Joint Inference Walkthrough
Joint inference uses the Cyclades algorithm, which is an algorithm for parallel stochastic optimization. Cyclades maintains serializability by avoiding conflicting read and writes by different cores to shared model parameters. So optimizing with 8 threads produces the same result as optimizing with 1 thread. Serializability is important as conflicting read and writes by different cores may lead to non-convergence or poorer results.
Batch - A group of stochastic updates assigned to a single core. Each core is assigned the same number of batches.
Cyclades ensures that updates in the i'th batch assigned to a core will not conflict with updates in the i'th batch assigned to a different core. This means all cores can perform updates in their i'th batch in parallel without worrying about conflicts. However, this also means that a core can not move on to the i+1'th batch until all other cores finish their i'th batch, since updates are not guaranteed to be nonconflicting across batches.
Cyclades is a partitioning algorithm that creates a schedule of non-conflicting stochastic updates to be executed by multiple cores.
Cyclades works on sparse stochastic optimization methods where updates only access/modify a subset of the model variables.
-
Step 1 - Create a conflict graph G from updates to model parameters
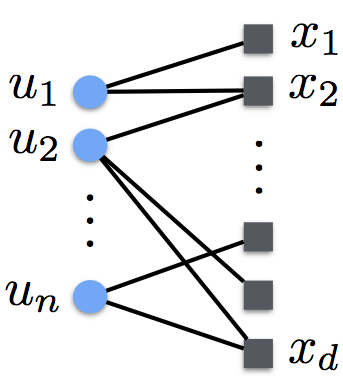
- Construct a bipartite graph where an edge exists from update u to model parameter x if update u reads/modifies parameter x. This creates a bipartite graph as depicted in the image above.
-
Step 1.5 - Assign current batch index b = 0
-
Step 2 - Randomly sample a set of updates from graph G and compute connected components on this set of updates. Remove this set of updates from the total set.
- Computing connected components on this set of updates tells us which updates conflict with each other. Specifically, updates in the same component access the same model parameters so they must be executed by a single core. Updates in different components access a disjoint set of model parameters, so they can be executed in parallel without worrying about conflicts.
-
Step 3 - Distribute the set of updates (output from step 2) to different cores
- Assign all updates in a particular connected component to be executed by a single core for batch b. The current core to assign is chosen as to minimize load imbalance. Repeat until there are no more components from the output of step 2.
-
Step 4 - Increment b by 1. Repeat from step 2 if there are still updates to assign
At the end of this process, we have a schedule telling each core which updates to execute in a particular batch.
Celeste optimization uses Newton updates, which take much larger steps compared to other stochastic optimization methods like SGD. This means that conflicting read/writes to model parameters by different cores have a larger impact on convergence. Using Cyclades solves this issue.
In Celeste, light source (e.g: galaxy or star) parameters are stochastically optimized so as to minimize a loss function. In this sense, a model parameter x_i is the parameters of a single light source. Stochastic updates to the parameters of a light source require reading the parameters of neighboring light sources, where two light sources are neighbors if they are within some distance of each other. Thus, the conflict graph generated in step 1 is equivalent to the "neighborship" graph of light sources.
Since a core needs to wait for all other cores to finish batch i before processing batch i+1, thread barriers are placed after the processing of a batch.
We run parallel stochastic updates over all light sources according to the Cyclades schedule a fixed number of times (currently set at around 3 or 4).
Shuffling of updates is often done to improve optimization. Although Cyclades specifies a schedule to perform the updates, the schedule is loose and to a degree can be rearranged. Specifically in Celeste, we randomly shuffle the updates within a particular batch. If further shuffling is needed, processing batches in a different order (E.G: cores 1..n all process batches in some random order) would also work.