Align processing block - CUDA implementation #2670
Merged
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Closed
|
Need to fix tabs all over |
dorodnic
approved these changes
Nov 12, 2018
|
My TX1 at 640x480 went from 7FPS to 19FPS with this - was previously unusable and now works great! Thanks! |
|
@matkatz When I update lib from 2.13 to 2.17, align processing performance is great. but,memory occupied increase(0.1M) each time the thread read one frame. could you give me a help,thank you! |
This was referenced Mar 6, 2022
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
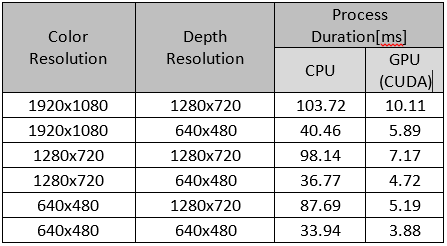
This PR improves the performance of the align processing block when building librealsense with CUDA (#2257).
Also the align processing block was split to 3 different implementations (CPU, SSE, CUDA).
The following table demonstrates the performance improvements as it was measured over NVIDIA Jetson TX2 where power saving mode is turned off ( via jetson_clocks.sh):