Fix cache invalidation issue #375
Closed
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
### Description <!-- Describe your changes. --> This branch is based on rel-1.18.0 and supports TensorRT 10-GA. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
) ### Description <!-- Describe your changes. --> Using certain APIs is about to require a [privacy manifest](https://developer.apple.com/documentation/bundleresources/privacy_manifest_files/describing_use_of_required_reason_api) to be added to a package. Our version of protobuf uses `mach_absolute_time`. Patch as per protocolbuffers/protobuf#15662 to remove usage. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. --> Usage of API will require a privacy manifest for an iOS app to be accepted as of 5/1/2024 microsoft#20519
### Description Follow up of microsoft#20216 to add kernel for sm=75 (GPU like T4, Geforce RTX 2080, GeForce GTX 1650 Ti, NVIDIA TITAN RTX, RTX 4000 etc) - [x] Add kernel for sm=75 - [x] Update dispatch code to use sm to call different kernel. - [x] Update compile script to use num_stages=2 instead of 3 for sm=75 - [x] Refactor test script and add tests for bfloat16. - [x] Fix performance test of token generation (previously we did not concatenate past_key) - [x] Fix debug build - [x] Run performance test and update numbers. For sm=70, the v1 kernel can be compiled but there is error in compiling v2 kernel. So it is skipped in this pull request. Performance Test on T4 GPU (using Standard_NC4as_T4_v3 Azure VM) with `batch_size=4, num_heads=32, max_seq_len=8192, head_size=128, sparse_block_size=64, local_blocks=16, vert_stride=8, num_layout=8` We compare sparse attention to corresponding GQA with dense causal. Note that GQA with dense need more computation since no sparsity is used. The TORCH-GQA use naive implementation (using cuSPARSE Block-SpMM could be faster). ``` prompt-sm75-batch4-head32-d128-local16-vert8-torch.float16: sequence_length TORCH-GQA ORT-GQA-Dense ORT-SparseAtt 1 32.0 0.184173 2.994347 0.089064 2 64.0 0.303300 3.023986 0.107418 3 128.0 0.887795 3.073728 0.174213 4 256.0 2.797654 3.246899 0.357869 5 512.0 10.055048 3.814039 0.893903 6 1024.0 37.849937 5.818439 2.658720 7 2048.0 148.641785 13.638480 7.202690 8 4096.0 OOM 43.556847 17.680954 9 8192.0 OOM 161.628540 44.336670 token-sm75-batch4-head32-d128-local16-vert8-torch.float16: past_sequence_length TORCH-GQA ORT-GQA-Dense ORT-SparseAtt 1 32.0 0.110353 2.996305 0.137509 2 64.0 0.145088 3.006860 0.165424 3 128.0 0.219500 3.036448 0.192001 4 256.0 0.347496 3.071341 0.249125 5 512.0 0.595842 3.135225 0.398726 6 1024.0 1.081216 3.261110 0.612744 7 2048.0 2.060307 3.515578 0.685670 8 4096.0 OOM 4.022986 0.819707 9 8191.0 OOM 5.024528 1.072912 ``` ### Motivation and Context To inference Phi-3-small in T4 GPU
### Description - Updates QNN pipelines to use QNN SDK 2.21 - Downloads QNN SDK from Azure storage to avoid having to rebuild images when a new version is released. ### Motivation and Context Test with the latest QNN SDK.
### Description <!-- Describe your changes. --> This PR registers DFT-20 to the DML EP. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
### Description Add tensor v2 support to unblock the inference with context binary generated from QNN v2.21
### Description - Adds support for float32/float16 HardSigmoid on HTP backend. Decomposes `HardSigmoid(X)` into `max(0, min(1, alpha * X + beta))`. - Fuses the sequence `X * HardSigmoid<alpha=1/6, beta=0.5>(X)` into a single `HardSwish(x)`. Only applies to non-quantized HardSigmoid/Mul. ### Motivation and Context QNN does not natively support HardSigmoid. These changes expand model support on QNN EP.
### Description Support Conv ConvTranspose 3D for QNN EP
### Description <!-- Describe your changes. --> with past/present shared same buffer, the present seq length is different with total sequence length. The size of cos/sin cache should be checked with sequence length. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
### Description As a follow-up of microsoft#20506 ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
Return ENGINE_ERROR for QNN NPU SSR issue
### Description Follow up of microsoft#20216 to add sparse attention kernel compiled by Triton for H100 (sm90). - [x] Refine sparse attention v1 kernel compilation (remove some combinations) - [x] compile kernels for v1 kernels - [x] compile kernels for H100 - [x] run performance tests ### Performane Test setting `batch_size=4, num_heads=32, max_seq_len=8192, head_size=128, sparse_block_size=64, local_blocks=16, vert_stride=8, num_layout=8` We compare sparse attention to corresponding GQA with local attention windows size 1024, or GQA with dense causal. Note that ORT-GQA-Dense has more computation than ORT-SparseAtt, while ORT-GQA-Local has less computation (no vertial strides) than ORT-SparseAtt. They are added for reference. It is not fair comparison, but could show the benefit of sparsity vs dense. Example results in Azure Standard_ND96isr_H100_v5 VM with NVIDIA H100-80GB-HBM3 GPU (sm=90): ``` prompt-sm90-batch4-head32-d128-local16-vert8-torch.float16: sequence_length TORCH-GQA ORT-GQA-Dense ORT-GQA-Local ORT-SparseAtt 0 16.0 0.079877 0.006362 0.006403 0.042758 1 32.0 0.086920 0.016404 0.016686 0.044183 2 64.0 0.090727 0.020429 0.020409 0.045343 3 128.0 0.128148 0.032009 0.031984 0.051516 4 256.0 0.323933 0.074110 0.073920 0.068308 5 512.0 1.021856 0.162167 0.161951 0.109226 6 1024.0 3.596002 0.452629 0.452780 0.231653 7 2048.0 13.865088 1.499534 1.195749 0.515488 8 4096.0 0.000000 5.454785 2.669682 1.163233 9 8192.0 0.000000 22.068159 6.018604 2.772873 token-sm90-batch4-head32-d128-local16-vert8-torch.float16: past_sequence_length TORCH-GQA ORT-GQA-Dense ORT-GQA-Local ORT-SparseAtt 0 16.0 0.104460 0.012652 0.012661 0.069549 1 32.0 0.113866 0.012776 0.012765 0.069024 2 64.0 0.124600 0.016791 0.012672 0.069397 3 128.0 0.108658 0.017900 0.018294 0.074844 4 256.0 0.115463 0.029409 0.029608 0.078911 5 512.0 0.149824 0.033968 0.033701 0.092998 6 1024.0 0.234050 0.042930 0.042951 0.116920 7 2048.0 0.390695 0.061462 0.043008 0.121555 8 4096.0 0.000000 0.097505 0.042948 0.134757 9 8191.0 0.000000 0.165861 0.043542 0.158796 ``` The following might be able to help performance on short sequence length. Need update operator spec: Fall back to flash attention when total_sequence length < local_blocks * block_size ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
### Description I misunderstood how UpdateCUDAProviderOptions and UpdateTensorRTProviderOptions work in the C API, I had assumed that they updated the options struct, however they re-initialize the struct to the defaults then only apply the values in the update. I've rewritten the Java bindings for those classes so that they aggregate all the updates and apply them in one go. I also updated the C API documentation to note that these classes have this behaviour. I've not checked if any of the other providers with an options struct have this behaviour, we only expose CUDA and TensorRT's options in Java. There's a small unrelated update to add a private constructor to the Fp16Conversions classes to remove a documentation warning (they shouldn't be instantiated anyway as they are utility classes containing static methods). ### Motivation and Context Fixes microsoft#20544.
### Fix missing node during mem efficient topo sort Some nodes are not cusumed by the backward path, they are also not generating graph outputs. We missed those nodes, so this PR fix that and add related tests. A side note: we should remove those nodes that are not used for computing any graph outputs in a graph transformer. (TODO) ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
### Description <!-- Describe your changes. --> This PR supports profiling and tuning MoE Gemm kernels in the very first run and store the best configuration to reuse in the following runs. The Gemm id (the key to the config map, int64_t) is determined by num_rows, gemm_n and gemm_k for each type. First 32 bits are total_rows, next 16 bits are gemm_n, next 16 bits are gemm_k int64_t key = total_rows; key = key << 16 | gemm_n; key = key << 16 | gemm_k; Mixtral-fp16 on 2 A100 with tp=2. batch size = 1, seq_len = 1k | | Prompt | Token | | :--- | :---: | ---: | | before | 138ms | 16.4ms | | after | 100ms | 13.9ms | ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
…crosoft#20550) microsoft#20445 The nvonnxparser still needs major version appending to it when building oss parser.
) ### Description <!-- Describe your changes. --> Operator should not modify input tensors because they are managed by framework and may be reused by other nodes. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
Gemma has a `Mul` node right after the `Gather` and before the first layer norm.
### Description (1) Fix UnpackQKV kernel (2) Update test_sparse_attention.py with packed QKV option
Enable int32 data support for Clip fix issue: microsoft#20525
Made some changes to the arm64x.cmake script to: - handle edge case - Enable Projects that include onnxruntime as submodule and build it, to be able to build as x without causing onnxruntime build_as_x to fail.
### Description There was a bug with gqa on cpu where on token case, with batch_size > 1, and with past_present_share_buffer off, the output would occasionally contain nans. this pr fixes that. it also updates documentation and fixes posid gen for rotary in cuda in prompt case. ### Motivation and Context this pr solves the GQA CPU bug as well as updates the documentation and makes seqlens_k irrelevant for prompt case, which is useful to prevent user error.
### Description <!-- Describe your changes. --> Currently figuring out if the protobuf dependency is building protoc it is a little obtuse and inconsistent * in some places we directly set protobuf_BUILD_PROTOC_BINARIES to OFF to indicate the protobuf dependency is not building protoc * e.g. macOS/iOS/visionOS builds * for a user provided protoc path we don't set protobuf_BUILD_PROTOC_BINARIES, and inside protobuf_function.cmake that determines if `protobuf::protoc` is added as a dependency or not * https://github.com/microsoft/onnxruntime/blob/0dda8b0c449009dee5e9cdf3ccaa4fbbacf04dd0/cmake/external/protobuf_function.cmake#L40-L45 To be more consistent/explicit, set protobuf_BUILD_PROTOC_BINARIES to OFF when ONNX_CUSTOM_PROTOC_EXECUTABLE set and valid. Remove outdated script that built and external protoc binary which was used in later builds. The build setup will fetch a pre-built protoc so there's no need for this additional build. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. --> Make it easier to figure out if protoc is coming from the protobuf dependency.
