SyncVSR: Data-Efficient Visual Speech Recognition with End-to-End Crossmodal Audio Token Synchronization (Interspeech 2024)
Visual Speech Recognition (VSR) stands at the intersection of computer vision and speech recognition, aiming to interpret spoken content from visual cues. A prominent challenge in VSR is the presence of homophenes-visually similar lip gestures that represent different phonemes. Prior approaches have sought to distinguish fine-grained visemes by aligning visual and auditory semantics, but often fell short of full synchronization. To address this, we present SyncVSR, an end-to-end learning framework that leverages quantized audio for frame-level crossmodal supervision. By integrating a projection layer that synchronizes visual representation with acoustic data, our encoder learns to generate discrete audio tokens from a video sequence in a non-autoregressive manner. SyncVSR shows versatility across tasks, languages, and modalities at the cost of a forward pass. Our empirical evaluations show that it not only achieves state-of-the-art results but also reduces data usage by up to ninefold.
Frame-level crossmodal supervision with quantized audio tokens for enhanced Visual Speech Recognition.
| Overview of SyncVSR | Performance of SyncVSR on LRS3 |
|---|---|
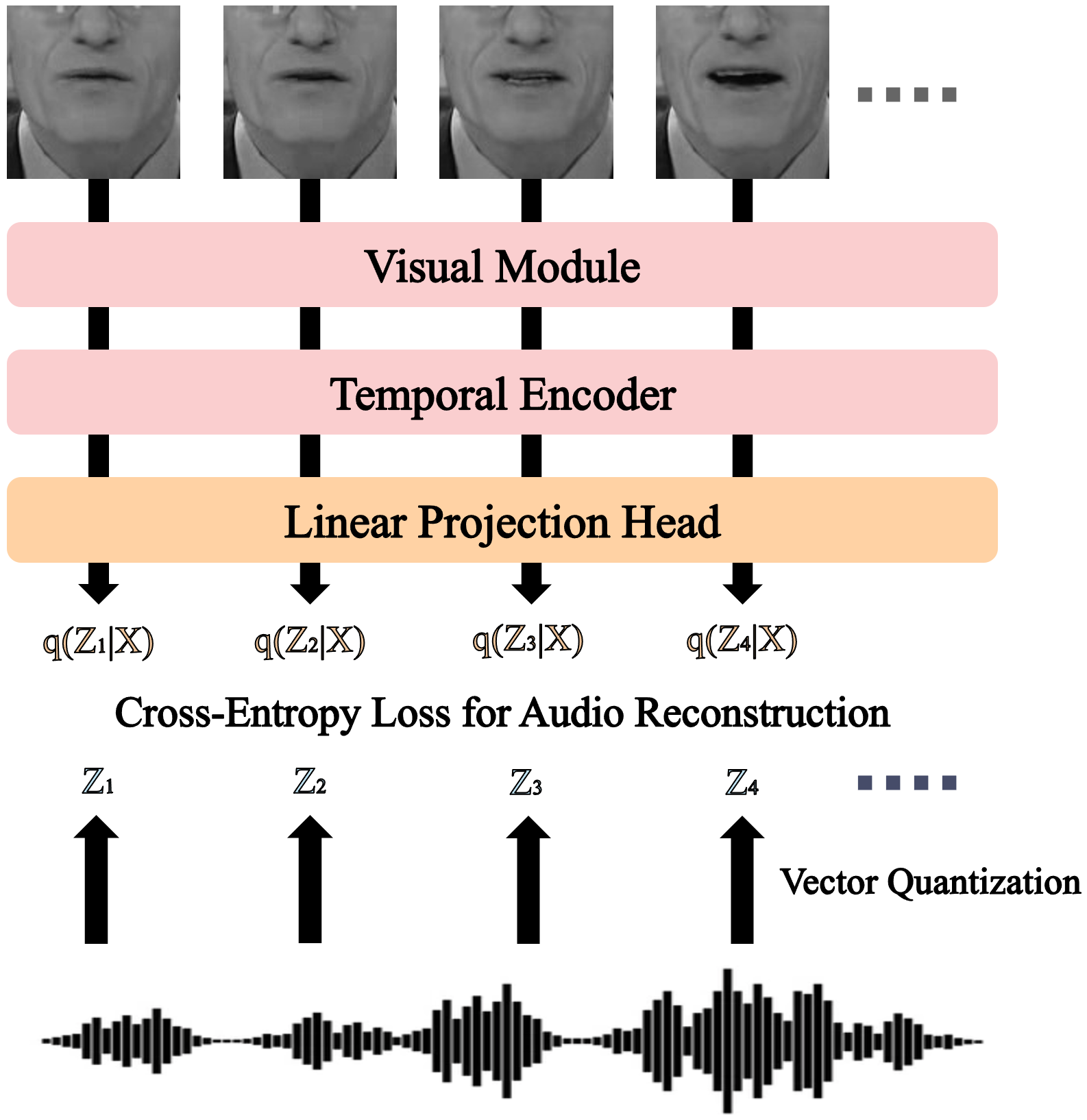 |
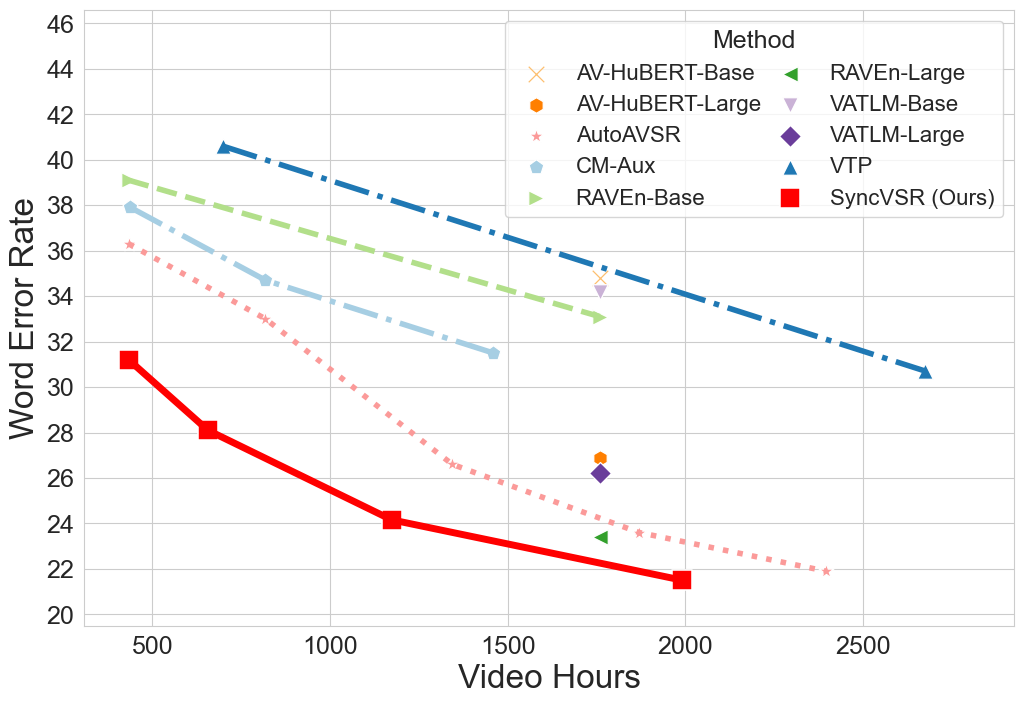 |
class Model(nn.Module):
"""
- audio_alignment: Ratio of audio tokens per video frame
- vq_groups: Number of quantized audio groups (i.e. audio channels number in the output of the codec)
- audio_vocab_size: Vocabulary size of quantized audio tokens of neural audio codec
- audio_projection: Linear projection layer for audio reconstruction
"""
def __init__(self, config):
...
self.audio_projection = nn.Linear(config.hidden_size, audio_alignment * vq_groups * audio_vocab_size)
self.lambda_audio = 10.0 # Larger the better, recommending at least 10 times larger loss coefficient of the VSR objective
def forward(self, videos, audio_tokens, ...):
# Get traditional VSR objective loss such as Word classification loss, CTC loss, and LM loss
loss_objective = ...
# Obtain the latent representation from the encoder for input video frames of length seq_len
# with a special token inserted at the start.
last_hidden_state = self.encoder(videos) # [B, seq_len+1, hidden_size]
# Get audio reconstruction loss
logits_audio = self.audio_projection(last_hidden_state[:, 1:, :]) # [B, seq_len, audio_alignment * vq_groups * audio_vocab_size]
logits_audio = logits_audio.reshape(B, seq_len, audio_alignment * vq_groups, audio_vocab_size) # [B, seq_len, audio_alignment * vq_groups, audio_vocab_size]
# For each encoded video frame, it should predict combination of (audio_alignment * vq_groups) audio tokens
loss_audio = F.cross_entropy(
logits_audio.reshape(-1, self.audio_vocab_size), # [B * seq_len * (audio_alignment * vq_groups), audio_vocab_size]
audio_tokens.flatten(), # [B * seq_len * (audio_alignment * vq_groups),]
)
# Simply add audio reconstruction loss to the objective loss. That's it!
loss_total = loss_objective + loss_audio * self.lambda_audio
...We uploaded tokenized audio for LRW, LRS2, LRS3 at the release section. Without installing the fairseq environment, you may load the tokenized audio from the files as below:
# download from the release section below
# https://github.com/KAIST-AILab/SyncVSR/releases/
# and untar the folder.
tar -xf audio-tokens.tar.gz""" access to the tokenized audio files """
import os
from glob import glob
benchname = "LRW" # or LRS2, LRS3
split = "train"
dataset_path = os.path.join("./data/audio-tokens", benchname)
audio_files = glob(os.path.join(dataset_path, "**", split, "*.pkl"))
""" load the dataset """
import random
import torch
tokenized_audio_sample = torch.load(random.choice(audio_files)) # dictionary type
tokenized_audio_sample.keys() # 'vq_tokens', 'wav2vec2_tokens'- Get authentification for Lip Reading in the Wild Dataset via https://www.bbc.co.uk/rd/projects/lip-reading-datasets
- Download dataset using the shell command below
wget --user <USERNAME> --password <PASSWORD> https://thor.robots.ox.ac.uk/~vgg/data/lip_reading/data1/lrw-v1-partaa
wget --user <USERNAME> --password <PASSWORD> https://thor.robots.ox.ac.uk/~vgg/data/lip_reading/data1/lrw-v1-partab
wget --user <USERNAME> --password <PASSWORD> https://thor.robots.ox.ac.uk/~vgg/data/lip_reading/data1/lrw-v1-partac
wget --user <USERNAME> --password <PASSWORD> https://thor.robots.ox.ac.uk/~vgg/data/lip_reading/data1/lrw-v1-partad
wget --user <USERNAME> --password <PASSWORD> https://thor.robots.ox.ac.uk/~vgg/data/lip_reading/data1/lrw-v1-partae
wget --user <USERNAME> --password <PASSWORD> https://thor.robots.ox.ac.uk/~vgg/data/lip_reading/data1/lrw-v1-partaf
wget --user <USERNAME> --password <PASSWORD> https://thor.robots.ox.ac.uk/~vgg/data/lip_reading/data1/lrw-v1-partag- Extract region of interest and convert mp4 file into pkl file with the commands below.
python ./src/preprocess_roi.py
python ./src/preprocess_pkl.pyLRS is for sentence-level lipreading and LRW is for word-level lipreading. In each of the tasks, the repository is organized into two main directories: config and src.
- The
configdirectory contains the configurations for training and inference on the benchmarks we evaluated. - The
srcdirectory holds the source code for modeling, preprocessing, data pipelining, and training.
$ tree
.
├── LRS
│ ├── landmark
│ └── video
│ ├── config
│ │ ├── lrs2.yaml
│ │ └── lrs3.yaml
│ ├── datamodule
│ │ ├── av_dataset.py
│ │ ├── data_module.py
│ │ ├── transforms.py
│ │ └── video_length.npy
│ ├── espnet
│ ├── lightning.py
│ ├── main.py
│ ├── preprocess
│ │ ├── prepare_LRS2.py
│ │ ├── prepare_LRS3.py
│ │ ├── prepare_Vox2.py
│ │ ├── transcribe_whisper.py
│ │ └── utils.py
│ ├── setup.sh
│ ├── spm
│ └── utils.py
├── LRW
│ ├── landmark
│ │ ├── README.md
│ │ ├── config
│ │ │ ├── transformer-8l-320d-1000ep-cmts10-lb0-wb.sh
│ │ │ ├── transformer-8l-320d-1000ep-cmts10-lb0.sh
│ │ │ └── ...
│ │ ├── durations.csv
│ │ ├── setup.sh
│ │ └── src
│ │ ├── dataset.py
│ │ ├── main.py
│ │ ├── modeling.py
│ │ ├── training.py
│ │ ├── transform.py
│ │ └── utils.py
│ └── video
│ ├── config
│ │ ├── bert-12l-512d_LRW_96_bf16_rrc_WB.yaml
│ │ ├── bert-12l-512d_LRW_96_bf16_rrc_noWB.yaml
│ │ └── dc-tcn-base.yaml
│ ├── durations.csv
│ ├── labels.txt
│ ├── setup.sh
│ └── src
│ ├── augment.py
│ ├── data.py
│ ├── inference.py
│ ├── lightning.py
│ ├── preprocess_pkl.py
│ ├── preprocess_roi.py
│ ├── tcn
│ └── train.py
└── README.md
For the replicating state-of-the-art results from the scratch, please follow the instructions below.
# Install depedency through apt-get
apt-get update
apt-get -yq install ffmpeg libsm6 libxext6
apt install libturbojpeg tmux -y
# Install dependencies for sentence-level VSR
git clone https://github.com/KAIST-AILab/SyncVSR.git
cd ./SyncVSR/LRS/video
bash setup.sh
# Or install dependencies for word-level VSR
cd ./SyncVSR/LRW/video
bash setup.sh
# You may also install dependencies for landmark VSR, trainable on TPU devices.
cd ./SyncVSR/LRW/landmark
bash setup.sh
# (Optional) Install fairseq to use vq-wav2vec audio quantizer.
# We recommend to use quantized audio tokens at https://github.com/KAIST-AILab/SyncVSR/releases/tag/weight-audio-v1
# Or use wav2vec 2.0's audio quantizer to avoid using fairseq.
git clone https://github.com/pytorch/fairseq
cd fairseq
pip install --editable ./
cd ..
pip install -r requirements.txt
wget https://dl.fbaipublicfiles.com/fairseq/wav2vec/vq-wav2vec_kmeans.pt -P ./Word-Level VSR
cd ./SyncVSR/LRW/video
python ./src/inference.py ./config/bert-12l-512d_LRW_96_bf16_rrc_WB.yaml devices=[0]Sentence-Level VSR
cd ./SyncVSR/LRS/video
python main.py config/lrs2.yaml # evaluating on lrs2
python main.py config/lrs3.yaml # evaluating on lrs3Word-Level VSR
After preprocessing the dataset using preprocess_roi.py and preprocess_pkl.py, please change configurations in yaml files in LRW/video/config.
python ./src/train.py ./config/bert-12l-512d_LRW_96_bf16_rrc_WB.yaml devices=[0]Sentence-Level VSR
After preprocessing the dataset using LRS/video/preprocess, please change configurations in yaml files in LRS/video/config.
cd ./SyncVSR/LRS/video
python main.py config/lrs2.yaml
python main.py config/lrs3.yamlThanks to the TPU Research Cloud program for providing resources. Models are trained on the TPU v4-64 or TPU v3-8 pod slice.
If you find SyncVSR useful for your research, please consider citing our paper:
@inproceedings{ahn2024syncvsr,
author={Young Jin Ahn and Jungwoo Park and Sangha Park and Jonghyun Choi and Kee-Eung Kim},
title={{SyncVSR: Data-Efficient Visual Speech Recognition with End-to-End Crossmodal Audio Token Synchronization}},
booktitle={Proc. Interspeech 2024},
doi={10.21437/Interspeech.2024-432}
}