4 times for each switch case arm. This will result in the same error from libbpf about mismatch of memory load size and original field size. I.e., if we were reading u32, we'd still have *(u8 *), *(u16 *), *(u32 *), and *(u64 *) memory loads, three of which will fail. Using barrier_var() forces Clang to apply BYTE_OFFSET relocation first (and once) to calculate p, after which value of p is used without relocation in each of switch case arms, doing appropiately-sized memory load. Here's the list of relevant relocations and pieces of generated BPF code before and after this patch for test_core_reloc_bitfields_direct selftests. BEFORE ===== #45: core_reloc: insn #160 --> [5] + 0:5: byte_sz --> struct core_reloc_bitfields.u32 #46: core_reloc: insn #167 --> [5] + 0:5: byte_off --> struct core_reloc_bitfields.u32 #47: core_reloc: insn #174 --> [5] + 0:5: byte_off --> struct core_reloc_bitfields.u32 #48: core_reloc: insn #178 --> [5] + 0:5: byte_off --> struct core_reloc_bitfields.u32 #49: core_reloc: insn #182 --> [5] + 0:5: byte_off --> struct core_reloc_bitfields.u32 157: 18 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r2 = 0 ll 159: 7b 12 20 01 00 00 00 00 *(u64 *)(r2 + 288) = r1 160: b7 02 00 00 04 00 00 00 r2 = 4 ; BYTE_SIZE relocation here ^^^ 161: 66 02 07 00 03 00 00 00 if w2 s> 3 goto +7 <LBB0_63> 162: 16 02 0d 00 01 00 00 00 if w2 == 1 goto +13 <LBB0_65> 163: 16 02 01 00 02 00 00 00 if w2 == 2 goto +1 <LBB0_66> 164: 05 00 12 00 00 00 00 00 goto +18 <LBB0_69> 0000000000000528 <LBB0_66>: 165: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll 167: 69 11 08 00 00 00 00 00 r1 = *(u16 *)(r1 + 8) ; BYTE_OFFSET relo here w/ WRONG size ^^^^^^^^^^^^^^^^ 168: 05 00 0e 00 00 00 00 00 goto +14 <LBB0_69> 0000000000000548 <LBB0_63>: 169: 16 02 0a 00 04 00 00 00 if w2 == 4 goto +10 <LBB0_67> 170: 16 02 01 00 08 00 00 00 if w2 == 8 goto +1 <LBB0_68> 171: 05 00 0b 00 00 00 00 00 goto +11 <LBB0_69> 0000000000000560 <LBB0_68>: 172: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll 174: 79 11 08 00 00 00 00 00 r1 = *(u64 *)(r1 + 8) ; BYTE_OFFSET relo here w/ WRONG size ^^^^^^^^^^^^^^^^ 175: 05 00 07 00 00 00 00 00 goto +7 <LBB0_69> 0000000000000580 <LBB0_65>: 176: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll 178: 71 11 08 00 00 00 00 00 r1 = *(u8 *)(r1 + 8) ; BYTE_OFFSET relo here w/ WRONG size ^^^^^^^^^^^^^^^^ 179: 05 00 03 00 00 00 00 00 goto +3 <LBB0_69> 00000000000005a0 <LBB0_67>: 180: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll 182: 61 11 08 00 00 00 00 00 r1 = *(u32 *)(r1 + 8) ; BYTE_OFFSET relo here w/ RIGHT size ^^^^^^^^^^^^^^^^ 00000000000005b8 <LBB0_69>: 183: 67 01 00 00 20 00 00 00 r1 <<= 32 184: b7 02 00 00 00 00 00 00 r2 = 0 185: 16 02 02 00 00 00 00 00 if w2 == 0 goto +2 <LBB0_71> 186: c7 01 00 00 20 00 00 00 r1 s>>= 32 187: 05 00 01 00 00 00 00 00 goto +1 <LBB0_72> 00000000000005e0 <LBB0_71>: 188: 77 01 00 00 20 00 00 00 r1 >>= 32 AFTER ===== #30: core_reloc: insn #132 --> [5] + 0:5: byte_off --> struct core_reloc_bitfields.u32 #31: core_reloc: insn #134 --> [5] + 0:5: byte_sz --> struct core_reloc_bitfields.u32 129: 18 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r2 = 0 ll 131: 7b 12 20 01 00 00 00 00 *(u64 *)(r2 + 288) = r1 132: b7 01 00 00 08 00 00 00 r1 = 8 ; BYTE_OFFSET relo here ^^^ ; no size check for non-memory dereferencing instructions 133: 0f 12 00 00 00 00 00 00 r2 += r1 134: b7 03 00 00 04 00 00 00 r3 = 4 ; BYTE_SIZE relocation here ^^^ 135: 66 03 05 00 03 00 00 00 if w3 s> 3 goto +5 <LBB0_63> 136: 16 03 09 00 01 00 00 00 if w3 == 1 goto +9 <LBB0_65> 137: 16 03 01 00 02 00 00 00 if w3 == 2 goto +1 <LBB0_66> 138: 05 00 0a 00 00 00 00 00 goto +10 <LBB0_69> 0000000000000458 <LBB0_66>: 139: 69 21 00 00 00 00 00 00 r1 = *(u16 *)(r2 + 0) ; NO CO-RE relocation here ^^^^^^^^^^^^^^^^ 140: 05 00 08 00 00 00 00 00 goto +8 <LBB0_69> 0000000000000468 <LBB0_63>: 141: 16 03 06 00 04 00 00 00 if w3 == 4 goto +6 <LBB0_67> 142: 16 03 01 00 08 00 00 00 if w3 == 8 goto +1 <LBB0_68> 143: 05 00 05 00 00 00 00 00 goto +5 <LBB0_69> 0000000000000480 <LBB0_68>: 144: 79 21 00 00 00 00 00 00 r1 = *(u64 *)(r2 + 0) ; NO CO-RE relocation here ^^^^^^^^^^^^^^^^ 145: 05 00 03 00 00 00 00 00 goto +3 <LBB0_69> 0000000000000490 <LBB0_65>: 146: 71 21 00 00 00 00 00 00 r1 = *(u8 *)(r2 + 0) ; NO CO-RE relocation here ^^^^^^^^^^^^^^^^ 147: 05 00 01 00 00 00 00 00 goto +1 <LBB0_69> 00000000000004a0 <LBB0_67>: 148: 61 21 00 00 00 00 00 00 r1 = *(u32 *)(r2 + 0) ; NO CO-RE relocation here ^^^^^^^^^^^^^^^^ 00000000000004a8 <LBB0_69>: 149: 67 01 00 00 20 00 00 00 r1 <<= 32 150: b7 02 00 00 00 00 00 00 r2 = 0 151: 16 02 02 00 00 00 00 00 if w2 == 0 goto +2 <LBB0_71> 152: c7 01 00 00 20 00 00 00 r1 s>>= 32 153: 05 00 01 00 00 00 00 00 goto +1 <LBB0_72> 00000000000004d0 <LBB0_71>: 154: 77 01 00 00 20 00 00 00 r1 >>= 323 Fixes: ee26dad ("libbpf: Add support for relocatable bitfields") Signed-off-by: Andrii Nakryiko <[email protected]> Signed-off-by: Alexei Starovoitov <[email protected]> Acked-by: Lorenz Bauer <[email protected]> Link: https://lore.kernel.org/bpf/[email protected] Signed-off-by: Sasha Levin <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
May 19, 2021
[ Upstream commit 0f20615 ] Fix BPF_CORE_READ_BITFIELD() macro used for reading CO-RE-relocatable bitfields. Missing breaks in a switch caused 8-byte reads always. This can confuse libbpf because it does strict checks that memory load size corresponds to the original size of the field, which in this case quite often would be wrong. After fixing that, we run into another problem, which quite subtle, so worth documenting here. The issue is in Clang optimization and CO-RE relocation interactions. Without that asm volatile construct (also known as barrier_var()), Clang will re-order BYTE_OFFSET and BYTE_SIZE relocations and will apply BYTE_OFFSET 4 times for each switch case arm. This will result in the same error from libbpf about mismatch of memory load size and original field size. I.e., if we were reading u32, we'd still have *(u8 *), *(u16 *), *(u32 *), and *(u64 *) memory loads, three of which will fail. Using barrier_var() forces Clang to apply BYTE_OFFSET relocation first (and once) to calculate p, after which value of p is used without relocation in each of switch case arms, doing appropiately-sized memory load. Here's the list of relevant relocations and pieces of generated BPF code before and after this patch for test_core_reloc_bitfields_direct selftests. BEFORE ===== #45: core_reloc: insn #160 --> [5] + 0:5: byte_sz --> struct core_reloc_bitfields.u32 #46: core_reloc: insn #167 --> [5] + 0:5: byte_off --> struct core_reloc_bitfields.u32 #47: core_reloc: insn #174 --> [5] + 0:5: byte_off --> struct core_reloc_bitfields.u32 #48: core_reloc: insn #178 --> [5] + 0:5: byte_off --> struct core_reloc_bitfields.u32 #49: core_reloc: insn #182 --> [5] + 0:5: byte_off --> struct core_reloc_bitfields.u32 157: 18 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r2 = 0 ll 159: 7b 12 20 01 00 00 00 00 *(u64 *)(r2 + 288) = r1 160: b7 02 00 00 04 00 00 00 r2 = 4 ; BYTE_SIZE relocation here ^^^ 161: 66 02 07 00 03 00 00 00 if w2 s> 3 goto +7 <LBB0_63> 162: 16 02 0d 00 01 00 00 00 if w2 == 1 goto +13 <LBB0_65> 163: 16 02 01 00 02 00 00 00 if w2 == 2 goto +1 <LBB0_66> 164: 05 00 12 00 00 00 00 00 goto +18 <LBB0_69> 0000000000000528 <LBB0_66>: 165: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll 167: 69 11 08 00 00 00 00 00 r1 = *(u16 *)(r1 + 8) ; BYTE_OFFSET relo here w/ WRONG size ^^^^^^^^^^^^^^^^ 168: 05 00 0e 00 00 00 00 00 goto +14 <LBB0_69> 0000000000000548 <LBB0_63>: 169: 16 02 0a 00 04 00 00 00 if w2 == 4 goto +10 <LBB0_67> 170: 16 02 01 00 08 00 00 00 if w2 == 8 goto +1 <LBB0_68> 171: 05 00 0b 00 00 00 00 00 goto +11 <LBB0_69> 0000000000000560 <LBB0_68>: 172: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll 174: 79 11 08 00 00 00 00 00 r1 = *(u64 *)(r1 + 8) ; BYTE_OFFSET relo here w/ WRONG size ^^^^^^^^^^^^^^^^ 175: 05 00 07 00 00 00 00 00 goto +7 <LBB0_69> 0000000000000580 <LBB0_65>: 176: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll 178: 71 11 08 00 00 00 00 00 r1 = *(u8 *)(r1 + 8) ; BYTE_OFFSET relo here w/ WRONG size ^^^^^^^^^^^^^^^^ 179: 05 00 03 00 00 00 00 00 goto +3 <LBB0_69> 00000000000005a0 <LBB0_67>: 180: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll 182: 61 11 08 00 00 00 00 00 r1 = *(u32 *)(r1 + 8) ; BYTE_OFFSET relo here w/ RIGHT size ^^^^^^^^^^^^^^^^ 00000000000005b8 <LBB0_69>: 183: 67 01 00 00 20 00 00 00 r1 <<= 32 184: b7 02 00 00 00 00 00 00 r2 = 0 185: 16 02 02 00 00 00 00 00 if w2 == 0 goto +2 <LBB0_71> 186: c7 01 00 00 20 00 00 00 r1 s>>= 32 187: 05 00 01 00 00 00 00 00 goto +1 <LBB0_72> 00000000000005e0 <LBB0_71>: 188: 77 01 00 00 20 00 00 00 r1 >>= 32 AFTER ===== #30: core_reloc: insn #132 --> [5] + 0:5: byte_off --> struct core_reloc_bitfields.u32 #31: core_reloc: insn #134 --> [5] + 0:5: byte_sz --> struct core_reloc_bitfields.u32 129: 18 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r2 = 0 ll 131: 7b 12 20 01 00 00 00 00 *(u64 *)(r2 + 288) = r1 132: b7 01 00 00 08 00 00 00 r1 = 8 ; BYTE_OFFSET relo here ^^^ ; no size check for non-memory dereferencing instructions 133: 0f 12 00 00 00 00 00 00 r2 += r1 134: b7 03 00 00 04 00 00 00 r3 = 4 ; BYTE_SIZE relocation here ^^^ 135: 66 03 05 00 03 00 00 00 if w3 s> 3 goto +5 <LBB0_63> 136: 16 03 09 00 01 00 00 00 if w3 == 1 goto +9 <LBB0_65> 137: 16 03 01 00 02 00 00 00 if w3 == 2 goto +1 <LBB0_66> 138: 05 00 0a 00 00 00 00 00 goto +10 <LBB0_69> 0000000000000458 <LBB0_66>: 139: 69 21 00 00 00 00 00 00 r1 = *(u16 *)(r2 + 0) ; NO CO-RE relocation here ^^^^^^^^^^^^^^^^ 140: 05 00 08 00 00 00 00 00 goto +8 <LBB0_69> 0000000000000468 <LBB0_63>: 141: 16 03 06 00 04 00 00 00 if w3 == 4 goto +6 <LBB0_67> 142: 16 03 01 00 08 00 00 00 if w3 == 8 goto +1 <LBB0_68> 143: 05 00 05 00 00 00 00 00 goto +5 <LBB0_69> 0000000000000480 <LBB0_68>: 144: 79 21 00 00 00 00 00 00 r1 = *(u64 *)(r2 + 0) ; NO CO-RE relocation here ^^^^^^^^^^^^^^^^ 145: 05 00 03 00 00 00 00 00 goto +3 <LBB0_69> 0000000000000490 <LBB0_65>: 146: 71 21 00 00 00 00 00 00 r1 = *(u8 *)(r2 + 0) ; NO CO-RE relocation here ^^^^^^^^^^^^^^^^ 147: 05 00 01 00 00 00 00 00 goto +1 <LBB0_69> 00000000000004a0 <LBB0_67>: 148: 61 21 00 00 00 00 00 00 r1 = *(u32 *)(r2 + 0) ; NO CO-RE relocation here ^^^^^^^^^^^^^^^^ 00000000000004a8 <LBB0_69>: 149: 67 01 00 00 20 00 00 00 r1 <<= 32 150: b7 02 00 00 00 00 00 00 r2 = 0 151: 16 02 02 00 00 00 00 00 if w2 == 0 goto +2 <LBB0_71> 152: c7 01 00 00 20 00 00 00 r1 s>>= 32 153: 05 00 01 00 00 00 00 00 goto +1 <LBB0_72> 00000000000004d0 <LBB0_71>: 154: 77 01 00 00 20 00 00 00 r1 >>= 323 Fixes: ee26dad ("libbpf: Add support for relocatable bitfields") Signed-off-by: Andrii Nakryiko <[email protected]> Signed-off-by: Alexei Starovoitov <[email protected]> Acked-by: Lorenz Bauer <[email protected]> Link: https://lore.kernel.org/bpf/[email protected] Signed-off-by: Sasha Levin <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
May 19, 2021
[ Upstream commit 0f20615 ] Fix BPF_CORE_READ_BITFIELD() macro used for reading CO-RE-relocatable bitfields. Missing breaks in a switch caused 8-byte reads always. This can confuse libbpf because it does strict checks that memory load size corresponds to the original size of the field, which in this case quite often would be wrong. After fixing that, we run into another problem, which quite subtle, so worth documenting here. The issue is in Clang optimization and CO-RE relocation interactions. Without that asm volatile construct (also known as barrier_var()), Clang will re-order BYTE_OFFSET and BYTE_SIZE relocations and will apply BYTE_OFFSET 4 times for each switch case arm. This will result in the same error from libbpf about mismatch of memory load size and original field size. I.e., if we were reading u32, we'd still have *(u8 *), *(u16 *), *(u32 *), and *(u64 *) memory loads, three of which will fail. Using barrier_var() forces Clang to apply BYTE_OFFSET relocation first (and once) to calculate p, after which value of p is used without relocation in each of switch case arms, doing appropiately-sized memory load. Here's the list of relevant relocations and pieces of generated BPF code before and after this patch for test_core_reloc_bitfields_direct selftests. BEFORE ===== #45: core_reloc: insn #160 --> [5] + 0:5: byte_sz --> struct core_reloc_bitfields.u32 #46: core_reloc: insn #167 --> [5] + 0:5: byte_off --> struct core_reloc_bitfields.u32 #47: core_reloc: insn #174 --> [5] + 0:5: byte_off --> struct core_reloc_bitfields.u32 #48: core_reloc: insn #178 --> [5] + 0:5: byte_off --> struct core_reloc_bitfields.u32 #49: core_reloc: insn #182 --> [5] + 0:5: byte_off --> struct core_reloc_bitfields.u32 157: 18 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r2 = 0 ll 159: 7b 12 20 01 00 00 00 00 *(u64 *)(r2 + 288) = r1 160: b7 02 00 00 04 00 00 00 r2 = 4 ; BYTE_SIZE relocation here ^^^ 161: 66 02 07 00 03 00 00 00 if w2 s> 3 goto +7 <LBB0_63> 162: 16 02 0d 00 01 00 00 00 if w2 == 1 goto +13 <LBB0_65> 163: 16 02 01 00 02 00 00 00 if w2 == 2 goto +1 <LBB0_66> 164: 05 00 12 00 00 00 00 00 goto +18 <LBB0_69> 0000000000000528 <LBB0_66>: 165: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll 167: 69 11 08 00 00 00 00 00 r1 = *(u16 *)(r1 + 8) ; BYTE_OFFSET relo here w/ WRONG size ^^^^^^^^^^^^^^^^ 168: 05 00 0e 00 00 00 00 00 goto +14 <LBB0_69> 0000000000000548 <LBB0_63>: 169: 16 02 0a 00 04 00 00 00 if w2 == 4 goto +10 <LBB0_67> 170: 16 02 01 00 08 00 00 00 if w2 == 8 goto +1 <LBB0_68> 171: 05 00 0b 00 00 00 00 00 goto +11 <LBB0_69> 0000000000000560 <LBB0_68>: 172: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll 174: 79 11 08 00 00 00 00 00 r1 = *(u64 *)(r1 + 8) ; BYTE_OFFSET relo here w/ WRONG size ^^^^^^^^^^^^^^^^ 175: 05 00 07 00 00 00 00 00 goto +7 <LBB0_69> 0000000000000580 <LBB0_65>: 176: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll 178: 71 11 08 00 00 00 00 00 r1 = *(u8 *)(r1 + 8) ; BYTE_OFFSET relo here w/ WRONG size ^^^^^^^^^^^^^^^^ 179: 05 00 03 00 00 00 00 00 goto +3 <LBB0_69> 00000000000005a0 <LBB0_67>: 180: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll 182: 61 11 08 00 00 00 00 00 r1 = *(u32 *)(r1 + 8) ; BYTE_OFFSET relo here w/ RIGHT size ^^^^^^^^^^^^^^^^ 00000000000005b8 <LBB0_69>: 183: 67 01 00 00 20 00 00 00 r1 <<= 32 184: b7 02 00 00 00 00 00 00 r2 = 0 185: 16 02 02 00 00 00 00 00 if w2 == 0 goto +2 <LBB0_71> 186: c7 01 00 00 20 00 00 00 r1 s>>= 32 187: 05 00 01 00 00 00 00 00 goto +1 <LBB0_72> 00000000000005e0 <LBB0_71>: 188: 77 01 00 00 20 00 00 00 r1 >>= 32 AFTER ===== #30: core_reloc: insn #132 --> [5] + 0:5: byte_off --> struct core_reloc_bitfields.u32 #31: core_reloc: insn #134 --> [5] + 0:5: byte_sz --> struct core_reloc_bitfields.u32 129: 18 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r2 = 0 ll 131: 7b 12 20 01 00 00 00 00 *(u64 *)(r2 + 288) = r1 132: b7 01 00 00 08 00 00 00 r1 = 8 ; BYTE_OFFSET relo here ^^^ ; no size check for non-memory dereferencing instructions 133: 0f 12 00 00 00 00 00 00 r2 += r1 134: b7 03 00 00 04 00 00 00 r3 = 4 ; BYTE_SIZE relocation here ^^^ 135: 66 03 05 00 03 00 00 00 if w3 s> 3 goto +5 <LBB0_63> 136: 16 03 09 00 01 00 00 00 if w3 == 1 goto +9 <LBB0_65> 137: 16 03 01 00 02 00 00 00 if w3 == 2 goto +1 <LBB0_66> 138: 05 00 0a 00 00 00 00 00 goto +10 <LBB0_69> 0000000000000458 <LBB0_66>: 139: 69 21 00 00 00 00 00 00 r1 = *(u16 *)(r2 + 0) ; NO CO-RE relocation here ^^^^^^^^^^^^^^^^ 140: 05 00 08 00 00 00 00 00 goto +8 <LBB0_69> 0000000000000468 <LBB0_63>: 141: 16 03 06 00 04 00 00 00 if w3 == 4 goto +6 <LBB0_67> 142: 16 03 01 00 08 00 00 00 if w3 == 8 goto +1 <LBB0_68> 143: 05 00 05 00 00 00 00 00 goto +5 <LBB0_69> 0000000000000480 <LBB0_68>: 144: 79 21 00 00 00 00 00 00 r1 = *(u64 *)(r2 + 0) ; NO CO-RE relocation here ^^^^^^^^^^^^^^^^ 145: 05 00 03 00 00 00 00 00 goto +3 <LBB0_69> 0000000000000490 <LBB0_65>: 146: 71 21 00 00 00 00 00 00 r1 = *(u8 *)(r2 + 0) ; NO CO-RE relocation here ^^^^^^^^^^^^^^^^ 147: 05 00 01 00 00 00 00 00 goto +1 <LBB0_69> 00000000000004a0 <LBB0_67>: 148: 61 21 00 00 00 00 00 00 r1 = *(u32 *)(r2 + 0) ; NO CO-RE relocation here ^^^^^^^^^^^^^^^^ 00000000000004a8 <LBB0_69>: 149: 67 01 00 00 20 00 00 00 r1 <<= 32 150: b7 02 00 00 00 00 00 00 r2 = 0 151: 16 02 02 00 00 00 00 00 if w2 == 0 goto +2 <LBB0_71> 152: c7 01 00 00 20 00 00 00 r1 s>>= 32 153: 05 00 01 00 00 00 00 00 goto +1 <LBB0_72> 00000000000004d0 <LBB0_71>: 154: 77 01 00 00 20 00 00 00 r1 >>= 323 Fixes: ee26dad ("libbpf: Add support for relocatable bitfields") Signed-off-by: Andrii Nakryiko <[email protected]> Signed-off-by: Alexei Starovoitov <[email protected]> Acked-by: Lorenz Bauer <[email protected]> Link: https://lore.kernel.org/bpf/[email protected] Signed-off-by: Sasha Levin <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Jul 27, 2021
A fstrim on a degraded raid1 can trigger the following null pointer dereference: BTRFS info (device loop0): allowing degraded mounts BTRFS info (device loop0): disk space caching is enabled BTRFS info (device loop0): has skinny extents BTRFS warning (device loop0): devid 2 uuid 97ac16f7-e14d-4db1-95bc-3d489b424adb is missing BTRFS warning (device loop0): devid 2 uuid 97ac16f7-e14d-4db1-95bc-3d489b424adb is missing BTRFS info (device loop0): enabling ssd optimizations BUG: kernel NULL pointer dereference, address: 0000000000000620 PGD 0 P4D 0 Oops: 0000 [#1] SMP NOPTI CPU: 0 PID: 4574 Comm: fstrim Not tainted 5.13.0-rc7+ #31 Hardware name: innotek GmbH VirtualBox/VirtualBox, BIOS VirtualBox 12/01/2006 RIP: 0010:btrfs_trim_fs+0x199/0x4a0 [btrfs] RSP: 0018:ffff959541797d28 EFLAGS: 00010293 RAX: 0000000000000000 RBX: ffff946f84eca508 RCX: a7a67937adff8608 RDX: ffff946e8122d000 RSI: 0000000000000000 RDI: ffffffffc02fdbf0 RBP: ffff946ea4615000 R08: 0000000000000001 R09: 0000000000000000 R10: 0000000000000000 R11: ffff946e8122d960 R12: 0000000000000000 R13: ffff959541797db8 R14: ffff946e8122d000 R15: ffff959541797db8 FS: 00007f55917a5080(0000) GS:ffff946f9bc00000(0000) knlGS:0000000000000000 CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 CR2: 0000000000000620 CR3: 000000002d2c8001 CR4: 00000000000706f0 Call Trace: btrfs_ioctl_fitrim+0x167/0x260 [btrfs] btrfs_ioctl+0x1c00/0x2fe0 [btrfs] ? selinux_file_ioctl+0x140/0x240 ? syscall_trace_enter.constprop.0+0x188/0x240 ? __x64_sys_ioctl+0x83/0xb0 __x64_sys_ioctl+0x83/0xb0 Reproducer: $ mkfs.btrfs -fq -d raid1 -m raid1 /dev/loop0 /dev/loop1 $ mount /dev/loop0 /btrfs $ umount /btrfs $ btrfs dev scan --forget $ mount -o degraded /dev/loop0 /btrfs $ fstrim /btrfs The reason is we call btrfs_trim_free_extents() for the missing device, which uses device->bdev (NULL for missing device) to find if the device supports discard. Fix is to check if the device is missing before calling btrfs_trim_free_extents(). CC: [email protected] # 5.4+ Reviewed-by: Filipe Manana <[email protected]> Signed-off-by: Anand Jain <[email protected]> Reviewed-by: David Sterba <[email protected]> Signed-off-by: David Sterba <[email protected]>
pelwell
pushed a commit
to pelwell/linux
that referenced
this issue
Aug 2, 2021
commit 16a200f upstream. A fstrim on a degraded raid1 can trigger the following null pointer dereference: BTRFS info (device loop0): allowing degraded mounts BTRFS info (device loop0): disk space caching is enabled BTRFS info (device loop0): has skinny extents BTRFS warning (device loop0): devid 2 uuid 97ac16f7-e14d-4db1-95bc-3d489b424adb is missing BTRFS warning (device loop0): devid 2 uuid 97ac16f7-e14d-4db1-95bc-3d489b424adb is missing BTRFS info (device loop0): enabling ssd optimizations BUG: kernel NULL pointer dereference, address: 0000000000000620 PGD 0 P4D 0 Oops: 0000 [#1] SMP NOPTI CPU: 0 PID: 4574 Comm: fstrim Not tainted 5.13.0-rc7+ raspberrypi#31 Hardware name: innotek GmbH VirtualBox/VirtualBox, BIOS VirtualBox 12/01/2006 RIP: 0010:btrfs_trim_fs+0x199/0x4a0 [btrfs] RSP: 0018:ffff959541797d28 EFLAGS: 00010293 RAX: 0000000000000000 RBX: ffff946f84eca508 RCX: a7a67937adff8608 RDX: ffff946e8122d000 RSI: 0000000000000000 RDI: ffffffffc02fdbf0 RBP: ffff946ea4615000 R08: 0000000000000001 R09: 0000000000000000 R10: 0000000000000000 R11: ffff946e8122d960 R12: 0000000000000000 R13: ffff959541797db8 R14: ffff946e8122d000 R15: ffff959541797db8 FS: 00007f55917a5080(0000) GS:ffff946f9bc00000(0000) knlGS:0000000000000000 CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 CR2: 0000000000000620 CR3: 000000002d2c8001 CR4: 00000000000706f0 Call Trace: btrfs_ioctl_fitrim+0x167/0x260 [btrfs] btrfs_ioctl+0x1c00/0x2fe0 [btrfs] ? selinux_file_ioctl+0x140/0x240 ? syscall_trace_enter.constprop.0+0x188/0x240 ? __x64_sys_ioctl+0x83/0xb0 __x64_sys_ioctl+0x83/0xb0 Reproducer: $ mkfs.btrfs -fq -d raid1 -m raid1 /dev/loop0 /dev/loop1 $ mount /dev/loop0 /btrfs $ umount /btrfs $ btrfs dev scan --forget $ mount -o degraded /dev/loop0 /btrfs $ fstrim /btrfs The reason is we call btrfs_trim_free_extents() for the missing device, which uses device->bdev (NULL for missing device) to find if the device supports discard. Fix is to check if the device is missing before calling btrfs_trim_free_extents(). CC: [email protected] # 5.4+ Reviewed-by: Filipe Manana <[email protected]> Signed-off-by: Anand Jain <[email protected]> Reviewed-by: David Sterba <[email protected]> Signed-off-by: David Sterba <[email protected]> Signed-off-by: Greg Kroah-Hartman <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Aug 11, 2021
commit 16a200f upstream. A fstrim on a degraded raid1 can trigger the following null pointer dereference: BTRFS info (device loop0): allowing degraded mounts BTRFS info (device loop0): disk space caching is enabled BTRFS info (device loop0): has skinny extents BTRFS warning (device loop0): devid 2 uuid 97ac16f7-e14d-4db1-95bc-3d489b424adb is missing BTRFS warning (device loop0): devid 2 uuid 97ac16f7-e14d-4db1-95bc-3d489b424adb is missing BTRFS info (device loop0): enabling ssd optimizations BUG: kernel NULL pointer dereference, address: 0000000000000620 PGD 0 P4D 0 Oops: 0000 [#1] SMP NOPTI CPU: 0 PID: 4574 Comm: fstrim Not tainted 5.13.0-rc7+ #31 Hardware name: innotek GmbH VirtualBox/VirtualBox, BIOS VirtualBox 12/01/2006 RIP: 0010:btrfs_trim_fs+0x199/0x4a0 [btrfs] RSP: 0018:ffff959541797d28 EFLAGS: 00010293 RAX: 0000000000000000 RBX: ffff946f84eca508 RCX: a7a67937adff8608 RDX: ffff946e8122d000 RSI: 0000000000000000 RDI: ffffffffc02fdbf0 RBP: ffff946ea4615000 R08: 0000000000000001 R09: 0000000000000000 R10: 0000000000000000 R11: ffff946e8122d960 R12: 0000000000000000 R13: ffff959541797db8 R14: ffff946e8122d000 R15: ffff959541797db8 FS: 00007f55917a5080(0000) GS:ffff946f9bc00000(0000) knlGS:0000000000000000 CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 CR2: 0000000000000620 CR3: 000000002d2c8001 CR4: 00000000000706f0 Call Trace: btrfs_ioctl_fitrim+0x167/0x260 [btrfs] btrfs_ioctl+0x1c00/0x2fe0 [btrfs] ? selinux_file_ioctl+0x140/0x240 ? syscall_trace_enter.constprop.0+0x188/0x240 ? __x64_sys_ioctl+0x83/0xb0 __x64_sys_ioctl+0x83/0xb0 Reproducer: $ mkfs.btrfs -fq -d raid1 -m raid1 /dev/loop0 /dev/loop1 $ mount /dev/loop0 /btrfs $ umount /btrfs $ btrfs dev scan --forget $ mount -o degraded /dev/loop0 /btrfs $ fstrim /btrfs The reason is we call btrfs_trim_free_extents() for the missing device, which uses device->bdev (NULL for missing device) to find if the device supports discard. Fix is to check if the device is missing before calling btrfs_trim_free_extents(). CC: [email protected] # 5.4+ Reviewed-by: Filipe Manana <[email protected]> Signed-off-by: Anand Jain <[email protected]> Reviewed-by: David Sterba <[email protected]> Signed-off-by: David Sterba <[email protected]> Signed-off-by: Greg Kroah-Hartman <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Sep 30, 2021
[ Upstream commit 240e126 ] uart_handle_dcd_change() requires a port lock to be held and will emit a warning when lockdep is enabled. Held corresponding lock to fix the following warnings. [ 132.528648] WARNING: CPU: 5 PID: 11600 at drivers/tty/serial/serial_core.c:3046 uart_handle_dcd_change+0xf4/0x120 [ 132.530482] Modules linked in: [ 132.531050] CPU: 5 PID: 11600 Comm: jsm Not tainted 5.14.0-rc1-00003-g7fef2edf7cc7-dirty #31 [ 132.535268] RIP: 0010:uart_handle_dcd_change+0xf4/0x120 [ 132.557100] Call Trace: [ 132.557562] ? __free_pages+0x83/0xb0 [ 132.558213] neo_parse_modem+0x156/0x220 [ 132.558897] neo_param+0x399/0x840 [ 132.559495] jsm_tty_open+0x12f/0x2d0 [ 132.560131] uart_startup.part.18+0x153/0x340 [ 132.560888] ? lock_is_held_type+0xe9/0x140 [ 132.561660] uart_port_activate+0x7f/0xe0 [ 132.562351] ? uart_startup.part.18+0x340/0x340 [ 132.563003] tty_port_open+0x8d/0xf0 [ 132.563523] ? uart_set_options+0x1e0/0x1e0 [ 132.564125] uart_open+0x24/0x40 [ 132.564604] tty_open+0x15c/0x630 Signed-off-by: Zheyu Ma <[email protected]> Link: https://lore.kernel.org/r/[email protected] Signed-off-by: Greg Kroah-Hartman <[email protected]> Signed-off-by: Sasha Levin <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Sep 30, 2021
[ Upstream commit 240e126 ] uart_handle_dcd_change() requires a port lock to be held and will emit a warning when lockdep is enabled. Held corresponding lock to fix the following warnings. [ 132.528648] WARNING: CPU: 5 PID: 11600 at drivers/tty/serial/serial_core.c:3046 uart_handle_dcd_change+0xf4/0x120 [ 132.530482] Modules linked in: [ 132.531050] CPU: 5 PID: 11600 Comm: jsm Not tainted 5.14.0-rc1-00003-g7fef2edf7cc7-dirty #31 [ 132.535268] RIP: 0010:uart_handle_dcd_change+0xf4/0x120 [ 132.557100] Call Trace: [ 132.557562] ? __free_pages+0x83/0xb0 [ 132.558213] neo_parse_modem+0x156/0x220 [ 132.558897] neo_param+0x399/0x840 [ 132.559495] jsm_tty_open+0x12f/0x2d0 [ 132.560131] uart_startup.part.18+0x153/0x340 [ 132.560888] ? lock_is_held_type+0xe9/0x140 [ 132.561660] uart_port_activate+0x7f/0xe0 [ 132.562351] ? uart_startup.part.18+0x340/0x340 [ 132.563003] tty_port_open+0x8d/0xf0 [ 132.563523] ? uart_set_options+0x1e0/0x1e0 [ 132.564125] uart_open+0x24/0x40 [ 132.564604] tty_open+0x15c/0x630 Signed-off-by: Zheyu Ma <[email protected]> Link: https://lore.kernel.org/r/[email protected] Signed-off-by: Greg Kroah-Hartman <[email protected]> Signed-off-by: Sasha Levin <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Oct 14, 2021
[ Upstream commit 240e126 ] uart_handle_dcd_change() requires a port lock to be held and will emit a warning when lockdep is enabled. Held corresponding lock to fix the following warnings. [ 132.528648] WARNING: CPU: 5 PID: 11600 at drivers/tty/serial/serial_core.c:3046 uart_handle_dcd_change+0xf4/0x120 [ 132.530482] Modules linked in: [ 132.531050] CPU: 5 PID: 11600 Comm: jsm Not tainted 5.14.0-rc1-00003-g7fef2edf7cc7-dirty #31 [ 132.535268] RIP: 0010:uart_handle_dcd_change+0xf4/0x120 [ 132.557100] Call Trace: [ 132.557562] ? __free_pages+0x83/0xb0 [ 132.558213] neo_parse_modem+0x156/0x220 [ 132.558897] neo_param+0x399/0x840 [ 132.559495] jsm_tty_open+0x12f/0x2d0 [ 132.560131] uart_startup.part.18+0x153/0x340 [ 132.560888] ? lock_is_held_type+0xe9/0x140 [ 132.561660] uart_port_activate+0x7f/0xe0 [ 132.562351] ? uart_startup.part.18+0x340/0x340 [ 132.563003] tty_port_open+0x8d/0xf0 [ 132.563523] ? uart_set_options+0x1e0/0x1e0 [ 132.564125] uart_open+0x24/0x40 [ 132.564604] tty_open+0x15c/0x630 Signed-off-by: Zheyu Ma <[email protected]> Link: https://lore.kernel.org/r/[email protected] Signed-off-by: Greg Kroah-Hartman <[email protected]> Signed-off-by: Sasha Levin <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Nov 22, 2021
[ Upstream commit d412137 ] The perf_buffer fails on system with offline cpus: # test_progs -t perf_buffer test_perf_buffer:PASS:nr_cpus 0 nsec test_perf_buffer:PASS:nr_on_cpus 0 nsec test_perf_buffer:PASS:skel_load 0 nsec test_perf_buffer:PASS:attach_kprobe 0 nsec test_perf_buffer:PASS:perf_buf__new 0 nsec test_perf_buffer:PASS:epoll_fd 0 nsec skipping offline CPU #24 skipping offline CPU #25 skipping offline CPU #26 skipping offline CPU #27 skipping offline CPU #28 skipping offline CPU #29 skipping offline CPU #30 skipping offline CPU #31 test_perf_buffer:PASS:perf_buffer__poll 0 nsec test_perf_buffer:PASS:seen_cpu_cnt 0 nsec test_perf_buffer:FAIL:buf_cnt got 24, expected 32 Summary: 0/0 PASSED, 0 SKIPPED, 1 FAILED Changing the test to check online cpus instead of possible. Signed-off-by: Jiri Olsa <[email protected]> Signed-off-by: Andrii Nakryiko <[email protected]> Acked-by: John Fastabend <[email protected]> Link: https://lore.kernel.org/bpf/[email protected] Signed-off-by: Sasha Levin <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Nov 22, 2021
[ Upstream commit d412137 ] The perf_buffer fails on system with offline cpus: # test_progs -t perf_buffer test_perf_buffer:PASS:nr_cpus 0 nsec test_perf_buffer:PASS:nr_on_cpus 0 nsec test_perf_buffer:PASS:skel_load 0 nsec test_perf_buffer:PASS:attach_kprobe 0 nsec test_perf_buffer:PASS:perf_buf__new 0 nsec test_perf_buffer:PASS:epoll_fd 0 nsec skipping offline CPU #24 skipping offline CPU #25 skipping offline CPU #26 skipping offline CPU #27 skipping offline CPU #28 skipping offline CPU #29 skipping offline CPU #30 skipping offline CPU #31 test_perf_buffer:PASS:perf_buffer__poll 0 nsec test_perf_buffer:PASS:seen_cpu_cnt 0 nsec test_perf_buffer:FAIL:buf_cnt got 24, expected 32 Summary: 0/0 PASSED, 0 SKIPPED, 1 FAILED Changing the test to check online cpus instead of possible. Signed-off-by: Jiri Olsa <[email protected]> Signed-off-by: Andrii Nakryiko <[email protected]> Acked-by: John Fastabend <[email protected]> Link: https://lore.kernel.org/bpf/[email protected] Signed-off-by: Sasha Levin <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Nov 29, 2021
[ Upstream commit d412137 ] The perf_buffer fails on system with offline cpus: # test_progs -t perf_buffer test_perf_buffer:PASS:nr_cpus 0 nsec test_perf_buffer:PASS:nr_on_cpus 0 nsec test_perf_buffer:PASS:skel_load 0 nsec test_perf_buffer:PASS:attach_kprobe 0 nsec test_perf_buffer:PASS:perf_buf__new 0 nsec test_perf_buffer:PASS:epoll_fd 0 nsec skipping offline CPU #24 skipping offline CPU #25 skipping offline CPU #26 skipping offline CPU #27 skipping offline CPU #28 skipping offline CPU #29 skipping offline CPU #30 skipping offline CPU #31 test_perf_buffer:PASS:perf_buffer__poll 0 nsec test_perf_buffer:PASS:seen_cpu_cnt 0 nsec test_perf_buffer:FAIL:buf_cnt got 24, expected 32 Summary: 0/0 PASSED, 0 SKIPPED, 1 FAILED Changing the test to check online cpus instead of possible. Signed-off-by: Jiri Olsa <[email protected]> Signed-off-by: Andrii Nakryiko <[email protected]> Acked-by: John Fastabend <[email protected]> Link: https://lore.kernel.org/bpf/[email protected] Signed-off-by: Sasha Levin <[email protected]>
nguyenanhgiau
pushed a commit
to nguyenanhgiau/linux
that referenced
this issue
Jan 5, 2022
[ Upstream commit 240e126 ] uart_handle_dcd_change() requires a port lock to be held and will emit a warning when lockdep is enabled. Held corresponding lock to fix the following warnings. [ 132.528648] WARNING: CPU: 5 PID: 11600 at drivers/tty/serial/serial_core.c:3046 uart_handle_dcd_change+0xf4/0x120 [ 132.530482] Modules linked in: [ 132.531050] CPU: 5 PID: 11600 Comm: jsm Not tainted 5.14.0-rc1-00003-g7fef2edf7cc7-dirty raspberrypi#31 [ 132.535268] RIP: 0010:uart_handle_dcd_change+0xf4/0x120 [ 132.557100] Call Trace: [ 132.557562] ? __free_pages+0x83/0xb0 [ 132.558213] neo_parse_modem+0x156/0x220 [ 132.558897] neo_param+0x399/0x840 [ 132.559495] jsm_tty_open+0x12f/0x2d0 [ 132.560131] uart_startup.part.18+0x153/0x340 [ 132.560888] ? lock_is_held_type+0xe9/0x140 [ 132.561660] uart_port_activate+0x7f/0xe0 [ 132.562351] ? uart_startup.part.18+0x340/0x340 [ 132.563003] tty_port_open+0x8d/0xf0 [ 132.563523] ? uart_set_options+0x1e0/0x1e0 [ 132.564125] uart_open+0x24/0x40 [ 132.564604] tty_open+0x15c/0x630 Signed-off-by: Zheyu Ma <[email protected]> Link: https://lore.kernel.org/r/[email protected] Signed-off-by: Greg Kroah-Hartman <[email protected]> Signed-off-by: Sasha Levin <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Aug 8, 2023
The below crash can be encountered when using xdpsock in rx mode for legacy rq: the buffer gets released in the XDP_REDIRECT path, and then once again in the driver. This fix sets the flag to avoid releasing on the driver side. XSK handling of buffers for legacy rq was relying on the caller to set the skip release flag. But the referenced fix started using fragment counts for pages instead of the skip flag. Crash log: general protection fault, probably for non-canonical address 0xffff8881217e3a: 0000 [#1] SMP CPU: 0 PID: 14 Comm: ksoftirqd/0 Not tainted 6.5.0-rc1+ #31 Hardware name: QEMU Standard PC (Q35 + ICH9, 2009), BIOS rel-1.13.0-0-gf21b5a4aeb02-prebuilt.qemu.org 04/01/2014 RIP: 0010:bpf_prog_03b13f331978c78c+0xf/0x28 Code: ... RSP: 0018:ffff88810082fc98 EFLAGS: 00010246 RAX: 0000000000000000 RBX: ffff888138404901 RCX: c0ffffc900027cbc RDX: ffffffffa000b514 RSI: 00ffff8881217e32 RDI: ffff888138404901 RBP: ffff88810082fc98 R08: 0000000000091100 R09: 0000000000000006 R10: 0000000000000800 R11: 0000000000000800 R12: ffffc9000027a000 R13: ffff8881217e2dc0 R14: ffff8881217e2910 R15: ffff8881217e2f00 FS: 0000000000000000(0000) GS:ffff88852c800000(0000) knlGS:0000000000000000 CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 CR2: 0000564cb2e2cde0 CR3: 000000010e603004 CR4: 0000000000370eb0 DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 Call Trace: <TASK> ? die_addr+0x32/0x80 ? exc_general_protection+0x192/0x390 ? asm_exc_general_protection+0x22/0x30 ? 0xffffffffa000b514 ? bpf_prog_03b13f331978c78c+0xf/0x28 mlx5e_xdp_handle+0x48/0x670 [mlx5_core] ? dev_gro_receive+0x3b5/0x6e0 mlx5e_xsk_skb_from_cqe_linear+0x6e/0x90 [mlx5_core] mlx5e_handle_rx_cqe+0x55/0x100 [mlx5_core] mlx5e_poll_rx_cq+0x87/0x6e0 [mlx5_core] mlx5e_napi_poll+0x45e/0x6b0 [mlx5_core] __napi_poll+0x25/0x1a0 net_rx_action+0x28a/0x300 __do_softirq+0xcd/0x279 ? sort_range+0x20/0x20 run_ksoftirqd+0x1a/0x20 smpboot_thread_fn+0xa2/0x130 kthread+0xc9/0xf0 ? kthread_complete_and_exit+0x20/0x20 ret_from_fork+0x1f/0x30 </TASK> Modules linked in: mlx5_ib mlx5_core rpcrdma rdma_ucm ib_iser libiscsi scsi_transport_iscsi ib_umad rdma_cm ib_ipoib iw_cm ib_cm ib_uverbs ib_core xt_conntrack xt_MASQUERADE nf_conntrack_netlink nfnetlink xt_addrtype iptable_nat nf_nat br_netfilter overlay zram zsmalloc fuse [last unloaded: mlx5_core] ---[ end trace 0000000000000000 ]--- Fixes: 7abd955 ("net/mlx5e: RX, Fix page_pool page fragment tracking for XDP") Signed-off-by: Dragos Tatulea <[email protected]> Reviewed-by: Tariq Toukan <[email protected]> Signed-off-by: Saeed Mahameed <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Aug 17, 2023
