Improve perf for mem efficient grad mgmt #20480
Merged
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
orttraining/orttraining/python/training/ortmodule/_mem_efficient_grad_mgmt.py
Fixed
Show fixed
Hide fixed
AdamLouly
reviewed
Apr 30, 2024
orttraining/orttraining/python/training/ortmodule/_mem_efficient_grad_mgmt.py
Show resolved
Hide resolved
orttraining/orttraining/python/training/ortmodule/_mem_efficient_grad_mgmt.py
Outdated
Show resolved
Hide resolved
…pengwa/perf_efficient_mem
|
Thanks @AdamLouly !! |
poweiw
pushed a commit
to poweiw/onnxruntime
that referenced
this pull request
Jun 25, 2024
### Improve perf for mem efficient grad mgmt When memory efficient gradient mangement feature is enabled, the weight retrieval PythonOp for every layers will be launched at the beginning of the forward, which would make GPU stream idle for few milliseconds. The reason is the ReversedDFS ordering cannot ALWAYS handle such input branching well, so we introduce a distantance-to-input_leaf concepts when doing the reversedDFS, which not only move the problematical PythonOp to the place where it is needed, but also those Cast ops following the weight retrieval to the place where it is needed. Main branch: 102.19 - 26.35s = 75.84s for 260 steps(4627samples), 61.04sample/second This PR: 100.28s - 25.10s = 75.18s for 260 steps. 61.54samples/second (+0.8% gains) Main branch: 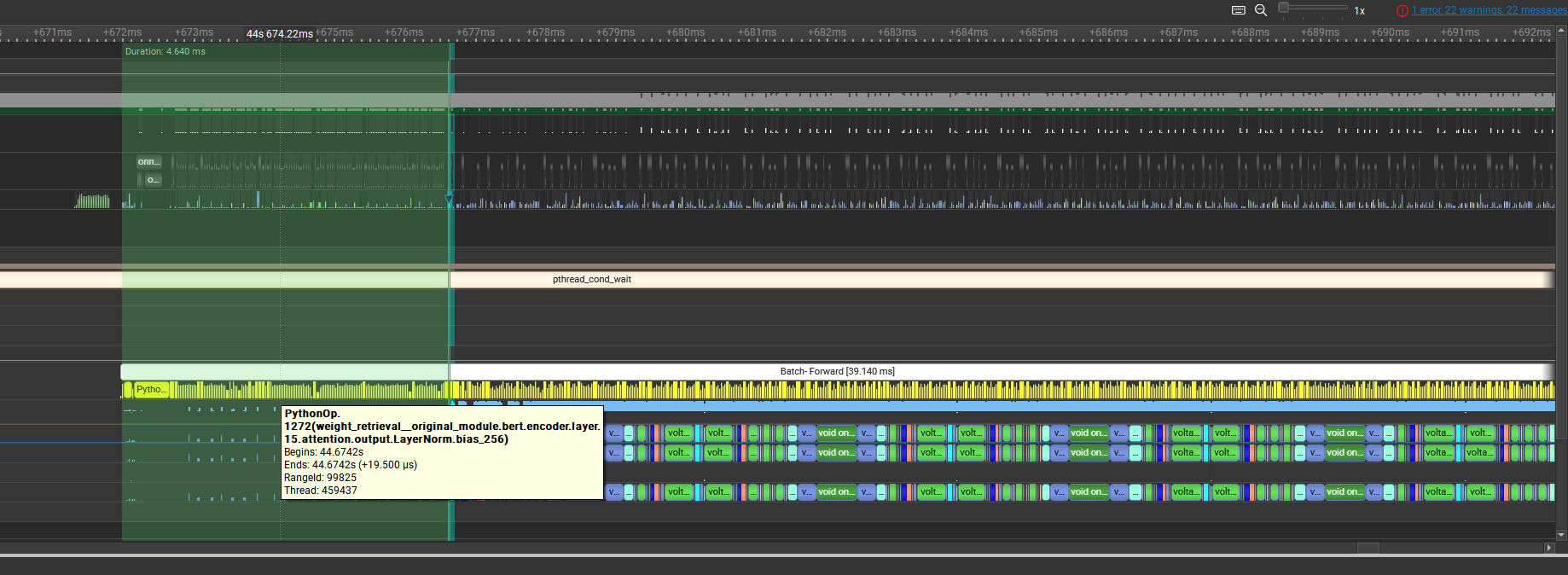 This PR:  ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Improve perf for mem efficient grad mgmt
When memory efficient gradient mangement feature is enabled, the weight retrieval PythonOp for every layers will be launched at the beginning of the forward, which would make GPU stream idle for few milliseconds. The reason is the ReversedDFS ordering cannot ALWAYS handle such input branching well, so we introduce a distantance-to-input_leaf concepts when doing the reversedDFS, which not only move the problematical PythonOp to the place where it is needed, but also those Cast ops following the weight retrieval to the place where it is needed.
Main branch: 102.19 - 26.35s = 75.84s for 260 steps(4627samples), 61.04sample/second
This PR: 100.28s - 25.10s = 75.18s for 260 steps. 61.54samples/second (+0.8% gains)
Main branch:
This PR:
Motivation and Context