hadoop安全
hadoop是一个复杂的分布式系统,hadoop安全性面对的挑战:
- 在Hadoop中,文件系统被分区和分发,需要在多个点进行授权检查。
- 在某节点提交的作业,稍后将在其他节点上执行。
- 辅助服务,如工作流系统,代表用户访问Hadoop(用户模拟)。
- Hadoop集群可扩展到数千台服务器和数万个并发任务。
Hortonworks采用基于五个核心安全特性的整体方法:
- 管理(Administration)
- 认证和周边安全
- 授权
- 审计
- 数据保护
不能通过使用各种各样的点解决方案来实现Hadoop堆栈的全面保护。安全性必须是构建Data Lake的平台的组成部分。这种自下而上的方法使得可以通过中央管理点来实施和管理整个堆栈的安全性,从而防止差距和不一致。
HDP包括功能强大的数据安全功能,可在组件技术上工作,并与现有的EDW,RDBMS和MPP系统集成。
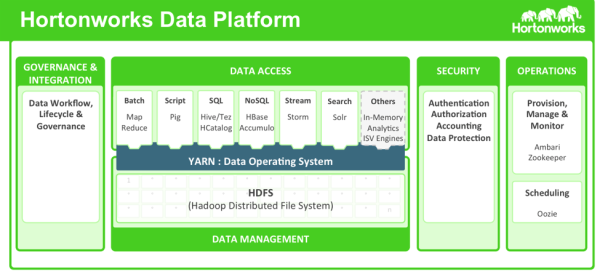
HDP使用Apache Ranger提供集中的安全管理和管理。Ranger管理门户是安全管理的中心接口。您可以使用Ranger创建和更新策略,然后存储在策略数据库中。Ranger插件(轻量级Java程序)嵌入在每个集群组件的进程中。
这些插件从中央服务器提取策略,并将其存储在文件中。当用户请求通过该组件时,这些插件拦截请求并根据安全策略进行评估。插件还可以从用户请求中收集数据,并按照单独的线程将此数据发送回审计服务器。
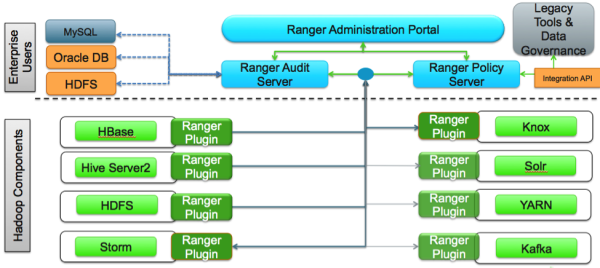
为了提供一致的安全管理和管理,Hadoop管理员需要一个集中的用户界面,可用于在所有Hadoop堆栈组件中一致地定义,管理和管理安全策略:
Ranger集中安全管理
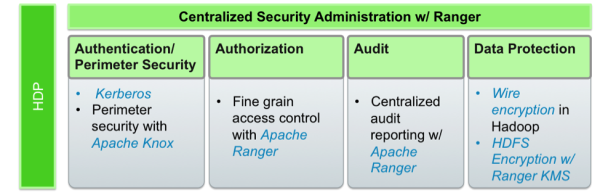
Apache Ranger管理控制台为Hadoop安全的其他四个支柱提供了一个中心管理点。
游侠管理控制台
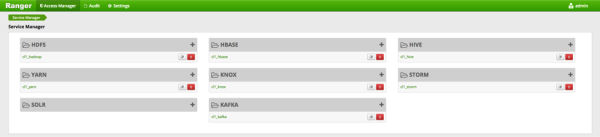
通过强大的认证建立用户身份是Hadoop中安全访问的基础。用户需要可靠地识别自己,然后在整个Hadoop集群中传播身份才能访问集群资源。Hortonworks使用Kerberos进行身份验证。Kerberos是用于对Hadoop集群中的用户和资源进行身份验证的行业标准。HDP还包括Ambari,它简化了Kerberos设置,配置和维护。
Apache Knox Gateway用于帮助确保Hortonworks客户的周边安全。使用Knox,企业可以自信地将Hadoop REST API扩展到没有Kerberos复杂性的新用户,同时还保持企业安全策略的合规性。Knox为Hadoop REST API提供了一个中心网关,这些API具有不同程度的授权,身份验证,SSL和SSO功能,可以为Hadoop提供单个接入点。
Apache Knox功能

Ranger通过用户界面管理访问控制,确保跨Hadoop数据访问组件统一的策略管理。安全管理员可以在数据库,表,列和文件级别定义安全策略,并可以管理特定的基于LDAP的组或单个用户的权限。基于动态条件(如时间或地理位置)的规则也可以添加到现有策略规则中。Ranger授权模式是可插拔的,可以使用基于服务的定义轻松地扩展到任何数据源。
管理员可以使用Ranger为以下Hadoop组件定义集中式安全策略:
- HDFS
- YARN
- Hive
- HBase
- Storm
- Knox
- Solr
- Kafka
Ranger在每个Hadoop组件中使用标准授权API,并且可以对用于访问数据湖的任何方法执行集中管理的策略。
游侠安全政策定义
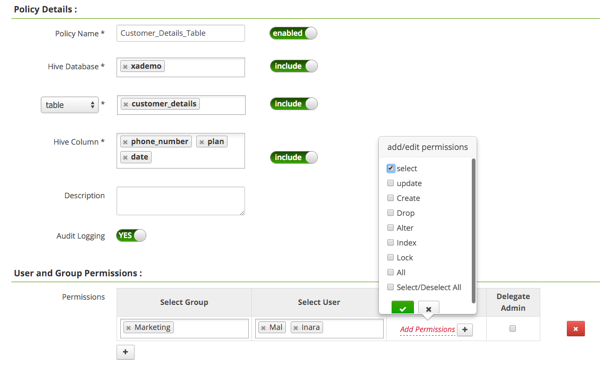
Ranger为管理员提供了对审计所需的安全管理过程的深入了解。丰富的用户界面和深度审计可见性的组合使得Ranger可以高度直观地使用,从而提高安全管理员的生产力。