[ Upstream commit e0f5229 ] The below crash can be encountered when using xdpsock in rx mode for legacy rq: the buffer gets released in the XDP_REDIRECT path, and then once again in the driver. This fix sets the flag to avoid releasing on the driver side. XSK handling of buffers for legacy rq was relying on the caller to set the skip release flag. But the referenced fix started using fragment counts for pages instead of the skip flag. Crash log: general protection fault, probably for non-canonical address 0xffff8881217e3a: 0000 [#1] SMP CPU: 0 PID: 14 Comm: ksoftirqd/0 Not tainted 6.5.0-rc1+ #31 Hardware name: QEMU Standard PC (Q35 + ICH9, 2009), BIOS rel-1.13.0-0-gf21b5a4aeb02-prebuilt.qemu.org 04/01/2014 RIP: 0010:bpf_prog_03b13f331978c78c+0xf/0x28 Code: ... RSP: 0018:ffff88810082fc98 EFLAGS: 00010246 RAX: 0000000000000000 RBX: ffff888138404901 RCX: c0ffffc900027cbc RDX: ffffffffa000b514 RSI: 00ffff8881217e32 RDI: ffff888138404901 RBP: ffff88810082fc98 R08: 0000000000091100 R09: 0000000000000006 R10: 0000000000000800 R11: 0000000000000800 R12: ffffc9000027a000 R13: ffff8881217e2dc0 R14: ffff8881217e2910 R15: ffff8881217e2f00 FS: 0000000000000000(0000) GS:ffff88852c800000(0000) knlGS:0000000000000000 CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 CR2: 0000564cb2e2cde0 CR3: 000000010e603004 CR4: 0000000000370eb0 DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 Call Trace: <TASK> ? die_addr+0x32/0x80 ? exc_general_protection+0x192/0x390 ? asm_exc_general_protection+0x22/0x30 ? 0xffffffffa000b514 ? bpf_prog_03b13f331978c78c+0xf/0x28 mlx5e_xdp_handle+0x48/0x670 [mlx5_core] ? dev_gro_receive+0x3b5/0x6e0 mlx5e_xsk_skb_from_cqe_linear+0x6e/0x90 [mlx5_core] mlx5e_handle_rx_cqe+0x55/0x100 [mlx5_core] mlx5e_poll_rx_cq+0x87/0x6e0 [mlx5_core] mlx5e_napi_poll+0x45e/0x6b0 [mlx5_core] __napi_poll+0x25/0x1a0 net_rx_action+0x28a/0x300 __do_softirq+0xcd/0x279 ? sort_range+0x20/0x20 run_ksoftirqd+0x1a/0x20 smpboot_thread_fn+0xa2/0x130 kthread+0xc9/0xf0 ? kthread_complete_and_exit+0x20/0x20 ret_from_fork+0x1f/0x30 </TASK> Modules linked in: mlx5_ib mlx5_core rpcrdma rdma_ucm ib_iser libiscsi scsi_transport_iscsi ib_umad rdma_cm ib_ipoib iw_cm ib_cm ib_uverbs ib_core xt_conntrack xt_MASQUERADE nf_conntrack_netlink nfnetlink xt_addrtype iptable_nat nf_nat br_netfilter overlay zram zsmalloc fuse [last unloaded: mlx5_core] ---[ end trace 0000000000000000 ]--- Fixes: 7abd955 ("net/mlx5e: RX, Fix page_pool page fragment tracking for XDP") Signed-off-by: Dragos Tatulea <[email protected]> Reviewed-by: Tariq Toukan <[email protected]> Signed-off-by: Saeed Mahameed <[email protected]> Signed-off-by: Sasha Levin <[email protected]>
0lxb
pushed a commit
to 0lxb/rpi_linux
that referenced
this issue
Jan 30, 2024
scx_atropos: Update various dependencies
popcornmix
pushed a commit
that referenced
this issue
Mar 5, 2024
[ Upstream commit a7d6027 ] syzkaller reported an overflown write in arp_req_get(). [0] When ioctl(SIOCGARP) is issued, arp_req_get() looks up an neighbour entry and copies neigh->ha to struct arpreq.arp_ha.sa_data. The arp_ha here is struct sockaddr, not struct sockaddr_storage, so the sa_data buffer is just 14 bytes. In the splat below, 2 bytes are overflown to the next int field, arp_flags. We initialise the field just after the memcpy(), so it's not a problem. However, when dev->addr_len is greater than 22 (e.g. MAX_ADDR_LEN), arp_netmask is overwritten, which could be set as htonl(0xFFFFFFFFUL) in arp_ioctl() before calling arp_req_get(). To avoid the overflow, let's limit the max length of memcpy(). Note that commit b5f0de6 ("net: dev: Convert sa_data to flexible array in struct sockaddr") just silenced syzkaller. [0]: memcpy: detected field-spanning write (size 16) of single field "r->arp_ha.sa_data" at net/ipv4/arp.c:1128 (size 14) WARNING: CPU: 0 PID: 144638 at net/ipv4/arp.c:1128 arp_req_get+0x411/0x4a0 net/ipv4/arp.c:1128 Modules linked in: CPU: 0 PID: 144638 Comm: syz-executor.4 Not tainted 6.1.74 #31 Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS 1.16.0-debian-1.16.0-5 04/01/2014 RIP: 0010:arp_req_get+0x411/0x4a0 net/ipv4/arp.c:1128 Code: fd ff ff e8 41 42 de fb b9 0e 00 00 00 4c 89 fe 48 c7 c2 20 6d ab 87 48 c7 c7 80 6d ab 87 c6 05 25 af 72 04 01 e8 5f 8d ad fb <0f> 0b e9 6c fd ff ff e8 13 42 de fb be 03 00 00 00 4c 89 e7 e8 a6 RSP: 0018:ffffc900050b7998 EFLAGS: 00010286 RAX: 0000000000000000 RBX: ffff88803a815000 RCX: 0000000000000000 RDX: 0000000000000000 RSI: ffffffff8641a44a RDI: 0000000000000001 RBP: ffffc900050b7a98 R08: 0000000000000001 R09: 0000000000000000 R10: 0000000000000000 R11: 203a7970636d656d R12: ffff888039c54000 R13: 1ffff92000a16f37 R14: ffff88803a815084 R15: 0000000000000010 FS: 00007f172bf306c0(0000) GS:ffff88805aa00000(0000) knlGS:0000000000000000 CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 CR2: 00007f172b3569f0 CR3: 0000000057f12005 CR4: 0000000000770ef0 DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 PKRU: 55555554 Call Trace: <TASK> arp_ioctl+0x33f/0x4b0 net/ipv4/arp.c:1261 inet_ioctl+0x314/0x3a0 net/ipv4/af_inet.c:981 sock_do_ioctl+0xdf/0x260 net/socket.c:1204 sock_ioctl+0x3ef/0x650 net/socket.c:1321 vfs_ioctl fs/ioctl.c:51 [inline] __do_sys_ioctl fs/ioctl.c:870 [inline] __se_sys_ioctl fs/ioctl.c:856 [inline] __x64_sys_ioctl+0x18e/0x220 fs/ioctl.c:856 do_syscall_x64 arch/x86/entry/common.c:51 [inline] do_syscall_64+0x37/0x90 arch/x86/entry/common.c:81 entry_SYSCALL_64_after_hwframe+0x64/0xce RIP: 0033:0x7f172b262b8d Code: 66 2e 0f 1f 84 00 00 00 00 00 0f 1f 00 f3 0f 1e fa 48 89 f8 48 89 f7 48 89 d6 48 89 ca 4d 89 c2 4d 89 c8 4c 8b 4c 24 08 0f 05 <48> 3d 01 f0 ff ff 73 01 c3 48 c7 c1 b8 ff ff ff f7 d8 64 89 01 48 RSP: 002b:00007f172bf300b8 EFLAGS: 00000246 ORIG_RAX: 0000000000000010 RAX: ffffffffffffffda RBX: 00007f172b3abf80 RCX: 00007f172b262b8d RDX: 0000000020000000 RSI: 0000000000008954 RDI: 0000000000000003 RBP: 00007f172b2d3493 R08: 0000000000000000 R09: 0000000000000000 R10: 0000000000000000 R11: 0000000000000246 R12: 0000000000000000 R13: 000000000000000b R14: 00007f172b3abf80 R15: 00007f172bf10000 </TASK> Reported-by: syzkaller <[email protected]> Reported-by: Bjoern Doebel <[email protected]> Fixes: 1da177e ("Linux-2.6.12-rc2") Signed-off-by: Kuniyuki Iwashima <[email protected]> Link: https://lore.kernel.org/r/[email protected] Signed-off-by: Paolo Abeni <[email protected]> Signed-off-by: Sasha Levin <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Mar 5, 2024
syzkaller reported an overflown write in arp_req_get(). [0] When ioctl(SIOCGARP) is issued, arp_req_get() looks up an neighbour entry and copies neigh->ha to struct arpreq.arp_ha.sa_data. The arp_ha here is struct sockaddr, not struct sockaddr_storage, so the sa_data buffer is just 14 bytes. In the splat below, 2 bytes are overflown to the next int field, arp_flags. We initialise the field just after the memcpy(), so it's not a problem. However, when dev->addr_len is greater than 22 (e.g. MAX_ADDR_LEN), arp_netmask is overwritten, which could be set as htonl(0xFFFFFFFFUL) in arp_ioctl() before calling arp_req_get(). To avoid the overflow, let's limit the max length of memcpy(). Note that commit b5f0de6 ("net: dev: Convert sa_data to flexible array in struct sockaddr") just silenced syzkaller. [0]: memcpy: detected field-spanning write (size 16) of single field "r->arp_ha.sa_data" at net/ipv4/arp.c:1128 (size 14) WARNING: CPU: 0 PID: 144638 at net/ipv4/arp.c:1128 arp_req_get+0x411/0x4a0 net/ipv4/arp.c:1128 Modules linked in: CPU: 0 PID: 144638 Comm: syz-executor.4 Not tainted 6.1.74 #31 Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS 1.16.0-debian-1.16.0-5 04/01/2014 RIP: 0010:arp_req_get+0x411/0x4a0 net/ipv4/arp.c:1128 Code: fd ff ff e8 41 42 de fb b9 0e 00 00 00 4c 89 fe 48 c7 c2 20 6d ab 87 48 c7 c7 80 6d ab 87 c6 05 25 af 72 04 01 e8 5f 8d ad fb <0f> 0b e9 6c fd ff ff e8 13 42 de fb be 03 00 00 00 4c 89 e7 e8 a6 RSP: 0018:ffffc900050b7998 EFLAGS: 00010286 RAX: 0000000000000000 RBX: ffff88803a815000 RCX: 0000000000000000 RDX: 0000000000000000 RSI: ffffffff8641a44a RDI: 0000000000000001 RBP: ffffc900050b7a98 R08: 0000000000000001 R09: 0000000000000000 R10: 0000000000000000 R11: 203a7970636d656d R12: ffff888039c54000 R13: 1ffff92000a16f37 R14: ffff88803a815084 R15: 0000000000000010 FS: 00007f172bf306c0(0000) GS:ffff88805aa00000(0000) knlGS:0000000000000000 CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 CR2: 00007f172b3569f0 CR3: 0000000057f12005 CR4: 0000000000770ef0 DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 PKRU: 55555554 Call Trace: <TASK> arp_ioctl+0x33f/0x4b0 net/ipv4/arp.c:1261 inet_ioctl+0x314/0x3a0 net/ipv4/af_inet.c:981 sock_do_ioctl+0xdf/0x260 net/socket.c:1204 sock_ioctl+0x3ef/0x650 net/socket.c:1321 vfs_ioctl fs/ioctl.c:51 [inline] __do_sys_ioctl fs/ioctl.c:870 [inline] __se_sys_ioctl fs/ioctl.c:856 [inline] __x64_sys_ioctl+0x18e/0x220 fs/ioctl.c:856 do_syscall_x64 arch/x86/entry/common.c:51 [inline] do_syscall_64+0x37/0x90 arch/x86/entry/common.c:81 entry_SYSCALL_64_after_hwframe+0x64/0xce RIP: 0033:0x7f172b262b8d Code: 66 2e 0f 1f 84 00 00 00 00 00 0f 1f 00 f3 0f 1e fa 48 89 f8 48 89 f7 48 89 d6 48 89 ca 4d 89 c2 4d 89 c8 4c 8b 4c 24 08 0f 05 <48> 3d 01 f0 ff ff 73 01 c3 48 c7 c1 b8 ff ff ff f7 d8 64 89 01 48 RSP: 002b:00007f172bf300b8 EFLAGS: 00000246 ORIG_RAX: 0000000000000010 RAX: ffffffffffffffda RBX: 00007f172b3abf80 RCX: 00007f172b262b8d RDX: 0000000020000000 RSI: 0000000000008954 RDI: 0000000000000003 RBP: 00007f172b2d3493 R08: 0000000000000000 R09: 0000000000000000 R10: 0000000000000000 R11: 0000000000000246 R12: 0000000000000000 R13: 000000000000000b R14: 00007f172b3abf80 R15: 00007f172bf10000 </TASK> Reported-by: syzkaller <[email protected]> Reported-by: Bjoern Doebel <[email protected]> Fixes: 1da177e ("Linux-2.6.12-rc2") Signed-off-by: Kuniyuki Iwashima <[email protected]> Link: https://lore.kernel.org/r/[email protected] Signed-off-by: Paolo Abeni <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Mar 5, 2024
[ Upstream commit a7d6027 ] syzkaller reported an overflown write in arp_req_get(). [0] When ioctl(SIOCGARP) is issued, arp_req_get() looks up an neighbour entry and copies neigh->ha to struct arpreq.arp_ha.sa_data. The arp_ha here is struct sockaddr, not struct sockaddr_storage, so the sa_data buffer is just 14 bytes. In the splat below, 2 bytes are overflown to the next int field, arp_flags. We initialise the field just after the memcpy(), so it's not a problem. However, when dev->addr_len is greater than 22 (e.g. MAX_ADDR_LEN), arp_netmask is overwritten, which could be set as htonl(0xFFFFFFFFUL) in arp_ioctl() before calling arp_req_get(). To avoid the overflow, let's limit the max length of memcpy(). Note that commit b5f0de6 ("net: dev: Convert sa_data to flexible array in struct sockaddr") just silenced syzkaller. [0]: memcpy: detected field-spanning write (size 16) of single field "r->arp_ha.sa_data" at net/ipv4/arp.c:1128 (size 14) WARNING: CPU: 0 PID: 144638 at net/ipv4/arp.c:1128 arp_req_get+0x411/0x4a0 net/ipv4/arp.c:1128 Modules linked in: CPU: 0 PID: 144638 Comm: syz-executor.4 Not tainted 6.1.74 #31 Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS 1.16.0-debian-1.16.0-5 04/01/2014 RIP: 0010:arp_req_get+0x411/0x4a0 net/ipv4/arp.c:1128 Code: fd ff ff e8 41 42 de fb b9 0e 00 00 00 4c 89 fe 48 c7 c2 20 6d ab 87 48 c7 c7 80 6d ab 87 c6 05 25 af 72 04 01 e8 5f 8d ad fb <0f> 0b e9 6c fd ff ff e8 13 42 de fb be 03 00 00 00 4c 89 e7 e8 a6 RSP: 0018:ffffc900050b7998 EFLAGS: 00010286 RAX: 0000000000000000 RBX: ffff88803a815000 RCX: 0000000000000000 RDX: 0000000000000000 RSI: ffffffff8641a44a RDI: 0000000000000001 RBP: ffffc900050b7a98 R08: 0000000000000001 R09: 0000000000000000 R10: 0000000000000000 R11: 203a7970636d656d R12: ffff888039c54000 R13: 1ffff92000a16f37 R14: ffff88803a815084 R15: 0000000000000010 FS: 00007f172bf306c0(0000) GS:ffff88805aa00000(0000) knlGS:0000000000000000 CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 CR2: 00007f172b3569f0 CR3: 0000000057f12005 CR4: 0000000000770ef0 DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 PKRU: 55555554 Call Trace: <TASK> arp_ioctl+0x33f/0x4b0 net/ipv4/arp.c:1261 inet_ioctl+0x314/0x3a0 net/ipv4/af_inet.c:981 sock_do_ioctl+0xdf/0x260 net/socket.c:1204 sock_ioctl+0x3ef/0x650 net/socket.c:1321 vfs_ioctl fs/ioctl.c:51 [inline] __do_sys_ioctl fs/ioctl.c:870 [inline] __se_sys_ioctl fs/ioctl.c:856 [inline] __x64_sys_ioctl+0x18e/0x220 fs/ioctl.c:856 do_syscall_x64 arch/x86/entry/common.c:51 [inline] do_syscall_64+0x37/0x90 arch/x86/entry/common.c:81 entry_SYSCALL_64_after_hwframe+0x64/0xce RIP: 0033:0x7f172b262b8d Code: 66 2e 0f 1f 84 00 00 00 00 00 0f 1f 00 f3 0f 1e fa 48 89 f8 48 89 f7 48 89 d6 48 89 ca 4d 89 c2 4d 89 c8 4c 8b 4c 24 08 0f 05 <48> 3d 01 f0 ff ff 73 01 c3 48 c7 c1 b8 ff ff ff f7 d8 64 89 01 48 RSP: 002b:00007f172bf300b8 EFLAGS: 00000246 ORIG_RAX: 0000000000000010 RAX: ffffffffffffffda RBX: 00007f172b3abf80 RCX: 00007f172b262b8d RDX: 0000000020000000 RSI: 0000000000008954 RDI: 0000000000000003 RBP: 00007f172b2d3493 R08: 0000000000000000 R09: 0000000000000000 R10: 0000000000000000 R11: 0000000000000246 R12: 0000000000000000 R13: 000000000000000b R14: 00007f172b3abf80 R15: 00007f172bf10000 </TASK> Reported-by: syzkaller <[email protected]> Reported-by: Bjoern Doebel <[email protected]> Fixes: 1da177e ("Linux-2.6.12-rc2") Signed-off-by: Kuniyuki Iwashima <[email protected]> Link: https://lore.kernel.org/r/[email protected] Signed-off-by: Paolo Abeni <[email protected]> Signed-off-by: Sasha Levin <[email protected]>
spockfish
pushed a commit
to RoPieee/linux
that referenced
this issue
Mar 8, 2024
commit a7d6027 upstream. syzkaller reported an overflown write in arp_req_get(). [0] When ioctl(SIOCGARP) is issued, arp_req_get() looks up an neighbour entry and copies neigh->ha to struct arpreq.arp_ha.sa_data. The arp_ha here is struct sockaddr, not struct sockaddr_storage, so the sa_data buffer is just 14 bytes. In the splat below, 2 bytes are overflown to the next int field, arp_flags. We initialise the field just after the memcpy(), so it's not a problem. However, when dev->addr_len is greater than 22 (e.g. MAX_ADDR_LEN), arp_netmask is overwritten, which could be set as htonl(0xFFFFFFFFUL) in arp_ioctl() before calling arp_req_get(). To avoid the overflow, let's limit the max length of memcpy(). Note that commit b5f0de6 ("net: dev: Convert sa_data to flexible array in struct sockaddr") just silenced syzkaller. [0]: memcpy: detected field-spanning write (size 16) of single field "r->arp_ha.sa_data" at net/ipv4/arp.c:1128 (size 14) WARNING: CPU: 0 PID: 144638 at net/ipv4/arp.c:1128 arp_req_get+0x411/0x4a0 net/ipv4/arp.c:1128 Modules linked in: CPU: 0 PID: 144638 Comm: syz-executor.4 Not tainted 6.1.74 raspberrypi#31 Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS 1.16.0-debian-1.16.0-5 04/01/2014 RIP: 0010:arp_req_get+0x411/0x4a0 net/ipv4/arp.c:1128 Code: fd ff ff e8 41 42 de fb b9 0e 00 00 00 4c 89 fe 48 c7 c2 20 6d ab 87 48 c7 c7 80 6d ab 87 c6 05 25 af 72 04 01 e8 5f 8d ad fb <0f> 0b e9 6c fd ff ff e8 13 42 de fb be 03 00 00 00 4c 89 e7 e8 a6 RSP: 0018:ffffc900050b7998 EFLAGS: 00010286 RAX: 0000000000000000 RBX: ffff88803a815000 RCX: 0000000000000000 RDX: 0000000000000000 RSI: ffffffff8641a44a RDI: 0000000000000001 RBP: ffffc900050b7a98 R08: 0000000000000001 R09: 0000000000000000 R10: 0000000000000000 R11: 203a7970636d656d R12: ffff888039c54000 R13: 1ffff92000a16f37 R14: ffff88803a815084 R15: 0000000000000010 FS: 00007f172bf306c0(0000) GS:ffff88805aa00000(0000) knlGS:0000000000000000 CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 CR2: 00007f172b3569f0 CR3: 0000000057f12005 CR4: 0000000000770ef0 DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 PKRU: 55555554 Call Trace: <TASK> arp_ioctl+0x33f/0x4b0 net/ipv4/arp.c:1261 inet_ioctl+0x314/0x3a0 net/ipv4/af_inet.c:981 sock_do_ioctl+0xdf/0x260 net/socket.c:1204 sock_ioctl+0x3ef/0x650 net/socket.c:1321 vfs_ioctl fs/ioctl.c:51 [inline] __do_sys_ioctl fs/ioctl.c:870 [inline] __se_sys_ioctl fs/ioctl.c:856 [inline] __x64_sys_ioctl+0x18e/0x220 fs/ioctl.c:856 do_syscall_x64 arch/x86/entry/common.c:51 [inline] do_syscall_64+0x37/0x90 arch/x86/entry/common.c:81 entry_SYSCALL_64_after_hwframe+0x64/0xce RIP: 0033:0x7f172b262b8d Code: 66 2e 0f 1f 84 00 00 00 00 00 0f 1f 00 f3 0f 1e fa 48 89 f8 48 89 f7 48 89 d6 48 89 ca 4d 89 c2 4d 89 c8 4c 8b 4c 24 08 0f 05 <48> 3d 01 f0 ff ff 73 01 c3 48 c7 c1 b8 ff ff ff f7 d8 64 89 01 48 RSP: 002b:00007f172bf300b8 EFLAGS: 00000246 ORIG_RAX: 0000000000000010 RAX: ffffffffffffffda RBX: 00007f172b3abf80 RCX: 00007f172b262b8d RDX: 0000000020000000 RSI: 0000000000008954 RDI: 0000000000000003 RBP: 00007f172b2d3493 R08: 0000000000000000 R09: 0000000000000000 R10: 0000000000000000 R11: 0000000000000246 R12: 0000000000000000 R13: 000000000000000b R14: 00007f172b3abf80 R15: 00007f172bf10000 </TASK> Reported-by: syzkaller <[email protected]> Reported-by: Bjoern Doebel <[email protected]> Fixes: 1da177e ("Linux-2.6.12-rc2") Signed-off-by: Kuniyuki Iwashima <[email protected]> Link: https://lore.kernel.org/r/[email protected] Signed-off-by: Paolo Abeni <[email protected]> Signed-off-by: Greg Kroah-Hartman <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
May 13, 2024
The current implementation of the mov instruction with sign extension has the
following problems:
1. It clobbers the source register if it is not stacked because it
sign extends the source and then moves it to the destination.
2. If the dst_reg is stacked, the current code doesn't write the value
back in case of 64-bit mov.
3. There is room for improvement by emitting fewer instructions.
The steps for fixing this and the instructions emitted by the JIT are explained
below with examples in all combinations:
Case A: offset == 32:
=====================
Case A.1: src and dst are stacked registers:
--------------------------------------------
1. Load src_lo into tmp_lo
2. Store tmp_lo into dst_lo
3. Sign extend tmp_lo into tmp_hi
4. Store tmp_hi to dst_hi
Example: r3 = (s32)r3
r3 is a stacked register
ldr r6, [r11, #-16] // Load r3_lo into tmp_lo
// str to dst_lo is not emitted because src_lo == dst_lo
asr r7, r6, #31 // Sign extend tmp_lo into tmp_hi
str r7, [r11, #-12] // Store tmp_hi into r3_hi
Case A.2: src is stacked but dst is not:
----------------------------------------
1. Load src_lo into dst_lo
2. Sign extend dst_lo into dst_hi
Example: r6 = (s32)r3
r6 maps to {ARM_R5, ARM_R4} and r3 is stacked
ldr r4, [r11, #-16] // Load r3_lo into r6_lo
asr r5, r4, #31 // Sign extend r6_lo into r6_hi
Case A.3: src is not stacked but dst is stacked:
------------------------------------------------
1. Store src_lo into dst_lo
2. Sign extend src_lo into tmp_hi
3. Store tmp_hi to dst_hi
Example: r3 = (s32)r6
r3 is stacked and r6 maps to {ARM_R5, ARM_R4}
str r4, [r11, #-16] // Store r6_lo to r3_lo
asr r7, r4, #31 // Sign extend r6_lo into tmp_hi
str r7, [r11, #-12] // Store tmp_hi to dest_hi
Case A.4: Both src and dst are not stacked:
-------------------------------------------
1. Mov src_lo into dst_lo
2. Sign extend src_lo into dst_hi
Example: (bf) r6 = (s32)r6
r6 maps to {ARM_R5, ARM_R4}
// Mov not emitted because dst == src
asr r5, r4, #31 // Sign extend r6_lo into r6_hi
Case B: offset != 32:
=====================
Case B.1: src and dst are stacked registers:
--------------------------------------------
1. Load src_lo into tmp_lo
2. Sign extend tmp_lo according to offset.
3. Store tmp_lo into dst_lo
4. Sign extend tmp_lo into tmp_hi
5. Store tmp_hi to dst_hi
Example: r9 = (s8)r3
r9 and r3 are both stacked registers
ldr r6, [r11, #-16] // Load r3_lo into tmp_lo
lsl r6, r6, #24 // Sign extend tmp_lo
asr r6, r6, #24 // ..
str r6, [r11, #-56] // Store tmp_lo to r9_lo
asr r7, r6, #31 // Sign extend tmp_lo to tmp_hi
str r7, [r11, #-52] // Store tmp_hi to r9_hi
Case B.2: src is stacked but dst is not:
----------------------------------------
1. Load src_lo into dst_lo
2. Sign extend dst_lo according to offset.
3. Sign extend tmp_lo into dst_hi
Example: r6 = (s8)r3
r6 maps to {ARM_R5, ARM_R4} and r3 is stacked
ldr r4, [r11, #-16] // Load r3_lo to r6_lo
lsl r4, r4, #24 // Sign extend r6_lo
asr r4, r4, #24 // ..
asr r5, r4, #31 // Sign extend r6_lo into r6_hi
Case B.3: src is not stacked but dst is stacked:
------------------------------------------------
1. Sign extend src_lo into tmp_lo according to offset.
2. Store tmp_lo into dst_lo.
3. Sign extend src_lo into tmp_hi.
4. Store tmp_hi to dst_hi.
Example: r3 = (s8)r1
r3 is stacked and r1 maps to {ARM_R3, ARM_R2}
lsl r6, r2, #24 // Sign extend r1_lo to tmp_lo
asr r6, r6, #24 // ..
str r6, [r11, #-16] // Store tmp_lo to r3_lo
asr r7, r6, #31 // Sign extend tmp_lo to tmp_hi
str r7, [r11, #-12] // Store tmp_hi to r3_hi
Case B.4: Both src and dst are not stacked:
-------------------------------------------
1. Sign extend src_lo into dst_lo according to offset.
2. Sign extend dst_lo into dst_hi.
Example: r6 = (s8)r1
r6 maps to {ARM_R5, ARM_R4} and r1 maps to {ARM_R3, ARM_R2}
lsl r4, r2, #24 // Sign extend r1_lo to r6_lo
asr r4, r4, #24 // ..
asr r5, r4, #31 // Sign extend r6_lo to r6_hi
Fixes: fc83265 ("arm32, bpf: add support for sign-extension mov instruction")
Reported-by: [email protected]
Signed-off-by: Puranjay Mohan <[email protected]>
Signed-off-by: Daniel Borkmann <[email protected]>
Reviewed-by: Russell King (Oracle) <[email protected]>
Closes: https://lore.kernel.org/all/[email protected]
Link: https://lore.kernel.org/bpf/[email protected]
popcornmix
pushed a commit
that referenced
this issue
May 20, 2024
[ Upstream commit c6f4850 ] The current implementation of the mov instruction with sign extension has the following problems: 1. It clobbers the source register if it is not stacked because it sign extends the source and then moves it to the destination. 2. If the dst_reg is stacked, the current code doesn't write the value back in case of 64-bit mov. 3. There is room for improvement by emitting fewer instructions. The steps for fixing this and the instructions emitted by the JIT are explained below with examples in all combinations: Case A: offset == 32: ===================== Case A.1: src and dst are stacked registers: -------------------------------------------- 1. Load src_lo into tmp_lo 2. Store tmp_lo into dst_lo 3. Sign extend tmp_lo into tmp_hi 4. Store tmp_hi to dst_hi Example: r3 = (s32)r3 r3 is a stacked register ldr r6, [r11, #-16] // Load r3_lo into tmp_lo // str to dst_lo is not emitted because src_lo == dst_lo asr r7, r6, #31 // Sign extend tmp_lo into tmp_hi str r7, [r11, #-12] // Store tmp_hi into r3_hi Case A.2: src is stacked but dst is not: ---------------------------------------- 1. Load src_lo into dst_lo 2. Sign extend dst_lo into dst_hi Example: r6 = (s32)r3 r6 maps to {ARM_R5, ARM_R4} and r3 is stacked ldr r4, [r11, #-16] // Load r3_lo into r6_lo asr r5, r4, #31 // Sign extend r6_lo into r6_hi Case A.3: src is not stacked but dst is stacked: ------------------------------------------------ 1. Store src_lo into dst_lo 2. Sign extend src_lo into tmp_hi 3. Store tmp_hi to dst_hi Example: r3 = (s32)r6 r3 is stacked and r6 maps to {ARM_R5, ARM_R4} str r4, [r11, #-16] // Store r6_lo to r3_lo asr r7, r4, #31 // Sign extend r6_lo into tmp_hi str r7, [r11, #-12] // Store tmp_hi to dest_hi Case A.4: Both src and dst are not stacked: ------------------------------------------- 1. Mov src_lo into dst_lo 2. Sign extend src_lo into dst_hi Example: (bf) r6 = (s32)r6 r6 maps to {ARM_R5, ARM_R4} // Mov not emitted because dst == src asr r5, r4, #31 // Sign extend r6_lo into r6_hi Case B: offset != 32: ===================== Case B.1: src and dst are stacked registers: -------------------------------------------- 1. Load src_lo into tmp_lo 2. Sign extend tmp_lo according to offset. 3. Store tmp_lo into dst_lo 4. Sign extend tmp_lo into tmp_hi 5. Store tmp_hi to dst_hi Example: r9 = (s8)r3 r9 and r3 are both stacked registers ldr r6, [r11, #-16] // Load r3_lo into tmp_lo lsl r6, r6, #24 // Sign extend tmp_lo asr r6, r6, #24 // .. str r6, [r11, #-56] // Store tmp_lo to r9_lo asr r7, r6, #31 // Sign extend tmp_lo to tmp_hi str r7, [r11, #-52] // Store tmp_hi to r9_hi Case B.2: src is stacked but dst is not: ---------------------------------------- 1. Load src_lo into dst_lo 2. Sign extend dst_lo according to offset. 3. Sign extend tmp_lo into dst_hi Example: r6 = (s8)r3 r6 maps to {ARM_R5, ARM_R4} and r3 is stacked ldr r4, [r11, #-16] // Load r3_lo to r6_lo lsl r4, r4, #24 // Sign extend r6_lo asr r4, r4, #24 // .. asr r5, r4, #31 // Sign extend r6_lo into r6_hi Case B.3: src is not stacked but dst is stacked: ------------------------------------------------ 1. Sign extend src_lo into tmp_lo according to offset. 2. Store tmp_lo into dst_lo. 3. Sign extend src_lo into tmp_hi. 4. Store tmp_hi to dst_hi. Example: r3 = (s8)r1 r3 is stacked and r1 maps to {ARM_R3, ARM_R2} lsl r6, r2, #24 // Sign extend r1_lo to tmp_lo asr r6, r6, #24 // .. str r6, [r11, #-16] // Store tmp_lo to r3_lo asr r7, r6, #31 // Sign extend tmp_lo to tmp_hi str r7, [r11, #-12] // Store tmp_hi to r3_hi Case B.4: Both src and dst are not stacked: ------------------------------------------- 1. Sign extend src_lo into dst_lo according to offset. 2. Sign extend dst_lo into dst_hi. Example: r6 = (s8)r1 r6 maps to {ARM_R5, ARM_R4} and r1 maps to {ARM_R3, ARM_R2} lsl r4, r2, #24 // Sign extend r1_lo to r6_lo asr r4, r4, #24 // .. asr r5, r4, #31 // Sign extend r6_lo to r6_hi Fixes: fc83265 ("arm32, bpf: add support for sign-extension mov instruction") Reported-by: [email protected] Signed-off-by: Puranjay Mohan <[email protected]> Signed-off-by: Daniel Borkmann <[email protected]> Reviewed-by: Russell King (Oracle) <[email protected]> Closes: https://lore.kernel.org/all/[email protected] Link: https://lore.kernel.org/bpf/[email protected] Signed-off-by: Sasha Levin <[email protected]>
6by9
pushed a commit
to 6by9/linux
that referenced
this issue
Nov 5, 2024
Running "modprobe amdgpu" the second time (followed by a modprobe -r amdgpu) causes a call trace like: [ 845.212163] Memory manager not clean during takedown. [ 845.212170] WARNING: CPU: 4 PID: 2481 at drivers/gpu/drm/drm_mm.c:999 drm_mm_takedown+0x2b/0x40 [ 845.212177] Modules linked in: amdgpu(OE-) amddrm_ttm_helper(OE) amddrm_buddy(OE) amdxcp(OE) amd_sched(OE) drm_exec drm_suballoc_helper drm_display_helper i2c_algo_bit amdttm(OE) amdkcl(OE) cec rc_core sunrpc qrtr intel_rapl_msr intel_rapl_common snd_hda_codec_hdmi edac_mce_amd snd_hda_intel snd_intel_dspcfg snd_intel_sdw_acpi snd_usb_audio snd_hda_codec snd_usbmidi_lib kvm_amd snd_hda_core snd_ump mc snd_hwdep kvm snd_pcm snd_seq_midi snd_seq_midi_event irqbypass crct10dif_pclmul snd_rawmidi polyval_clmulni polyval_generic ghash_clmulni_intel sha256_ssse3 sha1_ssse3 snd_seq aesni_intel crypto_simd snd_seq_device cryptd snd_timer mfd_aaeon asus_nb_wmi eeepc_wmi joydev asus_wmi snd ledtrig_audio sparse_keymap ccp wmi_bmof input_leds k10temp i2c_piix4 platform_profile rapl soundcore gpio_amdpt mac_hid binfmt_misc msr parport_pc ppdev lp parport efi_pstore nfnetlink dmi_sysfs ip_tables x_tables autofs4 hid_logitech_hidpp hid_logitech_dj hid_generic usbhid hid ahci xhci_pci igc crc32_pclmul libahci xhci_pci_renesas video [ 845.212284] wmi [last unloaded: amddrm_ttm_helper(OE)] [ 845.212290] CPU: 4 PID: 2481 Comm: modprobe Tainted: G W OE 6.8.0-31-generic raspberrypi#31-Ubuntu [ 845.212296] RIP: 0010:drm_mm_takedown+0x2b/0x40 [ 845.212300] Code: 1f 44 00 00 48 8b 47 38 48 83 c7 38 48 39 f8 75 09 31 c0 31 ff e9 90 2e 86 00 55 48 c7 c7 d0 f6 8e 8a 48 89 e5 e8 f5 db 45 ff <0f> 0b 5d 31 c0 31 ff e9 74 2e 86 00 66 0f 1f 84 00 00 00 00 00 90 [ 845.212302] RSP: 0018:ffffb11302127ae0 EFLAGS: 00010246 [ 845.212305] RAX: 0000000000000000 RBX: ffff92aa5020fc08 RCX: 0000000000000000 [ 845.212307] RDX: 0000000000000000 RSI: 0000000000000000 RDI: 0000000000000000 [ 845.212309] RBP: ffffb11302127ae0 R08: 0000000000000000 R09: 0000000000000000 [ 845.212310] R10: 0000000000000000 R11: 0000000000000000 R12: 0000000000000004 [ 845.212312] R13: ffff92aa50200000 R14: ffff92aa5020fb10 R15: ffff92aa5020faa0 [ 845.212313] FS: 0000707dd7c7c080(0000) GS:ffff92b93de00000(0000) knlGS:0000000000000000 [ 845.212316] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [ 845.212318] CR2: 00007d48b0aee200 CR3: 0000000115a58000 CR4: 0000000000f50ef0 [ 845.212320] PKRU: 55555554 [ 845.212321] Call Trace: [ 845.212323] <TASK> [ 845.212328] ? show_regs+0x6d/0x80 [ 845.212333] ? __warn+0x89/0x160 [ 845.212339] ? drm_mm_takedown+0x2b/0x40 [ 845.212344] ? report_bug+0x17e/0x1b0 [ 845.212350] ? handle_bug+0x51/0xa0 [ 845.212355] ? exc_invalid_op+0x18/0x80 [ 845.212359] ? asm_exc_invalid_op+0x1b/0x20 [ 845.212366] ? drm_mm_takedown+0x2b/0x40 [ 845.212371] amdgpu_gtt_mgr_fini+0xa9/0x130 [amdgpu] [ 845.212645] amdgpu_ttm_fini+0x264/0x340 [amdgpu] [ 845.212770] amdgpu_bo_fini+0x2e/0xc0 [amdgpu] [ 845.212894] gmc_v12_0_sw_fini+0x2a/0x40 [amdgpu] [ 845.213036] amdgpu_device_fini_sw+0x11a/0x590 [amdgpu] [ 845.213159] amdgpu_driver_release_kms+0x16/0x40 [amdgpu] [ 845.213302] devm_drm_dev_init_release+0x5e/0x90 [ 845.213305] devm_action_release+0x12/0x30 [ 845.213308] release_nodes+0x42/0xd0 [ 845.213311] devres_release_all+0x97/0xe0 [ 845.213314] device_unbind_cleanup+0x12/0x80 [ 845.213317] device_release_driver_internal+0x230/0x270 [ 845.213319] ? srso_alias_return_thunk+0x5/0xfbef5 This is caused by lost memory during early init phase. First time driver is removed, memory is freed but when second time the driver is inserted, VBIOS dmub is not active, since the PSP policy is to retain the driver loaded version on subsequent warm boots. Hence, communication with VBIOS DMUB fails. Fix this by aborting further communication with vbios dmub and release the memory immediately. Fixes: f59549c ("drm/amd/display: free bo used for dmub bounding box") Reviewed-by: Rodrigo Siqueira <[email protected]> Signed-off-by: Aurabindo Pillai <[email protected]> Signed-off-by: Rodrigo Siqueira <[email protected]> Tested-by: Daniel Wheeler <[email protected]> Signed-off-by: Alex Deucher <[email protected]>
popcornmix
pushed a commit
that referenced
this issue
Dec 7, 2024
[ Upstream commit d4f36e5 ] Running "modprobe amdgpu" the second time (followed by a modprobe -r amdgpu) causes a call trace like: [ 845.212163] Memory manager not clean during takedown. [ 845.212170] WARNING: CPU: 4 PID: 2481 at drivers/gpu/drm/drm_mm.c:999 drm_mm_takedown+0x2b/0x40 [ 845.212177] Modules linked in: amdgpu(OE-) amddrm_ttm_helper(OE) amddrm_buddy(OE) amdxcp(OE) amd_sched(OE) drm_exec drm_suballoc_helper drm_display_helper i2c_algo_bit amdttm(OE) amdkcl(OE) cec rc_core sunrpc qrtr intel_rapl_msr intel_rapl_common snd_hda_codec_hdmi edac_mce_amd snd_hda_intel snd_intel_dspcfg snd_intel_sdw_acpi snd_usb_audio snd_hda_codec snd_usbmidi_lib kvm_amd snd_hda_core snd_ump mc snd_hwdep kvm snd_pcm snd_seq_midi snd_seq_midi_event irqbypass crct10dif_pclmul snd_rawmidi polyval_clmulni polyval_generic ghash_clmulni_intel sha256_ssse3 sha1_ssse3 snd_seq aesni_intel crypto_simd snd_seq_device cryptd snd_timer mfd_aaeon asus_nb_wmi eeepc_wmi joydev asus_wmi snd ledtrig_audio sparse_keymap ccp wmi_bmof input_leds k10temp i2c_piix4 platform_profile rapl soundcore gpio_amdpt mac_hid binfmt_misc msr parport_pc ppdev lp parport efi_pstore nfnetlink dmi_sysfs ip_tables x_tables autofs4 hid_logitech_hidpp hid_logitech_dj hid_generic usbhid hid ahci xhci_pci igc crc32_pclmul libahci xhci_pci_renesas video [ 845.212284] wmi [last unloaded: amddrm_ttm_helper(OE)] [ 845.212290] CPU: 4 PID: 2481 Comm: modprobe Tainted: G W OE 6.8.0-31-generic #31-Ubuntu [ 845.212296] RIP: 0010:drm_mm_takedown+0x2b/0x40 [ 845.212300] Code: 1f 44 00 00 48 8b 47 38 48 83 c7 38 48 39 f8 75 09 31 c0 31 ff e9 90 2e 86 00 55 48 c7 c7 d0 f6 8e 8a 48 89 e5 e8 f5 db 45 ff <0f> 0b 5d 31 c0 31 ff e9 74 2e 86 00 66 0f 1f 84 00 00 00 00 00 90 [ 845.212302] RSP: 0018:ffffb11302127ae0 EFLAGS: 00010246 [ 845.212305] RAX: 0000000000000000 RBX: ffff92aa5020fc08 RCX: 0000000000000000 [ 845.212307] RDX: 0000000000000000 RSI: 0000000000000000 RDI: 0000000000000000 [ 845.212309] RBP: ffffb11302127ae0 R08: 0000000000000000 R09: 0000000000000000 [ 845.212310] R10: 0000000000000000 R11: 0000000000000000 R12: 0000000000000004 [ 845.212312] R13: ffff92aa50200000 R14: ffff92aa5020fb10 R15: ffff92aa5020faa0 [ 845.212313] FS: 0000707dd7c7c080(0000) GS:ffff92b93de00000(0000) knlGS:0000000000000000 [ 845.212316] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [ 845.212318] CR2: 00007d48b0aee200 CR3: 0000000115a58000 CR4: 0000000000f50ef0 [ 845.212320] PKRU: 55555554 [ 845.212321] Call Trace: [ 845.212323] <TASK> [ 845.212328] ? show_regs+0x6d/0x80 [ 845.212333] ? __warn+0x89/0x160 [ 845.212339] ? drm_mm_takedown+0x2b/0x40 [ 845.212344] ? report_bug+0x17e/0x1b0 [ 845.212350] ? handle_bug+0x51/0xa0 [ 845.212355] ? exc_invalid_op+0x18/0x80 [ 845.212359] ? asm_exc_invalid_op+0x1b/0x20 [ 845.212366] ? drm_mm_takedown+0x2b/0x40 [ 845.212371] amdgpu_gtt_mgr_fini+0xa9/0x130 [amdgpu] [ 845.212645] amdgpu_ttm_fini+0x264/0x340 [amdgpu] [ 845.212770] amdgpu_bo_fini+0x2e/0xc0 [amdgpu] [ 845.212894] gmc_v12_0_sw_fini+0x2a/0x40 [amdgpu] [ 845.213036] amdgpu_device_fini_sw+0x11a/0x590 [amdgpu] [ 845.213159] amdgpu_driver_release_kms+0x16/0x40 [amdgpu] [ 845.213302] devm_drm_dev_init_release+0x5e/0x90 [ 845.213305] devm_action_release+0x12/0x30 [ 845.213308] release_nodes+0x42/0xd0 [ 845.213311] devres_release_all+0x97/0xe0 [ 845.213314] device_unbind_cleanup+0x12/0x80 [ 845.213317] device_release_driver_internal+0x230/0x270 [ 845.213319] ? srso_alias_return_thunk+0x5/0xfbef5 This is caused by lost memory during early init phase. First time driver is removed, memory is freed but when second time the driver is inserted, VBIOS dmub is not active, since the PSP policy is to retain the driver loaded version on subsequent warm boots. Hence, communication with VBIOS DMUB fails. Fix this by aborting further communication with vbios dmub and release the memory immediately. Fixes: f59549c ("drm/amd/display: free bo used for dmub bounding box") Reviewed-by: Rodrigo Siqueira <[email protected]> Signed-off-by: Aurabindo Pillai <[email protected]> Signed-off-by: Rodrigo Siqueira <[email protected]> Tested-by: Daniel Wheeler <[email protected]> Signed-off-by: Alex Deucher <[email protected]> Signed-off-by: Sasha Levin <[email protected]>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Hi,
While my 'pi was doing real work for me it crashed 15 minutes after I had left. :-(
It produced the attached "ooops" (provided I can find how to attach files) .
It's reading from an SD card (microSD to be exact), and writing the data over a TPC connection to a server. This is progressing at 300k/sec. (with 32G total, that is expected tot take 29 hours).
It has now been running since this morning: about 14 hours.
The text was updated successfully, but these errors were encountered: