sql/schemachanger: generalize statement-time execution #88294
Comments
|
Andrew and I discussed this offline. Presently what we do is this:
The approach to the solution I propose is as follows:
This way, the concept of "statement phase" effectively disappears and only There is a missing piece to this puzzle: currently we only have this concept of uncommitted schema changes for descriptors, we'd need to extend that to the rest of the schema; so: namespace, comment, zone entries. We wanted to do that anyway so that's fine. |
|
The clear next step is to properly abstract these descriptor-associated concepts into the catalog to allow for in-memory side-effects to be observed. |
|
One case that @ecwall brought up that's interesting is the case of I think this alone motivates use of synthetic descriptors during statement evaluation. More generally, I think there are a number of cases where the view we want DMLs in the current transaction to have a different view of descriptors than what we'll want to write for concurrent transactions to see. |
|
That makes sense. I guess we agree that we want an in-memory txn-local view of descriptors; you're saying let's use the synthetic layer in the collection, I'm saying let's use the uncommitted layer. My reasoning is that it'll be easier to implement, but it doesn't really matter which layer we use as long as the collection does what we want. |
|
So, from what I'm understanding that, with the generic statement-time execution, we when statement (1) is first plan, we need to allocate a descriptor id for the function, then we clear the uncommitted layer before planning statement (2). To make the new UDF visible to statement (2), we need to replan statement (1). So here, if we don't cache the function id somewhere, we'd allocate a new id for the function, which is fine since we never flush the new function descriptor to kv, and statement (2) can just use the second allocated function id. The only thing is that it could be fun when debugging because the ID of newly created objects changes over later statements. For rollback, I think it's also fine because we'd have the descriptor id in job payload. |
This doesn't align with what I envision. The idea is that we'll never redo the build stage; we retain the targets from the previous statements. Let me do out an explicit example. Consider: CREATE TABLE foo (i INT PRIMARY KEY, j INT, INDEX(j));BEGIN;
ALTER TABLE foo DROP COLUMN j CASCADE; -- 1
SELECT * FROM foo; -- don't want to see j
ALTER TABLE foo ADD COLUMN k INT;
COMMIT;The idea is that in step 1, we'll first parse and build targets. In this case, we're going to have column j targetting absent and we're also going to get rid of the index etc. Today, during statement phase, we transition that column to Today, during statement execution, we will literally write the descriptor with the column j in Now, the idea is that with this proposal, we'll still move that column to When the second statement comes along, it'll get built and we'll have new targets (note that the builder sees the targets from the previous statements). Then, we'll plan with the targets from the union of the two statements and execute that synthetically. This will mean again transitioning the column to The key insight here is that this lets us, at commit time, act as though there was only a single DDL statement when we decide what side-effects we actually want to publish. Hope this helps. Happy to go through more details. |
|
I see, that make sense, thanks a lot. Holding targets of earlier statements is great. |
|
The example above helped a lot, Thanks Andrew! So it seems that what we want to do is:
Now it makes sense to why Andrew said "as if there were only a single ddl statement", because we plan from all the targets built from all ddl statements received so far on a fresh desc.Collection synthetically. I also sort of understand now why Marius said "statement phase disappears", because upon receiving each ddl statement, we perform all the mutation stages as if this is the last DDL statement we will ever receive and we will do all the mutation work so we can peacefully wait for the COMMIT to arrive, so we can schedule and let the schema changer job take over. |
This isn't quite the right language. We want to keep the cached state of what was read -- we just want to clear the synthetic state that was accumulated as side-effects of execution. |
Previously, in the declarative schema changer, each mutation stage would be executed by visiting each of the stage's mutation ops to collect the mutation state, followed by applying the mutations eagerly. This commit defers the running of kv.Batch containing the catalog mutations to the pre-commit phase. This change doesn't functionally change anything but paves the way for undoing all pending catalog mutations and re-planning the schema changes at pre-commit time. Informs cockroachdb#88294. Release note: None
95461: ui: remove reset sql stats for non-admin r=maryliag a=maryliag Continuation from #95303 The previous PR missed the reset on the Transactions tab. This PR removes the reset sql stats for non-admin users. Fixes #95213 Release note (ui change): Remove `reset sql stats` from Transactions page for non-admins. 95466: ingesting: fixup privileges granted during database restore r=rafiss a=adityamaru Previously, all schemas and tables that were ingested as part of a database restore would "inherit" the privileges of the database. The database would be granted `CONNECT` for the `public` role and `ALL` to `admin` and `root`, and so all ingested schemas would have `ALL` for `admin` and `root`. Since 21.2 we have moved away from tables/schemas inheriting privileges from the parent database and so this logic is stale and partly incorrect. It is incorrect because the restored `public` schema does not have `CREATE` and `USAGE` granted to the `public` role. These privileges are always granted to `public` schemas of a database and so there is a discrepancy in restore's behaviour. This change simplifies the logic to grant schemas and tables their default set of privileges if ingested via a database restore. It leaves the logic for cluster and table restores unchanged. Release note (bug fix): fixes a bug where a database restore would not grant `CREATE` and `USAGE` on the public schema to the public role Fixes: #95456 95467: schemachanger: a bunch of small fixes r=postamar a=postamar Informs #88294. Release note: None 95504: schemachangerccl: rename generated tests r=postamar a=postamar This commit adds an underscore in the generated tests' name where there previously was one missing. Informs #88294. Release note: None 95512: kvserver: fix flaky TestLearnerReplicateQueueRace test r=tbg a=aliher1911 Test was not expecting raft snapshots and injected failure at wrong moments. Fixes #94993 Release note: None Co-authored-by: maryliag <[email protected]> Co-authored-by: adityamaru <[email protected]> Co-authored-by: Marius Posta <[email protected]> Co-authored-by: Oleg Afanasyev <[email protected]>
This change makes it possible to plan and execute the following change
correctly:
BEGIN;
DROP TABLE foo;
CREATE UNIQUE INDEX idx ON bar (x);
COMMIT;
Inside the transaction, the table is seen as dropped right after the
DROP TABLE statement executes, but the table is not seen as dropped by
other transactions until the new, unrelated index has been validated, at
which point the schema change can no longer fail.
Fixes cockroachdb#88294.
Significant changes:
- descs.Collection has a new ResetUncommitted method.
- scstage.BuildStages is rewritten with unrolled loops and a new scheme:
statement phase has revertible op-edges, pre-commit has two stages,
one which resets the uncommitted state by scheduling the new
scop.UndoAllInTxnImmediateMutationOpSideEffects op, which triggers a call
to ResetUncommitted.
- This happens in scexec.executeMutationOps, which is now split into two
pieces, the first one which executes ops whose side-effects can be undone
by ResetUncommitted, and the other which handles those which can’t.
- These ops implement scop.ImmediateMutationOp and scop.DeferredMutationOp
respectively.
- These have their own visitors with their own state and their own
dependencies.
This all means that we can handle DROPs properly now: the TXN_DROPPED element
state is removed as are all the synthetic descriptor manipulations (outside of
index and constraint validation, that is). Furthermore, the
scgraph.PreviousTransactionPrecedence edge kind no longer serves any purpose
and has been replaced by PreviousStagePrecedence everywhere.
There’s a bunch of other more-or-less related changes, mostly as a consequence
to the above:
- nstree.MutableCatalog has new methods for deleting comments and zone configs
which are useful.
- scbuild.Build does better target filtering to remove no-op targets, which
used to be harmless but which now cause problems.
- sctestdeps.TestState has better storage layers modelling
(in-memory > stored > committed)
- the embedded scpb.Expression in constraint-related ops is replaced with
catpb.Expression.
- The fromHasPublicStatusIfFromIsTableAndToIsRowLevelTTL clause is removed from
the rules.
- Added missing “relation dropped before column|index no longer public” rules
which fix DROP COLUMN CASCADE when the column is referenced in a view.
- scgraph.Graph has a new GetOpEdgeTo method which is useful.
- added debug info to assertion error messages in scstage.BuildStages to make
debugging easier during development.
- EXPLAIN (DDL) output has a nicer root node label which puts the last statement first.
Release note: None
95091: security: add option to re-enable old cipher suites r=catj-cockroach a=catj-cockroach In #82362 we updated the list of cipher suites to match the "recommended" cipher suites defined in RFC 8447. As noted in that PR, very old clients may fail to connect. For systems using those very old clients, this PR adds a setting that can be used to re-enable the "old" cipher suites removed in that PR. Release note (security update): adds option to re-enable "old" cipher suites for use with very old clients. 95243: storage: disallow nil settings in StorageConfig r=RaduBerinde a=RaduBerinde Tolerating nil settings is tedious and error-prone. We don't want these settings to be unset in production paths. This change makes it non-optional. Release note: None 95548: cluster-ui: use absolute path in node selector import r=xinhaoz a=xinhaoz Previously, the import path for accumulateMetrics in `nodes.selector.ts` was using a relative path. This for some reason broke the session details page on CC for 23.1. Epic: none Release note: None https://www.loom.com/share/d315f2a605254701b91fc189213b0e41 95689: schemachanger: small fixes and tweaks r=postamar a=postamar These commits consist of straightforward changes to the declarative schema changer which were spun off from work on #88294 but which are required for it. Informs #88294. Release note: None 95694: batcheval: modify MVCCStats CleanRange assertion under race r=adityamaru a=adityamaru Previously, if ClearRange took a fast path and was being tested under race, then we would assert that the computed MVCCStats were the same as those of the fast path. This would not be true if the MVCCStats contained estimates which they do in operation such as cluster to cluster replication. This change tweaks the assertion to only run if the MVCCStats do not contain estimates since if they do there is no guarantee they will match up with the computed MVCCStats. Fixes: #95656 Fixes: #95677 Release note: None Co-authored-by: Cat J <[email protected]> Co-authored-by: Radu Berinde <[email protected]> Co-authored-by: Xin Hao Zhang <[email protected]> Co-authored-by: Marius Posta <[email protected]> Co-authored-by: adityamaru <[email protected]>
This change makes it possible to plan and execute the following change
correctly:
BEGIN;
DROP TABLE foo;
CREATE UNIQUE INDEX idx ON bar (x);
COMMIT;
Inside the transaction, the table is seen as dropped right after the
DROP TABLE statement executes, but the table is not seen as dropped by
other transactions until the new, unrelated index has been validated, at
which point the schema change can no longer fail.
Fixes cockroachdb#88294.
Significant changes:
- descs.Collection has a new ResetUncommitted method.
- scstage.BuildStages is rewritten with unrolled loops and a new scheme:
statement phase has revertible op-edges, pre-commit has two stages,
one which resets the uncommitted state by scheduling the new
scop.UndoAllInTxnImmediateMutationOpSideEffects op, which triggers a call
to ResetUncommitted.
- This happens in scexec.executeMutationOps, which is now split into two
pieces, the first one which executes ops whose side-effects can be undone
by ResetUncommitted, and the other which handles those which can’t.
- These ops implement scop.ImmediateMutationOp and scop.DeferredMutationOp
respectively.
- These have their own visitors with their own state and their own
dependencies.
This all means that we can handle DROPs properly now: the TXN_DROPPED element
state is removed as are all the synthetic descriptor manipulations (outside of
index and constraint validation, that is). Furthermore, the
scgraph.PreviousTransactionPrecedence edge kind no longer serves any purpose
and has been replaced by PreviousStagePrecedence everywhere.
There’s a bunch of other more-or-less related changes, mostly as a consequence
to the above:
- scbuild.Build must produce a tighter target set: no-op targets are
elided.
- nstree.MutableCatalog has new methods for deleting comments and zone configs
which are useful.
- sctestdeps.TestState has better storage layers modelling
(in-memory > stored > committed)
- Added missing “relation dropped before column|index no longer public” rules
which fix DROP COLUMN CASCADE when the column is referenced in a view.
- scgraph.Graph has a new GetOpEdgeTo method which is useful.
- added debug info to assertion error messages in scstage.BuildStages to make
debugging easier during development.
- EXPLAIN (DDL) output has a nicer root node label which puts the last
statement first.
Release note: None
This change makes it possible to plan and execute the following change
correctly:
BEGIN;
DROP TABLE foo;
CREATE UNIQUE INDEX idx ON bar (x);
COMMIT;
Inside the transaction, the table is seen as dropped right after the
DROP TABLE statement executes, but the table is not seen as dropped by
other transactions until the new, unrelated index has been validated, at
which point the schema change can no longer fail.
Fixes cockroachdb#88294.
Significant changes:
- descs.Collection has a new ResetUncommitted method.
- scstage.BuildStages is rewritten with unrolled loops and a new scheme:
statement phase has revertible op-edges, pre-commit has two stages,
one which resets the uncommitted state by scheduling the new
scop.UndoAllInTxnImmediateMutationOpSideEffects op, which triggers a call
to ResetUncommitted.
- This happens in scexec.executeMutationOps, which is now split into two
pieces, the first one which executes ops whose side-effects can be undone
by ResetUncommitted, and the other which handles those which can’t.
- These ops implement scop.ImmediateMutationOp and scop.DeferredMutationOp
respectively.
- These have their own visitors with their own state and their own
dependencies.
This all means that we can handle DROPs properly now: the TXN_DROPPED
element state is removed as are all the synthetic descriptor manipulations
(outside of index and constraint validation, that is). Furthermore, the
scgraph.PreviousTransactionPrecedence edge kind no longer serves any
purpose and has been replaced by PreviousStagePrecedence everywhere.
There’s a bunch of other more-or-less related changes, mostly as a
consequence to the above:
- scbuild.Build must produce a tighter target set: no-op targets are
elided.
- nstree.MutableCatalog has new methods for deleting comments and zone
configs which are useful.
- sctestdeps.TestState has better storage layers modelling
(in-memory > stored > committed)
- Added missing “relation dropped before column|index no longer public”
rules which fix DROP COLUMN CASCADE when the column is referenced in
a view.
- scgraph.Graph has a new GetOpEdgeTo method which is useful.
- added debug info to assertion error messages in scstage.BuildStages to
make debugging easier during development.
- EXPLAIN (DDL) output has a nicer root node label which puts the last
statement first.
Release note: None
95631: schemachanger: generalized statement-time execution r=postamar a=postamar
This change makes it possible to plan and execute the following change
correctly:
BEGIN;
DROP TABLE foo;
CREATE UNIQUE INDEX idx ON bar (x);
COMMIT;
Inside the transaction, the table is seen as dropped right after the
DROP TABLE statement executes, but the table is not seen as dropped by
other transactions until the new, unrelated index has been validated, at
which point the schema change can no longer fail.
Fixes #88294.
Significant changes:
- descs.Collection has a new ResetUncommitted method.
- scstage.BuildStages is rewritten with unrolled loops and a new scheme:
statement phase has revertible op-edges, pre-commit has two stages,
one which resets the uncommitted state by scheduling the new
scop.UndoAllInTxnImmediateMutationOpSideEffects op, which triggers a call
to ResetUncommitted.
- This happens in scexec.executeMutationOps, which is now split into two
pieces, the first one which executes ops whose side-effects can be undone
by ResetUncommitted, and the other which handles those which can’t.
- These ops implement scop.ImmediateMutationOp and scop.DeferredMutationOp
respectively.
- These have their own visitors with their own state and their own
dependencies.
This all means that we can handle DROPs properly now: the TXN_DROPPED element
state is removed as are all the synthetic descriptor manipulations (outside of
index and constraint validation, that is). Furthermore, the
scgraph.PreviousTransactionPrecedence edge kind no longer serves any purpose
and has been replaced by PreviousStagePrecedence everywhere.
There’s a bunch of other more-or-less related changes, mostly as a consequence
to the above:
- scbuild.Build must produce a tighter target set: no-op targets are
elided.
- nstree.MutableCatalog has new methods for deleting comments and zone configs
which are useful.
- sctestdeps.TestState has better storage layers modelling
(in-memory > stored > committed)
- Added missing “relation dropped before column|index no longer public” rules
which fix DROP COLUMN CASCADE when the column is referenced in a view.
- scgraph.Graph has a new GetOpEdgeTo method which is useful.
- added debug info to assertion error messages in scstage.BuildStages to make
debugging easier during development.
- EXPLAIN (DDL) output has a nicer root node label which puts the last
statement first.
Release note: None
95636: sql: increase the online help for SHOW RANGES r=ecwall a=knz
The output of `\h SHOW RANGES` wasn't mentioning the KEYS option. Now it does. Also this adds some additional details about the various options.
Release note: None
Epic: None
95691: sql: improve tenant records r=stevendanna,dt,ajwerner a=knz
supersedes #95574, #95581, #95655
Epic: CRDB-21836
**TLDR** This commit contains the following changes:
- rename "state" to "data_state", "active" to "ready"
- stored, non-virtual columns for "name", "data_state", "service_mode"
- deprecate the column "active" since it mirrors "data_state'
- move `descpb.TenantInfo` to new package `mtinfopb`.
- new statements `ALTER TENANT ... START SERVICE EXTERNAL/SHARED`,
`STOP SERVICE` to change the service mode.
Details follow.
**rename TenantInfo.State to DataState, "ACTIVE" to "READY"**
We've discovered that we'd like to separate the readiness of the data
from the activation of the service. To emphasize this, this commit
renames the field "State" to "DataState".
Additionally, the state "ACTIVE" was confusing as it suggests that
something is running, whereas it merely marks the tenant data as ready
for use. So this commit also renames that state accordingly.
**new tenant info field ServiceMode**
Summary of changes:
- the new TenantInfo.ServiceMode field indicates how to run servers.
- new syntax: `ALTER TENANT ... START SERVICE EXTERNAL/SHARED`,
`ALTER TENANT ... STOP SERVICE`.
- tenants created via `create_tenant(<id>)`
(via CC serverless control plane) start in service mode EXTERNAL.
- other tenants start in service mode NONE.
- need ALTER TENANT STOP SERVICE before dropping a tenant.
- except in the case of `crdb_internal.destroy_tenant`
for compat with CC serverless control plane.
**make the output columns of SHOW TENANT lowercase**
All the SHOW statements report status-like data in lowercase.
SHOW TENANT(s) should not be different.
**use actual SQL columns for the TenantInfo fields**
Release note: None
Co-authored-by: Marius Posta <[email protected]>
Co-authored-by: Raphael 'kena' Poss <[email protected]>
This commit endows the scpb.CurrentState with the set of element statuses which are in force at the beginning of the statement transaction. These are then used when planning the pre-commit reset stage. This commit also rewrites the target-setting logic in the scbuild package in a more explicit manner with extra commentary. This commit does not change any functional behavior in production. Informs cockroachdb#88294. Release note: None
This commit endows the scpb.CurrentState with the set of element statuses which are in force at the beginning of the statement transaction. These are then used when planning the pre-commit reset stage. This commit also rewrites the target-setting logic in the scbuild package in a more explicit manner with extra commentary. This commit does not change any functional behavior in production. Informs cockroachdb#88294. Release note: None
This commit endows the scpb.CurrentState with the set of element statuses which are in force at the beginning of the statement transaction. These are then used when planning the pre-commit reset stage. This commit also rewrites the target-setting logic in the scbuild package in a more explicit manner with extra commentary. This commit does not change any functional behavior in production. Informs cockroachdb#88294. Release note: None
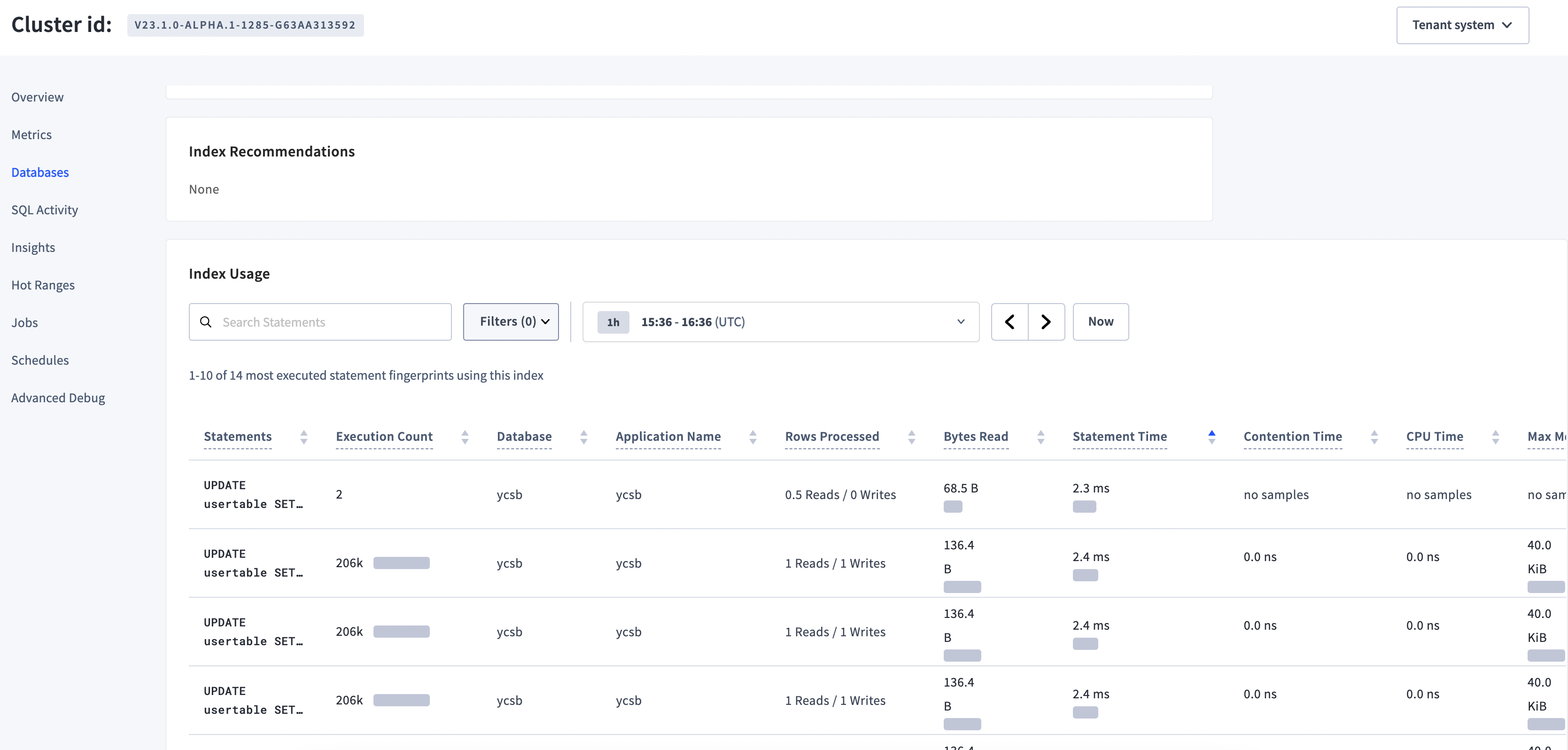
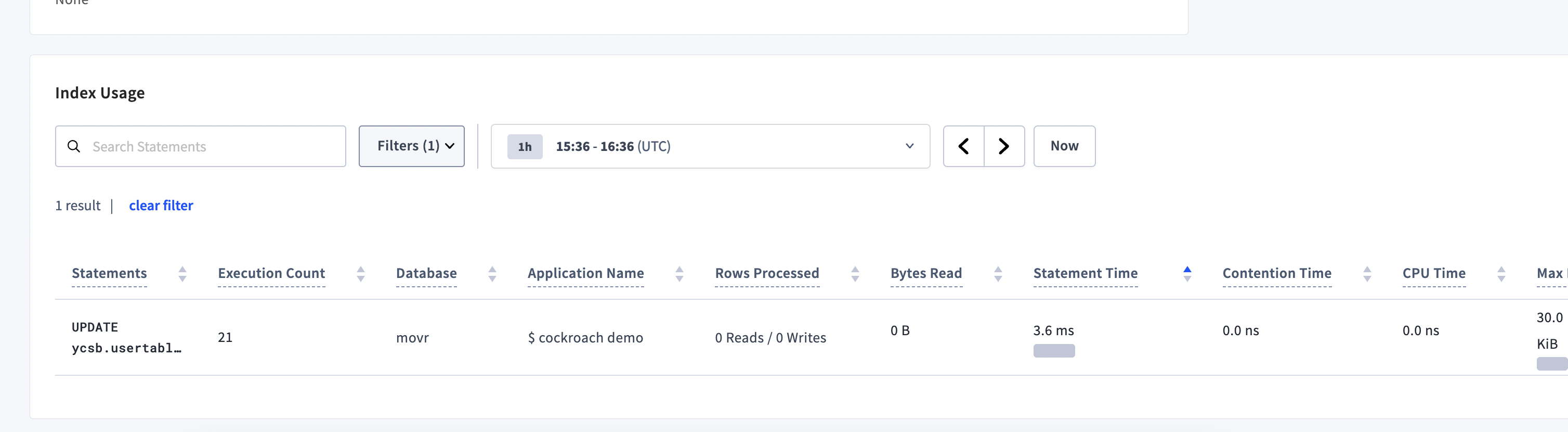
96112: ui: add search, filter and time picker on index details r=maryliag a=maryliag Fixes #93087 This commit adds search, filters and time picker for the list of fingerprints most used per index, on the Index Details page. It also limits to 20 fingerprints until we can make improvements to use pagination on our calls with sql-over-http. With no filters <img width="1669" alt="Screen Shot 2023-01-27 at 1 37 35 PM" src="https://user-images.githubusercontent.com/1017486/215167830-bd119e13-a875-49bd-9c8d-305230dd4b01.png"> With filters <img width="1508" alt="Screen Shot 2023-01-27 at 1 37 49 PM" src="https://user-images.githubusercontent.com/1017486/215167846-c668d79a-7a59-420e-b96c-2eff6a50aca6.png"> https://www.loom.com/share/d4129452593a40198902a5f2539d8568 Release note (ui change): Add search, filter and time picker for the list of most used statement fingerprints on the Index Details page. 96117: schemachanger: improve state management r=postamar a=postamar This commit endows the scpb.CurrentState with the set of element statuses which are in force at the beginning of the statement transaction. These are then used when planning the pre-commit reset stage. This commit also rewrites the target-setting logic in the scbuild package in a more explicit manner with extra commentary. This commit does not change any functional behavior in production. Informs #88294. Release note: None 96232: sql: move copy_in_test to pkg/sql/copy to have all copy tests together r=cucaroach a=cucaroach Epic: CRDB-18892 Informs: #91831 Release note: None 96272: backupccl,changefeedccl: properly display name if resource exists r=msbutler,HonoreDB a=renatolabs Previously, we were passing a `*string` to a string formatting function (`pgnotice.Newf`) with the `%q` verb. This leads to messages being displayed to the user that look like: ``` NOTICE: schedule %!q(*string=0xc006b324e0) already exists, skipping ``` This properly dereferences the pointer before printing. Epic: none Release note: None Co-authored-by: maryliag <[email protected]> Co-authored-by: Marius Posta <[email protected]> Co-authored-by: Tommy Reilly <[email protected]> Co-authored-by: Renato Costa <[email protected]>
{kind=link}
{kind=link}
Is your feature request related to a problem? Please describe.
In the declarative schema changer, we want to update the state of the world as observed by subsequent statements in the current transaction. Some of the logical side-effects we would like to make visible to the current transaction immediately, but would be dangerous or wrong to publish to concurrent transactions eagerly.
We have logic like this in a limited form today. When dropping descriptors, we drop them "synthetically". This
TXN_DROPPEDstate will store the descriptors in theDROPstate in the descriptor collection's synthetic set. This means that queries and virtual tables will observe the descriptor as being dropped, but the descriptor will not have been written to the key-value store as being dropped. Instead, we can defer the choice of whether or not to write the dropped descriptor untilPreCommitPhase, when we know whether any part of the schema change might fail.Consider the case of dropping a default expression followed by adding a constraint. Subsequent statements in the transaction, ideally, would no longer observe the old default expression. However, if the constraint addition subsequently (asynchronously) fails, no concurrent transactions should have observed the dropping of the default value.
Describe the solution you'd like
Rather than explicitly modeling the synthetic application of a state change as we did in
TXN_DROPPED, what we ought to do is to synthetically apply side-effects duringStatementPhasesuch that all mutations applied during statement phase affect only synthetic descriptors. This way, the synthetic state of the schema change diverges from the true state. At each schema change statement, we plan as though no operations have yet occurred to the descriptors, and we re-apply side-effects to create a new set of synthetic descriptors. This way, by the time we go to perform real side-effects on the descriptors, we have full knowledge of all of the operations in the schema change.Epic: CRDB-19158
Jira issue: CRDB-19763
The text was updated successfully, but these errors were encountered: