


What is CML? Continuous Machine Learning (CML) is an open-source CLI tool for implementing continuous integration & delivery (CI/CD) with a focus on MLOps. Use it to automate development workflows — including machine provisioning, model training and evaluation, comparing ML experiments across project history, and monitoring changing datasets.
CML can help train and evaluate models — and then generate a visual report with results and metrics — automatically on every pull request.
CML principles:
- GitFlow for data science. Use GitLab or GitHub to manage ML experiments, track who trained ML models or modified data and when. Codify data and models with DVC instead of pushing to a Git repo.
- Auto reports for ML experiments. Auto-generate reports with metrics and plots in each Git pull request. Rigorous engineering practices help your team make informed, data-driven decisions.
- No additional services. Build your own ML platform using GitLab, Bitbucket, or GitHub. Optionally, use cloud storage as well as either self-hosted or cloud runners (such as AWS EC2 or Azure). No databases, services or complex setup needed.
❓ Need help? Just want to chat about continuous integration for ML? Visit our Discord channel!
⏯️ Check out our YouTube video series for hands-on MLOps tutorials using CML!
- Setup (GitLab, GitHub, Bitbucket)
- Usage
- Getting started (tutorial)
- Using CML with DVC
- Advanced Setup (Self-hosted, local package)
- Example projects
You'll need a GitLab, GitHub, or Bitbucket account to begin. Users may wish to familiarize themselves with Github Actions or GitLab CI/CD. Here, will discuss the GitHub use case.
Please see our docs on CML with GitLab CI/CD and in particular the personal access token requirement.
Please see our docs on CML with Bitbucket Cloud. Bitbucket Server support estimated to arrive by mid 2021.
The key file in any CML project is .github/workflows/cml.yaml:
name: your-workflow-name
on: [push]
jobs:
run:
runs-on: ubuntu-latest
# optionally use a convenient Ubuntu LTS + CUDA + DVC + CML image
# container: docker://iterativeai/cml:0-dvc2-base1-gpu
# container: docker://ghcr.io/iterative/cml:0-dvc2-base1-gpu
steps:
- uses: actions/checkout@v2
# may need to setup NodeJS & Python3 on e.g. self-hosted
# - uses: actions/setup-node@v2
# with:
# node-version: '12'
# - uses: actions/setup-python@v2
# with:
# python-version: '3.x'
- uses: iterative/setup-cml@v1
- name: Train model
run: |
# Your ML workflow goes here
pip install -r requirements.txt
python train.py
- name: Write CML report
env:
REPO_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
# Post reports as comments in GitHub PRs
cat results.txt >> report.md
cml-send-comment report.mdWe helpfully provide CML and other useful libraries pre-installed on our
custom Docker images.
In the above example, uncommenting the field
container: docker://iterativeai/cml:0-dvc2-base1-gpu (or
container: docker://ghcr.io/iterative/cml:0-dvc2-base1-gpu) will make the
runner pull the CML Docker image. The image already has NodeJS, Python 3, DVC
and CML set up on an Ubuntu LTS base with CUDA libraries and
Terraform installed for convenience.
CML provides a number of functions to help package the outputs of ML workflows (including numeric data and visualizations about model performance) into a CML report.
Below is a table of CML functions for writing markdown reports and delivering those reports to your CI system.
| Function | Description | Example Inputs |
|---|---|---|
cml-runner |
Launch a runner locally or hosted by a cloud provider | See Arguments |
cml-publish |
Publicly host an image for displaying in a CML report | <path to image> --title <image title> --md |
cml-send-comment |
Return CML report as a comment in your GitLab/GitHub workflow | <path to report> --head-sha <sha> |
cml-send-github-check |
Return CML report as a check in GitHub | <path to report> --head-sha <sha> |
cml-pr |
Commit the given files to a new branch and create a pull request | <path>... |
cml-tensorboard-dev |
Return a link to a Tensorboard.dev page | --logdir <path to logs> --title <experiment title> --md |
The cml-send-comment command can be used to post reports. CML reports are
written in markdown (GitHub,
GitLab, or
Bitbucket
flavors). That means they can contain images, tables, formatted text, HTML
blocks, code snippets and more — really, what you put in a CML report is up to
you. Some examples:
🗒️ Text Write to your report using whatever method you prefer. For example, copy the contents of a text file containing the results of ML model training:
cat results.txt >> report.md🖼️ Images Display images using the markdown or HTML. Note that
if an image is an output of your ML workflow (i.e., it is produced by your
workflow), you will need to use the cml-publish function to include it a CML
report. For example, if graph.png is output by python train.py, run:
cml-publish graph.png --md >> report.md- Fork our example project repository.
⚠️ Note that if you are using GitLab, you will need to create a Personal Access Token for this example to work.
⚠️ The following steps can all be done in the GitHub browser interface. However, to follow along with the commands, we recommend cloning your fork to your local workstation:
git clone https://github.com/<your-username>/example_cml- To create a CML workflow, copy the following into a new file,
.github/workflows/cml.yaml:
name: model-training
on: [push]
jobs:
run:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: actions/setup-python@v2
- uses: iterative/setup-cml@v1
- name: Train model
env:
REPO_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
pip install -r requirements.txt
python train.py
cat metrics.txt >> report.md
cml-publish confusion_matrix.png --md >> report.md
cml-send-comment report.md-
In your text editor of choice, edit line 16 of
train.pytodepth = 5. -
Commit and push the changes:
git checkout -b experiment
git add . && git commit -m "modify forest depth"
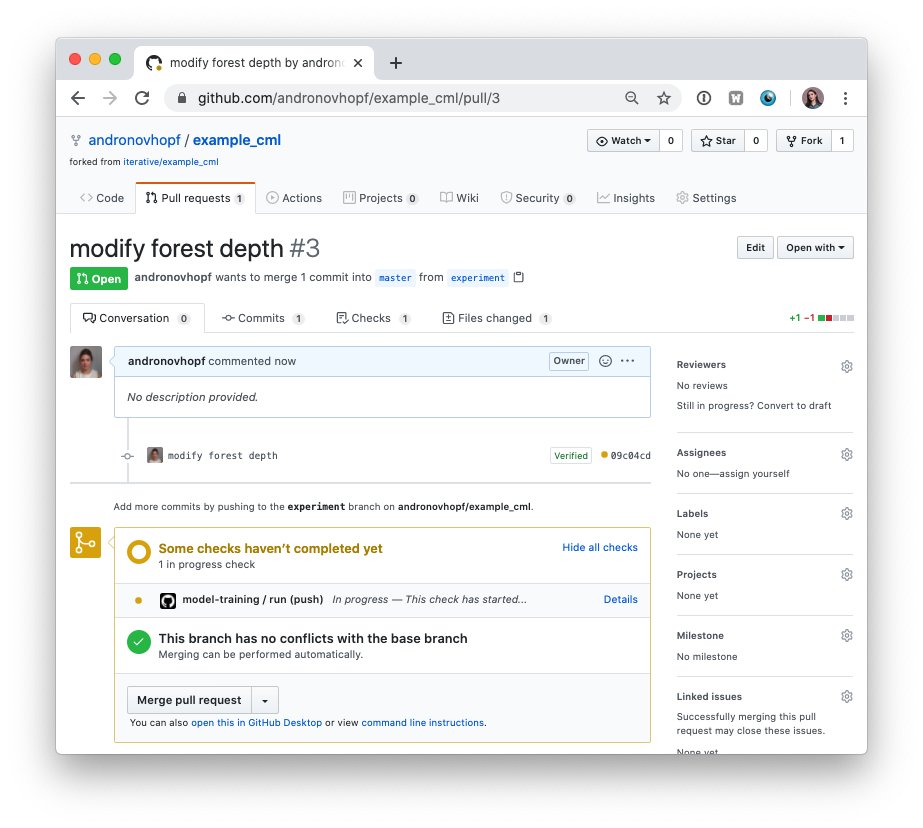
git push origin experiment- In GitHub, open up a pull request to compare the
experimentbranch tomaster.
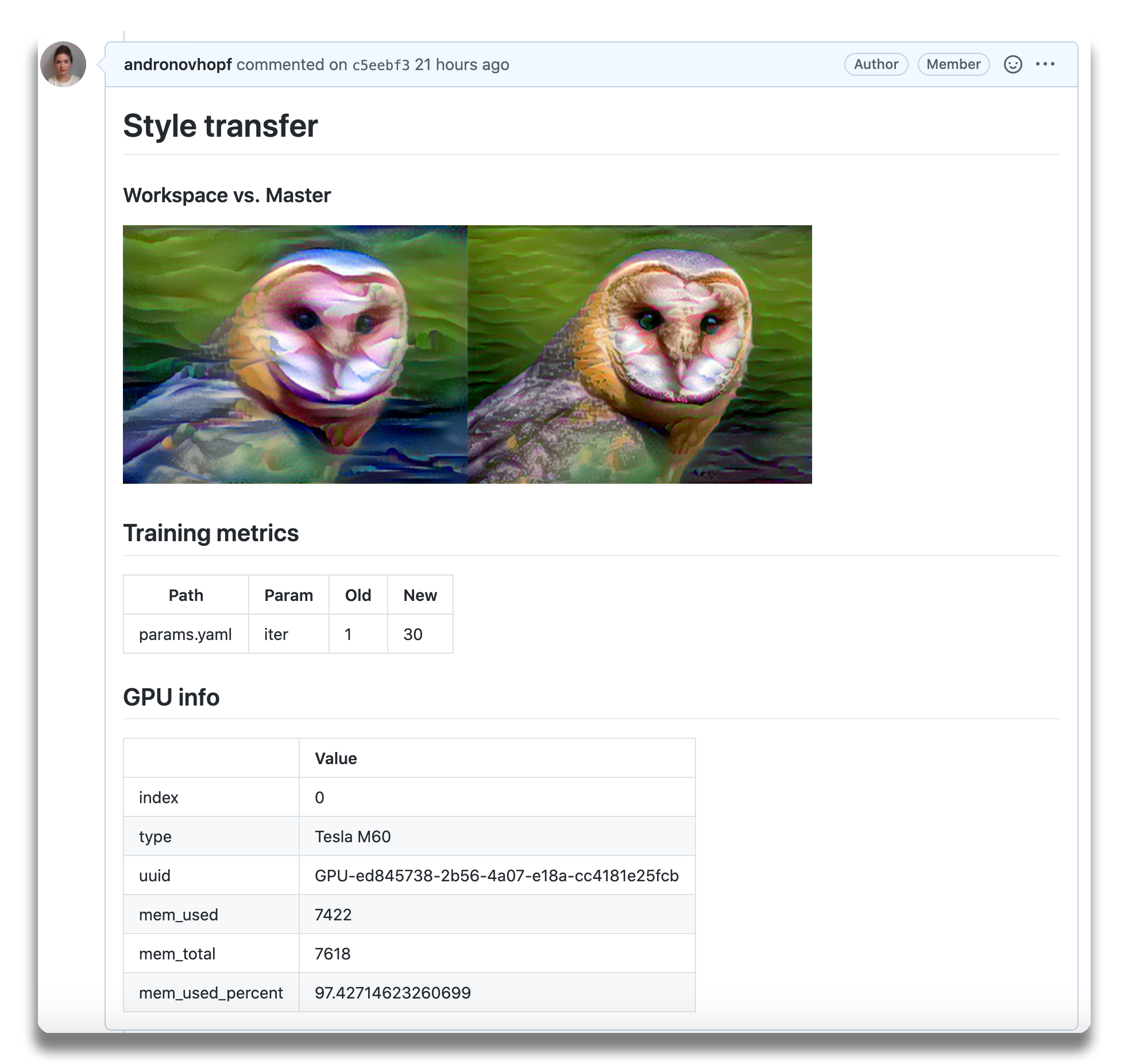
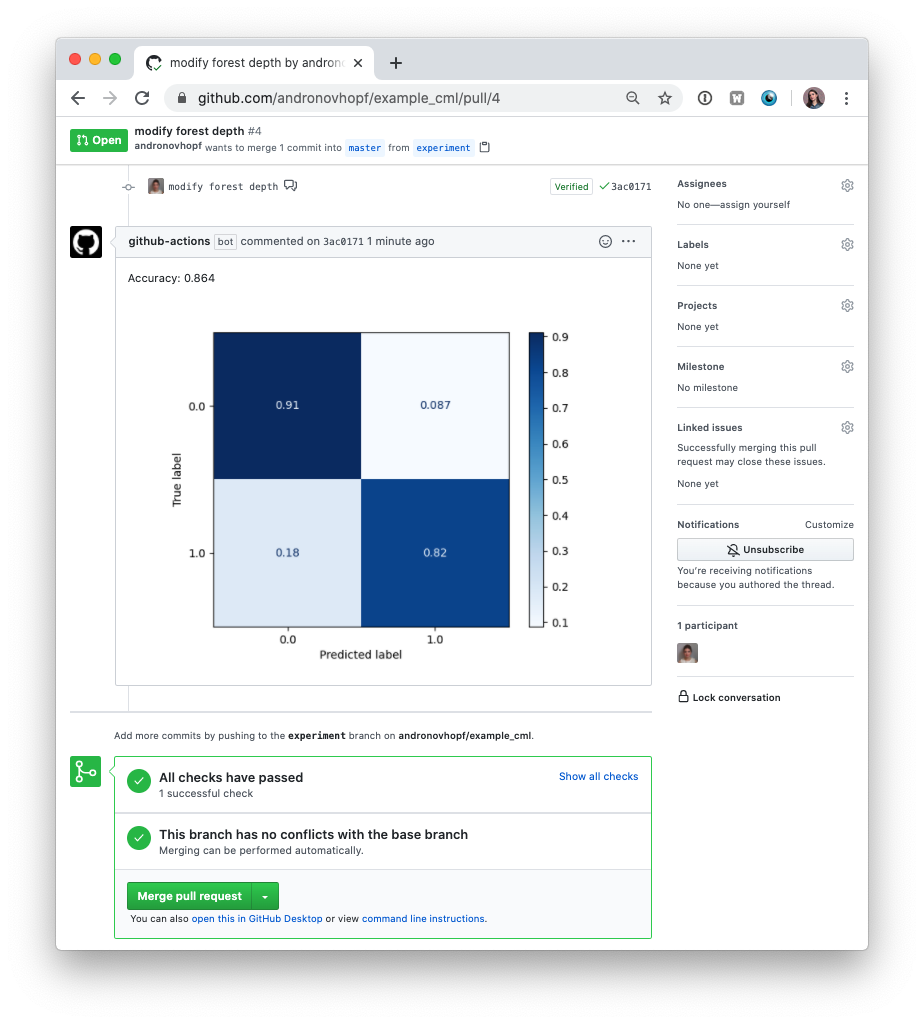
Shortly, you should see a comment from github-actions appear in the pull
request with your CML report. This is a result of the cml-send-comment
function in your workflow.
This is the outline of the CML workflow:
- you push changes to your GitHub repository,
- the workflow in your
.github/workflows/cml.yamlfile gets run, and - a report is generated and posted to GitHub.
CML functions let you display relevant results from the workflow — such as model performance metrics and visualizations — in GitHub checks and comments. What kind of workflow you want to run, and want to put in your CML report, is up to you.
In many ML projects, data isn't stored in a Git repository, but needs to be downloaded from external sources. DVC is a common way to bring data to your CML runner. DVC also lets you visualize how metrics differ between commits to make reports like this:
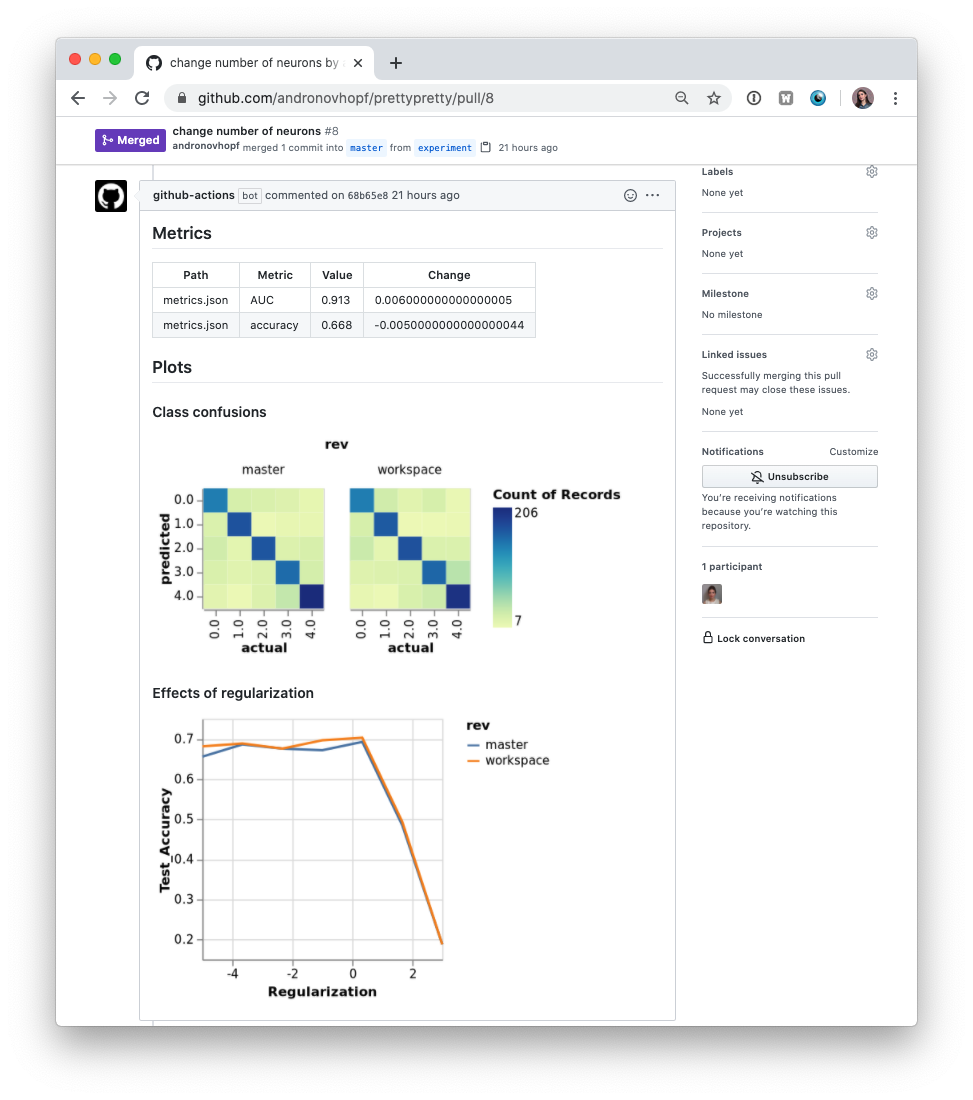
The .github/workflows/cml.yaml file used to create this report is:
name: model-training
on: [push]
jobs:
run:
runs-on: ubuntu-latest
container: docker://ghcr.io/iterative/cml:0-dvc2-base1
steps:
- uses: actions/checkout@v2
- name: Train model
env:
REPO_TOKEN: ${{ secrets.GITHUB_TOKEN }}
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
run: |
# Install requirements
pip install -r requirements.txt
# Pull data & run-cache from S3 and reproduce pipeline
dvc pull data --run-cache
dvc repro
# Report metrics
echo "## Metrics" >> report.md
git fetch --prune
dvc metrics diff master --show-md >> report.md
# Publish confusion matrix diff
echo "## Plots" >> report.md
echo "### Class confusions" >> report.md
dvc plots diff --target classes.csv --template confusion -x actual -y predicted --show-vega master > vega.json
vl2png vega.json -s 1.5 | cml-publish --md >> report.md
# Publish regularization function diff
echo "### Effects of regularization" >> report.md
dvc plots diff --target estimators.csv -x Regularization --show-vega master > vega.json
vl2png vega.json -s 1.5 | cml-publish --md >> report.md
cml-send-comment report.md
⚠️ If you're using DVC with cloud storage, take note of environment variables for your storage format.
There are many supported could storage providers. Here are a few examples for some of the most frequently used providers:
S3 and S3-compatible storage (Minio, DigitalOcean Spaces, IBM Cloud Object Storage...)
# Github
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
AWS_SESSION_TOKEN: ${{ secrets.AWS_SESSION_TOKEN }}👉
AWS_SESSION_TOKENis optional.
👉
AWS_ACCESS_KEY_IDandAWS_SECRET_ACCESS_KEYcan also be used bycml-runnerto launch EC2 instances. See [Environment Variables].
Azure
env:
AZURE_STORAGE_CONNECTION_STRING:
${{ secrets.AZURE_STORAGE_CONNECTION_STRING }}
AZURE_STORAGE_CONTAINER_NAME: ${{ secrets.AZURE_STORAGE_CONTAINER_NAME }}Aliyun
env:
OSS_BUCKET: ${{ secrets.OSS_BUCKET }}
OSS_ACCESS_KEY_ID: ${{ secrets.OSS_ACCESS_KEY_ID }}
OSS_ACCESS_KEY_SECRET: ${{ secrets.OSS_ACCESS_KEY_SECRET }}
OSS_ENDPOINT: ${{ secrets.OSS_ENDPOINT }}Google Storage
⚠️ Normally,GOOGLE_APPLICATION_CREDENTIALSis the path of thejsonfile containing the credentials. However in the action this secret variable is the contents of the file. Copy thejsoncontents and add it as a secret.
env:
GOOGLE_APPLICATION_CREDENTIALS: ${{ secrets.GOOGLE_APPLICATION_CREDENTIALS }}Google Drive
⚠️ After configuring your Google Drive credentials you will find ajsonfile atyour_project_path/.dvc/tmp/gdrive-user-credentials.json. Copy its contents and add it as a secret variable.
env:
GDRIVE_CREDENTIALS_DATA: ${{ secrets.GDRIVE_CREDENTIALS_DATA }}GitHub Actions are run on GitHub-hosted runners by default. However, there are many great reasons to use your own runners: to take advantage of GPUs; to orchestrate your team's shared computing resources, or to access on-premise data.
☝️ Tip! Check out the official GitHub documentation to get started setting up your own self-hosted runner.
When a workflow requires computational resources (such as GPUs), CML can
automatically allocate cloud instances using cml-runner. You can spin up
instances on your AWS or Azure account (GCP & Kubernetes support is
forthcoming!).
For example, the following workflow deploys a t2.micro instance on AWS EC2 and
trains a model on the instance. After the job runs, the instance automatically
shuts down.
You might notice that this workflow is quite similar to the
basic use case above. The only addition is cml-runner and a few
environment variables for passing your cloud service credentials to the
workflow.
Note that cml-runner will also automatically restart your jobs (whether from a
GitHub Actions 72-hour timeout
or a
AWS EC2 spot instance interruption).
name: Train-in-the-cloud
on: [push]
jobs:
deploy-runner:
runs-on: ubuntu-latest
steps:
- uses: iterative/setup-cml@v1
- uses: actions/checkout@v2
- name: Deploy runner on EC2
env:
REPO_TOKEN: ${{ secrets.PERSONAL_ACCESS_TOKEN }}
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
run: |
cml-runner \
--cloud aws \
--cloud-region us-west \
--cloud-type t2.micro \
--labels cml-runner
train-model:
needs: deploy-runner
runs-on: [self-hosted, cml-runner]
container: docker://iterativeai/cml:0-dvc2-base1-gpu
steps:
- uses: actions/checkout@v2
- name: Train model
env:
REPO_TOKEN: ${{ secrets.PERSONAL_ACCESS_TOKEN }}
run: |
pip install -r requirements.txt
python train.py
cat metrics.txt > report.md
cml-send-comment report.mdIn the workflow above, the deploy-runner step launches an EC2 t2-micro
instance in the us-west region. The model-training step then runs on the
newly-launched instance. See [Environment Variables] below for details on the
secrets required.
🎉 Note that you can use any container with this workflow! While you must have CML and its dependencies set up to use functions such
cml-send-commentfrom your instance, you can create your favourite training environment in the cloud by pulling the Docker container of your choice.
We like the CML container (docker://iterativeai/cml) because it comes loaded
with Python, CUDA, git, node and other essentials for full-stack data
science. Different versions of these essentials are available from different
iterativeai/cml image tags. The tag convention is
{CML_VER}-dvc{DVC_VER}-base{BASE_VER}{-gpu}:
{BASE_VER} |
Software included (-gpu) |
|---|---|
| 0 | Ubuntu 18.04, Python 2.7 (CUDA 10.1, CuDNN 7) |
| 1 | Ubuntu 20.04, Python 3.8 (CUDA 11.0.3, CuDNN 8) |
For example, docker://iterativeai/cml:0-dvc2-base1-gpu, or
docker://ghcr.io/iterative/cml:0-dvc2-base1.
The cml-runner function accepts the following arguments:
Usage: cml-runner
Options:
--version Show version number [boolean]
--labels One or more user-defined labels for this runner
(delimited with commas) [default: "cml"]
--idle-timeout Time in seconds for the runner to be waiting for
jobs before shutting down. Setting it to 0
disables automatic shutdown [default: 300]
--name Name displayed in the repository once registered
cml-{ID}
--no-retry Do not restart workflow terminated due to instance
disposal or GitHub Actions timeout
[boolean] [default: false]
--single Exit after running a single job
[boolean] [default: false]
--reuse Don't launch a new runner if an existing one has
the same name or overlapping labels
[boolean] [default: false]
--driver Platform where the repository is hosted. If not
specified, it will be inferred from the
environment [choices: "github", "gitlab"]
--repo Repository to be used for registering the runner.
If not specified, it will be inferred from the
environment
--token Personal access token to register a self-hosted
runner on the repository. If not specified, it
will be inferred from the environment
--cloud Cloud to deploy the runner
[choices: "aws", "azure", "kubernetes"]
--cloud-region Region where the instance is deployed. Choices:
[us-east, us-west, eu-west, eu-north]. Also
accepts native cloud regions [default: "us-west"]
--cloud-type Instance type. Choices: [m, l, xl]. Also supports
native types like i.e. t2.micro
--cloud-gpu GPU type.
[choices: "nogpu", "k80", "v100", "tesla"]
--cloud-hdd-size HDD size in GB
--cloud-ssh-private Custom private RSA SSH key. If not provided an
automatically generated throwaway key will be used
[default: ""]
--cloud-spot Request a spot instance [boolean]
--cloud-spot-price Maximum spot instance bidding price in USD.
Defaults to the current spot bidding price
[default: "-1"]
--cloud-startup-script Run the provided Base64-encoded Linux shell script
during the instance initialization [default: ""]
--cloud-aws-security-group Specifies the security group in AWS [default: ""]
-h Show help [boolean]
⚠️ You will need to create a personal access token (PAT) with repository read/write access and workflow privileges. In the example workflow, this token is stored asPERSONAL_ACCESS_TOKEN.
Note that you will also need to provide access credentials for your cloud
compute resources as secrets. In the above example, AWS_ACCESS_KEY_ID and
AWS_SECRET_ACCESS_KEY (with privileges to create & destroy EC2 instances) are
required.
For AWS, the same credentials can also be used for configuring cloud storage.
This means using on-premise machines as self-hosted runners. The cml-runner
function is used to set up a local self-hosted runner. On your local machine or
on-premise GPU cluster, install CML as a package and then run:
cml-runner \
--repo $your_project_repository_url \
--token $PERSONAL_ACCESS_TOKEN \
--labels tf \
--idle-timeout 180Now your machine will be listening for workflows from your project repository.
In the examples above, CML is installed by the setup-cml action, or comes
pre-installed in a custom Docker image pulled by a CI runner. You can also
install CML as a package:
npm i -g @dvcorg/cmlYou may need to install additional dependencies to use DVC plots and Vega-Lite CLI commands:
sudo apt-get install -y libcairo2-dev libpango1.0-dev libjpeg-dev libgif-dev \
librsvg2-dev libfontconfig-dev
npm install -g vega-cli vega-liteCML and Vega-Lite package installation require the NodeJS package manager
(npm) which ships with NodeJS. Installation instructions are below.
- GitHub: This is probably not necessary when using GitHub's default containers or one of CML's Docker containers. Self-hosted runners may need to use a set up action to install NodeJS:
uses: actions/setup-node@v2
with:
node-version: '12'- GitLab: Requires direct installation.
curl -sL https://deb.nodesource.com/setup_12.x | bash
apt-get update
apt-get install -y nodejsThese are some example projects using CML.
- Basic CML project
- CML with DVC to pull data
- CML with Tensorboard
- CML with a small EC2 instance 🔑
- CML with EC2 GPU 🔑
🔑 needs a PAT.