Core
The Core is the coordinator of the other modules.
It'll make the bridge between UI, [Memory Structure](Memory structure) and the Crawler.
It's an important piece which can be seen as the corpus maintainer as descibred in previous project versions.
The main task of the core will be to manage the URLS coming out crawl tasks. The objective is to prepare them to be included into the [Memory Structure](Memory structure).
-
Objects specifications :
-
PAGE :
- lru
- is_node (boolean)
- node (a lru)
- page_item metadata
-
PAGE_LINK object :
- source_lru
- target_lru
-
LRU tree object :
- def add_lru(lru)
- def get_children(lru)
-
-
Algorithm :
- get page_items from crawler result queue
- create PAGE objects and insert lru in LRU_tree object from lru_links
- create the links objects
- for page in page_list :
- if len(page)> PRECISION_LIMIT :
- page.is_node=false
- p=Page(shorten(page,PRECISION_LIMIT),is_node=True)
- lru_tree.add(p)
- page.node=p
- else :
- page.is_node=True
- if len(page)> PRECISION_LIMIT :
- send the PAGe list to Memory Structure : store_and_retrieve_flags(LRU_list_with_node_flags)
- get flags as a result (list of FLAG+LRU_PREFIXE+REGEXP) FLAG in "precision_limit_exception", "webentity_creation_rule", "nowebentity"
- for lru_prefix in precision_limit_flags.order_by_length(DESC) :
- children = lru_tree.get_chlidren(lru_prefix)
- for child in children :
- child.node=lru_prefix
- for page in pages if page.is_node=false :
- for source in link.getsourcefrom_target(page) :
- links.add(source,page.node) # increment weight id already existing
- for target in link.gettargetfrom_source(page) :
- links.add(page.node,target)
- for source in link.getsourcefrom_target(page) :
- for (flag,we_lru_prefix,we_regexp) in we_flags.order_by_length(DESC) :
- if flag == creation:
- we_candidates= lru_tree.get_children(we_lru_prefixe)
- for candidate in we_candidates :
- webentities.append(regexp(candidate))
- elif flag==NoFlag :
- webentities.append(shorten(lru_prefix,defaultwebentitylevel))
- create_webentities(webentities)
- get page_items from crawler result queue
The core will manage the communicaiton with user interfaces. This will be done through an API. The specification can be found here : [User interface API](User interface API)
It's not sure yet if this will be an actual interface or more likely organised through the scrapy framework. In this perspective what we call here CORE is a composition of scrapy's engine, pipelines, scheduler. The crawler is then a composition of scrapy's downloader and spiders.
- core to crawler : the core has a scheduler role in the sense that it will manage the crawl processes. Crawls are started on request from the UI through the Web Service.
- crawler to core : gives content and extracted links for a given URL to crawl
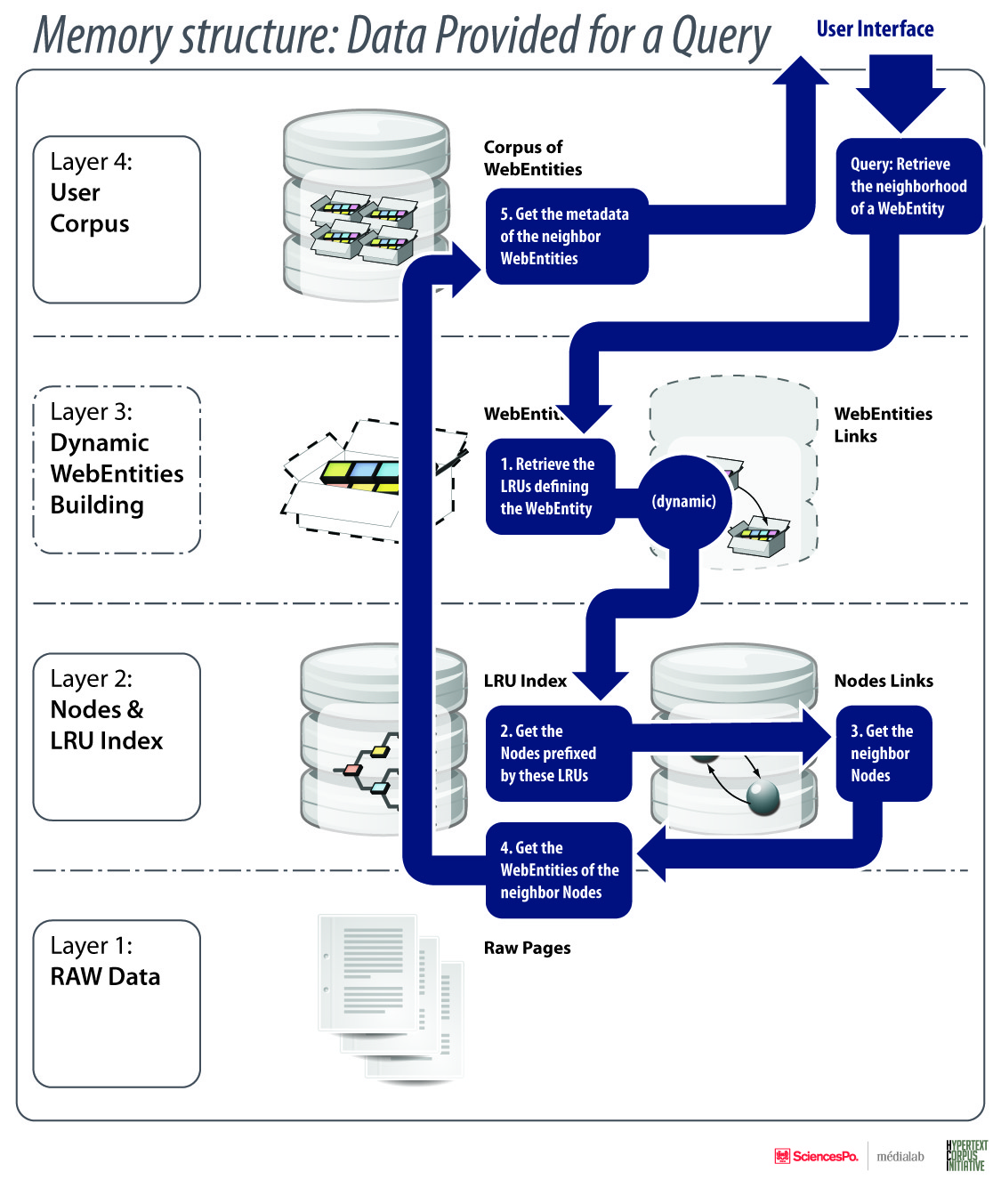
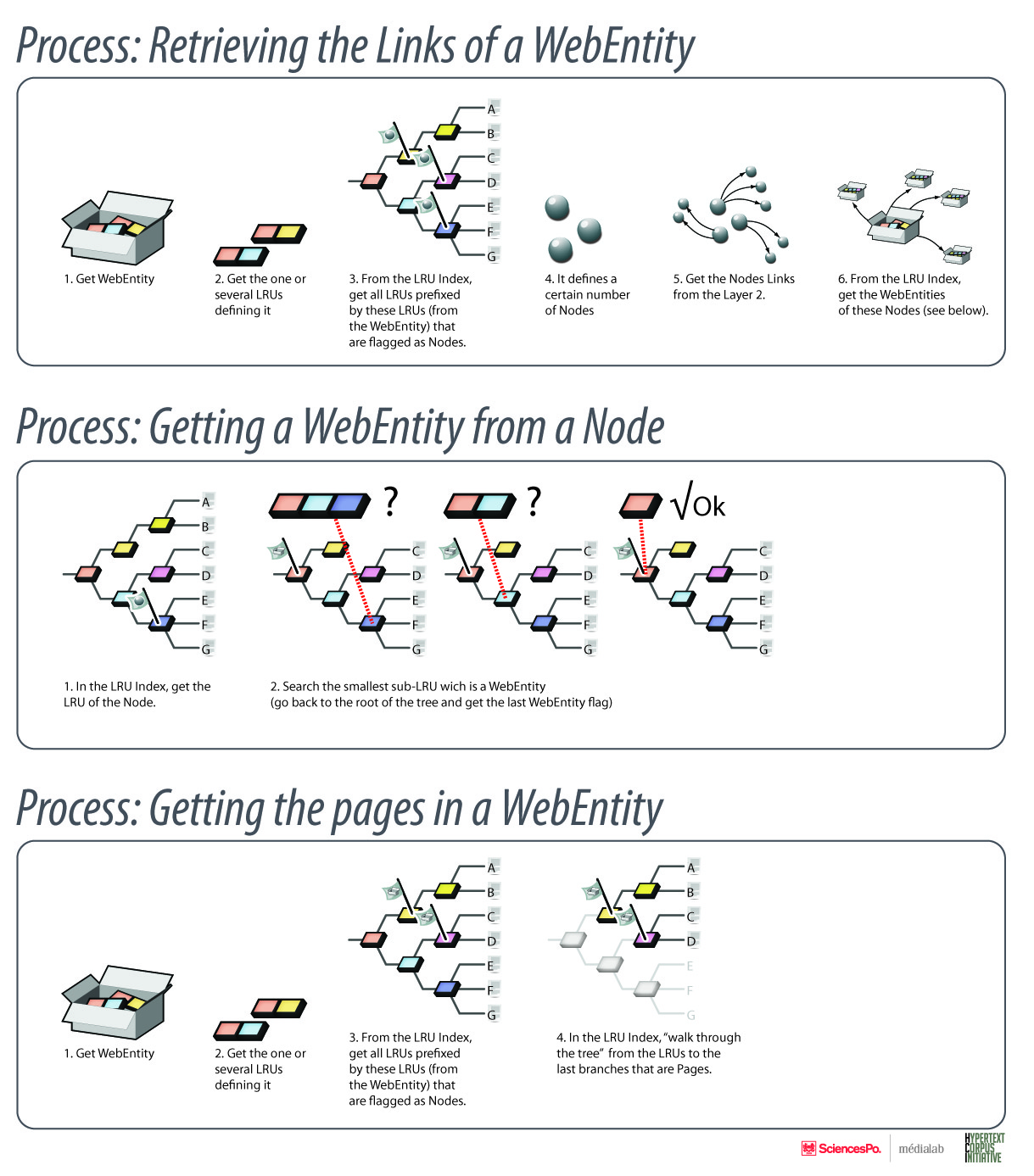
The core will use the memory structure as the memory backend.
All the data the system needs to read/write efficently to run will be stored in the memory structure.
The spefications of the interface between the core and the memory structure is described here : [Memory Structure Interface](Memory Structure Interface)
The core has the responsability to maintain the corpus integrity.
It will contain a set of maintenance algorythm which will assure the integrity of the many different data levels.
Those data manipulation must be loged in the memory structure
- is the core multi corpus ?
Can a core manage several corpora or should we launch a core by corpus ?
- how to chose the starting points to crawl a web entity ?
- ** option 1 : all the pages included in the web entity **
- ** option 2 : all pages pointed by external links (entry points to the web entity) **
- ** option 3 : a specific page choose by th e user as home page ? **
Qualification
Remove a web entity
The first prototype has been drafted using Python and more precisely the Twisted framework.
The protocol used for communication between UI and Core is JSON RPC.
Twisted has been used for prototyping the webservice by creating a JSON RPC server delivering python class methods.
For the prototype we also develop a naive crawler to test the so-called research driven crawling. Here again Twisted is a good framework by offering asynchroneous web client.
In the first version the memory structure has not been used. All data are stored in memory and not persistant if server stops.
The prototype code can be found here
The next prototype will use scrapy as a framework. Although scrapy looks like the perfect framework to host our project, we still have a list of questions/difficulties to answer before implementing it :
- implement a webservice for the UI as described above using Scrapy web service Ressource
- with webservice should be able to do the spider manager work by dynamically creating/configuring/monitoring a spider for each crawl task
- the basic item is a Page with 3 fields : url, content, extracted_links
- implement a crawler as a CrawlerSpider
- implement a PagePipeline to treate page information and send them to the next pipeline : memory structure
- how to interface properly and efficently the core and memory structure : Thrift or pylucene ?
- implement a Memory Structure Pipeline respecting the [interface specification](Memory Structure interface). While developping the Thrift connection to the Java Lucene Memory structure it would be nice to develop an other one using MongoDB pipeline