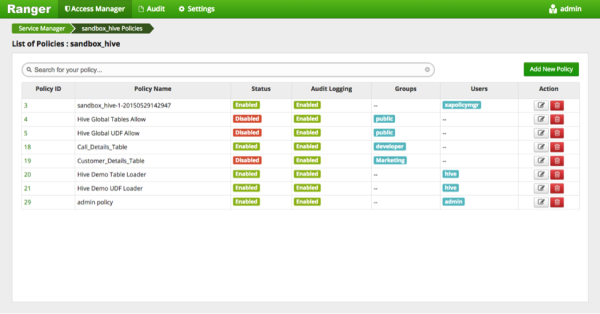
游侠安全政策概述
随着客户将Hadoop部署到企业数据和处理环境中,元数据和数据治理必须是任何企业级数据湖的重要组成部分。为此,Hortonworks 与Aetna,Merck,Target和SAS建立了数据治理计划(DGI),为Hadoop数据治理引入开源社区。此举已经演变成一个名为Apache Atlas的新开源项目。Apache Atlas是一套核心治理服务,使企业能够在Hadoop中满足其合规性要求,同时也可以与完整的企业数据生态系统集成。这些服务包括:
- 数据集搜索和谱系操作
- 元数据驱动的数据访问控制
- 索引和可搜索的集中审核
- 从摄入到处置的数据生命周期管理
- 元数据与其他工具交换 Ranger还提供了一个收集访问审计历史并报告此数据的集中框架,包括对各种参数进行过滤。HDP增强了Hadoop内不同组件中捕获的审核信息,并通过此集中报告功能提供了洞察。
数据保护功能使数据在通过网络传输和静止在磁盘上无法读取。HDP通过使用透明数据加密(TDE)来加密HDFS文件的数据,以及Ranger嵌入式开源Hadoop密钥管理存储(KMS)来满足安全性和合规性要求。Ranger使安全管理员可以管理KMS的密钥和授权策略。Hortonworks还与其加密合作伙伴广泛合作,将HDFS加密与企业级关键管理框架相集成。
加密HDFS,结合Ranger维护的KMS访问策略,防止流氓Linux或Hadoop管理员访问数据,并支持对数据访问和加密的职责分离。
强大的认证和建立用户身份是Hadoop安全访问的基础。
用户需要能够可靠地“证明”自身,然后在整个Hadoop集群中传播该身份。一旦这样做,这些用户可以访问资源(如文件或目录)或与集群进行交互(如运行MapReduce作业)。除了用户之外,Hadoop集群资源本身(如主机和服务)需要彼此认证,以避免潜在的恶意系统或守护程序的“构成”受信任的组件,以获取对数据的访问。
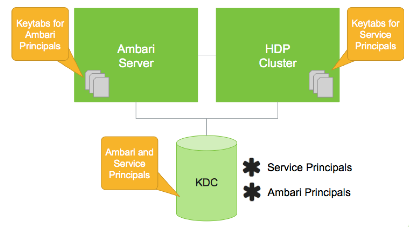
Hadoop使用Kerberos作为用户和服务的强身份验证和身份传播的基础。Kerberos是第三方认证机制,其中用户和服务依赖第三方(Kerberos服务器)来对每个认证机制进行认证。Kerberos服务器本身被称为密钥分发中心或KDC。在高层次上,它有三个部分:
- 一个存放用户和服务(称为主体)及其各自的Kerberos密码的数据库
- 一个认证服务器(AS)执行初始认证并颁发票证授予票证(TGT)
- 一个票据授权服务器(TGS)发出基于初始后续服务票证TGT
一个用户主体来自AS请求认证。AS返回使用用户主体的Kerberos密码加密的TGT,该密码仅对用户主体和AS已知。用户主体使用其Kerberos密码在本地解密TGT,从该点开始,直到票证过期,用户主体可以使用TGT从TGS获取服务票据。服务票是允许校长访问各种服务的。
因为集群资源(主机或服务)每次无法提供密码来解密TGT,所以他们使用一个特殊文件,称为Keytab,其中包含资源主体的身份验证凭据。Kerberos服务器控制的主机,用户和服务集合称为领域。
术语:
| 术语 | 描述 |
|---|---|
| 密钥分配中心或KDC | 在启用Kerberos的环境中用于验证的受信任来源。 |
| Kerberos KDC服务器 | 作为密钥分发中心(KDC)的机器或服务器。 |
| Kerberos客户端 | 集群中的任何针对KDC认证的机器。 |
| 主体principal | 针对KDC认证的用户或服务的唯一名称。 |
| Keytab | 包含一个或多个主体及其键的文件。 |
| 领域realm | 包含KDC和多个客户端的Kerberos网络。 |
| KDC管理帐号 | Ambari用于在KDC中创建主体并生成密钥表的管理帐户。 |
另一篇文章中对相关术语的定义(链接):
A Kerberos realm is a set of managed nodes that share the same Kerberos database.
