Capture Questions, Answer with Code
| Name | Blog | |
|---|---|---|
| Young Jin Ahn | [email protected] | snoop2head.github.io |
Master of Science in Artificial Intelligence
- Machine Learning for AI (A+)
- Large Language Models (A+)
- Programming for AI (A+)
- Deep Reinforcement Learning (A+)
- Machine Learning for Healthcare (A+)
- Advanced Machine Learning for AI (A0)
- Advanced Deep Learning (A-)
- Scientific Writing (P)
Bachelor of Arts in Economics & Minor in Applied Statistics
- INTRODUCTION TO STATISTICS (A0)
- STATISTICAL METHOD (A+)
- CALCULUS (B+)
- LINEAR ALGEBRA (B+)
- MATHEMATICAL STATISTICS 1 (A+)
- LINEAR REGRESSION (B+)
- R AND PYTHON PROGRAMMING (A+)
- DATA STRUCTURE (B+)
- SPECIAL PROBLEMS IN COMPUTING (A0)
- SOCIAL INFORMATICS (A+)
- TIME SERIES ANALYSIS (A+)
- THEORY AND PRACTICE OF DEEP LEARNING (A+)

Transparent Large Language Model via scaling the expert count to 262,144.
- Parameter-efficient architecture with increased number of experts: By utilizing a novel expert decomposition method, Monet addresses memory constraints, ensuring that the total number of parameters scales proportionally to the square root of the number of experts.
- Mechanistic interpretability via monosemantic experts: Monet facilitates mechanistic interpretability by enabling observations of fine-grained experts’ routing patterns. Our analyses confirm mutual exclusivity of knowledge between groups of experts, while qualitative examples demonstrate individual experts’ parametric knowledge.
- Robust knowledge manipulation without performance trade-offs: Monet allows for end-to-end training that extends to robust knowledge manipulation during inference. Without degrading performance, it provides effortless control over knowledge domains, languages, and toxicity mitigation.
📄 SyncVSR: Data-Efficient Visual Speech Recognition with End-to-End Crossmodal Audio Token Synchronization (Interspeech 2024)
| Overview of SyncVSR | Performance of SyncVSR on LRS3 |
|---|---|
 |
 |
Frame-level crossmodal supervision with quantized audio tokens for enhanced Visual Speech Recognition.
- A prominent challenge in VSR is the presence of homophenes—visually similar lip gestures that represent different phonemes.
- Prior approaches have sought to distinguish fine-grained visemes by aligning visual and auditory semantics, but often fell short of full synchronization.
- Our proposed learning framework, SyncVSR, shows versatility across tasks, languages, and input modalities at the cost of a forward pass.
- By integrating a projection layer that synchronizes visual representation with acoustic data, the encoder learns to generate discrete audio tokens from a video sequence in a non-autoregressive manner.

Generating dress outfit images based on given input text | 📄 Presentation
- Created training pipeline from VQGAN through DALLE
- Maintained versions of 1 million pairs image-caption dataset.
- Trained VQGAN and DALLE model from the scratch.
- Established live demo for the KoDALLE on Huggingface Space via FastAPI.
| Host / Platform | Topic / Task | Result | Repository | Year |
|---|---|---|---|---|
| National IT Industry Promotion Agency |
Machine Reading Compehension | 🥈 2nd (2/26) |
2022 | |
| Ministry of Statistics | Korean Standard Industry Classification | 🎖 7th (7/311) |
- | 2022 |
| Dacon | KLUE benchmark Natural Language Inference | 🥇 1st (1/468) |
🌐 KLUE NLI | 2022 |
| Dacon & AI Frenz | Python Code Clone Detection | 🥉 3rd (3/337) |
2022 | |
| Dacon & CCEI Korea | Stock Price Forecast on KOSPI & KOSDAQ | 🎖 6th (6/205) |
2021 |
**Dacon is Kaggle alike competition platform in Korea.
Implementation of Carlini et al(2020) Extracting Training Data from Large Language Models
- Accelerated inference speed with parallel Multi-GPU usage.
- Ruled out 'low-quality repeated generations' problem of the paper with repetition penalty and with ngram restriction.
Implementation of Shokri et al(2016) Membership Inference Attacks Against Machine Learning Models
- Prevented overfitting of shadow models' by adding early stop, regularizing with weight decay and allocating train/val/test datasets.
- Referenced Carlini et al(2021) to conduct further research on different types of models and metrics.
- Reproduced attack metrics as the following.
| MIA Attack Metrics | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| CIFAR10 | 0.7761 | 0.7593 | 0.8071 | 0.7825 |
| CIFAR100 | 0.9746 | 0.9627 | 0.9875 | 0.9749 |
| MIA ROC Curve CIFAR10 | MIA ROC Curve CIFAR100 |
|---|---|
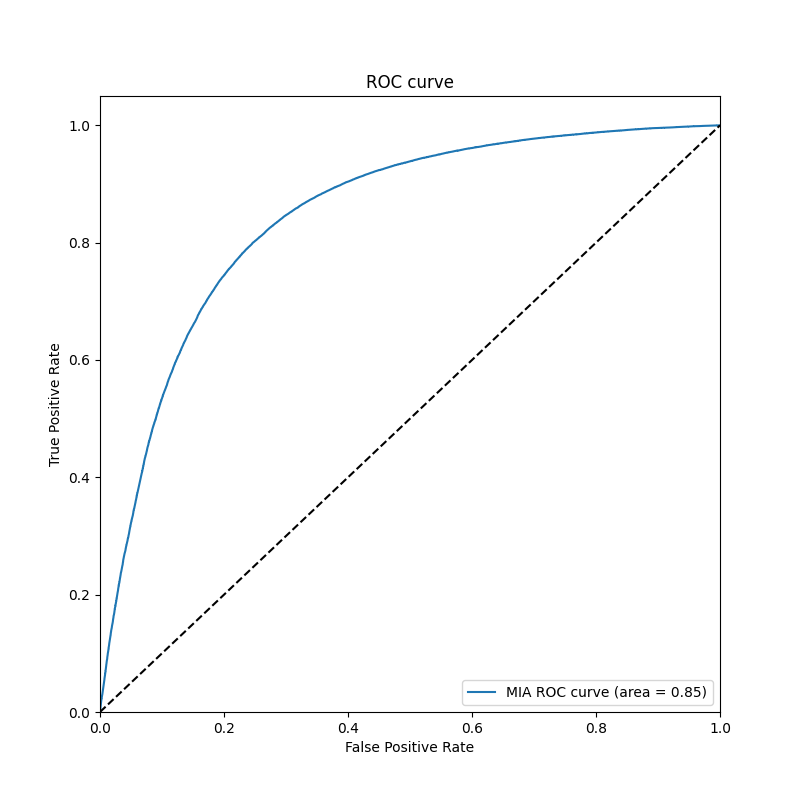 |
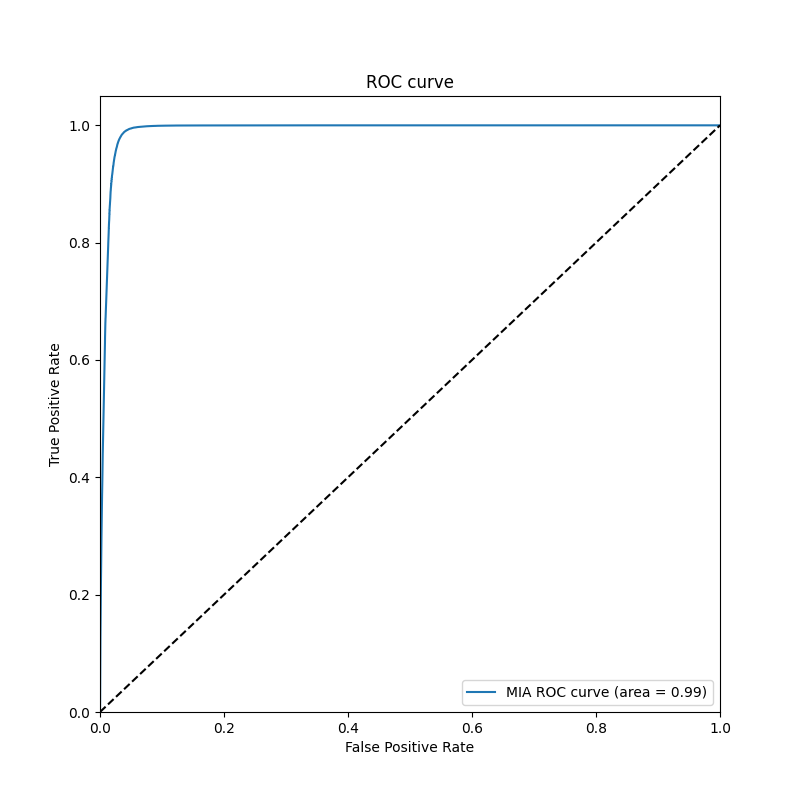 |
Paraphrasing tool with round trip translation utilizing T5 Machine Translation. | 🤗 KoQuillBot Demo & 🤗 Translator Demo
| BLEU Score | Translation Result | |
|---|---|---|
| Korean ➡️ English | 45.15 | 🔗 Inference Result |
| English ➡️ Korean | - | - |
Implementation of Kasai et al(2020) Deep Encoder, Shallow Decoder: Reevaluating Non-autoregressive Machine Translation | 📄 Translation Output
- Composed custom dataset, trainer, inference code in pytorch and huggingface.
- Trained and hosted encoder-decoder transformers model using huggingface.
| BLEU Score | Translation Result | |
|---|---|---|
| Korean ➡️ English | 35.82 | 🔗 Inference Result |
| English ➡️ Korean | - | - |
Extracting relations between subject and object entity in KLUE Benchmark dataset | ✍️ Blog Post
- Finetuned RoBERTa model according to RBERT structure in pytorch.
- Applied stratified k-fold cross validation for the custom trainer.
Sentence generation with given emotion conditions | 🤗 Huggingface Demo
- Finetuned KoGPT-Trinity with conditional emotion labels.
- Maintained huggingface hosted model and live demo.
Retrieved and extracted answers from wikipedia texts for given question | ✍️ Blog Post
- Attached bidirectional LSTM layers to the backbone transformers model to extract answers.
- Divided benchmark into start token prediction accuracy and end token prediction accuracy.
Corporate joint project for mathematics problems classification task | 📄 Presentation
- Preprocessed Korean mathematics problems dataset based on EDA.
- Maintained version of preprocessing module.
Created Emotional Instagram Posts(글스타그램) dataset | 📄 Presentation
- Managed version control for the project Github Repository.
- Converted Korean texts on image file into text file using Google Cloud Vision API.
Light-weight Neural Network for Optical Braille Recognition in the wild & on the book. | 🤗 Huggingface Demo

- Classified multi label one-hot encoded labels for raised braille patterns.
- Pseudo-labeled Natural Scene Braille dataset.
- Trained single stage object detection YOLO models for braille cell recognition.
Elimination based Lightweight Neural Net with Pretrained Weights | 📄 Presentation
- Constructed lightweight CNN model with less than 1M #params by removing top layers from pretrained CNN models.
- Assessed on Trash Annotations in Context(TACO) Dataset sampled for 6 classes with 20,851 images.
- Compared metrics accross VGG11, MobileNetV3 and EfficientNetB0.
Identifying 18 classes from given images: Age Range(3 classes), Biological Sex(2 classes), Face Mask(3 classes) | ✍️ Blog Post
- Optimized combination of backbone models, losses and optimizers.
- Created additional dataset with labels(age, sex, mask) to resolve class imbalance.
- Cropped facial characteristics with MTCNN and RetinaFace to reduce noise in the image.
Real-time desk posture classification through webcam | 📷 Demo Video
- Created real-time detection window using opencv-python.
- Converted image dataset into Yaw/Pitch/Roll numerical dataset using RetinaFace model.
- Trained and optimized random forest classification model with precision rate of 93%.
Overview for student life in foreign universities |
- 3400 Visitors within a year (2021.07 ~ 2022.07)
- 22000 Pageviews within a year (2021.07 ~ 2022.07)
- 3 minutes+ of Average Retention Time


- Collected and preprocessed 11200 text review data from the Yonsei website using pandas.
- Visualized department distribution and weather information using matplotlib.
- Sentiment analysis on satisfaction level for foreign universities with pretrained BERT model.
- Clustered universities with provided curriculum with K-means clustering.
- Hosted reports on universities using Gatsby.js, GraphQL, and Netlify.
Federal Rate Prediction for the next FOMC Meeting
- Wrangled quantitative dataset with Finance Data Reader.
- Yielded metrics and compared candidate regression models for the adaquate fit.
- Hyperparameter optimization for the candidate models.
Get financial data of public companies involved in spinoff events on Google Spreadsheet | 🧩 Dataset Demo
- Wrangled finance dataset which are displayed on Google Sheets
Fixed torch version comparison fallback error for source repo of NVIDIA Research | ✍️ Pull Request
- Skills: torch, torchvision
Updated PostgreSQL initialization for "Quickstart: dockerizing django" documentation | ✍️ Pull Request
- Skills: Docker, docker-compose, Django