Patching in fast match disabled in the MIGraphX Compile stage in the MIGraphX EP ### Description Allow the MIGraphX API to compile the program given to the EP to turn off fast math by default. ### Motivation and Context Fixes accuracy issue we're seeing with GELU parity tests. Without fast math disabled GELU will use a faster but less numerically stable version which trades speed for accuracy. Co-authored-by: Ted Themistokleous <[email protected]>
SkipSimplifiedLayerNormalization used in phi3 comes down from 222usec to 14usec
### Description <!-- Describe your changes. --> ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
### Description Fix a few issues in GQA: (1) memory efficient attention does not have bfloat16, need disable it when bfloat16 is used. (2) When prompt length is 1, it is not classified as prompt. (3) Fix benchmark_gqa.py (4) Add a comment about seqlen_k to avoid confusion. ### Motivation and Context microsoft#20279
### Description <!-- Describe your changes. --> optimize the GQA implementation on CPU. Mainly optimization are: 1. compute attention on real total sequence length instead of maximum sequence length in case past/present share same buffer 2. remove the mask 3. remove the transpose after attention x value It improve the phi3 model https://github.com/microsoft/onnxruntime-genai/blob/main/examples/python/phi3-qa.py with max sequence length 2k/4k from 10 tps to 20 tps. ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
### Description When sequence length is 128K, block_mask has 2048 rows, that is not supported by previous kernel. (1) Add a new kernel to handle more than 1024 rows, and each thread need handle two rows. (2) Add a test for sequence length 128k.
This pull request primarily involves changes to the build scripts in the `tools/ci_build/github/azure-pipelines` directory. The changes add build date and time information to the build process. This is achieved by introducing two new parameters, `BuildDate` and `BuildTime`, and incorporating them into the `msbuildArguments` in multiple locations. Addition of new parameters: * [`tools/ci_build/github/azure-pipelines/templates/c-api-cpu.yml`](diffhunk://#diff-00815920cc190d10fdebceac0c3a4b8a59e408684ae38177dfe7f96cae276c59R309-R310): Added `BuildDate` and `BuildTime` parameters using the pipeline's start time. Incorporation of new parameters in `msbuildArguments`: * [`tools/ci_build/github/azure-pipelines/c-api-noopenmp-packaging-pipelines.yml`](diffhunk://#diff-efb530efd945fdd9d3e1b92e53d25cc8db7df2e28071c364b07a7193092de01bL947-R948): Added `CurrentDate` and `CurrentTime` parameters to `msbuildArguments` in multiple locations. [[1]](diffhunk://#diff-efb530efd945fdd9d3e1b92e53d25cc8db7df2e28071c364b07a7193092de01bL947-R948) [[2]](diffhunk://#diff-efb530efd945fdd9d3e1b92e53d25cc8db7df2e28071c364b07a7193092de01bL1092-R1093) [[3]](diffhunk://#diff-efb530efd945fdd9d3e1b92e53d25cc8db7df2e28071c364b07a7193092de01bL1114-R1115) [[4]](diffhunk://#diff-efb530efd945fdd9d3e1b92e53d25cc8db7df2e28071c364b07a7193092de01bL1137-R1138) * [`tools/ci_build/github/azure-pipelines/templates/c-api-cpu.yml`](diffhunk://#diff-00815920cc190d10fdebceac0c3a4b8a59e408684ae38177dfe7f96cae276c59L446-R448): Incorporated the `CurrentDate` and `CurrentTime` parameters into `msbuildArguments`.### Description <!-- Describe your changes. --> ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
### Description Add support for using Onnx Runtime with Node ### Motivation and Context Onnx Runtime supports the QNN HTP, but does not support it for Node.js. This adds baseline support for the Onnx Runtime to be used with Node. Note it does not update the node packages that are distributed officially. This simply patches the onnxruntime.dll to allow 'qnn' to be used as an execution provider. Testing was done using the existing onnxruntime-node package. The `onnxruntime.dll` and `onnxruntime_binding.node` were swapped into `node_modules\onnxruntime-node\bin\napi-v3\win32\arm64` with the newly built version, then the various QNN dlls and .so files were placed next to the onnxruntime.dll. Testing was performed on a variety of models and applications, but the easiest test is to modify the [node quickstart example](https://github.com/microsoft/onnxruntime-inference-examples/tree/main/js/quick-start_onnxruntime-node).
### Description orttrainingtestdatascus has only save mnist whose size is only 64M in Azure File To meet security requirements and reduce maintenance cost, move the test data to lotusscus and saved in Azure blob.