A Kerberos principal is a service or user that is known to the Kerberos system.
Hadoop中的每个服务和子服务都必须有自己的主体。给定领域的主体名称由一个主名称和一个实例名称组成,实例名称为运行该服务的主机的FQDN。由于服务不使用密码登录来获取其票据,因此其主体的身份验证凭据存储在从Kerberos数据库提取的密钥表文件中,并将其本地存储在服务主体上的服务主体的安全目录中。
主体和Keytab的命名约定:
| 名称 | 约定 | 范例 |
|---|---|---|
| 校长 |
|
nn/[email protected] |
| Keytabs | $service_component_abbreviation.service.keytab | /etc/security/keytabs/nn.service.keytab |
除了Hadoop 服务主体外,Ambari本身还需要一套Ambari主体来执行服务“冒烟”检查,执行警报健康检查和从集群组件检索度量。Ambari主体的Keytab文件会驻留在群集的每台主机上,就像一般服务主体的Keytab文件一样。
| Ambari主体 | 描述 |
|---|---|
| 冒烟和“headless”服务用户 | 由Ambari用于执行服务“冒烟”检查并运行警报健康检查。 |
| Ambari服务器用户 | 当集群启用Kerberos时,组件REST端点(例如YARN ATS组件)需要SPNEGO身份验证。Ambari Server需要访问这些API,并需要Kerberos主体才能通过SPNEGO针对这些API进行身份验证。 |
kerberos KDC的安装参考这个。
这个是kerberos的客户端使用测试。
kerberos主体(principal)分成两类:用户主体UPN和服务主体SPN。
KDC由三个组件组成:Kerberos数据库,认证服务(AS)和票证授予服务(TGS)。
UPN(用户主体名称)的命名规范:
- [email protected] 用户alice在领域EXAMPLE.COM
- bob/[email protected] 管理员用户bob在领域EXAMPLE.COM
SPN(服务主体名称)的命令规范:
- hdfs/[email protected] 该主体代表了hdfs 服务的SPN ,位于Kerberos领域EXAMPLE.COM 的主机node1.example.com上。(a service name, a hostname, and a realm)
| 术语 | 名称 | 描述 |
|---|---|---|
| TGT | Ticket-granting ticket | 一个特殊票据类型,发放给被AS认证成功的用户 |
| TGS | Ticket-granting service | 一个验证TGT和授予服务票据的KDC服务 |
| 服务票据 | service ticket | 用TGT向TGS换取,相当于令牌 |
| keytab file | keytab文件保存了实际的加密密码,用于完成给定主体的密码挑战 |
例子使用的数据如下:
- EXAMPLE.COM Kerberos领域(realm)
- Alice 一个系统的用户,UPN是[email protected]
- myservice 主机server1.example.com上的一个服务,SPN是myservice/[email protected]
- kdc.example.com Kerberos领域EXAMPLE.COM的KDC
Alice为了使用myservice,她需要提交一个有效的服务票据(service ticket)到myservice。下面的步骤显示了她是怎么做的:
- Alice需要获得一个TGT。为了得到它,她发出一个请求到位于kdc.example.com的KDC,以便证明她是主体[email protected]。
- AS的响应提供了一个TGT,TGT被主体[email protected]的密码加密。
- 收到加密的消息后,Alice被提示输入主体[email protected]的密码,以便解密消息。
- 当成功解密包含TGT的消息后,Alice向位于kdc.example.com的TGS请求myservice/[email protected]的服务票据,TGT随请求一起发出。
- TGS验证TGT,提供给Alice一个服务票据(service ticket),服务票据使用主体myservice/[email protected]的密码(key)进行加密。
- Alice现在提交服务票据到myservice,myservice可以随后使用myservice/[email protected]的密码来解密票据。
- 服务myservice准许Alice使用服务,因为她已经被成功认证。

MIT Kerberos的官方网站
当前的版本是MIT Kerberos V5,或称krb5。
在之前的例子中,我们提到Alice发送认证请求。在实践中,Alice使用工具kinit做这个。
Example 4-1. kinit using the default user
[alice@server1 ~]$ kinit
Enter password for [email protected]:
[alice@server1 ~]$
这个例子使用当前Linux用户名alice和默认领域组合成了建议主体[email protected]。kinit工具还允许用户显式指定认证主体。
Example 4-2. kinit using a specified user
[alice@server1 ~]$ kinit alice/[email protected]
Enter password for alice/[email protected]:
[alice@server1 ~]$
另一个认证选线是使用keytab文件。keytab文件保存了实际的加密密码,用于完成给定主体的密码挑战。创建keytab文件对于非交互式主体很有用,如SPN,它经常与长时间运行进程(如Hadoop守护进程)关联。多个不同主体密码(key)可以存放在同一个keytab文件中。用户可以使用kinit附加一个keytab文件和主体名称(因为keytab文件可能含有多个主体密码)来进行认证。
