{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
#Behavioral cloning
The aim of this present project is to predict the steering angle to be applied on a car using images captured using a front facing camera. For this purpose, this image is fed as an input to a convolutional network, followed by several fully connected layers, which results in the final normalized steering command. This model is trained on data acquired by driving the vehicle manually around a circuit . Hence, the model tries to copy the natural behavior of a driver, which is a method called behavioral cloning. This architecture of the project is illustrated in the following diagram.
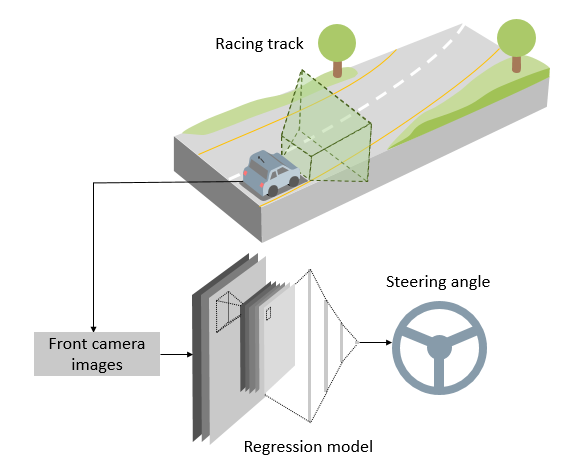
This repository contains all the code required to train and drive the vehicle around the track.
Files:
- Behaviourial_cloning.ipynb
- drive.py
- Readme.md
- steering_angles.json and steering_angles.h5
Firstly, the training code is provided in the form of a juypter notebook. All cells should be run in order to train a model and save the output. This notebook also illustrates how to use all the functions for data exploration and data augmentation. Secondly, the drive.py file is used to capture the images sent by the simulator, feed them to the model and send back the corresponding steering angle to the simulator. The code is run through the command prompt using the following command:
python drive.py steering_angle.jsonThe model is saved in the form of a json file and a h5 file for the weights.
The data used to train this model was acquired by Udacity and is available at https://github.com/udacity/CarND-Behavioral-Cloning-P3 . The simulator used to test the code is available at https://github.com/udacity/self-driving-car-sim.
In order to get a better grasp of the problem to solve, the data used for the training was first explored. In this section, only the data set released by Udacity was considered. The following general features were extracted from the set:
| Parameter | Value |
|---|---|
| Number of samples | 8036 |
| Maximum steering angle | 1 |
| Minimum steering angle | -0.94 |
| Image size | (160, 320, 3) |
| Image color space | RGB |
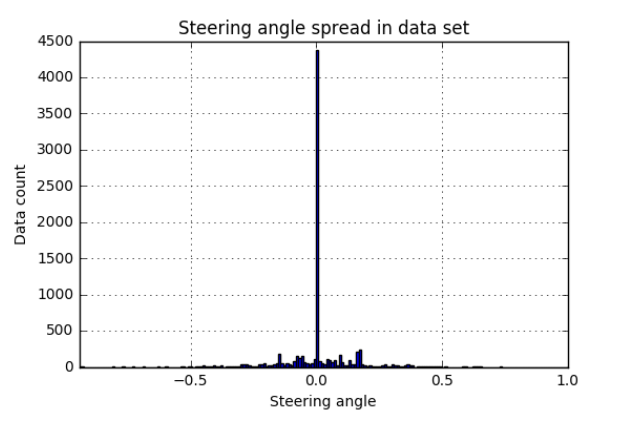
A histogram of the different driving angles present in the set was also plotted. It is observed that the set is strongly biased towards straight driving, which will result in a model with a similar bias if used for training. In the next section of this report, data augmentation methods are proposed in order to shape this curve and improve the performance of the model.
In real world conditions, the acquisition of driving data requires many driving hours and is quite costly if one wants to cover every possible scenario. Modifying a smaller subset of data in order to represent a broader range of situations is therefore of great interest. This method, called data augmentation, can be done on-the-fly during the training of the model, which minimizes the required memory and hard drive space.
Different data augmentation methods have been used in this project in order to improve the performance of the prediction model on the first track. They also allowed the same model to generalized on the second track for which no data was present in the training set. Hence, data augmentation method help our model to better generalize, reduce over-fitting to the acquired data and allow it to learn general driving rules.
The data for the first track was acquired considering sunny conditions. Applying a randomized exposure variation to those images allows to represent over-cast conditions, which are present in the second track. The exposure variation is realized by changing the representation of the image from the RGB color space to the HSV. Subsequently, the V component of this image is randomly scaled and the image is finally brought back to the RGB space. The data resulting from this augmentation is shown in the following image.

The data provided by Udacity is recorded on the first track and considering only one driving direction. Hence, there are more left turns than right turns, which biases the model. By flipping all the images and changing the sign of the corresponding steering angle, the size of the data set is doubled and this bias is removed. The output of this augmentation is shown in the following images.

The acquired data represents a normal driving behavior on the race track. If one trains considering only this ideal trajectory, the model will slowly drift and end-up leaving the road. The model should also learn how to recover from off-center positions. For this purpose, the considered vehicle is equipped with two off-center cameras, which take the same image as the centered camera but with a slight offset to the left and to the right. By adjusting the corresponding steering angle to drive the vehicle back to the center of the road, the model learns to recover from this drift. The offset applied to the steering command is very important and tweaked experimentally. If this value is too low, the vehicle will still drift off the road and if this value is too high, the vehicle will zig-zag across the road. An optimal offset of 0.22 was reached. The output of the lateral cameras is represented in the following images.

Another method to help the vehicle take sharper turns and to help it recover from drift is to rotate it randomly on the road and adapt the steering angle accordingly. For this purpose, the image was split horizontally at the approximate height of the horizon. Since the data was only recorded on the first track, this horizon height value could be kept constant as no slopes are present on this track. The lower part of this image is then skewed horizontally in order to simulate a shift in orientation of the car. This skewed-half is finally stitched back to the sky. The steering angle is adapted to steer the vehicle back to the center of the road, with an offset that is proportional to the randomly drawn rotation shift.

The mountains present in the second track cast strong shadows on the road, which confused the model initially. Those shadows were also added artificially on the recorded data by using a weighted sum of a black polygon and the initial image. The weight of this sum is called alpha value and corresponds to the strength of the shadow.

A great amount of the recorded images are occupied by the sky and the hood of the vehicle, which contain no meaningful information for the steering angle predictor. Therefore, those parts were cropped before the image was used for the training.

Finally, the augmented image is resized in order to fit the input size of the first layer of the model. This results in a down-sized image and, therefore, in a reduction of the amounts of weights to be trained.
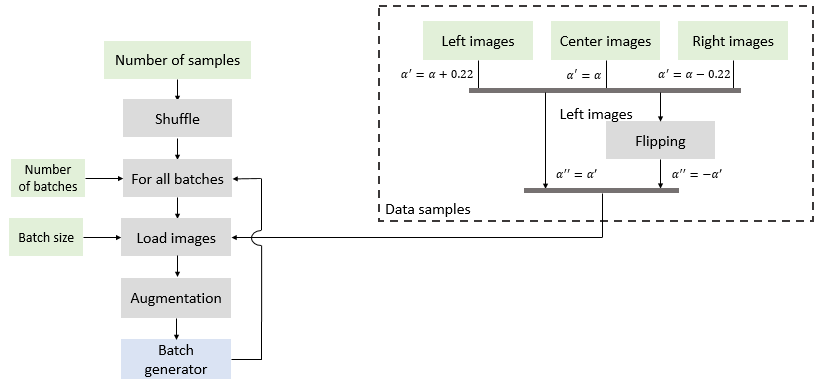
Since the entire data set does not fit in my RAM, I decided to load the images batch by batch using indexed to refer to them. For this purpose, all the images for the left, right, center and the corresponding flipped images are mapped to a vector of unique references. This vector can be split before training into a training and a validation data set.
At the start of a training epoch, this vector is shuffled and sliced in smaller vectors of length equal to the batch size. Those references are used to load the batches one-by-one in the memory, to augment the corresponding data and then to train the network. The loaded data is discarded before the next batch is loaded. Using a Keras fit_generator allows to do this without loss in performance or training speed. The full pipeline used for the training and augmentation is proposed in the following diagram.
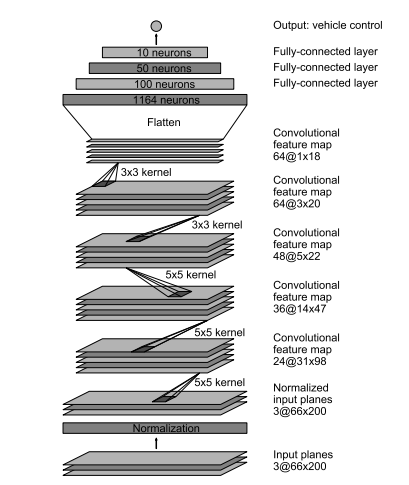
The model used in this work was originally proposed by Nvidia in the following paper: https://arxiv.org/pdf/1604.07316.pdf. This architecture was found to perform well for the present task and was therefore not modified. The activation used between all the layers are rectified linear units. Dropout was used before each fully-connected layer in order to reduce the over-fitting of the model.
The model was trained using an Adam optimizer and considering the following hyper-parameters:
| Hyper parameter | Value |
|---|---|
| Learning rate | 0.0001 |
| Dropout | 0.5 |
| Batch size | 128 |
| Number of batches per epoch | 200 |
| Number of epochs | 7 |
The loss that was optimized was the MSE on the steering angle. However, it was found that this value was not really representative of the steering performance of the model. Therefore, it was chosen instead to stop the training after several epochs and to test the model on the track. The final training, once all the hyper-parameters were optimized, was done by fusing the training and validation dataset together.
The car is able to drive around the first track without crossing the borders. Through careful tuning of the parameters, the oscillations of the vehicle were minimized, which results in a behavior close to a human driver. Thanks to the strong augmentation of the data, the car was also able to generalize to the second track, which it had never seen before. This was also achieved considering higher graphic settings, which results in extra shadows cast on the road. In conclusion, data augmentation methods and careful training of the model allowed it to learn general driving rules and allowed it to perform up to expectation on both tracks.