-
Notifications
You must be signed in to change notification settings - Fork 540
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
This PR add row major Gram matrices. These will be used in SVM kernels to allow flexibility in the input layout (#2198). For the benchmarked cases, row major input is around 2.5% slower on average. 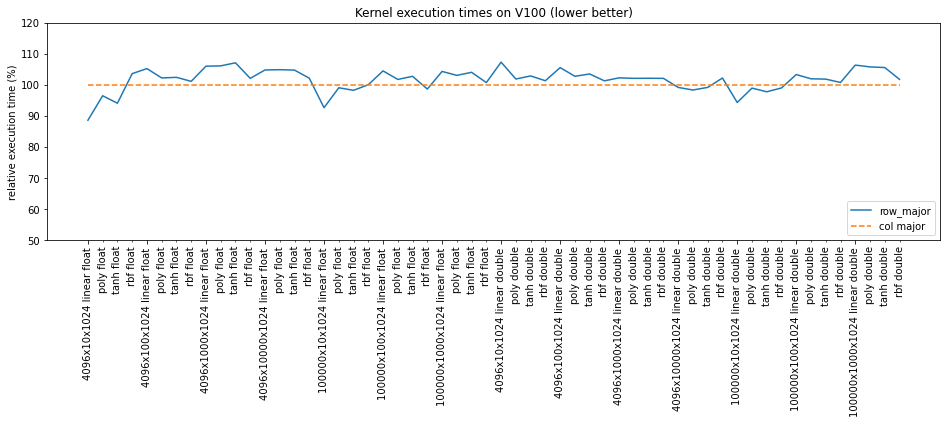 Authors: - Tamas Bela Feher (@tfeher) Approvers: - Thejaswi. N. S (@teju85) - Dante Gama Dessavre (@dantegd) URL: #3639
{kind=link}
- Loading branch information
Showing
6 changed files
with
298 additions
and
238 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.