Load data from  to
to  , the fastest way.
, the fastest way.
ConnectorX enables you to load data from databases into Python in the fastest and most memory efficient way.
What you need is one line of code:
import connectorx as cx
cx.read_sql("postgresql://username:password@server:port/database", "SELECT * FROM lineitem")Optionally, you can accelerate the data loading using parallelism by specifying a partition column.
import connectorx as cx
cx.read_sql("postgresql://username:password@server:port/database", "SELECT * FROM lineitem", partition_on="l_orderkey", partition_num=10)The function will partition the query by evenly splitting the specified column to the amount of partitions. ConnectorX will assign one thread for each partition to load and write data in parallel. Currently, we support partitioning on numerical columns (cannot contain NULL) for SPJA queries.
Experimental: We are now providing federated query support, you can write a single query to join tables from two or more databases!
import connectorx as cx
db1 = "postgresql://username1:password1@server1:port1/database1"
db2 = "postgresql://username2:password2@server2:port2/database2"
cx.read_sql({"db1": db1, "db2": db2}, "SELECT * FROM db1.nation n, db2.region r where n.n_regionkey = r.r_regionkey")By default, we pushdown all joins from the same data source. More details for setup and configuration can be found here.
Check out more detailed usage and examples here. A general introduction of the project can be found in this blog post.
pip install connectorxCheck out here to see how to build python wheel from source.
We compared different solutions in Python that provides the read_sql function, by loading a 10x TPC-H lineitem table (8.6GB) from Postgres into a DataFrame, with 4 cores parallelism.
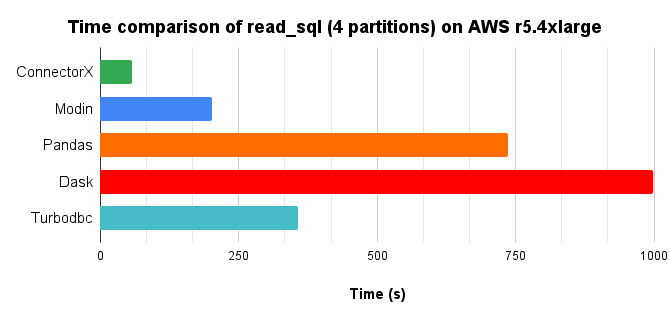
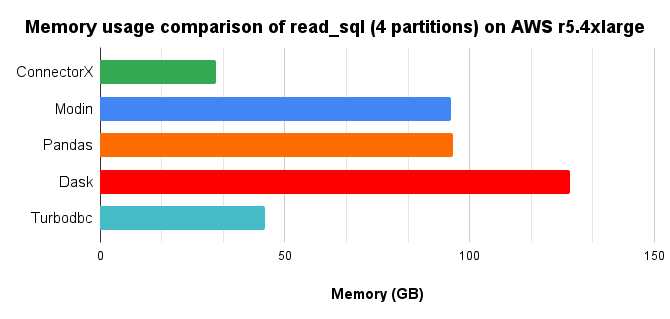
In conclusion, ConnectorX uses up to 3x less memory and 21x less time (3x less memory and 13x less time compared with Pandas.). More on here.
We observe that existing solutions more or less do data copy multiple times when downloading the data. Additionally, implementing a data intensive application in Python brings additional cost.
ConnectorX is written in Rust and follows "zero-copy" principle. This allows it to make full use of the CPU by becoming cache and branch predictor friendly. Moreover, the architecture of ConnectorX ensures the data will be copied exactly once, directly from the source to the destination.
Upon receiving the query, e.g. SELECT * FROM lineitem, ConnectorX will first issue a LIMIT 1 query SELECT * FROM lineitem LIMIT 1 to get the schema of the result set.
Then, if partition_on is specified, ConnectorX will issue SELECT MIN($partition_on), MAX($partition_on) FROM (SELECT * FROM lineitem) to know the range of the partition column.
After that, the original query is split into partitions based on the min/max information, e.g. SELECT * FROM (SELECT * FROM lineitem) WHERE $partition_on > 0 AND $partition_on < 10000.
ConnectorX will then run a count query to get the partition size (e.g. SELECT COUNT(*) FROM (SELECT * FROM lineitem) WHERE $partition_on > 0 AND $partition_on < 10000). If the partition
is not specified, the count query will be SELECT COUNT(*) FROM (SELECT * FROM lineitem).
Finally, ConnectorX will use the schema info as well as the count info to allocate memory and download data by executing the queries normally.
Once the downloading begins, there will be one thread for each partition so that the data are downloaded in parallel at the partition level. The thread will issue the query of the corresponding partition to the database and then write the returned data to the destination row-wise or column-wise (depends on the database) in a streaming fashion.
Example connection string, supported protocols and data types for each data source can be found here.
For more planned data sources, please check out our discussion.
- Postgres
- Mysql
- Mariadb (through mysql protocol)
- Sqlite
- Redshift (through postgres protocol)
- Clickhouse (through mysql protocol)
- SQL Server
- Azure SQL Database (through mssql protocol)
- Oracle
- Big Query
- Trino
- ODBC (WIP)
- ...
- Pandas
- PyArrow
- Modin (through Pandas)
- Dask (through Pandas)
- Polars (through PyArrow)
Doc: https://sfu-db.github.io/connector-x/intro.html Rust docs: stable nightly
Checkout our discussion to participate in deciding our next plan!
https://sfu-db.github.io/connector-x/dev/bench/
Please see Developer's Guide for information about developing ConnectorX.
You are always welcomed to:
- Ask questions & propose new ideas in our github discussion.
- Ask questions in stackoverflow. Make sure to have #connectorx attached.
![]()
![]()

To add your project/organization here, reply our post here
If you use ConnectorX, please consider citing the following paper:
Xiaoying Wang, Weiyuan Wu, Jinze Wu, Yizhou Chen, Nick Zrymiak, Changbo Qu, Lampros Flokas, George Chow, Jiannan Wang, Tianzheng Wang, Eugene Wu, Qingqing Zhou. ConnectorX: Accelerating Data Loading From Databases to Dataframes. VLDB 2022.
BibTeX entry:
@article{connectorx2022,
author = {Xiaoying Wang and Weiyuan Wu and Jinze Wu and Yizhou Chen and Nick Zrymiak and Changbo Qu and Lampros Flokas and George Chow and Jiannan Wang and Tianzheng Wang and Eugene Wu and Qingqing Zhou},
title = {ConnectorX: Accelerating Data Loading From Databases to Dataframes},
journal = {Proc. {VLDB} Endow.},
volume = {15},
number = {11},
pages = {2994--3003},
year = {2022},
url = {https://www.vldb.org/pvldb/vol15/p2994-wang.pdf},
}












































