Compute column sizes in Parquet preprocess with single kernel #12931
Conversation
|
Would it be accurate to say that column size computation is 4x faster for this schema? Would you please share a few details about the schema in your test case? |
The highlighted region in the timelines includes the memsets for allocating the columns as well so the just the columns size and offset computation is actually many times faster in this case since, but I think it would be fair to say column allocation overall is 4x faster for this schema. This schema has 1629 columns with up to 8 levels of nesting which is why there were so many |
There was a problem hiding this comment.
Impressive speedups!
Some surface-level comments, did not go into the actual algorithm changes yet.
Echoing @PointKernel 's observations about mixed integral types.
| thrust::reduce_by_key(rmm::exec_policy(_stream), | ||
| reduction_keys, | ||
| reduction_keys + num_keys, | ||
| size_input, | ||
| thrust::make_discard_iterator(), | ||
| sizes.d_begin()); | ||
|
|
||
| // for nested hierarchies, compute per-page start offset | ||
| thrust::exclusive_scan_by_key(rmm::exec_policy(_stream), | ||
| reduction_keys, | ||
| reduction_keys + num_keys, | ||
| size_input, | ||
| start_offset_output_iterator{pages.device_ptr(), | ||
| page_index.begin(), | ||
| 0, | ||
| input_cols.device_ptr(), | ||
| max_depth, | ||
| pages.size()}); |
There was a problem hiding this comment.
I wonder if we can even do better by combining these 2 kernel calls? Since they are operating on the same reduction_keys. Maybe just one reduce_by_key with a custom device lambda/functor that can do both reduce and scan?
There was a problem hiding this comment.
I'm not quite sure how to create a functor for reduce_by_key that would also perform the scan but it could be possible. Do you have an idea in mind?
|
@SrikarVanavasam there are failing Parquet tests with the current version. Looks like it's related to the review changes, since CI passed with e8b7c24 |
There was a problem hiding this comment.
This looks good to me. Only minor thing I'd bring up is that in the reduction_indices struct I'd suggest using the underscores for the constructor parameters, and keeping the fields of the struct itself without them.
I like the abstraction of the reduction_indices itself - clarifies how we're organizing the keys.
Also, if there's a bug that got introduced during PR changes, be sure to also re-run the Spark integration tests after fixing.
|
/merge |
Addresses #11922
Currently in Parquet preprocessing a
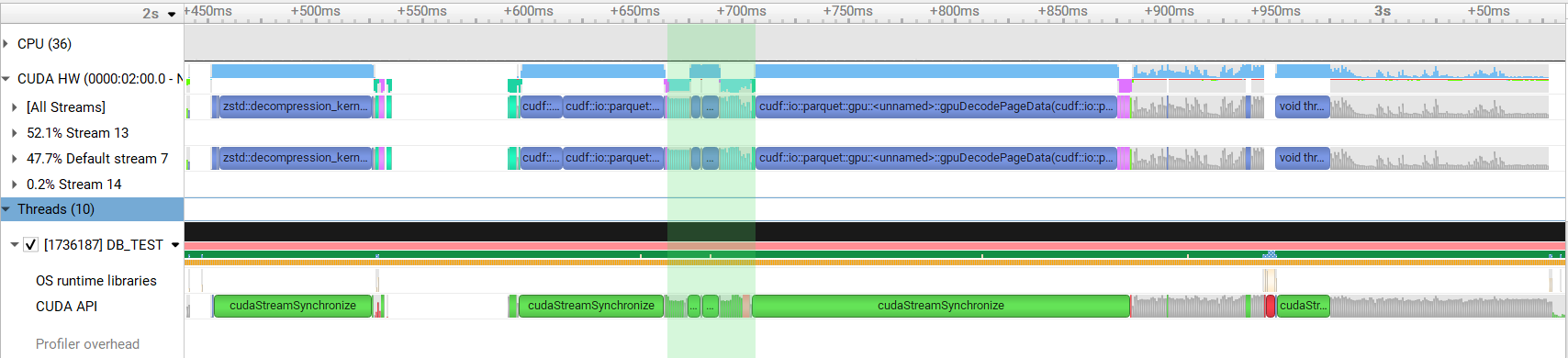
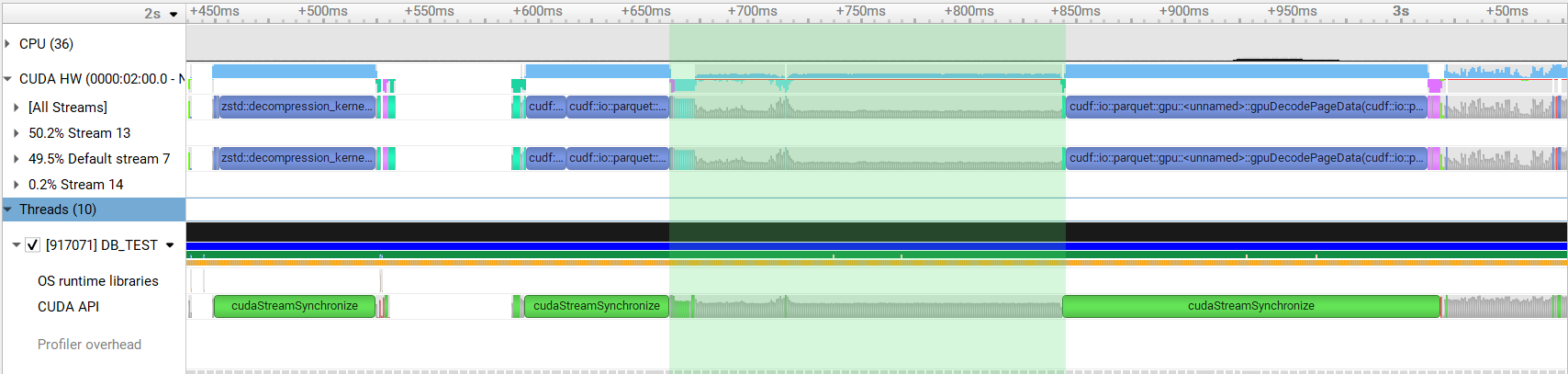
thrust::reduce()andthrust::exclusive_scan_by_key()is performed to compute the column size and offsets for each nested column. For complicated schemas this results in a large number of kernel invocations. This PR calculates the sizes and offsets of all columns in single calls tothrust::reduce_by_key()andthrust::exclusive_scan_by_key().This change results in around 1.3x speedup when reading a complicated schema.
Before:
After: