-
项目概述
本项目是基于flex,bison以及LLVM,使用c++11实现的类C语法编译器,使用flex结合yacc对源代码进行词法、语法分析;在语法分析阶段生成整个源代码相应的抽象语法树后,根据LLVM IR(Intermediate Representation)模块中定义的中间代码语法输出符合LLVM中间语言语法、机器无关的中间代码;最后,本项目通过调用LLVM Back ends模块的接口,根据本地指令集与操作系统架构,将中间代码编译成二进制目标代码。编译生成的目标代码之后可直接编译生成可执行文件,或与其他目标代码链接生成可执行文件。
本项目解析的语法与是C语言的一个子集,但部分语法存在区别,这些将在最后的测试用例中具体说明。目前已支持的数据类型包括:
- void
- int
- float
- double
- char
- string
- bool
- 自定义结构体
- 数组(包括多维数组)
支持的主要语法包括:
- 变量的声明、初始化(包括一维数组初始化,多维数组暂不支持初始化,只能逐个元素赋值使用)
- 函数声明,函数调用(传递参数类型可以是任意已支持类型)
- 外部函数声明和调用
- 控制流语句if-else、for、while及任意层级的嵌套使用
- 单行注释(#)
- 二元运算符、赋值、函数参数的隐式类型转换
- 全局变量的使用
- ...
以上提到的类型和语法均已通过编译成目标代码并生成二进制文件运行测试。
-
相关术语
- LLVM:LLVM是一个自由软件项目,它是一种编译器基础设施,以C++写成。LLVM基于静态单赋值形式(SSA)的编译策略提供了完整编译系统的中间层,它会将中间语言(Intermediate form,IF)从编译器取出与最优化,最优化后的IF接着被转换及链接到目标平台的汇编语言。LLVM支持与语言无关的指令集架构及类型系统。每个在静态单赋值形式(SSA)的指令集代表着,每个变量(被称为具有类型的寄存器)仅被赋值一次,这简化了变量间相依性的分析。LLVM允许代码被静态的编译,包含在传统的GCC系统底下,或是类似JAVA等后期编译才将IF编译成机器码所使用的即时编译(JIT)技术。
- flex:flex(快速词法分析产生器,英语:fast lexical analyzer generator)是一种词法分析程序。它是lex的开放源代码版本,以BSD许可证发布。通常与GNU bison一同运作,但是它本身不是GNU计划的一部分。
- GNU bison:GNU bison是一个自由软件,用于自动生成语法分析器程序,实际上可用于所有常见的操作系统。Bison把LALR形式的上下文无关文法描述转换为可做语法分析的C或C++程序。在新近版本中,Bison增加了对GLR语法分析算法的支持。
-
主要源代码结构
TinyCompiler
├── ASTNodes.h 抽象语法树节点的定义
├── CodeGen.cpp 抽象语法树生成中间代码
├── CodeGen.h
├── Makefile
├── ObjGen.cpp 中间代码生成目标代码
├── ObjGen.h
├── Readme.md
├── TypeSystem.cpp 类型系统实现
├── TypeSystem.h
├── grammar.y 语法分析yacc文件
├── main.cpp TinyCompiler程序入口
├── test.input 用于测试词法、语法、语义分析的源代码
├── testmain.cpp 用于测试链接目标文件的源代码
├── token.l 词法分析lex文件
├── tests 测试用例及结果图
│ ├── testArray.input
│ ├── testArray.png
│ ├── testArrayAST.png
│ ├── testBasic.input
│ ├── testBasic.png
│ ├── testBasicAST.png
│ ├── testStruct.input
│ ├── testStruct.png
│ └── testStructAST.png
└── utils.cpp 通用函数实现 -
运行环境
本项目已在 OSX Sierra 12.1(64位) 以及 Ubuntu LTS 14.04(64位)下,使用LLVM 3.9平台进行测试,测试截图见最后一节。
Windows平台可自行搭建LLVM环境后测试。
-
使用说明
注: 本项目使用LLVM 3.9.0版本的接口,据测试不同版本可能无法直接编译
- 编译TinyCompiler
make- 使用TinyCompiler编译test.c文件,将目标代码输出到output.o
cat test.c | compiler用g++链接output.o生成可执行文件
g++ output.o -o test ./test使用test.input, testmain.cpp文件自动测试编译、链接
make test make testlink -
参考资料
本编译器实现的语法是类似标准C的语法,引入的几个区别包括:
- 去掉了标准C的每个语句后的分号
- 不显式提供指针类型,但可以对变量取地址
- 暂不支持多维数组初始化
- 强制要求写return语句
- 数组初始化列表使用中括号而非大括号
- if-else,for,while等语句强制使用大括号
- ...
基本语法
int func(int a, int b){
if( a > b ){
return func(b * 0.5)
}else if( a == b ){
return func(a * b)
}else{
return 0
}
}
int main(int argc, string[1] argv){
int i = 0
for( ; i<argc; i=i+1){
func(i, argc)
}
while( 1 ){}
return 0
}结构体使用
struct Point{
int x
int y
}
int func(struct Point p){
return p.x
}
int test(){
struct Point p
p.x = 1
p.y = 3
func(p)
return 0
}数组使用
int testArray(){
int[10] oneDim = [1,2,3,4]
int[3][4] twoDim
int i, j
for(i=0; i<3; i=i+1){
for(j=0; j<4; j=j+1){
twoDim[i][j] = 0
}
}
return 0
}外部函数使用
extern int printf(string format)
extern int scanf(string format)
int testExtern(){
string input
scanf("%s", &input)
printf("%d, %f, input = %s", 1, 0.1, input)
return 0
}-
实现方式
词法分析是编译器实现中相对简单的一步。想好所需要实现的语法后,需要将输入转化为一系列的内部标记token。本项目定义的token包括:C语言关键字if、else、return、for、while、struct、int、double、extern等每个关键字对应的token,加减乘除、位运算、括号、逗号、取地址等符号token,以及表示用户自定义的标志符(identifier)的token、数字常量token(整型和浮点数)、字符串常量token等。
我们需要先在yacc源文件grammar.y中声明这些token,并在lex源文件token.l中定义这些token对应的操作,即遇到identifier、数字、字符串等token就将其内容保存到一个string对象中,并返回相应的tokenid以便之后bison程序用来进行语法分析;如果遇到if、else、while或运算符等静态的token就直接返回tokenid。
-
实现方式
语法分析是本项目的关键环节之一。由于源代码是以字符串即字节流的形式存在的,难以进行后续的编译解释工作,因此我们需要将源代码转化成能够反映语法规则的数据结构,即抽象语法树(Abstract Syntax Tree,AST),之后才能利用抽象语法树进行语义分析,中间代码的生成。
抽象语法树实际上就是经过简化和抽象的语法分析树。在完整的语法分析树中每个推导过程的终结符都包含在语法树内,而且每个非终结符都是不同的节点类型。实际上,如果仅仅是要做编译器的话,很多终结符(如关键字、各种标点符号)是无需出现在语法树里的
-
抽象语法树实现
首先我们需要针对每种类型的语法,如变量声明、变量赋值、函数定义、控制流定义等语法定义其相应的抽象语法树,以便能够将任意符合语法标准的源代码都能够转化成一棵抽象语法树。
TinyCompiler支持语言的语法主要可以分为两类,有返回值的Expression——表达式,以及没有返回值的Statement——语句,这样一来所有合法的语法语句都可以归为表达式或语句中的一种。
因此,根据OOP思想,我们只需要定义抽象语法树的根节点Node类,以及两种语法对应的NStatement以及NExpression类,作为所有语法的抽象基类。之后所有语法对应的抽象语法树结点类,如表示For循环语句的NForStatement类,二元运算表达式的NBinaryOperator类,只需要继承这两个类中的一个并实现其接口即可。
现已实现的Expression即表达式类型包括整数、浮点数、变量、二元运算式、函数调用、数组元素、结构体、赋值、字符串,基本块;实现的Statement即语句类型包括变量定义、结构体定义、函数定义、表达式语句、if语句、for语句、数组初始化语句。
为了增强程序的鲁棒性,避免出现内存泄漏,本项目使用C++11提供的shared_ptr智能指针代替所有成员的裸指针,用于维护本语法特有的成员字段。此外,每类AST节点除了要维护这些字段外,还需要实现一个codeGen函数,作为每种语法树生成相应LLVM中间代码的接口。
Node抽象基类节点的定义
class Node { protected: const char m_DELIM = ':'; const char* m_PREFIX = "--"; public: Node(){} virtual ~Node() {} virtual string getTypeName() const = 0; virtual void print(string prefix) const{} virtual llvm::Value *codeGen(CodeGenContext &context) { return (llvm::Value *)0; } };
各个AST结点类的继承关系如下图所示。
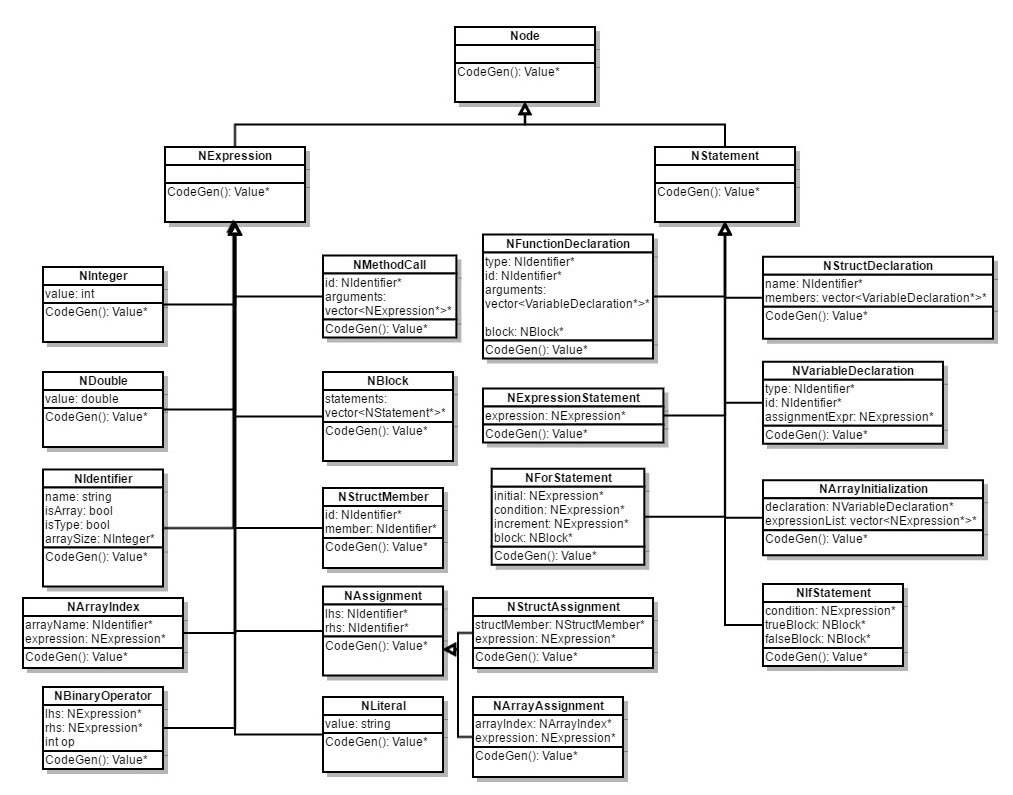
-
bison代码实现
bison(yacc)是基于类似于BNF的语法,使用定义的好终结符和非终结符来组成我们有效的每一个语句和表达式(这些语句和表达式就代表我们之前定义的AST节点)。例如:
if_stmt : TIF expr block { $$ = new NIfStatement(shared_ptr<NExpression>($2), shared_ptr<NBlock>($3)); } | TIF expr block TELSE block { $$ = new NIfStatement(shared_ptr<NExpression>($2), shared_ptr<NBlock>($3), shared_ptr<NBlock>($5)); } | TIF expr block TELSE if_stmt { auto blk = new NBlock(); blk->statements->push_back(shared_ptr<NStatement>($5)); $$ = new NIfStatement(shared_ptr<NExpression>($2), shared_ptr<NBlock>($3), shared_ptr<NBlock>(blk)); }
例子中涉及到的NIfStatement结点的定义:
class NIfStatement: public NStatement{ public: shared_ptr<NExpression> condition; shared_ptr<NBlock> trueBlock; // should not be null shared_ptr<NBlock> falseBlock; // can be null NIfStatement(shared_ptr<NExpression> cond, shared_ptr<NBlock> blk, shared_ptr<NBlock> blk2 = nullptr) : condition(cond), trueBlock(blk), falseBlock(blk2){} string getTypeName() const override { return "NIfStatement"; } void print(string prefix) const override; llvm::Value *codeGen(CodeGenContext &context) override ; };
在该例子中,我们定义了一个if语句,针对每个语法后都注明了相应的语义动作,这个动作将在此条语法被规约(reduce)的时候被执行。 这个过程将会递归地从叶符号到根结点符号的次序执行。在这个过程中,每个非终结符最终会被合并为一棵大的语法树。
例如,遇到
TIF expr block TELSE block类型的语法时,说明解析到一个标准的if-else语法,这时候便调用NIfStatement类的构造函数,同时将所需要的条件表达式($2)以及true和false所要执行的两个block作为函数参数传递进去,生成一个NIfStatement结点的对象后返回给上一层级。
-
实现方式 所谓编程语言的语义,就是一段代码的实际含义。比如最简单的一行代码:a = 1; 它的语义是“将32位整型常量存储到变量a中”。首先我们对“1”有明确的定义,它是32位有符号整型字面量,这里“32位有符号整型”就是表达式“1”的类型。其次,这句话成为合法的编程语言,32位整型常量必须能够隐式转换为a的类型。假设a就是int型变量,那么这条语句就直接将1存储到a所在内存里。如果a是浮点数类型的,那么这句话就隐含着将整型常量转换为浮点类型V的步骤。
在语义分析中,类型检查是贯穿始终的一个步骤。类型检查通常要做到:
- 判定每一个表达式的声明类型
- 判定每一个字段、形式参数、变量声明的类型
- 判断每一次赋值、传参数时,是否存在合法的隐式类型转换
- 判断一元和二元运算符左右两侧的类型是否合法(类型相同或存在隐式转换)
- 将所有要发生的隐式类型转换明确化
在TinyCompiler中,目前暂时使用NIdentifier即标识符对AST结点来存储类型信息(之后可以专门定义表示类型的数据结构用于表达类型)。标识符除了存储其字符串值之外,还使用两个bool变量isType以及isArray来表示该标识符是否为类型标识符,是否为数组类型的标识符。通过在grammar.y文件中定义相应的语义动作,我们实现了语法分析时发现一个标识符是类型标识符而非变量名,那么其isType以及isArray字段将立即被设为true。
NIdentifier定义:
class NIdentifier : public NExpression { public: std::string name; bool isType = false; bool isArray = false; shared_ptr<NInteger> arraySize; NIdentifier(){} NIdentifier(const std::string &name) : name(name), arraySize(nullptr) { } string getTypeName() const override { return "NIdentifier"; } void print(string prefix) const override; virtual llvm::Value* codeGen(CodeGenContext& context) override ; }; -
类型系统实现
在有了能够表达类型的数据结构后,我们便能够通过类型名(name)以及isArray字段判断在一个变量声明语法(NVaraibleDeclaration类)中,变量所使用的类型了。但为了实现判断两种类型之间是否存在可转换的关系,以及以上类型检查所需要的其他操作,我们定义并实现了一个TypeSystem类专门用于存储类型相关、上下文无关的信息,包括各种隐式类型转换关系,是否为结构体,以及结构体各个成员类型等。
TypeSystem类定义:
class TypeSystem{ private: LLVMContext& llvmContext; std::map<string, std::vector<TypeNamePair>> _structMembers; std::map<string, llvm::StructType*> _structTypes; std::map<Type*, std::map<Type*, CastInst::CastOps>> _castTable; void addCast(Type* from, Type* to, CastInst::CastOps op); public: Type* floatTy = Type::getFloatTy(llvmContext); Type* intTy = Type::getInt32Ty(llvmContext); Type* charTy = Type::getInt8Ty(llvmContext); Type* doubleTy = Type::getDoubleTy(llvmContext); Type* stringTy = Type::getInt8PtrTy(llvmContext); Type* voidTy = Type::getVoidTy(llvmContext); Type* boolTy = Type::getInt1Ty(llvmContext); TypeSystem(LLVMContext& context); void addStructType(string structName, llvm::StructType*); void addStructMember(string structName, string memType, string memName); long getStructMemberIndex(string structName, string memberName); Type* getVarType(const NIdentifier& type) ; Type* getVarType(string typeStr) ; Value* getDefaultValue(string typeStr, LLVMContext &context) ; Value* cast(Value* value, Type* type, BasicBlock* block) ; bool isStruct(string typeStr) const; static string llvmTypeToStr(Value* value) ; static string llvmTypeToStr(Type* type) ; };
由于TinyCompiler的后端是基于LLVM实现的,为了便于生成LLVM中间代码,需要将所有前端语言的类型转化为LLVM IR语言支持的类型,如上述定义中所示:float,double,void类型分别转成LLVM内的float,double,void类型,int用32位整数类型表示,char用8位整数类型,bool用1位整数类型,而string则是用8位整数指针类型即相当于char指针类型来表示。
在TypeSystem中,我们使用key-value结构的表castTable存储每个类型之间的类型转换指令,其中key为源类型和目标类型,value则是相应的LLVM IR类型转换指令。我们实现了一个内部调用的接口addCast,以便在TypeSystem的构造函数中调用来设定哪些类型存在隐式转换,并将其添加到castTable中。
TypeSystem::TypeSystem(LLVMContext &context): llvmContext(context){ addCast(intTy, floatTy, llvm::CastInst::SIToFP); addCast(intTy, doubleTy, llvm::CastInst::SIToFP); addCast(boolTy, doubleTy, llvm::CastInst::SIToFP); addCast(floatTy, doubleTy, llvm::CastInst::FPExt); addCast(floatTy, intTy, llvm::CastInst::FPToSI); addCast(doubleTy, intTy, llvm::CastInst::FPToSI); addCast(boolTy, intTy, llvm::CastInst::SExt); }
如上所示,默认支持的隐式转换包括int->float,int->double,bool->double,float->double,float->int,double->int,bool->int。
此外,TypeSystem另一个重要的接口即cast函数,用于提供某个表达式的值向另一类型的转换指令。若两种类型不存在转换关系时,则输出错误信息并返回源类型的值。
Value* TypeSystem::cast(Value *value, Type *type, BasicBlock *block) { Type* from = value->getType(); if( from == type ) return value; if( _castTable.find(from) == _castTable.end() ){ LogError("Type has no cast"); return value; } if( _castTable[from].find(type) == _castTable[from].end() ){ string error = "Unable to cast from "; error += llvmTypeToStr(from) + " to " + llvmTypeToStr(type); LogError(error.c_str()); return value; } return CastInst::Create(_castTable[from][type], value, type, "cast", block); }
-
变量类型检查
TypeSystem维护的只是整个语言的类型信息,但类型检查还需要知道每一条语句中涉及的变量具体类型及在该语句中的使用是否合法,因此我们需要维护额外的数据来进行这一工作。在c语言中变量的作用域是以大括号划分的,每组大括号内部作为一个block能够访问其内部定义的局部变量,也能访问包含其block的外部block中定义的变量。
为了实现这一功能,我们定义了一个用于表示每个block的类CodeGenBlock,内部维护的信息包括这一层block的局部变量,局部变量的类型,以及该变量是否为函数参数(主要是因为对于函数参数传递过来的数组要当做指针处理)等,如下所示。
class CodeGenBlock{ public: BasicBlock * block; Value * returnValue; std::map<string, Value*> locals; std::map<string, shared_ptr<NIdentifier>> types; // type name string of vars std::map<string, bool> isFuncArg; };
此外,还需要在整个编译器程序中使用一个单例的CodeGenContext对象维护全局的编译信息。在这个对象中主要维护的成员包括处理CodeGenBlock时所用到的栈blockStack,全局变量表globalVars以及类型系统单例typeSystem,以及之后生成中间代码时需要用到的LLVM提供的相关对象。
class CodeGenContext{ private: std::vector<CodeGenBlock*> blockStack; public: LLVMContext llvmContext; IRBuilder<> builder; unique_ptr<Module> theModule; SymTable globalVars; TypeSystem typeSystem; ... // functions }
这样一来在进行类型检查时,我们便可以通过让CodeGenContext从栈顶开始�遍历每个block的types表来查询某个变量的具体类型。这样也能够保证在变量名有冲突的情况下,能够正确的返回最近的block中定义的变量,符合c语言的编译处理规则。
类型检查示例(数组元素表达式)
llvm::Value *NArrayIndex::codeGen(CodeGenContext &context) { cout << "Generating array index expression of " << this->arrayName->name << endl; auto varPtr = context.getSymbolValue(this->arrayName->name); auto type = context.getSymbolType(this->arrayName->name); string typeStr = type->name; assert(type->isArray); ...
-
实现方式
编译器的下一步自然就是将抽象语法树转化生成某种类型的中间代码。在LLVM提供的接口下实现中间代码的生成比较优雅,因为LLVM将真实的指令抽象成了类似AST的指令,因此我们能够很方便的将AST的树形结构生成线性的中间代码。
可以想象这个过程是从抽象语法树的根节点开始遍历每一个树上节点并产生中间代码的过程。这一工作就是通过在各个AST节点类中实现在Node中定义的codeGen方法来实现的。例如,当我们遍历NBlock代码的时候(语义上NBlock代表一组我们语言的语句的集合),我们将调用列表中每条语句的codeGen方法。每种AST节点的Codegen()方法负责生成该类型AST节点的IR代码及其他必要信息,生成的内容以LLVM Value对象指针的形式返回。LLVM用“Value”类表示“静态一次性赋值(SSA,Static Single Assignment)寄存器”或“SSA值”。SSA值最为突出的特点就在于“固定不变”:SSA值经由对应指令运算得出后便固定下来,直到该指令再次执行之前都不可修改。详情请参考Static Single Assignment
我们将实现抽象语法树上所有节点的codeGen方法,然后在向下遍历树的时候调用它,并隐式的遍历我们整个抽象语法树。在这个过程中,我们在CodeGenContext类来告诉我们生成中间代码的位置。
-
实现细节
由于各个结点实现codeGen方法的方式大同小异,因此这里只用几个具有代表性的实现来解释生成方法。
生成NBlock的过程如下所示:
llvm::Value* NBlock::codeGen(CodeGenContext &context) { cout << "Generating block" << endl; Value* last = nullptr; for(auto it=this->statements->begin(); it!=this->statements->end(); it++){ last = (*it)->codeGen(context); } return last; }
可以清楚的看出NBlock中间代码的生成过程就是调用其内部的语句列表(Statements)中每个语句的codeGen生成对应的中间代码,并将最后一个语句(Return语句)的SSA值作为该结点的值返回。
NIdentifier 标识符AST结点
llvm::Value* NIdentifier::codeGen(CodeGenContext &context) { cout << "Generating identifier " << this->name << endl; Value* value = context.getSymbolValue(this->name); if( !value ){ return LogErrorV("Unknown variable name " + this->name); } if( value->getType()->isPointerTy() ){ auto arrayPtr = context.builder.CreateLoad(value, "arrayPtr"); if( arrayPtr->getType()->isArrayTy() ){ cout << "(Array Type)" << endl; std::vector<Value*> indices; indices.push_back(ConstantInt::get(context.�typeSystem.intTy, 0, false)); auto ptr = context.builder.CreateInBoundsGEP(value, indices, "arrayPtr"); return ptr; } } return context.builder.CreateLoad(value, false, ""); }
标识符表达式主要用于引用有变量名的表达式中,其语义即为取出变量对应的值。对于普通变量则是直接从当前block的符号表中通过
getSymbolValue先取出其存储地址,然后通过CreateLoad创建一条Load指令将变量值取出来并返回寄存器的地址给调用者 -
LLVM中间代码语法 格式样例
源代码:
int main() { int a,i; for(i=0;i<10;i++){ a=a*2; } }
对应LLVM中间代码:
; ModuleID = 'testmain.cpp' source_filename = "testmain.cpp" target datalayout = "e-m:o-i64:64-f80:128-n8:16:32:64-S128" target triple = "x86_64-apple-macosx10.12.0" define i32 @main() nounwind { entry: %retval = alloca i32, align 4 %i = alloca i32, align 4 %a = alloca i32, align 4 store i32 0, i32* %retval store i32 0, i32* %i, align 4 br label %for.cond for.cond: ; preds = %for.inc, %entry %0 = load i32* %i, align 4 %cmp = icmp slt i32 %0, 10 br i1 %cmp, label %for.body, label %for.end for.body: ; preds = %for.cond %1 = load i32* %a, align 4 %mul = mul nsw i32 %1, 2 store i32 %mul, i32* %a, align 4 br label %for.inc for.inc: ; preds = %for.body %2 = load i32* %i, align 4 %inc = add nsw i32 %2, 1 store i32 %inc, i32* %i, align 4 br label %for.cond for.end: ; preds = %for.cond %3 = load i32* %retval ret i32 %3 }
-
实现方式
LLVM中的平台无关代码生成器(Code Generator),同时也是一个编译器开发 框架(Framework)。它提供了一些可复用的组件,帮助用户将LLVM IR编译到特定的平台上。
LLVM平台描述相关的类(Target Description Classes) 为不同的平台提供了相同的抽象接口。这些类在设计上仅用来表达目标平台的属性,例如平台所支持的指令和寄存器,但不会保存任何和具体算法相关的描述。在本项目中主要使用到的是:
-
TargetMachine
TargetMachine类提供了一组虚方法以获得具体的平台描述。这组函数一般都命名成get*Info,如getInstrInfo,getRegisterInfo,getFrameInfo。TargetMachine也是通过子类提供平台相关的实现(如X86TargetMachine)。如果只是想实现一个能被LLVM支持的最简单的TargetMachine,那只要能返回DataLayout,如果你使用了LLVM其他的代码生成组件,那就需要实现诸如getInstrInfo等其他的接口函数。 -
DataLayout
所有平台描述类中,只有
DataLayout是必须要支持的,同时它也是唯一一个不能被继承的类。DataLayout保存了 结构体成员的内存布局 、不同类型的数据的内存对齐、指针大小还有Little Endian/Big Endian等诸多信息。
所有的平台描述类除了DataLayout外都是可以被继承的,用户可以根据不同的平台提供具体的子类。这些子类通过重载接口的虚函数来提供平台信息。TargetMachine类提供了一组接口,可以访问这些描述(在实现细节部分的代码中使用)。
-
-
实现细节
- (根据本地运行环境)初始化生成目标代码的TargetMachine
InitializeAllTargetInfos(); InitializeAllTargets(); InitializeAllTargetMCs(); InitializeAllAsmParsers(); InitializeAllAsmPrinters();
- 获取并设置当前环境的target triple(如"x86_64-apple-darwin16.1.0")
auto targetTriple = sys::getDefaultTargetTriple(); context.theModule->setTargetTriple(targetTriple);
- 获取并设置TargetMachine信息
auto CPU = "generic"; auto features = ""; TargetOptions opt; auto RM = Optional<Reloc::Model>(); auto theTargetMachine = Target->createTargetMachine(targetTriple, CPU, features, opt, RM); context.theModule->setDataLayout(theTargetMachine->createDataLayout()); context.theModule->setTargetTriple(targetTriple);
- 将目标代码输出到文件
std::error_code EC; raw_fd_ostream dest(filename.c_str(), EC, sys::fs::F_None); legacy::PassManager pass; auto fileType = TargetMachine::CGFT_ObjectFile; if( theTargetMachine->addPassesToEmitFile(pass, dest, fileType) ){ errs() << "theTargetMachine can't emit a file of this type"; return; } pass.run(*context.theModule.get()); dest.flush();
- 基本语法
测试代码
extern int printf(string format)
extern int puts(string s)
int func(int a, int b){
int res = 0
if( a <= 1 ) {
res = 1
}else if( 1 ){
res = func(a-1, b) + func(a-2, b)
}else{
res = func(b, a)
}
return res
}
int main(int argc, string[1] argv){
int i
argc = 5
for( i = 1 ; i<argc; i=i+1){
printf("i=%d, func=%d", i, func(i, argc))
puts("")
}
return 0
}抽象语法树

中间代码
; ModuleID = 'main'
source_filename = "main"
@string = private unnamed_addr constant [14 x i8] c"i=%d, func=%d\00"
@string.1 = private unnamed_addr constant [1 x i8] zeroinitializer
declare i32 @printf(i8*)
declare i32 @puts(i8*)
define i32 @func(i32 %a, i32 %b) {
entry:
%0 = alloca i32
store i32 %a, i32* %0
%1 = alloca i32
store i32 %b, i32* %1
%2 = alloca i32
store i32 0, i32* %2
%arrayPtr = load i32, i32* %0
%3 = load i32, i32* %0
%cmptmp = icmp sle i32 %3, 1
%4 = icmp ne i1 %cmptmp, false
br i1 %4, label %then, label %else
then: ; preds = %entry
store i32 1, i32* %2
br label %ifcont12
else: ; preds = %entry
br i1 true, label %then1, label %else8
then1: ; preds = %else
%arrayPtr2 = load i32, i32* %0
%5 = load i32, i32* %0
%subtmp = sub i32 %5, 1
%arrayPtr3 = load i32, i32* %1
%6 = load i32, i32* %1
%calltmp = call i32 @func(i32 %subtmp, i32 %6)
%arrayPtr4 = load i32, i32* %0
%7 = load i32, i32* %0
%subtmp5 = sub i32 %7, 2
%arrayPtr6 = load i32, i32* %1
%8 = load i32, i32* %1
%calltmp7 = call i32 @func(i32 %subtmp5, i32 %8)
%addtmp = add i32 %calltmp, %calltmp7
store i32 %addtmp, i32* %2
br label %ifcont
else8: ; preds = %else
%arrayPtr9 = load i32, i32* %1
%9 = load i32, i32* %1
%arrayPtr10 = load i32, i32* %0
%10 = load i32, i32* %0
%calltmp11 = call i32 @func(i32 %9, i32 %10)
store i32 %calltmp11, i32* %2
br label %ifcont
ifcont: ; preds = %else8, %then1
br label %ifcont12
ifcont12: ; preds = %ifcont, %then
%arrayPtr13 = load i32, i32* %2
%11 = load i32, i32* %2
ret i32 %11
}
define i32 @main(i32 %argc, i8** %argv) {
entry:
%0 = alloca i32
store i32 %argc, i32* %0
%1 = alloca i8**
store i8** %argv, i8*** %1
%2 = alloca i32
store i32 5, i32* %0
%arrayPtr = load i32, i32* %2
%3 = load i32, i32* %2
%arrayPtr1 = load i32, i32* %0
%4 = load i32, i32* %0
%cmptmp = icmp ult i32 %3, %4
%5 = icmp ne i1 %cmptmp, false
store i32 1, i32* %2
br i1 %5, label %forloop, label %forcont
forloop: ; preds = %forloop, %entry
%arrayPtr2 = load i32, i32* %2
%6 = load i32, i32* %2
%arrayPtr3 = load i32, i32* %2
%7 = load i32, i32* %2
%arrayPtr4 = load i32, i32* %0
%8 = load i32, i32* %0
%calltmp = call i32 @func(i32 %7, i32 %8)
%calltmp5 = call i32 @printf([14 x i8]* @string, i32 %6, i32 %calltmp)
%calltmp6 = call i32 @puts([1 x i8]* @string.1)
%arrayPtr7 = load i32, i32* %2
%9 = load i32, i32* %2
%addtmp = add i32 %9, 1
store i32 %addtmp, i32* %2
%arrayPtr8 = load i32, i32* %2
%10 = load i32, i32* %2
%arrayPtr9 = load i32, i32* %0
%11 = load i32, i32* %0
%cmptmp10 = icmp ult i32 %10, %11
%12 = icmp ne i1 %cmptmp10, false
br i1 %12, label %forloop, label %forcont
forcont: ; preds = %forloop, %entry
ret i32 0
}
运行结果
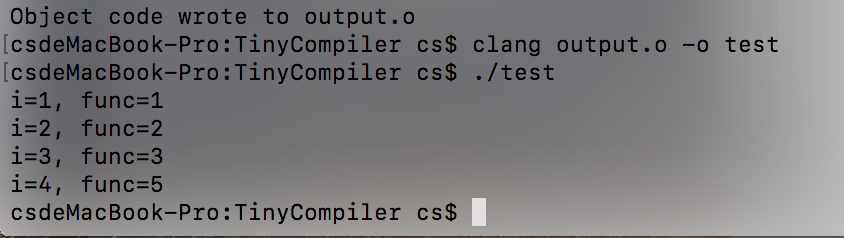
- 结构体使用
struct Point{
int x
int y
}
int func(struct Point p){
return p.x
}
int test(){
struct Point p
p.x = 1
p.y = 3
func(p)
return 0
}抽象语法树可视化

中间代码
; ModuleID = 'main'
source_filename = "main"
%Point = type { i32, i32 }
@string = private unnamed_addr constant [3 x i8] c"%s\00"
@string.1 = private unnamed_addr constant [8 x i8] c"%s = %d\00"
declare i32 @printf(i8*)
declare i32 @scanf(i8*)
define i32 @func(%Point %p) {
entry:
%0 = alloca %Point
store %Point %p, %Point* %0
%structPtr = load %Point, %Point* %0, align 4
%memberPtr = getelementptr inbounds %Point, %Point* %0, i32 0, i32 0
%1 = load i32, i32* %memberPtr
ret i32 %1
}
define i32 @main() {
entry:
%0 = alloca %Point
%arraytmp = alloca [32 x i8], i32 32
%arrayPtr = load [32 x i8], [32 x i8]* %arraytmp
%arrayPtr1 = getelementptr inbounds [32 x i8], [32 x i8]* %arraytmp, i32 0
%calltmp = call i32 @scanf([3 x i8]* @string, [32 x i8]* %arrayPtr1)
%arrayPtr2 = load [32 x i8], [32 x i8]* %arraytmp
%arrayPtr3 = getelementptr inbounds [32 x i8], [32 x i8]* %arraytmp, i32 0
%arrayPtr4 = load %Point, %Point* %0
%1 = load %Point, %Point* %0
%calltmp5 = call i32 @func(%Point %1)
%calltmp6 = call i32 @printf([8 x i8]* @string.1, [32 x i8]* %arrayPtr3, i32 %calltmp5)
ret i32 0
}
运行结果

- 数组使用
extern int printf(string str)
extern int puts(string str)
int main(){
int[13] arr = [ 1,2,3,4,5,6,7,8,9,10,11,12 ]
int[3][4] arr2
int i
int j
for(i=0; i<3; i=i+1){
for(j=0; j<4; j=j+1){
arr2[i][j] = arr[i*4+j]
}
}
for(i=0; i<3; i=i+1){
for(j=0; j<4; j=j+1){
printf("%d,", arr2[i][j])
}
puts("")
}
return 0
}抽象语法树可视化
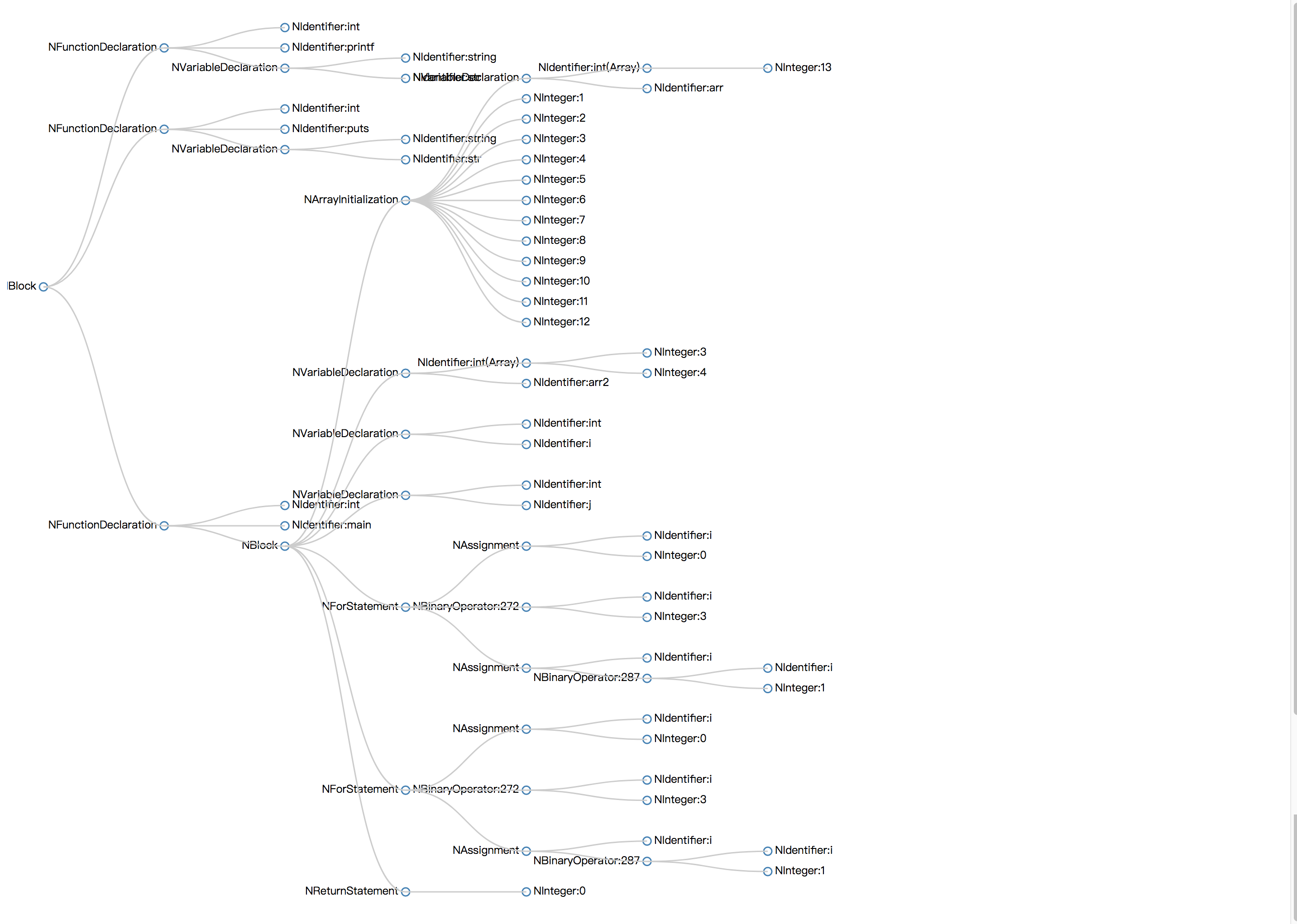
中间代码
; ModuleID = 'main'
source_filename = "main"
@string = private unnamed_addr constant [4 x i8] c"%d,\00"
@string.1 = private unnamed_addr constant [1 x i8] zeroinitializer
declare i32 @printf(i8*)
declare i32 @puts(i8*)
define i32 @main() {
entry:
%arraytmp = alloca [13 x i32], i32 13
%arrayPtr = load [13 x i32], [13 x i32]* %arraytmp
%elementPtr = getelementptr inbounds [13 x i32], [13 x i32]* %arraytmp, i64 0, i32 0
store i32 1, i32* %elementPtr, align 4
%arrayPtr1 = load [13 x i32], [13 x i32]* %arraytmp
%elementPtr2 = getelementptr inbounds [13 x i32], [13 x i32]* %arraytmp, i64 0, i32 1
store i32 2, i32* %elementPtr2, align 4
%arrayPtr3 = load [13 x i32], [13 x i32]* %arraytmp
%elementPtr4 = getelementptr inbounds [13 x i32], [13 x i32]* %arraytmp, i64 0, i32 2
store i32 3, i32* %elementPtr4, align 4
%arrayPtr5 = load [13 x i32], [13 x i32]* %arraytmp
%elementPtr6 = getelementptr inbounds [13 x i32], [13 x i32]* %arraytmp, i64 0, i32 3
store i32 4, i32* %elementPtr6, align 4
%arrayPtr7 = load [13 x i32], [13 x i32]* %arraytmp
%elementPtr8 = getelementptr inbounds [13 x i32], [13 x i32]* %arraytmp, i64 0, i32 4
store i32 5, i32* %elementPtr8, align 4
%arrayPtr9 = load [13 x i32], [13 x i32]* %arraytmp
%elementPtr10 = getelementptr inbounds [13 x i32], [13 x i32]* %arraytmp, i64 0, i32 5
store i32 6, i32* %elementPtr10, align 4
%arrayPtr11 = load [13 x i32], [13 x i32]* %arraytmp
%elementPtr12 = getelementptr inbounds [13 x i32], [13 x i32]* %arraytmp, i64 0, i32 6
store i32 7, i32* %elementPtr12, align 4
%arrayPtr13 = load [13 x i32], [13 x i32]* %arraytmp
%elementPtr14 = getelementptr inbounds [13 x i32], [13 x i32]* %arraytmp, i64 0, i32 7
store i32 8, i32* %elementPtr14, align 4
%arrayPtr15 = load [13 x i32], [13 x i32]* %arraytmp
%elementPtr16 = getelementptr inbounds [13 x i32], [13 x i32]* %arraytmp, i64 0, i32 8
store i32 9, i32* %elementPtr16, align 4
%arrayPtr17 = load [13 x i32], [13 x i32]* %arraytmp
%elementPtr18 = getelementptr inbounds [13 x i32], [13 x i32]* %arraytmp, i64 0, i32 9
store i32 10, i32* %elementPtr18, align 4
%arrayPtr19 = load [13 x i32], [13 x i32]* %arraytmp
%elementPtr20 = getelementptr inbounds [13 x i32], [13 x i32]* %arraytmp, i64 0, i32 10
store i32 11, i32* %elementPtr20, align 4
%arrayPtr21 = load [13 x i32], [13 x i32]* %arraytmp
%elementPtr22 = getelementptr inbounds [13 x i32], [13 x i32]* %arraytmp, i64 0, i32 11
store i32 12, i32* %elementPtr22, align 4
%arraytmp23 = alloca [12 x i32], i32 12
%0 = alloca i32
%1 = alloca i32
store i32 0, i32* %0
%arrayPtr24 = load i32, i32* %0
%2 = load i32, i32* %0
%cmptmp = icmp ult i32 %2, 3
%3 = icmp ne i1 %cmptmp, false
br i1 %3, label %forloop, label %forcont45
forloop: ; preds = %forcont, %entry
store i32 0, i32* %1
%arrayPtr26 = load i32, i32* %1
%4 = load i32, i32* %1
%cmptmp27 = icmp ult i32 %4, 4
%5 = icmp ne i1 %cmptmp27, false
br i1 %5, label %forloop25, label %forcont
forloop25: ; preds = %forloop25, %forloop
%arrayPtr28 = load [12 x i32], [12 x i32]* %arraytmp23
%arrayPtr29 = load i32, i32* %0
%6 = load i32, i32* %0
%multmp = mul i32 4, %6
%arrayPtr30 = load i32, i32* %1
%7 = load i32, i32* %1
%addtmp = add i32 %multmp, %7
%elementPtr31 = getelementptr inbounds [12 x i32], [12 x i32]* %arraytmp23, i64 0, i32 %addtmp
%arrayPtr32 = load i32, i32* %0
%8 = load i32, i32* %0
%multmp33 = mul i32 %8, 4
%arrayPtr34 = load i32, i32* %1
%9 = load i32, i32* %1
%addtmp35 = add i32 %multmp33, %9
%elementPtr36 = getelementptr inbounds [13 x i32], [13 x i32]* %arraytmp, i64 0, i32 %addtmp35
%10 = load i32, i32* %elementPtr36, align 4
store i32 %10, i32* %elementPtr31, align 4
%arrayPtr37 = load i32, i32* %1
%11 = load i32, i32* %1
%addtmp38 = add i32 %11, 1
store i32 %addtmp38, i32* %1
%arrayPtr39 = load i32, i32* %1
%12 = load i32, i32* %1
%cmptmp40 = icmp ult i32 %12, 4
%13 = icmp ne i1 %cmptmp40, false
br i1 %13, label %forloop25, label %forcont
forcont: ; preds = %forloop25, %forloop
%arrayPtr41 = load i32, i32* %0
%14 = load i32, i32* %0
%addtmp42 = add i32 %14, 1
store i32 %addtmp42, i32* %0
%arrayPtr43 = load i32, i32* %0
%15 = load i32, i32* %0
%cmptmp44 = icmp ult i32 %15, 3
%16 = icmp ne i1 %cmptmp44, false
br i1 %16, label %forloop, label %forcont45
forcont45: ; preds = %forcont, %entry
store i32 0, i32* %0
%arrayPtr47 = load i32, i32* %0
%17 = load i32, i32* %0
%cmptmp48 = icmp ult i32 %17, 3
%18 = icmp ne i1 %cmptmp48, false
br i1 %18, label %forloop46, label %forcont67
forloop46: ; preds = %forcont61, %forcont45
store i32 0, i32* %1
%arrayPtr50 = load i32, i32* %1
%19 = load i32, i32* %1
%cmptmp51 = icmp ult i32 %19, 4
%20 = icmp ne i1 %cmptmp51, false
br i1 %20, label %forloop49, label %forcont61
forloop49: ; preds = %forloop49, %forloop46
%arrayPtr52 = load i32, i32* %0
%21 = load i32, i32* %0
%multmp53 = mul i32 4, %21
%arrayPtr54 = load i32, i32* %1
%22 = load i32, i32* %1
%addtmp55 = add i32 %multmp53, %22
%elementPtr56 = getelementptr inbounds [12 x i32], [12 x i32]* %arraytmp23, i64 0, i32 %addtmp55
%23 = load i32, i32* %elementPtr56, align 4
%calltmp = call i32 @printf([4 x i8]* @string, i32 %23)
%arrayPtr57 = load i32, i32* %1
%24 = load i32, i32* %1
%addtmp58 = add i32 %24, 1
store i32 %addtmp58, i32* %1
%arrayPtr59 = load i32, i32* %1
%25 = load i32, i32* %1
%cmptmp60 = icmp ult i32 %25, 4
%26 = icmp ne i1 %cmptmp60, false
br i1 %26, label %forloop49, label %forcont61
forcont61: ; preds = %forloop49, %forloop46
%calltmp62 = call i32 @puts([1 x i8]* @string.1)
%arrayPtr63 = load i32, i32* %0
%27 = load i32, i32* %0
%addtmp64 = add i32 %27, 1
store i32 %addtmp64, i32* %0
%arrayPtr65 = load i32, i32* %0
%28 = load i32, i32* %0
%cmptmp66 = icmp ult i32 %28, 3
%29 = icmp ne i1 %cmptmp66, false
br i1 %29, label %forloop46, label %forcont67
forcont67: ; preds = %forcont61, %forcont45
ret i32 0
}
运行结果
