rpc: retain information about failed connections #99191
Conversation
|
This change is |
27b5b32 to
26cd800
Compare
ae2f39c to
33f44f7
Compare
20f6390 to
3fa5742
Compare
330f311 to
6301cc4
Compare
6301cc4 to
6a0ef1c
Compare
6a0ef1c to
a13af72
Compare
a13af72 to
41d8862
Compare
103582: server: call VerifyClockOffset directly r=aliher1911 a=tbg Extracted from #99191. ---- There was this weird setup where we were hiding it in a callback. Let's just call it directly. This was masking that fatalling on the result is actually turned off except when starting a `Server` (i.e. outside of pure unit tests). Now there's an explicit variable on the options to opt into the fatal error. Now we also call it only when we want to: we didn't actually want to call it when dealing with blocking requests. It didn't hurt either since the blocking requests didn't change the state of the tracker, but still - now we're only checking when something has changed which is better. Epic: None Release note: None Co-authored-by: Tobias Grieger <[email protected]>
103387: grpcutil: improve gRPC logging r=knz a=tbg Extracted from #99191, where I ran a bunch of experiments to make sure the logging around connection failures is clean and helpful. I did manual testing on the changes in this PR. It's tricky to test vmodule-depth-thingies programmatically and I don't want to spend time building new infra here. - cli: don't lower gRPC severity threshold - grpcutil: adopt DepthLoggerV2 - sidetransport: suppress logging when peer down Release note: None Epic: CRDB-21710 103492: kv: add assertion to prevent lock re-acquisition at prior epochs r=nvanbenschoten a=arulajmani Lock re-acquisitions from requests that belong to prior epochs is not allowed. For replicated locks, mvccPutInternal rejects such requests with an error. However, for unreplicated locks where the in-memory lock table is the source of truth, no such check happens. This patch adds one. The comment on `lockHolderInfo.txn` field suggests this was always the intended behavior; it was just never enforced. While here, we also add an assertion to ensure a replicated lock acquisition never calls into the lock table with a transaction belonging to a prior epoch. We expect this case to be handled in mvccPutInternal, so unlike the unreplicated case, this deserves to be an assertion failure. This patch also updates a test that unintentionally re-acquired a lock using a txn from an older epoch. We also add a new test. Informs: #102269 Release note: None 103533: allocator2: fix normalization for the no constraint case r=kvoli a=sumeerbhola Informs #103320 Epic: CRDB-25222 Release note: None 103579: server: add comment pointing out TestGraphite slowness r=aliher1911 a=tbg Epic: none Release note: None 103581: server,rpc,circuit: assortment of small cleanups/improvements r=knz a=tbg Extracted from #99191. - server: fix a (harmless) test buglet - rpc: small comment tweak - rpc: fix incorrect comment - circuit: provide type for the anonymous Signal interface - rpc: rename a package - rpc: minor Goland lint appeasement - rpc: avoid shadowing `backoff` package - rpc: make some unused args anonymous - rpc: make it clear that TestStoreMetrics restarts stores Release note: None Epic: None Co-authored-by: Tobias Grieger <[email protected]> Co-authored-by: Arul Ajmani <[email protected]> Co-authored-by: sumeerbhola <[email protected]>
41d8862 to
cddee5c
Compare
103829: rpc: simplify VerifyDialback via circuit breakers r=erikgrinaker a=tbg Now that we have #99191, we can simplify `VerifyDialback`. Storing connection attempts is no longer necessary since the circuit breakers keep track of the health of the remote. Epic: none Release note: none Co-authored-by: Tobias Grieger <[email protected]>
103837: ui: Network latency page improvements r=koorosh a=koorosh - use connectivity endpoint as a source of connection statuses and latency; - removed popup with disconnected peers, instead it will be shown on latency matrix; Resolves: #96101 Release note (ui change): add "Show dead nodes" option to show/hide dead/decommissioned nodes from latency matrix. Release note (ui change): "No connections" popup menu is removed. Now failed connections are displayed on the latencies matrix. - [x] test coverage (storybook added for visual validation) This PR depends on following PRs that should be merged before this one: - #95429 - #99191 #### example 1. one node cannot establish connection to another one. 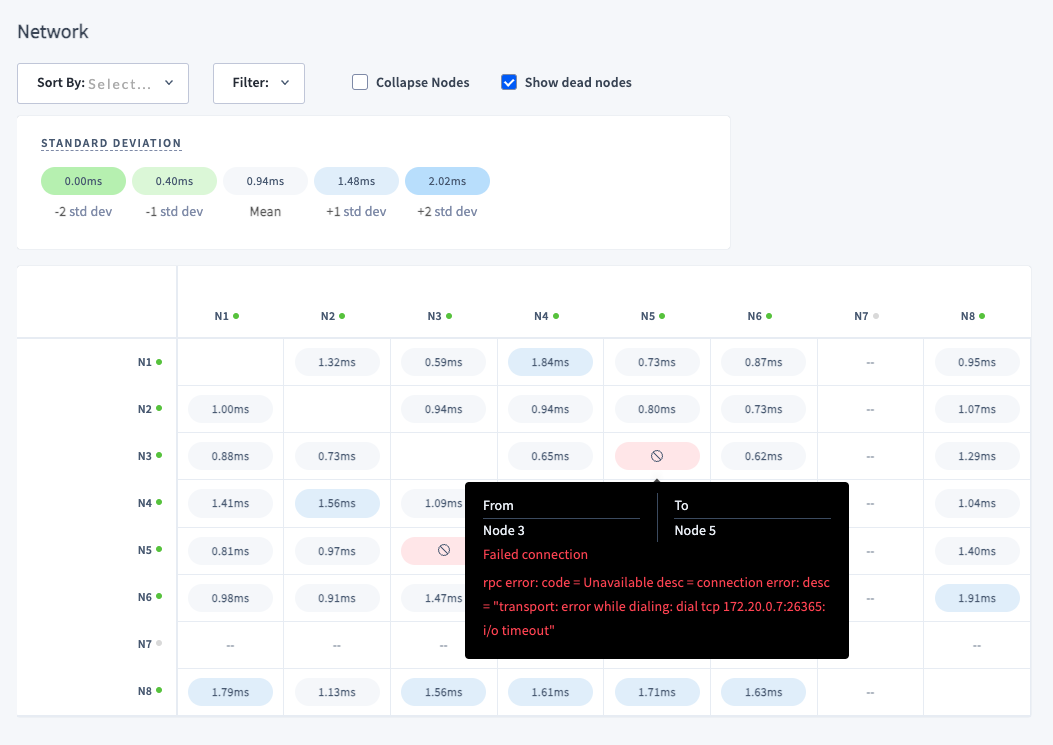 #### example 2. Node 5 is stopped and it is considered as `unavailable` before setting as `dead`  #### example 3. Node 3 is dead. No connection from/to node. Show error message. <img width="954" alt="Screenshot 2023-06-23 at 14 07 25" src="https://github.com/cockroachdb/cockroach/assets/3106437/8078c421-aeaa-4038-adf5-e3c69ba6d863"> #### example 4. Decommissioned node.  106082: sql: add REPLICATION roleoption for replication mode r=rafiss a=otan These commits add the REPLICATION roleoption (as per PG), and then uses it to authenticate whether a user can use the replication protocol. Informs #105130 ---- # sql: add REPLICATION roleoption Matches PostgreSQL implementation of the REPLICATION roleoption. Release note (sql change): Added the REPLICATION role option for a user, which allows a user to use the streaming replication protocol. # sql: only allow REPLICATION users to login with replication mode In PG, the REPLICATION roleoption is required to use streaming replication mode. Enforce the same constraint. Release note: None Co-authored-by: Andrii Vorobiov <[email protected]> Co-authored-by: Oliver Tan <[email protected]>
It was previously possible to make a new peer while the old one was in the middle of being deleted, which caused a crash due to to acquiring child metrics when they still existed. Luckily, this is easy enough to fix: just remove some premature optimization where I had tried to be too clever. Fixes cockroachdb#105335. Epic: CRDB-21710 Release note: None (bug was never shipped in a release; it's new as of cockroachdb#99191).
|
Folks, any chance of backporting this flag to 22.2? thanks |
|
No, this is a major change. We won't be able to backport it. |
|
@tbg , the cluster setting Thanks cc @florence-crl |
The setting However, prior to 23.2, this setting does not expose additional RPC metrics. In 23.2, it will also expose per-peer connection metrics as described in the release notes in this PR. This does not happen in 23.1, and can not since the necessary changes are too invasive. The 23.1 reference you see here was for a minor bugfix that was extracted out of this PR, see #105626. It is not related to the functionality you're interested in. |
|
Thanks for the clear answer @erikgrinaker. |
110892: *: remove use of cockroachdb/circuitbreaker package r=erikgrinaker a=erikgrinaker This package is no longer used. RPC circuit breakers use pkg/util/circuit instead. Resolves #105890. Touches #99191. Epic: none Release note: None Co-authored-by: Erik Grinaker <[email protected]>
Prior to this change,
rpc.Contextdid not remember a connection after itfailed. A connection attempt would be created whenever we didn't have a
functioning connection to the given
(nodeID, targetAddress, class)andcallers would be multiplexed onto it as long as that attempt was not known to
have failed.
The main problem with this setup was that it makes it difficult to provide good
observability because a remote node that just hasn't been dialed yet and one
that is down but between attempts looks the same. We could write code that
periodically tries to fully connect all nodes in the cluster to each other, but
even then exporting good metrics is challenging and while we're currently
comfortable with a densely connected cluster, that may change over time.
An additional challenge was presented by circuit breaking and logging of
attempts. Without state retained, we were limited to a simple retry scheme with
lots of redundant logging. It wasn't easy to log how long a connection had been
unhealthy (as an unhealthy connection was represented as an absent connection),
so in effect folks had to trawl through logs to grab the corresponding
timestamps of first and last failure.
Another piece of complexity were the RPC circuit breakers. These were
implemented at the NodeDialer-level (i.e. one circuit breaker per
(NodeID,Class)) but kept in therpc.Context(which generally operates on(NodeID, Addr, Class)because gossip also used them. The library they wereusing uses recruitment of client traffic, which also isn't ideal as it could
periodically subject a SQL query to a timeout failure. We'd really prefer it
if the breakers probed without user traffic recruitment.
This PR addresses the above shortcomings:
(NodeID, Addr, Class)basis inthe `rpc.Context. This has a few complications, for example we need to handle
decommissioned nodes, as well as nodes that restart under a new listening
address.
util/circuitpackage already used for Replica-level circuit breaking. Thislibrary uses an async background probe to determine when to heal the breaker.
I also think the amount of incidental complexity in the
rpcpackage is greatlyreduced as a result of this work.
I ran the
failover/non-system/suite of tests to validate this change. The resultslook good1.
Epic: CRDB-21710
Release note (ui change): a "Networking" metrics dashboard was added.
Release note (ops change): CockroachDB now exposes the following metrics:
rpc.connection.{un,}healthy: Gauge of healthy/unhealthy connections,rpc.connection.{un,}healthy_nanos: Gauge of aggregate duration the currently {un,}healthy connections have been {,un}healthy for,grpc.connection.avg_round_trip_latency: sum of weighted moving averages of round-trip latencies for all peers (it really only makes sense to consume these on a per-peer basis via prometheus)rpc.connection.heartbeatsandrpc.connection.failures.When the
server.child_metrics.enabledcluster setting is set, these metrics export per-peer values, meaning they can be used to derive a connectivity graph.Release note (ops change): logging for intra-node RPC connection failures has improved by reducing frequently and improving information content.
Footnotes
https://gist.github.com/tbg/5f5c716fa2fe5a21eca4a0c3a4a35069 ↩