Example 4-3. kinit using a keytab file
[alice@server1 ~]$ kinit -kt alice.keytab alice/[email protected]
[alice@server1 ~]$
另一个有用的MIT Kerberos工具是klist。这个工具允许用户查看在凭据缓存中存在的Kerberos凭据。凭据缓存位于本地文件系统中,当成功被AS认证后,保存TGT。默认地址一般是文件 /tmp/krb5cc_,是本地系统的用户ID。当成功执行kinit,alice可以使用klist显示凭据缓存。
Example 4-4. Viewing the credentials cache with klist
[alice@server1 ~]$ kinit
Enter password for [email protected]:
[alice@server1 ~]$ klist
Ticket cache: FILE:/tmp/krb5cc_5000
Default principal: [email protected]
Valid starting Expires Service principal
02/13/14 12:00:27 02/14/14 12:00:27 krbtgt/[email protected]
renew until 02/20/14 12:00:27
[alice@server1 ~]$
如果在认证之前查看凭据缓存,会显示没有发现凭据。
Example 4-5. No credentials cache found
[alice@server1 ~]$ klist
No credentials cache found (ticket cache FILE:/tmp/krb5cc_5000
[alice@server1 ~]$
另一个有用的MIT Kerberos工具是kdestory。就像名称显示的那样,它允许用户删除凭据缓存中的凭据。这个可用于切换用户,或调试新的配置。
Example 4-6. Destroying the credentials cache with kdestroy
[alice@server1 ~]$ kinit
Enter password for [email protected]:
[alice@server1 ~]$ klist
Ticket cache: FILE:/tmp/krb5cc_5000
Default principal: [email protected]
Valid starting Expires Service principal
02/13/14 12:00:27 02/14/14 12:00:27 krbtgt/[email protected]
renew until 02/20/14 12:00:27
[alice@server1 ~]$ kdestroy
[alice@server1 ~]$ klist
No credentials cache found (ticket cache FILE:/tmp/krb5cc_5000
[alice@server1 ~]$
Kerberos没有提供先进id功能,如分组和角色。特别是,Kerberos将id表示为一个简单的两部分字符串(或表示服务时的三部分字符串) ,一个短名称和一个领域。
Kerberos使用了一个两部分字符串(如[email protected])或三部分字符串(如hdfs/[email protected]),包含名称、领域和一个可选的实例名或主机名(hostname)。Hadoop将kerberos主体名称映射为本地用户名。 映射策略定义在krb5.conf文件的auth_to_local参数中,或core-site.xml中的hadoop特定规则hadoop.security.auth_to_local参数中。
hadoop用参数hadoop.security.group.mapping去控制用户到用户组的映射。默认实现是通过原生调用或本地shell命令,并利用标准UNIX接口去查找用户到组的映射。如果集群中各个主机定义的用户组不同,会导致用户到组的映射不一致。对于hadoop,映射发生在NodeNode、JobTracker(对于MR1)和ResourceManager(对于YARN/MR2)。
hadoop集群需要一个统一的用户数据库,并且将用户同步到集群中所有服务器的本地操作系统中。并且要控制这些用户在本地操作系统中权限。
Table 5-4. Hadoop ecosystem authentication methods
| Service | Protocol | Methods |
|---|---|---|
| HDFS | RPC | Kerberos, delegation token |
| HDFS | Web UI | SPNEGO (Kerberos), pluggable |
| HDFS | REST (WebHDFS) | SPNEGO (Kerberos), delegation token |
| HDFS | REST (HttpFS) | SPNEGO (Kerberos), delegation token |
| MapReduce | RPC | Kerberos, delegation token |
| MapReduce | Web UI | SPNEGO (Kerberos), pluggable |
| YARN | RPC | Kerberos, delegation token |
| YARN | Web UI | SPNEGO (Kerberos), pluggable |
| Hive Server 2 | Thrift | Kerberos, LDAP (username/password) |
| Hive Metastore | Thrift | Kerberos, LDAP (username/password) |
| Impala | Thrift | Kerberos, LDAP (username/password) |
| HBase | RPC | Kerberos, delegation token |
| HBase | Thrift Proxy | None |
| HBase | REST Proxy | SPNEGO (Kerberos) |
| Accumulo | RPC | Username/password, pluggable |
| Accumulo | Thrift Proxy | Username/password, pluggable |
| Solr | HTTP | Based on HTTP container |
| Oozie | REST | SPNEGO (Kerberos, delegation token) |
| Hue | Web UI | Username/password (database, PAM, LDAP), SAML, OAuth, SPNEGO (Kerberos), remote user (HTTP proxy) |
| ZooKeeper | RPC | Digest (username/password), IP, SASL (Kerberos), pluggable |
Hadoop支持两种认证机制:simple和kerberos。simple模式下,hadoop服务器信任所有的客户端。simple模式仅适合POC或实验室环境。
HDFS、MapReduce、YARN、HBase、Oozie和ZooKeeper都支持Kerberos作为客户端的一个认证机制,但实现因服务和接口有所不同。
对于以RPC为基础的协议,Simple Authentication and Security Layer (SASL)框架被用于在协议底层添加认证。理论上,所有SASL机制都应支持,实际上,仅支持GSSAPI(需要Kerberos V5)和DISGEST-MD5。
Oozie没有RPC协议,只提供REST接口。Oozie使用 Simpleand Protected GSSAPI Negotiation Mechanism (SPNEGO),一个通过HTTP进行Kerberos认证的协议。HDFS、MapReduce、YARN、Oozie和Hue的web接口,以及HDFS (both WebHDFS and HttpFS)和HBase的REST接口也支持SPNEGO。对于SASL和SPNEGO,
Alice使用kerberos通过HDFS NameNode认证的步骤:
- Alice向位于kdc.example.com的TGS请求一个服务票据,请求的HDFS服务id是hdfs/[email protected],随请求附上她的TGT。
- TGS验证TGT,然后为Alice提供一个服务票据(service ticket),服务票据用主体hdfs/[email protected]的key(密码)加密。
- Alice发送服务票据到NameNode(通过SASL),NameNode可以用hdfs/[email protected]的key(也就是它自己的)解密和验证这个票据。
Zookeeper支持通过用户名和密码的认证。用户名和密码认证由摘要认证供应商实现,供应商会生成用户名和密码的SHA-1摘要。
Hadoop生态系统中有许多服务代表最终用户执行操作。为了确保安全,这些服务必须对客户端进行认证,以确保客户端可以模拟那些用户。 Oozie、Hive (in HiveServer2)和Hue都支持模拟最终用户访问HDFS、MapReduce、YARN或HBase。
模拟有时被称为代理(proxying)。可以执行模拟的用户(可以代理其他用户的用户)被称为代理人(proxy)。启用模拟的配置参数有三个,可以任意组合这三个参数:
hadoop.proxyuser.<proxy>.hosts (指定模拟可以从哪台机器上发起)
hadoop.proxyuser.<proxy>.groups (指定可以被模拟的用户所在的用户组)
hadoop.proxyuser.<proxy>.users (指定可以被模拟的用户有哪几个)
其中<proxy>是执行模拟的用户的用户名,一般是超级用户,如hue、knox。值是逗号隔开的主机列表/用户组/用户列表,或*表示全部主机/用户组/用户。
如果你想要Hue和Oozie具有代理功能,但你想限制Oozie只能代理oozie-users用户组的用户,那么你最好使用类似下面的配置:
<!-- 允许超级用户hue从节点hue.example.com上模拟所有用户组的最终用户 -->
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>hue.example.com</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
<!-- 允许超级用户oozie从节点oozie01.example.com和oozie02.example.com上模拟用户组oozie-users中的最终用户 -->
<property>
<name>hadoop.proxyuser.oozie.hosts</name>
<value>oozie01.example.com,oozie02.example.com</value>
</property>
<property>
<name>hadoop.proxyuser.oozie.groups</name>
<value>oozie-users</value>
</property>
如果群集以安全模式运行,超级用户必须具有Kerberos凭据才能模拟另一个用户。
当位置好kerberos认证后,所有用户和守护进程必须提供有效的凭据才能访问RPC接口。 这意味着你必须为集群中的每一个服务器/守护进程对创建一个kerberos服务凭据。回顾一下服务主体名称(SPN)的概念,它有三部分组成:一个服务名,一个主机名,和一个领域。在hadoop中,每个作为特定服务组成部分的守护进程使用这个服务名称(对于HDFS是hdfs,对于MapReduce是mapred,对于YARN是yarn)。另外,如果你想为各种web接口启用kerberos认证,那么你还需要为HTTP服务名称提供主体。
假设有一个hadoop集群的主机和服务如下表:
Table 5-5. Service layout
| Hostname | Daemon |
|---|---|
| nn1.example.com | NameNode |
| JournalNode | |
| nn2.example.com | NameNode |
| JournalNode | |
| snn.example.com | SecondaryNameNode |
| JournalNode | |
| rm.example.com | ResourceManager |
| jt.example.com | JobTracker |
| JobHistoryServer | |
| dn1.example.com | DataNode |
| TaskTracker | |
| NodeManager | |
| dn2.example.com | DataNode |
| TaskTracker | |
| NodeManager | |
| dn3.example.com | DataNode |
| TaskTracker | |
| NodeManager |
第一步是在kerberos KDC上创建所有需要的SPN,然后为每个服务器上的每个守护进程到处一个keytab文件。需要的SPN列表如下:
Table 5-6. Required Kerberos principals
| Hostname | Daemon | Keytab file | SPN |
|---|---|---|---|
| nn1.example.com | NameNode/JournalNode | hdfs.keytab | hdfs/[email protected] |
| HTTP/[email protected] | |||
| nn2.example.com | NameNode/JournalNode | hdfs.keytab | hdfs/[email protected] |
| HTTP/[email protected] | |||
| snn.example.com | SecondaryNameNode/JournalNode | hdfs.keytab | hdfs/[email protected] |
| HTTP/[email protected] | |||
| rm.example.com | ResourceManager | yarn.keytab | yarn/[email protected] |
| jt.example.com | JobTracker | mapred.keytab | mapred/[email protected] |
| HTTP/[email protected] | |||
| JobHistoryServer | mapred.keytab | mapred/[email protected] | |
| dn1.example.com | DataNode | hdfs.keytab | hdfs/[email protected] |
| HTTP/[email protected] | |||
| TaskTracker | mapred.keytab | mapred/[email protected] | |
| HTTP/[email protected] | |||
| NodeManager | yarn.keytab | yarn/[email protected] | |
| HTTP/[email protected] | |||
| dn2.example.com | DataNode | hdfs.keytab | hdfs/[email protected] |
| HTTP/[email protected] | |||
| TaskTracker | mapred.keytab | mapred/[email protected] | |
| HTTP/[email protected] | |||
| NodeManager | yarn.keytab | yarn/[email protected] | |
| HTTP/[email protected] | |||
| dn3.example.com | DataNode | hdfs.keytab | hdfs/[email protected] |
| HTTP/[email protected] | |||
| TaskTracker | mapred.keytab | mapred/[email protected] | |
| HTTP/[email protected] | |||
| NodeManager | yarn.keytab | yarn/[email protected] | |
| HTTP/[email protected] |
keytab文件的建议存放目录是$HADOOP_CONF_DIR目录(一般是/etc/hadoop/conf)。
当创建好需要的SPN,并将keytab文件分发好,需要配置Hadoop使用Kerberos认证。首先,设置core-site.xml文件的hadoop.security.authentication参数:
<property>
<name>hadoop.security.authentication</name>
<value>kerberos</value>
</property>以HDFS的配置文件是hdfs-site.xml。NameNode服务的配置如下:
<property>
<name>dfs.block.access.token.enable</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.keytab.file</name>
<value>hdfs.keytab</value>
</property>
<property>
<name>dfs.namenode.kerberos.principal</name>
<value>hdfs/[email protected]</value>
</property>
<property>
<name>dfs.namenode.kerberos.internal.spnego.principal</name>
<value>HTTP/[email protected]</value>
</property>上例中的_HOST是通配符,实际执行时会被替换为具体的主机名。
(其他Hadoop服务的配置文件略。)
身份验证仅仅是整体安全性故事的一部分,还需要一种方法来对经过身份验证的用户可以访问的操作或数据进行建模。以这种方式保护资源称为授权。
参考
每次尝试访问HDFS中的文件或目录必须首先通过授权检查。HDFS采用与POSIX兼容的文件系统通用的授权方案。权限由三个不同类别的用户管理:所有者,组和其他人。读取,写入和执行权限可以独立授予每个类。对于文件,需要r权限才能读取文件,并且需要w权限才能写入或附加到文件中。对于目录,需要r权限来列出目录的内容,创建或删除文件或目录所需的w权限,并且需要x权限来访问目录的子目录。
从Hadoop 0.22开始,Hadoop支持两种不同的操作模式来确定用户的身份,由hadoop.security.authentication属性指定:
- simple
在这种操作模式下,客户端进程的身份由主机操作系统决定。在类Unix系统上,用户名等同于
whoami。 - kerberos
在Kerberos操作中,客户端进程的身份由其Kerberos凭据确定。例如,在Kerberos环境中,用户可以使用kinit实用程序来获取Kerberos票证授权(TGT),并使用klist来确定其当前的主体。将Kerberos主体映射到HDFS用户名时,除了主要的所有组件都将被删除。例如,一个主体todd/[email protected]将作为HDFS上的简单用户名todd。
不管操作模式如何,用户身份机制对于HDFS本身是外在的。HDFS中没有规定创建用户身份,建立组或处理用户凭据。
参考了《Hadoop Security Protecting Your Big Data Platform.pdf》。
虽然HDFS上的文件与所有者和组相关联,但Hadoop本身并不具有组的定义。从用户到组的映射是由操作系统或LDAP完成的。
一旦用户名被确定如上所述,组列表由组映射服务确定,由hadoop.security.group.mapping属性配置。
可以通过org.apache.hadoop.security.LdapGroupsMapping将替代实现直接连接到LDAP服务器来解析组列表。但是,只有在必需的组仅存在于LDAP中且不在Unix服务器上实现时,才应使用此提供程序。
hadoop在进行用户到用户组映射时,默认使用ShellBasedUnixGroupsMapping的机制。这是一个基于shell的实现,类似于id -Gn命令。
hadoop支持LdapGroupsMapping的实现。但选择这种实现会覆盖本地系统中用户和用户组,你将失去原来定义的hadoop服务账号如hdfs。所以建议将LDAP配置在操作系统级,使用类似SSSD的网络认证方案。
Hadoop支持服务级别授权。授权策略保存在hadoop-policy.xml中。在该xml中可以定义“权力清单(如提交作业到集群的权力)”与用户(用户组)的对应。用户之间用逗号隔开,用户与用户组之间用空格隔开。以空格开始表示只定义了用户组,以空格结尾表示只定义了用户。
无论MapReduce还是YARN都不需要控制数据访问,而是要控制集群资源,如CPU、内存、磁盘I/O和网络I/O。服务级别授权仅可以控制到特定协议(protocol),如谁可以提交一个作业到集群,但无法细致到控制集群资源的访问。
Hadoop支持将ACL定义到作业队列。这些ACL控制哪些用户可以提交作业到特定队列,还可以控制哪些用户可以管理(administer)队列。
边缘节点托管web接口、代理和客户端配置。边缘节点部署的服务有:
- HDFS HttpFS and NFS gateway
- Hive HiveServer2 and WebHCatServer
- Network proxy/load balancer for Impala
- Hue server and Kerberos ticket renewer
- Oozie server
- HBase Thrift server and REST server
- Flume agent
- Client configuration files
下面是一些典型的边缘节点类型:
- Data Gateway
HDFS HttpFS and NFS gateway, HBase Thrift server and REST server, Flume agent - SQL Gateway
Hive HiveServer2 and WebHCatServer, Impala load-balancing proxy (e.g., HAP‐roxy) - User Portal
Hue server and Kerberos ticket renewer, Oozie server, client configuration files
核心Hadoop命令行工具(hdfs、yarn和mapred)仅支持Kerberos或授权令牌进行身份验证。认证这些命令的最简单的方法是在执行命令之前使用kinit 获取Kerberos票证授予票据(ticket-granting ticket)。
$ kinit [email protected] (登录使用kerberos的kinit工具)
$ hdfs dfs -mkdir /tmp/webb (创建/tmp/webb目录)
$ hdfs dfs -ls /tmp (查看/tmp目录)
...
drwxr-xr-x - webb3 hdfs 0 2017-04-25 02:31 /tmp/webb (这是新创建的目录,注意这个目录的拥有者是webb3)
HDFS的superuser是hdfs。当haddop集群启用kerberos后,hdfs的主体并没有在KDC中建立。测试中碰到针对HDFS的权限不足时,可能会用到HDFS的超级用户,可以用kadmin命令来在KDC创建hdfs的主体。在u1404上执行:
$ kadmin
kadmin: add_principal hdfs
Enter password for principal "[email protected]": (需要输入hdfs的密码)
Re-enter password for principal "[email protected]": (再次输入hdfs的密码)
Principal "[email protected]" created.
使用hive命令行工具beeline连接HiveServer2。其中jdbc:hive2://u1403.ambari.apache.org:10000/default是JDBC URL,principal=hive/[email protected]是连接使用的Hive Kerberos主体。beeline命令以感叹号!开始。
$ kinit [email protected] (使用主体webb3访问Hive)
$ beeline
Beeline version 1.2.1000.2.5.3.0-37 by Apache Hive
beeline> !connect jdbc:hive2://u1403.ambari.apache.org:10000/default;principal=hive/[email protected]
Connecting to jdbc:hive2://u1403.ambari.apache.org:10000/default;principal=hive/[email protected]
Enter username for jdbc:hive2://u1403.ambari.apache.org:10000/default;principal=hive/[email protected]:
Enter password for jdbc:hive2://u1403.ambari.apache.org:10000/default;principal=hive/[email protected]:
Connected to: Apache Hive (version 1.2.1000.2.5.3.0-37)
Driver: Hive JDBC (version 1.2.1000.2.5.3.0-37)
Transaction isolation: TRANSACTION_REPEATABLE_READ
下面在Hive创建一个外部表,表文件存放在前面创建的HDFS/tmp/webb/student目录下:
0: jdbc:hive2://u1403.ambari.apache.org:10000> CREATE EXTERNAL TABLE student(name string, age int, gpa double) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS TEXTFILE LOCATION '/tmp/webb/student';
0: jdbc:hive2://u1403.ambari.apache.org:10000> show tables; (显示hive中数据库表清单)
+---------------+--+
| tab_name |
+---------------+--+
| student |
+---------------+--+
3 rows selected (0.284 seconds)
0: jdbc:hive2://u1403.ambari.apache.org:10000> SELECT * FROM student; (显示hive表student中数据,可看到列名,数据空)
+---------------+--------------+--------------+--+
| student.name | student.age | student.gpa |
+---------------+--------------+--------------+--+
+---------------+--------------+--------------+--+
No rows selected (0.425 seconds)
下面利用直接利用hdfs命令行看看HDFS中hive建立的/tmp/webb/student文件:
$ hdfs dfs -ls /tmp/webb
Found 1 items
drwxr-xr-x - webb3 hdfs 0 2017-04-25 07:48 /tmp/webb/student
看到hive表对应到HDFS中是个同名的目录。
采用了类似linux文件系统的权限模式。每个文件都拥有用户、组所有者以及权限设置。这些权限控制了用户对于特定目录或文件的访问。
操作系统用户和用户在分布式文件系统中分配的权限之间并没有直接的联系。在更改目录或文件的所有者时,Hadoop并不会检查用户是否真正存在。
MapReduce安全的重心在于作业提交以及管理。
Hadoop提供了对于集群管理员和队伍管理员这两个概念的支持。集群和队列管理员属于Linux用户和群组,他们拥有查看和修改运行作业的权限。
查看了一下本地HDP环境,发现文件/etc/hadoop/2.5.3.0-37/0/mapred-site.xml中与安全相关内容:
<property>
<name>mapreduce.cluster.administrators</name>
<value> hadoop</value>
</property>:
上述定义是mapreduce的集群管理员。
mapred-queue-acls.xml中可以定义哪些用户或用户组可以向哪个队列中提交作业。但这个配置文件可能是个老版本(非yarn)才有的。
####Hadoop服务级别验证 配置文件/etc/hadoop/conf/hadoop-policy.xml中定义了一些acl策略,如下列配置
<property>
<name>security.client.protocol.acl</name>
<value>*</value>
</property>
可以控制那些群组的用户可以分布式文件系统的后台服务进行通讯。
在hadoop-policy.xml文件中有更多的选项能够对Hadoop服务(包括内部通信鞋业)访问进行控制。
在配置文件/etc/hadoop/conf/core-site.xml中默认值是:
<property>
<name>hadoop.security.authentication</name>
<value>simple</value>
</property>
如果开启kerberos,需要把simple替换为kerberos。
我选择让Ambari自动安装kerberos,参考Ambari测试。
当使用ambari安装完kerberos后,会发现上面的core-site.xml中simple被修改成了kerberos,文件中还有其他的一些相关配置变化。
http://www.thekspace.com/home/component/content/article/54-kerberos-and-spnego.html Kerberos一般部署在C/S环境,很少用于web应用和瘦客户端环境。SPNEGO提供了一个机制,通过HTTP协议将kerberos扩展到了web应用。
为了保证安全,hadoop集群用户应使用默认shell为/sbin/nologin,并且利用/etc/ssh/sshd中的AllowUsers、DenyUsers、AllowGroups和DenyGroups来禁用SSH。
(P95)
对于基于RPC的协议,SASL(Simple Authentication and Security Layer)框架用于对底层协议添加认证。理论上任何SASL机制都支持,但实际上,仅支持GSSAPI (仅Kerberos V5) 和 DIGESTMD5 (see “Tokens” on page 78 for details on DIGEST-MD5)。 Oozie使用SPNEGO(Simple
and Protected GSSAPI Negotiation)机制,一个首先被微软在IE5.0.1和IIS5.0中实现的,通过HTTP协议实现kerberos认证的协议。