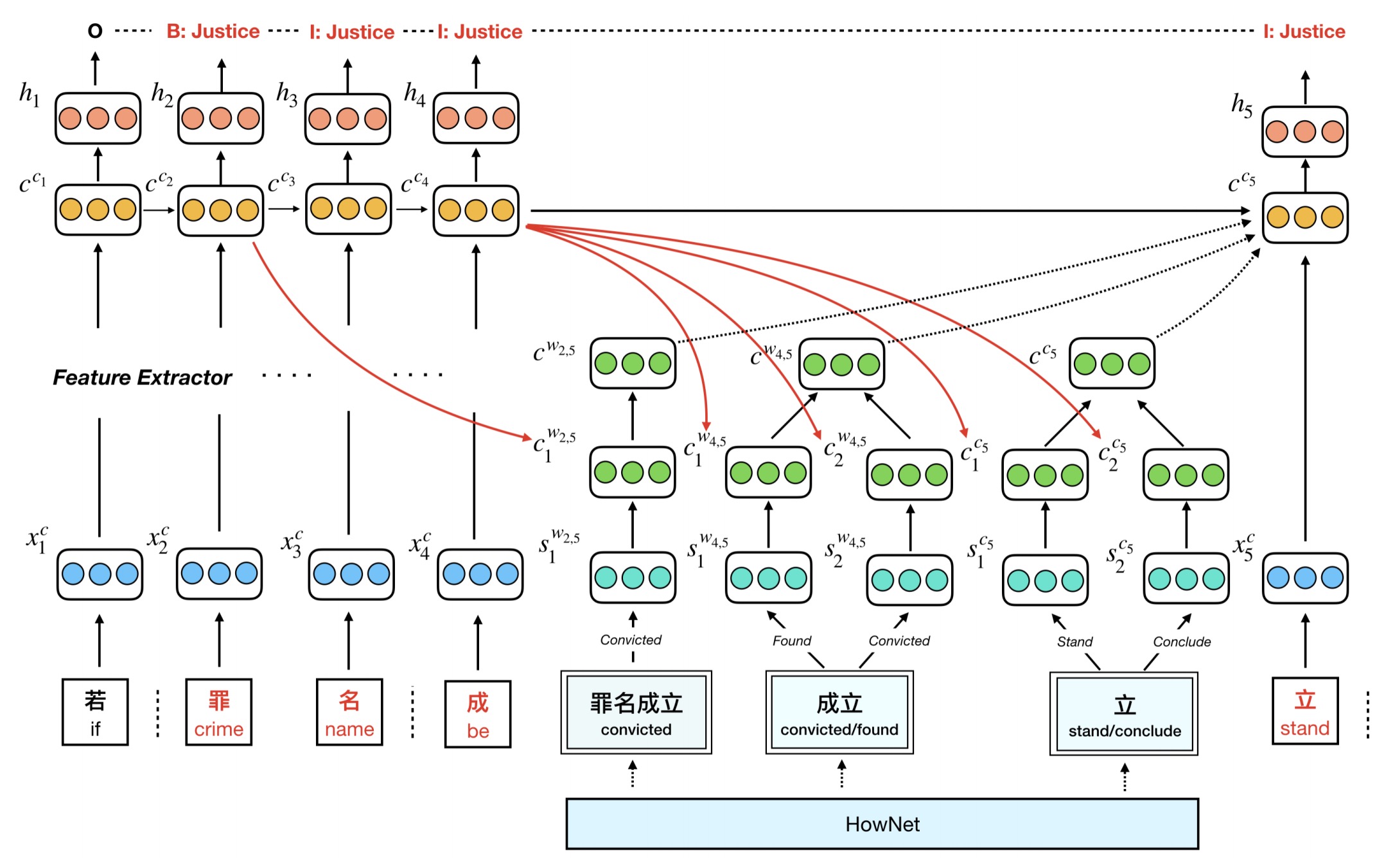
This is the source code of the EMNLP 2019 paper Event Detection with Trigger-Aware Lattice Neural Network . TLNN model aims to address the issues of trigger-word mismatch and trigger polysemy. In this project, the event detection is a sequence labeling task. For more information, please read the paper.
-
Python 3.6
-
Pytorch 0.3.0
-
CUDA 0.9
-
Numpy
Datasets in our paper is ACE2005 and KBP Eval 2017. According to terms of LDC, we can not share the data to the third party. But if you have LDC license, you can obtain the two datasets with the LDC numbers:
-
ACE 2005: LDC2006T06
-
KBP Eval 2017: LDC2017E55


The task is regarded as a sequence labeling task. The training, dev and test data is expected in standard tab-separated format. One word per line, separate column for token and label, empty line between sentences. The first line of each sentence is the document id corresponding to golden set.
for each word, the first column is the token, the second column is the character index, the last column is the tag of event type. For example:
sid:CTS20001223.1300.0809
歹 297 O
徒 298 O
抢 300 B-Conflict:Attack
得 301 O
实 302 O
在 303 O
One character per line. For each line, the first column is the character, the rest columns is the value of the embedding of the character.
Similar to character embedding but for word senses. For example:
苹果#1 0.304095 ...
苹果#2 -0.175496 ...
香蕉 -0.230772 ...
where Word#n means that it is the n-th sense of word A, The pretrained word senses embedding could be obtained by SAT.
Records all senses for each polysemous word, corresponding to the word sense embedding. One word per line, for each line, the first column is the word, and the rest columns are all the senses of it ( if exits ). For example:
苹果 苹果#1 苹果#2
香蕉
Recodes the answer of all triggers with location and event types for evaluations. One trigger per line, the columns are doucment id, start index of character, trigger word length, trigger word and event type. For example:
CTV20001227.1330.0447 57 2 宣判 Justice:Sentence
CTV20001227.1330.0447 131 2 判处 Justice:Sentence
CTV20001227.1330.0447 110 2 判处 Justice:Sentence
CTV20001227.1330.0447 51 2 上诉 Justice:Appeal
CTV20001227.1330.0447 288 2 上诉 Justice:Appeal
Arguments of the code are set in config.py, which contains
status = 'train' Status of the program
savemodel = 'data/model/test' Path of the saved model
savedset = 'data/model/test.dset' Path of the saved data settings
TRAIN = 'trainid_BIO.txt' Path of the training data
dev = 'devid_BIO.txt' Path of the dev data
test = "testchrid_BIO.txt" Path of the test data
loadmodel = 'data/model/test.model' Path of the model to load
output = 'data/test.output' Path of the output
lr = 0.015 Learning rate
maxlen = 300 Max length of each sequence
dataset = 'ace' Dataset name
pretrain_char_emb = 'char.vec' Pre-trained character embeddings
pretrain_sense_emb = 'sense.vec' Pre-trained sense embeddings
pretrain_word_emb = 'word.vec' Pre-trained word embeddings
With appropriate data settings, you could run the code with:
python train.py@inproceedings{ding2019event,
title={Event Detection with Trigger-Aware Lattice Neural Network},
author={Ding, Ning and Li, Ziran and Liu, Zhiyuan and Zheng, Haitao and Lin, Zibo},
booktitle={Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)},
pages={347--356},
year={2019}
}
For any questions, please contact: