University of Pennsylvania, CIS 565: GPU Programming and Architecture, Project 3
- Xiaomao Ding
- Tested on: Windows 8.1, i7-4700MQ @ 2.40GHz 8.00GB, GT 750M 2047MB (Personal Computer)


The code in this repository implements a CUDA-based Monte Carlo path tracer allowing us to quickly render globally illuminated images. The path tracer sends out many rays into the scene to "sample" the colors of the objects in the scene. Upon hitting an object, another ray is generated at that location. This allows the path tracer to accumulate color of light bouncing off of nearby surfaces as well. Because each new ray generated is sampled from a probability distribution described by the object's material, it takes many iterations of the algorithm before a uniform "non-noisy" image emerges.
The following features have been implemented in this project:
- Direct illumination with Multiple Importance Sampling
- Depth of field via camera jittering
- Stochastic Sample Anti-aliasing
- Realistic reflective and refractive materials via Fresnel dielectrics and conductors
- Path termination via stream compaction
- First bounce caching
Features are enabled/disable via defines at the top of interactions.h and pathtrace.cu. MIS and Fresnel effects are toggled at the top of interactions.h. All other features are located at the top of pathtrace.cu.
- Esc to save an image and exit.
- S to save an image. Watch the console for the output filename.
- Space to re-center the camera at the original scene lookAt point
- left mouse button to rotate the camera
- right mouse button on the vertical axis to zoom in/out
- middle mouse button to move the LOOKAT point in the scene's X/Z plane
The idea of direct illumination is to directly sample the light at each bounce by shooting and evaluating an additional ray. This in theory allows us to converge to a stable image much quicker than waiting for the rays to randomly hit light. In this project, the base global illumination renderer multiplicatively stacks the color of each surface hit. However, in the direct illumination renderer, I use a more realistic implementation of the light transport equation, found in the Physically Based Rendering Textbook [PBRT]. Thus, the images generated by the two algorithms will look different. For this section, it is more important to just compare how "grainy" the images are. Below are three sets of images, rendered with 10, 100, and 500 iterations, using the base renderer as well as the direct illumination renderer.
| Base Renderer | Direct Illumination |
|---|---|
 |
 |
 |
 |
 |
 |
It is clear that the direct illumination renderer gives a much nicer image at the same number of iterations. However, the increased renderering quality comes with a performance tradeoff. With the direct renderer, we shoot a ray to the light at each bounce, requiring an additional intersection test. The above image in particular was also rendered with multiple importance sampling, which shoots another ray from the intersection. This totals to 2 additional rays for each bounce. The plot below shows how much slower the direct illumination renderer is. All values in this plot as well as additional plots later on are averaged over 10 iterations of the renderer.
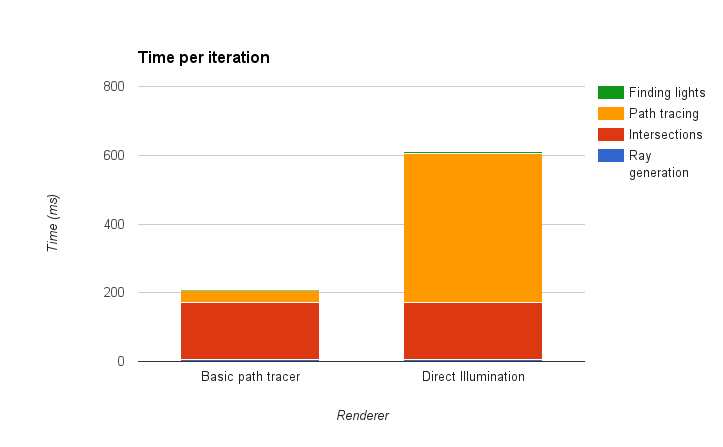
Shockingly, the time taken for the actual path tracing is now over 10 times greater than the basic renderer! Overall, this the direct illumination renderer takes about 3 times longer per iteration, so we could have run the basic renderer for that many more iterations giving the same time. Below, I ran the basic renderer for 1500 iterations, compared to a 500 iteration image from the direct illumination renderer. Even with 1000 extra iterations, the direct illumination renderer looks a bit better.
| Base Renderer 1500 iterations | Direct Illumination 500 iterations |
|---|---|
 |
|
The direct illumination's runtime is fairly undesireable. Luckily, several of the other features in this project allow us drastically reduce the runtime. The first feature is path termination. The idea is to remove paths that have terminated (hit a light source or finished all their bounces) each time before we execute the path tracing kernel. In theory, this reduces the number of threads that need to be executed as the rays are evaluated. We usethrust::partition to perform stream compaction on the rays that have terminated. Here is a plot of the number of rays remaining, as well as the executition time of a single kernel call against the bounce number.



Because we are sampling for many iterations, we can also cache the rays first cast from the camera. This is because the camera will always be in the same position when we render. This saves us time by removing the need to cast the initial set of rays on each iteration. This naturally saves time as a function of the number of iterations we are running. Below is a plot of the time saved by caching the first rays for 10 iterations of the algorithm.

We save roughly 3 milliseconds per iteration when we cache the first bounces. For a 5000 iteration rendering, this amounts to roughly 15000 milliseconds save or about 43 (15000/350) additional iterations. This seems like a fairly insignificant boost in performance, especially because caching the first ray cast will prevent us from performing anti-aliasing.
If we only cast our initial ray from a single location, aliasing can occur. This is when there may be multiple objects in a single pixel but only one gets sampled. The result is that lines and boundaries in the image may appear jagged. To address this issue, we jitter our intial ray cast slightly within the pixel. This stochastic jittering let's us sample every object that may be in a pixel since our initial ray is no longer fixed. As just mentioned in the previous section, the we can no longer cache our first bounce. One possible solution would be to cache a large amount of initial casts. However, if we do so, we always have a higher risk of aliasing! Personally, I think the first bounce caching doesn't provide enough of a benefit to make pre-allocating a large amount of space to store so many more rays worthwhile. Below are two images, one anti-aliased, one not. Notice how the edges of the box and the border of the spheres are jagged in the non-aliased version.
| No Anti-alias | With Anti-alias |
|---|---|
 |
|
Because anti-aliasing is something that occurs at the start of each iteration, it is essentially free! (minus 2 random number generations). Unless we were caching our initial bounces, there are no performance tradeoffs for this feature.
Depth of field refers to the blurring affect on objects not within the same plane of focus. We can mimic the effect of depth of field by slightly jittering our inital ray cast through an imaginary lens. The image below shows the result. Notice how the objects become less blurry the further away the are from the camera. This occurs if our focus is far away.

Similar to anti-aliasing, there are no performance costs for this feature because it is a ray pre-processing step.
We make use of two Fresnel equations to implement reflective and refractive materials. Note that the Fresnel implementations are only available in the direct illumination renderer. The basic renderer just assumes perfectly specular surfaces and uses Snell's law to calculate refracted rays. For reflections, we assume the material to be a Fresnel conductor. For refractions, we assume a Fresnel dielecctric. The formula for the two materials are as follows:


We use an approximation of the two equations [PBRT 8.2-8.3] in our implementations. Additionally, the Fresnel equations are relatively cheap. The runtime assuming a perfect specular material is only 3.5 milliseconds faster per iteration. This means that the Fresnel materials are essentially free!
For diffuse materials, the brdf is Lambertian. This means that rays sampled off the bounce come from a uniform distribution over a hemisphere. Cosine sampling is a way to get a uniform distribution over a hemishpere. However, this requires several cosine/sine calls which are very costly on the GPU, since they depend on a limited number of special computation units. Malley's method is a way to approximate a cosine distribution. The great thing about this approximation is that it requires NO cosine or sines. Instead, we only need two random number generations. This means that using this method avoids the bottleneck on the GPU! Below is a plot showing how Malley's method can improve performance. One thing to note is that the time for intersections has decreased slightly as well. This is possible because the approximation is less accurate and sends more stray rays, but I am not certain what the root cause is.

For some reason, taking out MIS from the code cuts the path tracing kernel runtime nearly in half! I have no idea why this happens. This is surprising because commenting out that section of the MIS code does not remove half the calculations (at least not in code). It is true though that 1 of the intersections is no longer used when MIS is disabled, so perhaps the compiler has also removed the intersection test call?
With MIS.
Without MIS.
[PBRT] Physically Based Rendering, Second Edition: From Theory To Implementation. Pharr, Matt and Humphreys, Greg. 2010.