This a rewrite of the Provisium code started under ESIP (https://github.com/ESIPFed/provisium). It is dramatically different to apply lessons learned. It has been updated as part of EarthCube THROUGHPUT.
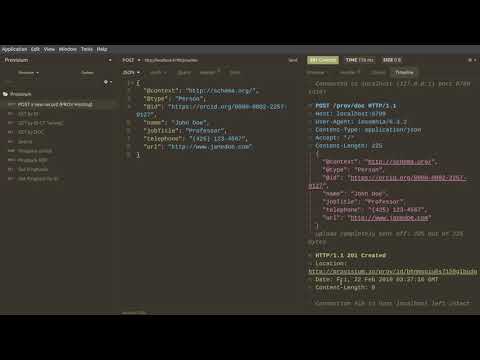
The code has been placed under the main Provisium repo listed above. This repository will focus on the settings, deployment codes that Throughput will then use to enable this new version of the code.
The plan will be to merge these implementation patterns back into the main repository. This will provide implementation patterns for groups to use to set up an instance for their use.
The search and a few things like a resource display need to be implemented still. All the plumbing is there though, just need time to flesh out some templates and structures.
Provisium has two run time dependencies. These can be launched via a Docker compose file locate in deployments. Later this package will build to a docker file and one compose file will bring up the entire service.
The package currently builds to a docker container now. We need to push that out and modify the compose file to reflect that.
You also need to set three environment variables for this code. You can use something like the script setenvs.sh in the scripts directory to do this. These are the settings for the Minio system and the location of your SPARQL endpoint.
General approach is:
export MINIO_HOST=clear.local
export MINIO_PORT=9000
export MINIO_ACCESS_KEY=AKIAIOSFODNN7EXAMPLE
export MINIO_SECRET_KEY=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
git clone https://github.com/ESIPFed/provisium
cd provisium
go run cmd/provisium/main.go
will get you started. I need to get some more details here though. This is rather sketch on how to get started.
An instance of Jena Fuseki in Docker that can be used for Provisium. Note any SPARQL 1.1 (including update) compliant triples store should work.
- https://cloud.docker.com/u/fcore/repository/docker/fcore/jena
- https://www.w3.org/TR/sparql11-update/
- https://www.w3.org/TR/sparql11-protocol/
An instance of Minio to supply S3 API compliant object store.
Note any S3 compliant system such as OpenStack Swift or even
AWS S3 itself will work.
- https://hub.docker.com/r/minio/minio
- https://wiki.openstack.org/wiki/Swift
- https://aws.amazon.com/s3/
- All submissions come in and get put in an object store (minio) with basic metadata about them (requester info) and the package
- RDF packages are validated prior to archiving. Once in the object store, they move into the graph (Jena)
- Non-RDF package are validated prior to archiving. These are likely just URL lists as defined by the PROV-AQ spec.
- Non-RDF input is also stored in a separate named graph with sufficient triples to allow query across the default graph to work for both types of submissions.
Request "hosting" a prov record (require RDF for this one) (ttl, nt, json-ld)
Load to graph with a unique QUAD (what if it comes with quads?)
Don't allow quads :) screw your graph! (can't allow JSON-LD then...)
Section 2 Access Section and 3 Locating Prov records
direct access with 303 redirection
In this case doc/id is really a page about the hosted PROVURI
it could give examples of link or query header or RDF graph
also the pingback ID
Section 4 query service (direct and SPARQL)
NOTE this needs a ?q= or more and we need to support SPARQL too
Section 5 pingback (URI list, or has query service or RDF)
Due to the nature of pingback we can simply hold the POST in an object store.
If we did accept RDF, we could place that in a graph, but it would be incomplete and care
would need to be taken to include the other info. That pingback bundle could be
converted to RDF but we need to ensure a singable or deterministic serialization
text/uri-list (which is doable)
Though not part of the Note, a GET service can be called to present past pingbacks
Potentially, this might be restricted to the authors of a resource, though here no
authentication or authorization is imposed. Simple OpenID for ID with some auth policy
could be built in.