### Improve perf for mem efficient grad mgmt When memory efficient gradient mangement feature is enabled, the weight retrieval PythonOp for every layers will be launched at the beginning of the forward, which would make GPU stream idle for few milliseconds. The reason is the ReversedDFS ordering cannot ALWAYS handle such input branching well, so we introduce a distantance-to-input_leaf concepts when doing the reversedDFS, which not only move the problematical PythonOp to the place where it is needed, but also those Cast ops following the weight retrieval to the place where it is needed. Main branch: 102.19 - 26.35s = 75.84s for 260 steps(4627samples), 61.04sample/second This PR: 100.28s - 25.10s = 75.18s for 260 steps. 61.54samples/second (+0.8% gains) Main branch: 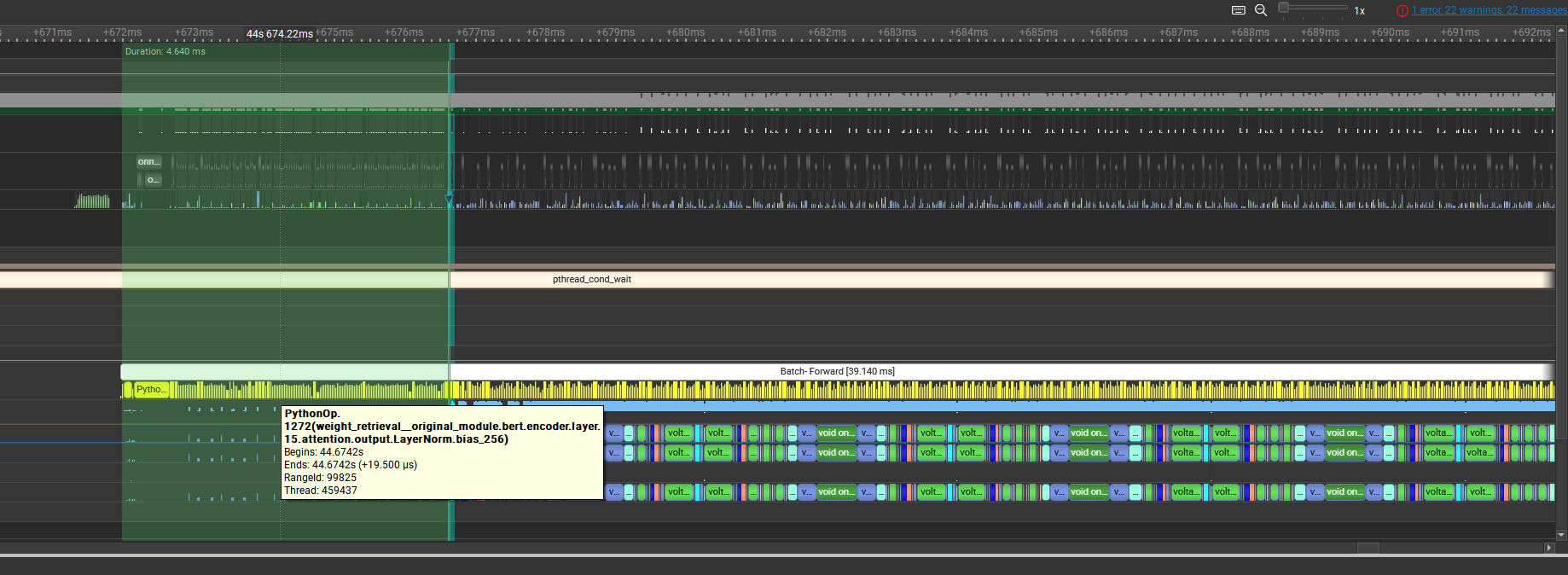 This PR:  ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
sign only onnxruntime.dll and onnxruntime_pybind11_state.pyd in packages.
) ### Description Make the operator more flexible: (1) Decouple the max sequence length of rotary cache, kv cache and block mask. They are allowed to have different values. (2) Replace block_mask dense by CSR format (block_row_indices and block_col_indices) to improve performance. (3) Mark past_key and past_value as required inputs since we need them to compute the shape of present_key and present_value. ### Motivation and Context (1) LongRoPE has short and long rotary cache, which has different length. (2) Most users do not have enough GPU memory to run maximum sequence length 128K. This change allows user to use smaller kv cache length to test without hitting out of memory.
…ully (microsoft#20626) ### Description <!-- Describe your changes. --> during VITSIAI shared library load, set unload to false to prevent crash when linux lib load not successfully ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. --> for Linux environment, when library not loaded successfully, it will end up with crash without giving any useful message. the fix is to prevent the crash and give the useful message when shared library not loaded correctly.
### Description
The InsertGatherBeforeSceLoss optimization is enabled when the density
of label padding less than 90%. We need to check the density of the
label padding to decide whether enable the optimization.
Before this pr, we just check the inputs of graph and correlate one with
the SCE node by iterate graph from the SCE node back to one graph input.
This is hard to be general because there may be complicated pattern
between graph input and SCE node.
This pr check padding density by the direct input of SCE module rather
than the input of graph at the first graph execution when exporting onnx
graph.
And if the density < 90%, insert a flag PythonOp after the SCE node as:
```
SoftmaxCrossEntropy
|
PythonOp (func_name: FlagAndPrintDensity) (insert if density < 90%)
|
Following graph
```
When the InsertGatherBeforeSceLoss is invoked, it check if there is the
flag PythonOp(func_name: FlagAndPrintDensity) after the SCE node and if
it is, remove it and do the padding elimination optimization.
If the env of ORTMODULE_PRINT_INPUT_DENSITY is 1, we will print input
density each step by the PythonOp (func_name: FlagAndPrintDensity). In
this case the PythonOp will not be removed.
### Description
Update benchmark_gqa.py to test latency on popular models (like
Llama3-8b, Llama3-70b, Mixtral-8x22B-v0.1 and Phi-3 etc).
Note that this is latency of just one GroupQueryAttention node, not the
whole model. For example, packed QKV might need more time in GQA, but it
is faster in MatMul of input projection, the overall effect is not
measured here.
Example output in A100-SXM4-80GB :
```
prompt-sm80-Llama3-8B-b1-h32_8x128-fp16:
sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.019073 0.016264
1 32.0 0.017768 0.017957
2 64.0 0.023304 0.023192
3 128.0 0.032541 0.031348
4 256.0 0.048329 0.049484
5 512.0 0.095294 0.095950
6 1024.0 0.228050 0.228980
7 2048.0 0.663820 0.663308
8 4096.0 2.243657 2.242999
9 8192.0 8.197120 8.186282
token-sm80-Llama3-8B-b1-h32_8_d128-fp16:
past_sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.018516 0.015398
1 32.0 0.015687 0.016079
2 64.0 0.016115 0.016053
3 128.0 0.018727 0.019413
4 256.0 0.036373 0.035962
5 512.0 0.041701 0.042203
6 1024.0 0.053730 0.053750
7 2048.0 0.076382 0.075707
8 4096.0 0.121876 0.121802
9 8191.0 0.211292 0.211254
prompt-sm80-Llama3-8B-b4-h32_8x128-fp16:
sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.024558 0.022070
1 32.0 0.021276 0.021406
2 64.0 0.044172 0.027789
3 128.0 0.069100 0.059071
4 256.0 0.146569 0.106717
5 512.0 0.270472 0.244461
6 1024.0 0.690024 0.692501
7 2048.0 2.308546 2.325453
8 4096.0 8.724295 8.957337
9 8192.0 39.030785 41.381378
token-sm80-Llama3-8B-b4-h32_8_d128-fp16:
past_sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.018893 0.018611
1 32.0 0.018124 0.018190
2 64.0 0.018115 0.018156
3 128.0 0.023291 0.023733
4 256.0 0.038357 0.038351
5 512.0 0.047117 0.047792
6 1024.0 0.066272 0.065409
7 2048.0 0.104196 0.104527
8 4096.0 0.180557 0.180424
9 8191.0 0.332545 0.332714
prompt-sm80-Llama3-70B-b1-h64_8x128-fp16:
sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.040974 0.015852
1 32.0 0.017839 0.018615
2 64.0 0.023956 0.022704
3 128.0 0.044622 0.035229
4 256.0 0.080241 0.075237
5 512.0 0.143457 0.144322
6 1024.0 0.380473 0.381731
7 2048.0 1.217328 1.214505
8 4096.0 4.305315 4.286324
9 8192.0 15.918250 15.933440
token-sm80-Llama3-70B-b1-h64_8_d128-fp16:
past_sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.016148 0.015612
1 32.0 0.015616 0.015616
2 64.0 0.016082 0.016070
3 128.0 0.019470 0.019130
4 256.0 0.036617 0.037296
5 512.0 0.042087 0.042176
6 1024.0 0.053704 0.053587
7 2048.0 0.076918 0.076365
8 4096.0 0.122534 0.121984
9 8191.0 0.212961 0.213330
prompt-sm80-Llama3-70B-b4-h64_8x128-fp16:
sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.031137 0.026270
1 32.0 0.030938 0.032009
2 64.0 0.040833 0.059118
3 128.0 0.084899 0.085482
4 256.0 0.163951 0.166310
5 512.0 0.420436 0.423721
6 1024.0 1.282019 1.283482
7 2048.0 4.397661 4.420121
8 4096.0 16.931839 17.456945
9 8192.0 77.896706 83.007484
token-sm80-Llama3-70B-b4-h64_8_d128-fp16:
past_sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.026106 0.026061
1 32.0 0.025678 0.025589
2 64.0 0.025438 0.025965
3 128.0 0.033879 0.033320
4 256.0 0.058078 0.057656
5 512.0 0.078010 0.078153
6 1024.0 0.106353 0.098079
7 2048.0 0.160039 0.159153
8 4096.0 0.282527 0.283346
9 8191.0 0.546207 0.542135
prompt-sm80-Mistral-7B-v0.1-b1-h32_8x128-fp16:
sequence_length ORT-GQA-Dense ORT-GQA-Local ORT-GQA-Dense-PackedQKV ORT-GQA-Local-PackedQKV
0 16.0 0.015722 0.015655 0.015666 0.016150
1 32.0 0.018590 0.018562 0.018136 0.024617
2 64.0 0.022480 0.023085 0.023184 0.023160
3 128.0 0.029948 0.030581 0.030839 0.031464
4 256.0 0.048532 0.049099 0.049424 0.049408
5 512.0 0.095096 0.095665 0.096174 0.096175
6 1024.0 0.228606 0.228942 0.228434 0.229568
7 2048.0 0.660832 0.661943 0.662170 0.663979
8 4096.0 2.238001 2.243999 2.242243 2.241707
9 8192.0 8.173824 6.147072 8.187648 6.152822
10 16384.0 33.826305 14.486015 34.849792 14.938283
11 32768.0 176.702469 32.725330 184.309753 34.736130
token-sm80-Mistral-7B-v0.1-b1-h32_8_d128-fp16:
past_sequence_length ORT-GQA-Dense ORT-GQA-Local ORT-GQA-Dense-PackedQKV ORT-GQA-Local-PackedQKV
0 16.0 0.015407 0.016042 0.016030 0.015429
1 32.0 0.015525 0.016115 0.016768 0.016052
2 64.0 0.015556 0.016079 0.015383 0.016008
3 128.0 0.019302 0.018644 0.018680 0.019278
4 256.0 0.036924 0.035900 0.036753 0.036786
5 512.0 0.041482 0.041434 0.041646 0.042238
6 1024.0 0.053587 0.052972 0.052888 0.052856
7 2048.0 0.075749 0.075807 0.076528 0.075945
8 4096.0 0.122053 0.122016 0.122115 0.122216
9 8192.0 0.212069 0.121317 0.211919 0.121087
10 16384.0 0.394036 0.121202 0.393661 0.121483
11 32767.0 0.757216 0.124326 0.757659 0.124157
prompt-sm80-Mistral-7B-v0.1-b4-h32_8x128-fp16:
