[FEA] The final step of the parquet preprocess step can get very slow for highly complicated schemas. #11922
Assignees

Labels
0 - Backlog
In queue waiting for assignment
cuIO
cuIO issue
improvement
Improvement / enhancement to an existing function
libcudf
Affects libcudf (C++/CUDA) code.
Performance
Performance related issue
proposal
Change current process or code
Milestone
Comments
rapids-bot bot
pushed a commit
that referenced
this issue
Apr 7, 2023
Addresses #11922 Currently in Parquet preprocessing a `thrust::reduce()` and `thrust::exclusive_scan_by_key()` is performed to compute the column size and offsets for each nested column. For complicated schemas this results in a large number of kernel invocations. This PR calculates the sizes and offsets of all columns in single calls to `thrust::reduce_by_key()` and `thrust::exclusive_scan_by_key()`. This change results in around 1.3x speedup when reading a complicated schema. Before: 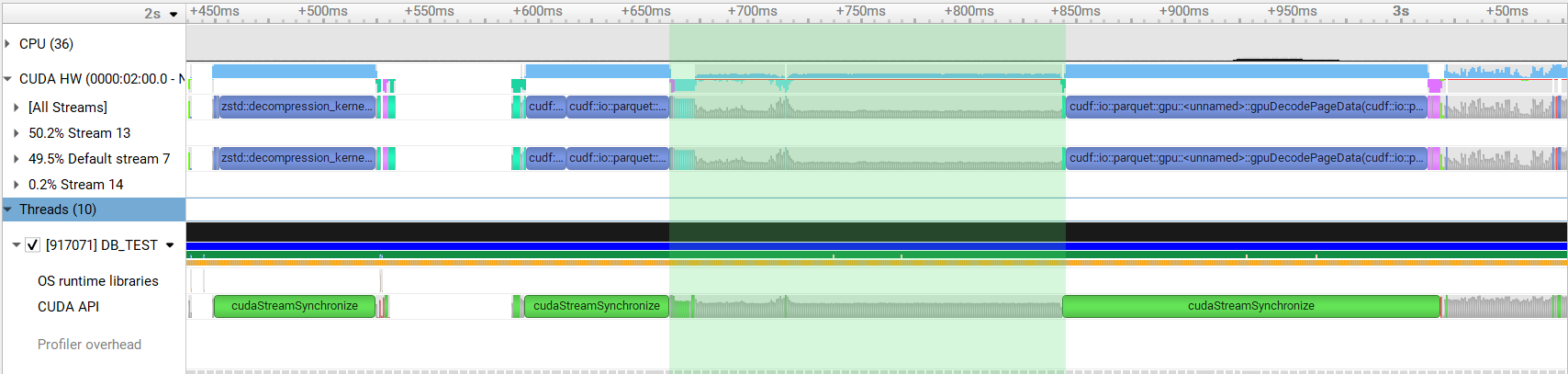 After: 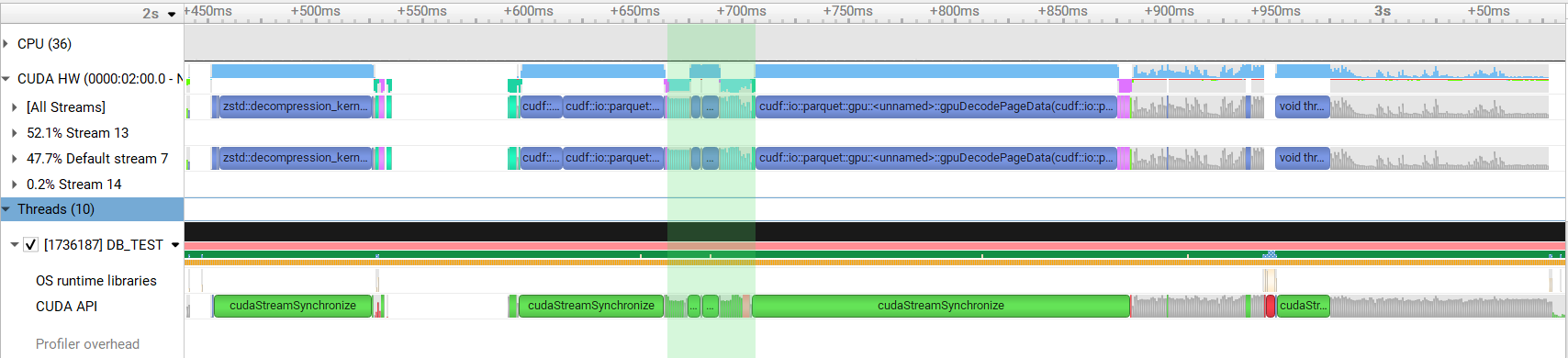 Authors: - Srikar Vanavasam (https://github.com/SrikarVanavasam) Approvers: - Yunsong Wang (https://github.com/PointKernel) - Nghia Truong (https://github.com/ttnghia) - Vukasin Milovanovic (https://github.com/vuule) URL: #12931
{kind=link}
{kind=link}
|
@SrikarVanavasam FYI Github supports certain keywords to automate linking issues to PRs. If you had included |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
For parquet files that contain columns with lists in them, we do a preprocess step to compute column sizes (and other information). As a very last step, we iterate over the input columns and march through them by depth here:
cudf/cpp/src/io/parquet/page_data.cu
Line 1827 in e91d7d9
For very complicated schemas, this can result in a large number of calls to
thrust::reduce()andthrust::exclusive_scan_by_key(). In some cases, cases, so much so that it can dominate the rest of the decompress/decode work.We should spend some time figuring out how to coalesce this into fewer (perhaps 1 each of
reduce_by_keyandexclusive_scan_by_key) calls.The text was updated successfully, but these errors were encountered: