



PyTorchPipe (PTP) is a component-oriented framework that facilitates development of computational multi-modal pipelines and comparison of diverse neural network-based models.
PTP frames training and testing procedures as pipelines consisting of many components communicating through data streams. Each such a stream can consist of several components, including one task instance (providing batches of data), any number of trainable components (models) and additional components providing required transformations and computations.

As a result, the training & testing procedures are no longer pinned to a specific task or model, and built-in mechanisms for compatibility checking (handshaking), configuration and global variables management & statistics collection facilitate rapid development of complex pipelines and running diverse experiments.
In its core, to accelerate the computations on their own, PTP relies on PyTorch and extensively uses its mechanisms for distribution of computations on CPUs/GPUs, including multi-process data loaders and multi-GPU data parallelism. The models are agnostic to those operations and one indicates whether to use them in configuration files (data loaders) or by passing adequate argument (--gpu) at run-time.
Please refer to the tutorial presentation for more details.
Datasets: PTP focuses on multi-modal reasoning combining vision and language. Currently it offers the following Tasks from the following task, categorized into three domains:

Aside of providing batches of samples, the Task class will automatically download the files associated with a given dataset (as long as the dataset is publicly available). The diversity of those tasks (and the associated models) proves the flexibility of the framework. We are constantly working on incorporation of new Tasks into PTP.
Pipelines: What people typically define as a model in PTP is framed as a pipeline, consisting of many inter-connected components, with one or more Models containing trainable elements. Those components are loosely coupled and care only about the input streams they retrieve and output streams they produce. The framework offers full flexibility and it is up to the programmer to choose the granularity of his/her components/models/pipelines. Such a decomposition enables one to easily combine many components and models into pipelines, whereas the framework supports loading of pretrained models, freezing during training, saving them to checkpoints etc.
Model/Component Zoo: PTP provides several ready to use, out of the box models and other, non-trainable (but parametrizable) components.
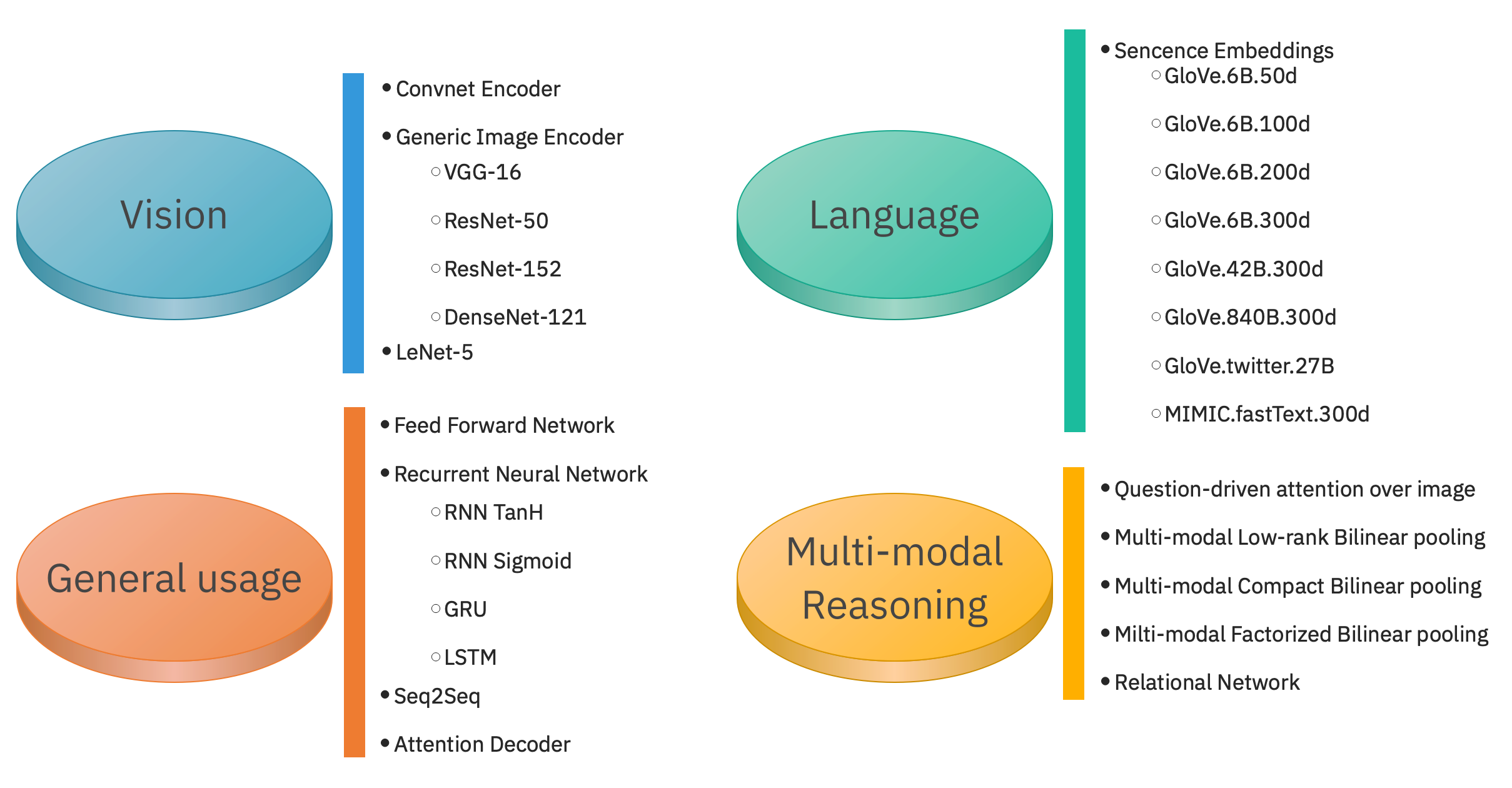
The model zoo includes several general usage components, such as:
- Feed Forward Network (variable number of Fully Connected layers with activation functions and dropout)
- Recurrent Neural Network (different cell types with activation functions and dropout, a single model can work both as encoder or decoder)
It also inludes few models specific for a given domain, but still quite general:
- Convnet Encoder (CNNs with ReLU and MaxPooling, can work with different sizes of images)
- General Image Encoder (wrapping several models from Torch Vision)
- Sentence Embeddings (encoding words using the embedding layer)
There are also some classical baselines both for vision like LeNet-5 or language domains, e.g. Seq2Seq (Sequence to Sequence model) or Attention Decoder (RNN-based decoder implementing Bahdanau-style attention). PTP also offers the several models useful for multi-modal fusion and reasoning.

The framework also offers components useful when working with language, vision or other types of streams (e.g. tensor transformations). There are also several general-purpose components, from components calculating losses and statistics to publishers and viewers.
Workers: PTP workers are python scripts that are agnostic to the tasks/models/pipelines that they are supposed to work with. Currently framework offers three workers:
-
ptp-offline-trainer (a trainer relying on classical methodology interlacing training and validation at the end of every epoch, creates separate instances of training and validation tasks and trains the models by feeding the created pipeline with batches of data, relying on the notion of an epoch)
-
ptp-online-trainer (a flexible trainer creating separate instances of training and validation tasks and training the models by feeding the created pipeline with batches of data, relying on the notion of an episode)
-
ptp-processor (performing one pass over the all samples returned by a given task instance, useful for collecting scores on test set, answers for submissions to competitions etc.)
PTP relies on PyTorch, so you need to install it first. Please refer to the official installation guide for details. It is easily installable via conda_, or you can compile it from source to optimize it for your machine.
PTP is not (yet) available as a pip package, or on conda.
However, we provide the setup.py script and recommend to use it for installation.
First please clone the project repository:
git clone [email protected]:IBM/pytorchpipe.git
cd pytorchpipe/Next, install the dependencies by running:
python setup.py developThis command will install all dependencies via pip_, while still enabling you to change the code of the existing components/workers and running them by calling the associated ptp-* commands.
More in that subject can be found in the following blog post on dev_mode.
Please consider a simple ConvNet model consisting of two parts:
- few convolutional layers accepting the MNIST images and returning feature maps being, in general, a 4D tensor (first dimension being the batch size, a rule of thumb in PTP),
- one (or more) dense layers that accept the (flattened) feature maps and return predictions in the form of logarithm of probability distributions (LogSoftmax as last non-linearity).
Assume that we will use NLL Loss function, and, besides, want to monitor the Accuracy statistics.
The resulting pipeline is presented below.
The additional Answer Decoder component translates the predictions into class names, whereas Stream Viewer displays content of the indicated data streams for a single sample randomly picked from the batch.

Note: The associated mnist_classification_convnet_softmax.yml configuration file can be found in configs/tutorials folder.
We will train the model with ptp-offline-trainer, a general worker script that follows the classical training-validation, epoch-based methodology.
This means, that despite the presence of three sections (associated with training, validation and test splits of the MNIST dataset) the trainer will consider only the content of training and validation sections (plus pipeline, containing the definition of the whole pipeline).
Let's run the training by calling the following from the command line:
ptp-offline-trainer --c configs/tutorials/mnist_classification_convnet_softmax.ymlNote: Please call offline-trainer --h to learn more about the run-time arguments. In order to understand the structure of the main configuration file please look at the default configuration file of the trainer located in configs/default/workers folder.
The trainer will log on the console training and validation statistis, along with additional information logged by the components, e.g. contents of the streams:
[2019-07-05 13:31:44] - INFO - OfflineTrainer >>> episode 006000; epoch 06; loss 0.1968410313; accuracy 0.9219
[2019-07-05 13:31:45] - INFO - OfflineTrainer >>> End of epoch: 6
================================================================================
[2019-07-05 13:31:45] - INFO - OfflineTrainer >>> episode 006019; episodes_aggregated 000860; epoch 06; loss 0.1799264401; loss_min 0.0302138925; loss_max 0.5467863679; loss_std 0.0761705562; accuracy 0.94593; accuracy_std 0.02871 [Full Training]
[2019-07-05 13:31:45] - INFO - OfflineTrainer >>> Validating over the entire validation set (5000 samples in 79 episodes)
[2019-07-05 13:31:45] - INFO - stream_viewer >>> Showing selected streams for sample 20 (index: 55358):
'labels': One
'targets': 1
'predictions': tensor([-1.1452e+01, -1.6804e-03, -1.1357e+01, -1.1923e+01, -6.6160e+00,
-1.4658e+01, -9.6191e+00, -8.6472e+00, -9.6082e+00, -1.3505e+01])
'predicted_answers': OnePlease note that whenever the validation loss goes down, the trainer automatically will save the pipeline to the checkpoint file:
[2019-07-05 13:31:47] - INFO - OfflineTrainer >>> episode 006019; episodes_aggregated 000079; epoch 06; loss 0.1563445479; loss_min 0.0299939774; loss_max 0.5055227876; loss_std 0.0854654983; accuracy 0.95740; accuracy_std 0.02495 [Full Validation]
[2019-07-05 13:31:47] - INFO - mnist_classification_convnet_softmax >>> Exporting pipeline 'mnist_classification_convnet_softmax' parameters to checkpoint:
/users/tomaszkornuta/experiments/mnist/mnist_classification_convnet_softmax/20190705_132624/checkpoints/mnist_classification_convnet_softmax_best.pt
+ Model 'image_encoder' [ConvNetEncoder] params saved
+ Model 'classifier' [FeedForwardNetwork] params savedAfter the training finsh the trainer will inform about the termination reason and indicate where the experiment files (model checkpoint, log files, statistics etc.) can be found:
[2019-07-05 13:32:33] - INFO - mnist_classification_convnet_softmax >>> Updated training status in checkpoint:
/users/tomaszkornuta/experiments/mnist/mnist_classification_convnet_softmax/20190705_132624/checkpoints/mnist_classification_convnet_softmax_best.pt
[2019-07-05 13:32:33] - INFO - OfflineTrainer >>>
================================================================================
[2019-07-05 13:32:33] - INFO - OfflineTrainer >>> Training finished because Converged (Full Validation Loss went below Loss Stop threshold of 0.15)
[2019-07-05 13:32:33] - INFO - OfflineTrainer >>> Experiment finished!
[2019-07-05 13:32:33] - INFO - OfflineTrainer >>> Experiment logged to: /users/tomaszkornuta/experiments/mnist/mnist_classification_convnet_softmax/20190705_132624/In order to test the model generalization we will use ptp-processor, yet another general worker script that performs a single pass over the indicated set.

ptp-processor --load /users/tomaszkornuta/experiments/mnist/mnist_classification_convnet_softmax/20190705_132624/checkpoints/mnist_classification_convnet_softmax_best.ptNote: ptp-processor uses the content of test section as default, but it can be changed at run-time. Please call ptp-processor --h to learn about the available run-time arguments.
[2019-07-05 13:34:41] - INFO - Processor >>> episode 000313; episodes_aggregated 000157; loss 0.1464060694; loss_min 0.0352710858; loss_max 0.3801054060; loss_std 0.0669835582; accuracy 0.95770; accuracy_std 0.02471 [Full Set]
[2019-07-05 13:34:41] - INFO - Processor >>> Experiment logged to: /users/tomaszkornuta/experiments/mnist/mnist_classification_convnet_softmax/20190705_132624/test_20190705_133436/Note: Please analyze the mnist_classification_convnet_softmax.yml configuration file (located in configs/tutorials directory). Keep in mind that:
- all components come with default configuration files, located in
configs/default/componentsfolders, - all workers come with default configuration files, located in
configs/default/workersfolders.
Currently PTP does not have an on-line documentation. However, there are high-quality comments in all source/configuration files, that will be used for automatic generation of documentation (Sphinx + ReadTheDocs). Besides, we have shared a tutorial presentation explaining motivations and core concepts as well as providing hints how to use the tool and develop your own solutions.
PTP is open for external contributions. We follow the Git Branching Model, in short:
developbranch is the main branch,masterbranch is for used for releases only- all changes are integrated by merging pull requests from feat/fix/other branches
- PTP is integrated with several DevOps monitoring the quality of code/pull requests
- we strongly encourage unit testing and Test-Driven Development
- we use projects and kanban to monitor issues/progress/etc.
A project of the Machine Intelligence team, IBM Research AI, Almaden Research Center.
- Tomasz Kornuta ([email protected])