sequence_length ORT-GQA-Dense ORT-GQA-Local ORT-GQA-Dense-PackedQKV ORT-GQA-Local-PackedQKV
0 16.0 0.018418 0.018911 0.023387 0.019256
1 32.0 0.021085 0.021132 0.022143 0.022251
2 64.0 0.026743 0.026770 0.027942 0.027714
3 128.0 0.057922 0.058483 0.058800 0.059402
4 256.0 0.105927 0.104876 0.106695 0.105996
5 512.0 0.242958 0.242543 0.244599 0.244774
6 1024.0 0.689321 0.689347 0.691759 0.692334
7 2048.0 2.308250 2.304410 2.321587 2.317875
8 4096.0 8.705210 8.713682 8.927418 8.903866
9 8192.0 39.630848 28.227926 41.604607 29.648554
10 16384.0 175.553543 61.422592 183.384064 64.560127
11 32768.0 772.296692 132.006912 813.537292 138.996735
token-sm80-Mistral-7B-v0.1-b4-h32_8_d128-fp16:
past_sequence_length ORT-GQA-Dense ORT-GQA-Local ORT-GQA-Dense-PackedQKV ORT-GQA-Local-PackedQKV
0 16.0 0.018127 0.018691 0.018661 0.018681
1 32.0 0.018183 0.018812 0.018739 0.018759
2 64.0 0.018081 0.018116 0.018136 0.018153
3 128.0 0.023257 0.023146 0.023114 0.023103
4 256.0 0.038665 0.038102 0.038120 0.038759
5 512.0 0.047181 0.047156 0.047012 0.046382
6 1024.0 0.066047 0.066103 0.066604 0.066076
7 2048.0 0.104427 0.103770 0.103799 0.103807
8 4096.0 0.180951 0.180373 0.180173 0.180154
9 8192.0 0.334018 0.180801 0.333269 0.180690
10 16384.0 0.638682 0.180965 0.638543 0.180202
11 32767.0 1.249536 0.184779 1.249963 0.184624
prompt-sm80-Mixtral-8x22B-v0.1-b1-h48_8x128-fp16:
sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.015699 0.015563
1 32.0 0.017931 0.017719
2 64.0 0.029975 0.022875
3 128.0 0.031038 0.055747
4 256.0 0.050191 0.050845
5 512.0 0.125187 0.122813
6 1024.0 0.304004 0.301824
7 2048.0 0.936454 0.931546
8 4096.0 3.264547 3.255931
9 8192.0 12.062719 12.030080
10 16384.0 49.018368 48.970749
11 32768.0 261.211151 254.461945
12 65536.0 1221.138428 1197.559814
token-sm80-Mixtral-8x22B-v0.1-b1-h48_8_d128-fp16:
past_sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.015980 0.016024
1 32.0 0.015440 0.016165
2 64.0 0.015987 0.015979
3 128.0 0.020837 0.018715
4 256.0 0.036240 0.036747
5 512.0 0.042477 0.041813
6 1024.0 0.052950 0.052956
7 2048.0 0.076084 0.076691
8 4096.0 0.122233 0.121540
9 8192.0 0.212469 0.212433
10 16384.0 0.394937 0.394996
11 32768.0 0.757285 0.757257
12 65535.0 1.484867 1.485015
prompt-sm80-Mixtral-8x22B-v0.1-b4-h48_8x128-fp16:
sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.024119 0.018755
1 32.0 0.022214 0.022267
2 64.0 0.028045 0.027562
3 128.0 0.062894 0.079766
4 256.0 0.135146 0.134483
5 512.0 0.331323 0.329094
6 1024.0 0.984576 0.982221
7 2048.0 3.353564 3.351021
8 4096.0 12.762113 12.778350
9 8192.0 58.599422 57.704449
10 16384.0 263.392242 258.709503
11 32768.0 1155.789795 1128.622070
12 65536.0 5014.187012 4874.590332
token-sm80-Mixtral-8x22B-v0.1-b4-h48_8_d128-fp16:
past_sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.018148 0.018813
1 32.0 0.018929 0.018840
2 64.0 0.018745 0.018232
3 128.0 0.023864 0.023822
4 256.0 0.038603 0.038694
5 512.0 0.048347 0.047630
6 1024.0 0.066957 0.067392
7 2048.0 0.105094 0.105058
8 4096.0 0.181941 0.181808
9 8192.0 0.334227 0.334324
10 16384.0 0.640429 0.640961
11 32768.0 1.267897 1.269120
12 65535.0 2.534238 2.504408
prompt-sm80-Phi-3-mini-128k-b1-h32_32x96-fp16:
sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.016112 0.026949
1 32.0 0.016486 0.017284
2 64.0 0.020910 0.020994
3 128.0 0.029306 0.029452
4 256.0 0.044604 0.044642
5 512.0 0.090079 0.086868
6 1024.0 0.208169 0.208094
7 2048.0 0.604687 0.607910
8 4096.0 2.029056 2.046771
9 8192.0 7.792128 7.906303
10 16384.0 34.271233 34.418175
11 32768.0 160.377853 159.980545
12 65536.0 733.443054 734.722046
token-sm80-Phi-3-mini-128k-b1-h32_32_d96-fp16:
past_sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.016339 0.015718
1 32.0 0.016572 0.015964
2 64.0 0.016182 0.016192
3 128.0 0.019373 0.018621
4 256.0 0.021856 0.022463
5 512.0 0.028943 0.028888
6 1024.0 0.041124 0.041104
7 2048.0 0.067668 0.067542
8 4096.0 0.117528 0.117447
9 8192.0 0.216241 0.215492
10 16384.0 0.413434 0.414047
11 32768.0 0.811085 0.810612
12 65536.0 1.606189 1.606458
13 131071.0 3.193037 3.192491
prompt-sm80-Phi-3-mini-128k-b4-h32_32x96-fp16:
sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.019385 0.019403
1 32.0 0.019801 0.020006
2 64.0 0.025958 0.025376
3 128.0 0.056445 0.055909
4 256.0 0.103180 0.102221
5 512.0 0.244224 0.244360
6 1024.0 0.703066 0.709327
7 2048.0 2.307456 2.335001
8 4096.0 8.334522 8.406760
9 8192.0 33.340416 33.758209
10 16384.0 144.141312 145.005569
11 32768.0 655.496216 655.656982
12 65536.0 2981.463135 2984.790039
token-sm80-Phi-3-mini-128k-b4-h32_32_d96-fp16:
past_sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.018701 0.018185
1 32.0 0.020625 0.019213
2 64.0 0.019936 0.019943
3 128.0 0.023648 0.023689
4 256.0 0.030309 0.030305
5 512.0 0.043501 0.043801
6 1024.0 0.067314 0.068014
7 2048.0 0.108649 0.108134
8 4096.0 0.186053 0.186848
9 8192.0 0.339973 0.339742
10 16384.0 0.643288 0.644366
11 32768.0 1.261468 1.261510
12 65536.0 2.502252 2.501820
13 131071.0 4.990437 4.989521
prompt-sm80-Phi-3-small-128k-b1-h32_8x128-fp16:
sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.025280 0.023331
1 32.0 0.023071 0.025931
2 64.0 0.022883 0.026258
3 128.0 0.030658 0.031445
4 256.0 0.057659 0.057073
5 512.0 0.095589 0.106579
6 1024.0 0.228532 0.229402
7 2048.0 0.662315 0.663349
8 4096.0 2.242885 2.248095
9 8192.0 8.194646 8.180395
10 16384.0 33.926659 35.130882
11 32768.0 175.320068 184.967163
12 65536.0 810.447876 847.632385
token-sm80-Phi-3-small-128k-b1-h32_8_d128-fp16:
past_sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.015517 0.016038
1 32.0 0.016372 0.015477
2 64.0 0.015472 0.016016
3 128.0 0.019291 0.018664
4 256.0 0.036250 0.035990
5 512.0 0.041691 0.042238
6 1024.0 0.053730 0.053126
7 2048.0 0.075912 0.076439
8 4096.0 0.121336 0.121334
9 8192.0 0.213104 0.212443
10 16384.0 0.394353 0.394272
11 32768.0 0.756965 0.757017
12 65536.0 1.484548 1.485371
13 131071.0 2.939200 2.939552
prompt-sm80-Phi-3-small-128k-b4-h32_8x128-fp16:
sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.044326 0.019298
1 32.0 0.021840 0.021408
2 64.0 0.027492 0.027802
3 128.0 0.058128 0.059431
4 256.0 0.104300 0.106019
5 512.0 0.242562 0.244948
6 1024.0 0.689614 0.692305
7 2048.0 2.297931 2.312857
8 4096.0 8.654848 8.843170
9 8192.0 38.770176 40.929279
10 16384.0 175.572998 183.692291
11 32768.0 780.126221 820.551697
12 65536.0 3357.564941 3488.527344
token-sm80-Phi-3-small-128k-b4-h32_8_d128-fp16:
past_sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.018061 0.017995
1 32.0 0.018225 0.018851
2 64.0 0.018203 0.018104
3 128.0 0.023161 0.023651
4 256.0 0.038421 0.037673
5 512.0 0.047590 0.046938
6 1024.0 0.065639 0.066055
7 2048.0 0.103545 0.103581
8 4096.0 0.180461 0.179998
9 8192.0 0.332667 0.332564
10 16384.0 0.638503 0.639094
11 32768.0 1.249180 1.249479
12 65536.0 2.469457 2.471666
13 131071.0 4.915362 4.914499
prompt-sm80-Phi-3-medium-128K-b1-h40_10x128-fp16:
sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.025759 0.016318
1 32.0 0.018282 0.018111
2 64.0 0.022642 0.022978
3 128.0 0.030860 0.037988
4 256.0 0.055703 0.050318
5 512.0 0.113465 0.113776
6 1024.0 0.267678 0.268292
7 2048.0 0.795202 0.797222
8 4096.0 2.737953 2.740435
9 8192.0 10.101760 10.149092
10 16384.0 43.326466 43.990013
11 32768.0 230.886398 229.886978
12 65536.0 1067.412476 1052.922852
token-sm80-Phi-3-medium-128K-b1-h40_10_d128-fp16:
past_sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.016122 0.015582
1 32.0 0.015594 0.016262
2 64.0 0.016099 0.015512
3 128.0 0.018708 0.019510
4 256.0 0.037582 0.036341
5 512.0 0.042411 0.041894
6 1024.0 0.053278 0.053914
7 2048.0 0.076553 0.076636
8 4096.0 0.121539 0.121610
9 8192.0 0.212083 0.212377
10 16384.0 0.395086 0.395280
11 32768.0 0.757879 0.757888
12 65536.0 1.486093 1.486915
13 131071.0 2.941728 2.941408
prompt-sm80-Phi-3-medium-128K-b4-h40_10x128-fp16:
sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.019448 0.018872
1 32.0 0.022290 0.022380
2 64.0 0.027986 0.027955
3 128.0 0.062699 0.062175
4 256.0 0.124868 0.125247
5 512.0 0.298873 0.298169
6 1024.0 0.862584 0.863467
7 2048.0 2.944640 2.957824
8 4096.0 11.318656 11.390720
9 8192.0 52.606976 52.019199
10 16384.0 232.616959 230.360062
11 32768.0 1024.171997 1019.540466
12 65536.0 4377.362305 4354.510742
token-sm80-Phi-3-medium-128K-b4-h40_10_d128-fp16:
past_sequence_length ORT-GQA-Dense ORT-GQA-Dense-PackedQKV
0 16.0 0.018192 0.018175
1 32.0 0.018999 0.018319
2 64.0 0.018447 0.018897
3 128.0 0.023863 0.023195
4 256.0 0.037712 0.038192
5 512.0 0.048863 0.048548
6 1024.0 0.067244 0.066473
7 2048.0 0.105203 0.105021
8 4096.0 0.180712 0.180429
9 8192.0 0.334948 0.334734
10 16384.0 0.640662 0.639709
11 32768.0 1.252196 1.251684
12 65536.0 2.474927 2.474280
13 131071.0 4.930829 4.959340
```
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description - This PR combine all CUDA 12 stage into the Zip-nuget-... pipeline. - It also enables the cuda12 support ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
### Motivation and Context The Intel NPU does not support 16-bit int quantized operators. Consequently, the execution provider removes the QuantizeLinear/DeQuantizeLinear (Q/DQ) operators from node units and executes the operation as FP16 in the backend. However, if a Clip operator was fused into a Q operator in the node unit, the removal of Q/DQ operators results in inaccuracies because the effect of the original Clip operators is lost. Consider the following example: - FP32 model: -> Op_FP32 -> Clip -> - QDQ model: -> (DQ-> Op_FP32 -> Q) -> (DQ' -> Clip -> Q') -> - After ClipQuantFusion: -> (DQ-> Op_FP32 -> Q) -> (DQ' -> Q') -> - Intel Execution Provider strips Q/DQ: -> Op_FP16 -> To solve this issue, we have enabled ClipQuantFusion exclusively on the CPU execution provider.
### Description Adds the extra option `QDQKeepRemovableActivations` to optionally prevent automatic removal of Clip/Relu ops in QDQ models. The current default behavior, which is to remove Clip/Relu, remains the same if the new option is not enabled. ### Motivation and Context Explicitly representing these Relu/Clip operators in the QDQ model is necessary if optimizations or EP transformations will later remove QuantizeLinear/DequantizeLinear operators from the model.
…osoft#20650) Do more in the Python helper script so the Bash code in the release definition can be simplified.
TODOs: 1. Handle H * params.kvNumHeads greater than work group size limit. 2. Support BNSH kv cache.
…microsoft#20652) ### Description And Set allowPackageConflicts = True `#allowPackageConflicts: false # boolean. Optional. Use when command = push && nuGetFeedType = internal. Allow duplicates to be skipped. Default: false.` https://learn.microsoft.com/en-us/azure/devops/pipelines/tasks/reference/nuget-command-v2?view=azure-pipelines Once the publish patial failed, we don't need to rerun the whole package generation workflow.
### Description Enable Qnn nuget nightly
### Description <!-- Describe your changes. --> ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
- Move iOS package build to separate job so it can run in parallel with Android AAR build and be decoupled from the test stage. The test stage fails sometimes (not infrequently) and may need to be re-run. - Update stop iOS simulator step so it doesn't fail if the start step doesn't run.
### Description <!-- Describe your changes. --> - Fix `logSeverityLevel` - Correct get RCTCxxBridge, old method for some cases will got wrong bridge ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. --> --------- Co-authored-by: Yulong Wang <[email protected]>
Update the instructions of how to get test models.
### Description <!-- Describe your changes. --> ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
WebNN spec has removed activation option for conv and batchNormalization. We don't need additional activation fusion in WebNN EP anymore. [edit by fdwr] Note this is handled in the browser now, which knows more about the backend platform version and can more safely make decisions about which fusions are possible (e.g. for the DirectML backend, whether softmax and gelu can fuse successfully with their base operator).
### Description <!-- Describe your changes. --> * Partially revert [previous change](microsoft#19804), and * Redo concurrency_test_result parser outside of post.py * Add support of syncing memtest result to db ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. --> To fix the error when CI is running on two model groups. - When running on two model groups, the [previous change](microsoft#19804) wrongly navigates two levels up in the directory after running one model group, while one level is needed. After that, the script can't find another model group. - Running on one model group can't repro the issue
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
No description provided.