-
Notifications
You must be signed in to change notification settings - Fork 919
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Compute column sizes in Parquet preprocess with single kernel (#12931)
Addresses #11922 Currently in Parquet preprocessing a `thrust::reduce()` and `thrust::exclusive_scan_by_key()` is performed to compute the column size and offsets for each nested column. For complicated schemas this results in a large number of kernel invocations. This PR calculates the sizes and offsets of all columns in single calls to `thrust::reduce_by_key()` and `thrust::exclusive_scan_by_key()`. This change results in around 1.3x speedup when reading a complicated schema. Before: 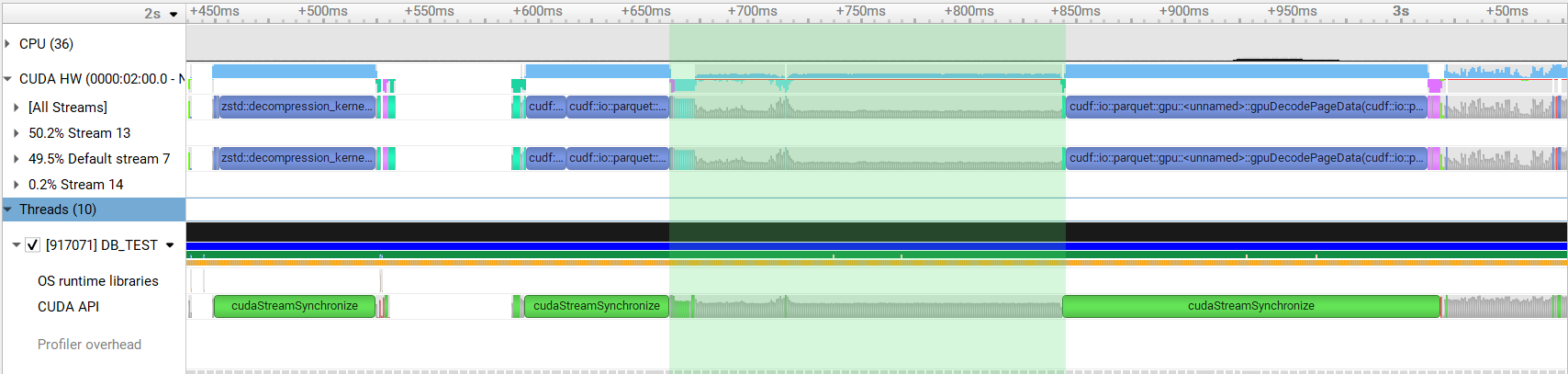 After: 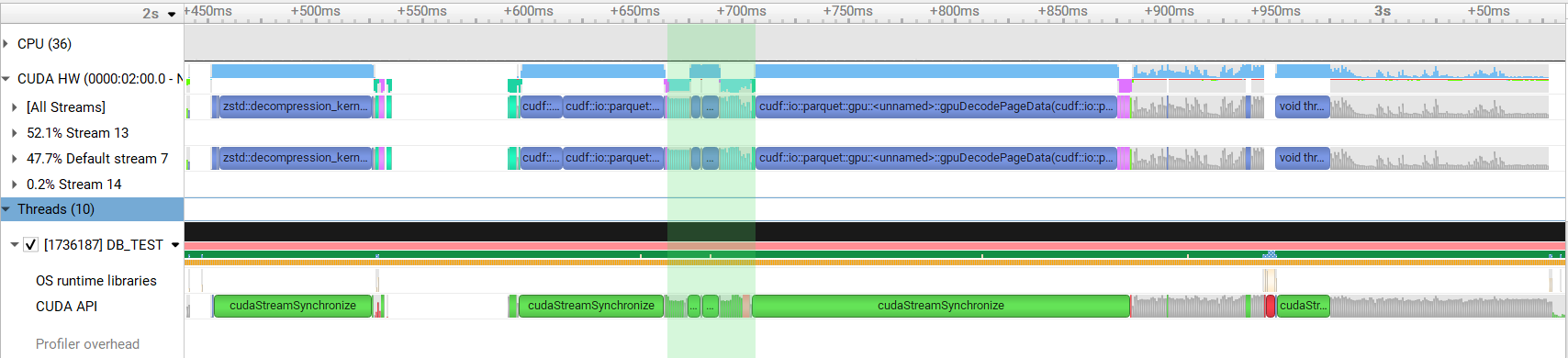 Authors: - Srikar Vanavasam (https://github.com/SrikarVanavasam) Approvers: - Yunsong Wang (https://github.com/PointKernel) - Nghia Truong (https://github.com/ttnghia) - Vukasin Milovanovic (https://github.com/vuule) URL: #12931
{kind=link}
{kind=link}
- Loading branch information
1 parent
46b5900
commit f328b64
Showing
1 changed file
with
120 additions
and
51 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters