Memory Structure
The memory structure is the format in which the information will be stored at the sotware level. It's the efficient memory structure on which the software will work. It's designed to store only the URLs and the links between those. No content is stored here since it's delegated to the [raw data level](Raw data level) which isn't described here [about data levels](Software architecture). Plus the URLs and links, the memory structure has to sore the abstraction layer created by the users as [Web entities](Web entities)
This structure has to be optimal to :
- allow a constant read cost
- allow a small insertion cost
- allow the definition and manipulation of web entities without having to re-crawl
- allow insertion and delation at low cost
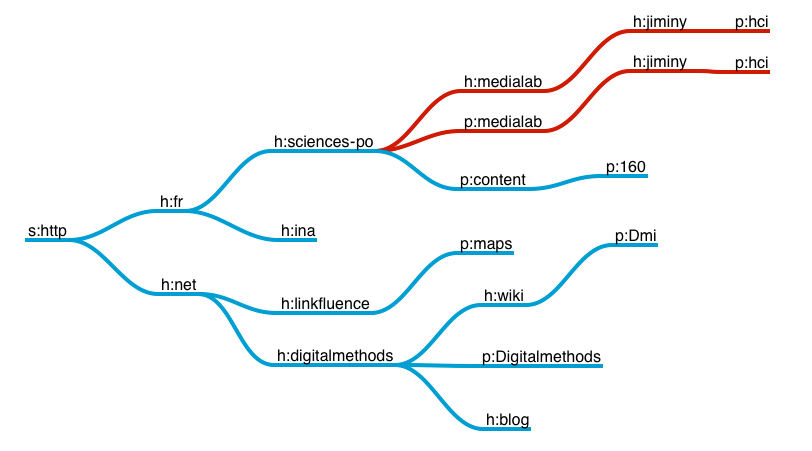
The memory structure has to store the many URLs, the crawler went through and the core transformed as [Reverse URLs](Reverse URLs). Those LRUs would form a tree as the included schema illustrates it.
Thus [web entities](web entities) will be set as pointers to node of the tree. As we want web entity to deal with aliases, web entities are list of pointers ot nodes of the tree. Web entities will also have a status (included, excluded, not_seen, not_decided) and some metadata.
To allow good performances we decided to restrict the storage of links to a certain [Precision limit](Precision limit). The memory strucutre will only store the links at this level of precision. The full information about links is stored on the above level of data storage called [raw data level](Raw data level).
There are two kinds of metadata to described the web entities :
- mandatory metadata built-in the system and automatically updated by the system (uid, version dates...)
- users metadata specified by an ad-hoc [web entity codebook](Web entity codebook) but stored in teh web entity index.
The [WebEntity Links update process](WebEntity Links update process) allows to have performance when retrieving links between web entities as well as having performance when inserting new links between Nodes. Its purpose is somehow to put the links in cache. We do not want :
- To update the cache each time there is a change in the WebEntity (a Node insertion, with its links)
- To update each time the core asks for data (no cache)
Our solution is to index in time the Node Links in WebEntity Links.
We chose to code the memory structure by using Lucene http://lucene.apache.org indexation engine from the apache software fondation.
That being said, a comparison was done whether it's a good idea to use Neo4j, a graph database, to model more closely the tree structure in this diagram :
See the [Lucene Neo4j Comparison](Lucene Neo4j Comparison) page to learn more about the findings.
The implementation is a Java application. Its server functionality is exposed to clients over a Thrift protocol. See the [technical specification](Memory structure tech spec) about how this software works and how to build and run it.
- a page is a web page which has been seen by the crawler at least as an outgoing link
- field lru String: the LRU of that page
- field full_precision boolean: indicates if a [FULL PRECISION](Precision limit#FULL_PRECISION_exception) flag has been set on this page by the user note that this field is stored by the memory structure but will only be used by the core since it's the core which does the web entities creation and link agregations.
- field is_node boolean : indicates wether this page is above or bellow the [Precision limit](Precision limit)
- field id : String : uniq identifier
- field name String : a trivial name from user
- field LRU_prefixeS String[] : list of [LRU prefixes](LRU prefixes) which are the aliases including in that web entity
- field metadata DICT HashTable ? : the metadata about the web entity. Ideally JSON formated or a vector type. See [Web entity codebook](Web entity codebook).
- those objects are regular expression on LRU_prefix which stands that LRU to be inserted as Page in Lucene should trigger a web entity creation see [Web entities](Web entities)
- field lru_prefix String : filter to detect LRU candidates to that rule through indexing
- field lru_regexp String : teh regular expression which return the LRU_prefix to use as a new web entity if the LRU matches
- field comments String : users' explanation
- field lruSource String : Lru from which the link has been found
- field lruTarget String : Lru targeted by the link
- field weight int : weight of the link i.e. the numbers of parallel links found
- those links are a agregation of the PageLinks depending on the webentity grouping feature. They will only be updated on demand from the core but not at each PageLinks modification for performance reasons
- field webEntitySource String : identifier of the webentity source
- field webentityTarget String : identifier of the webentity target
- field Weight int : weight of the link i.e. the numbers of parallel links found
See the dedicated page : [Memory structure interface](Memory structure interface)