This Tampermonkey script allows you to extract image URLs from a Dropbox folder page and copy them to your clipboard with a single click. The script adds a "Copy all URLs" button to the Dropbox page, and when you click the button, it scrolls through the entire folder, collects all image URLs, and copies them to your clipboard.
This is a userscript that extracts image URLs from a Dropbox page and copies them to the clipboard when a button is clicked. The script creates a button on the page that, when clicked, scrolls to the bottom of the page, waits for new images to load, and extracts the image URLs. The script then joins the URLs into a string separated by newlines. It then puts the links on your clipboard with ?dl=0 replaced with ?raw=1 parameters.
The power of extracting image URLs from a Dropbox folder page and copying them to your clipboard with a single click!
Floating button in the bottom right of your browser window:
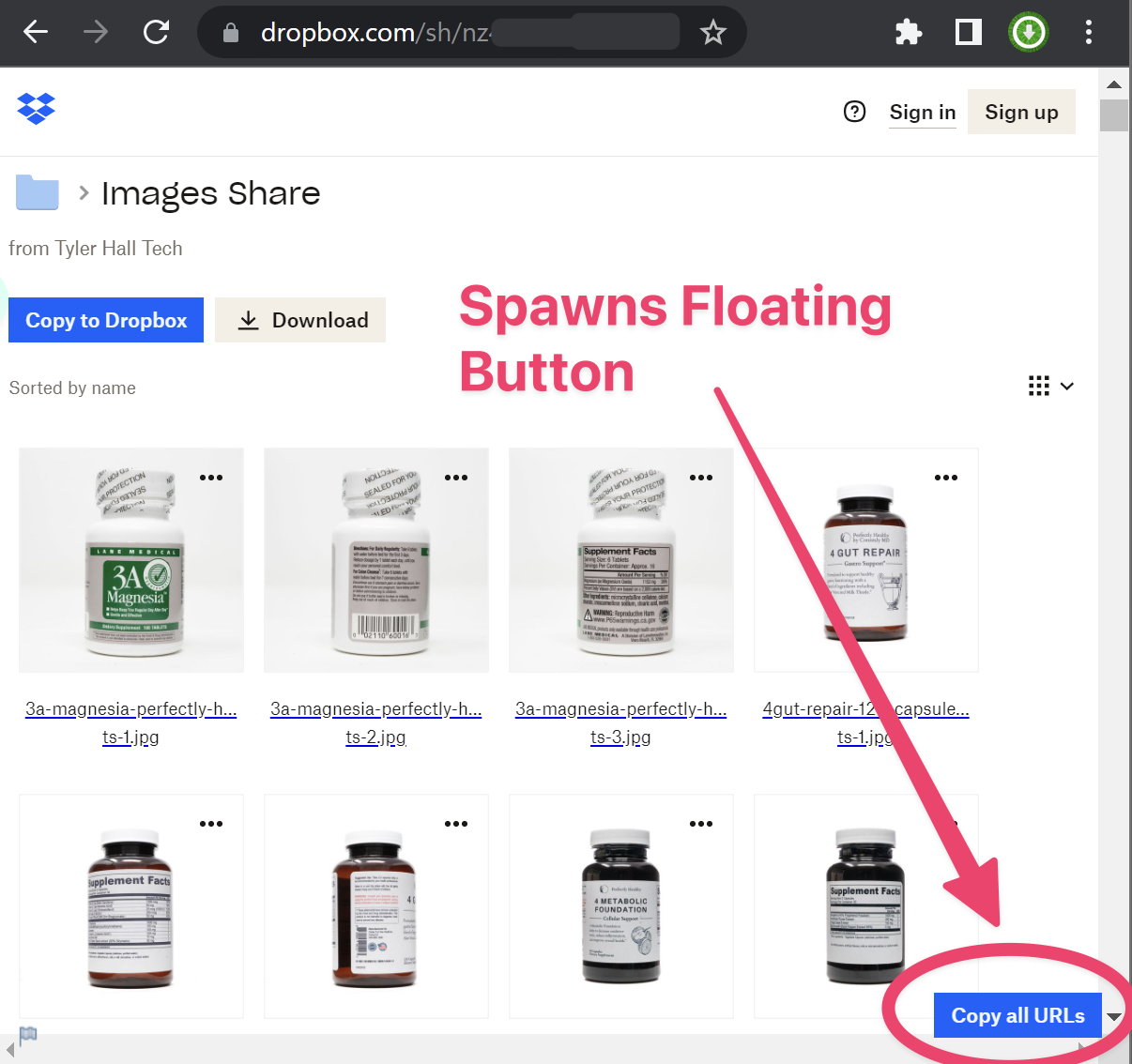
Click the button and all image URLs are copied to your clipboard

Paste all your URLs:

- Install the Tampermonkey browser extension from the official website.
- Open the Tampermonkey dashboard and go to the "Utilities" tab.
- Under "URL," paste the raw URL of the script file (e.g.,
https://raw.githubusercontent.com/tyhallcsu/dropbox-image-url-extractor/main/dropbox-image-bulk-url-extractor) and click "Import." - Confirm the installation when prompted.
- Navigate to a Dropbox folder page containing images.
- Click the "Copy all URLs" button that appears in the bottom right corner of the page.
- The script will scroll through the entire folder, collect all image URLs, and copy them to your clipboard.
- The button will display the number of URLs copied and will be temporarily disabled for 3 seconds before becoming active again.
This Tampermonkey script allows you to extract image URLs from a Dropbox folder page and copy them to your clipboard with a single click. The script adds a "Copy all URLs" button to the Dropbox page, and when you click the button, it scrolls through the entire folder, collects all image URLs, and copies them to your clipboard.
Known bugs:
- None.
| Version | Link | Alternative | Note |
|---|---|---|---|
| Userscript | Greasy Fork | Install (GitHub) | Work in Progress |
| Chrome/Edge/Opera | GitHub | - | Work in progress |
| Legacy | Gist | Link | - |
(Optional) Mobile Bookmarklet:
JSCopy code
javascript:(function(){['https://raw.githubusercontent.com/tyhallcsu/dropbox-image-url-extractor/main/dropbox-image-bulk-url-extractor'].map(s=>document.body.appendChild(document.createElement('script')).src=s)})();
Tested and compatible with Tampermonkey.
- Automatically scrolls through the entire Dropbox folder to load all images.
- Extracts image URLs and copies them to the clipboard with a single click.
- Button is temporarily disabled after copying URLs to prevent accidental clicks.
- Configurable wait time for loading new images.
Nothing appears bottom right:
- Try again on another Dropbox folder page.
- Make sure the Tampermonkey extension is enabled and the script is installed.
- If issue persists, see Viewing UserJS Logs.
- Open your web browser's Inspect Element and navigate to its Console.
- Locate the following [UserScript] < message > (you can filter your Console by entering UserScript or [).
- Feel free to screenshot any error messages to the GitHub for additional help.
- If nothing appears, this means the script is not executing at all.
You can adjust the SECONDS_TO_WAIT_FOR_SCROLL constant in the script to change the amount of time the script waits for new images to load after scrolling to the bottom of the page.
The Tampermonkey script is designed to automate the process of extracting image URLs from a Dropbox folder page and copying them to the user's clipboard. The script is executed as a userscript in the context of the browser's web page, and it operates by interacting with the Document Object Model (DOM) of the Dropbox page. Below is a technical explanation of how the script works:
-
The script starts by defining a set of constants and functions that will be used later in the script:
SECONDS_TO_WAIT_FOR_SCROLL: A constant that specifies the number of seconds the script should wait for new images to load after scrolling to the bottom of the page.DOWNLOAD_URL_REPLACEMENT: A constant that specifies the query parameter to be appended to the image URLs to enable direct download.getImageLinks: A function that queries the DOM for anchor elements (<a>) containing links to image files. It then extracts thehrefattribute of each anchor element, replaces the query parameter?dl=0with?raw=1to enable direct download, and returns an array of modified URLs.waitForImagesToLoad: An asynchronous function that programmatically scrolls to the bottom of the page and waits for a specified duration (defined bySECONDS_TO_WAIT_FOR_SCROLL) to allow new images to load.
-
The script creates an empty array
imageUrlsto store the image URLs that will be extracted from the page. -
The script dynamically creates a button element (
<button>) and appends it to the DOM. The button is styled and positioned in the bottom right corner of the page. The text content of the button is set to "Copy all URLs." -
The script adds a click event listener to the button. When the button is clicked, the following actions are performed:
- The script enters a loop that continues until all image URLs have been extracted from the page. The loop is controlled by the
finishedvariable, which is initially set tofalse. - Within the loop, the script calls the
waitForImagesToLoadfunction to scroll to the bottom of the page and wait for new images to load. - The script then calls the
getImageLinksfunction to extract the URLs of the newly loaded images. It filters out any URLs that have already been added to theimageUrlsarray to avoid duplicates. - The script checks whether any new URLs were extracted in the current iteration. If no new URLs were extracted, it sets the
finishedvariable totrue, which will terminate the loop. - The script keeps track of the total number of URLs extracted in the
numUrlsvariable.
- The script enters a loop that continues until all image URLs have been extracted from the page. The loop is controlled by the
-
Once the loop is complete, the script concatenates the image URLs into a single string, separated by newline characters (
\n), and copies the string to the clipboard using theGM_setClipboardfunction provided by the Tampermonkey API. -
The script updates the text content of the button to indicate the number of URLs copied to the clipboard and temporarily disables the button for 3 seconds. After this duration, the button is re-enabled, and the text content is reset to "Copy all URLs."
The script leverages the Tampermonkey API, DOM manipulation, and asynchronous programming to automate the process of extracting image URLs from a Dropbox folder page and copying them to the user's clipboard. The script is designed to be compatible with the Dropbox web interface.
Tyler Hall Tech
This script is provided "as is" without warranty of any kind. Use it at your own risk. The author is not responsible for any consequences resulting from the use of this script.
This project is licensed under the MIT License. See the LICENSE file for details.
- Tyler Hall Tech