Serdar Ozsoy, Shadi Hamdan, Sercan Ö. Arik, Deniz Yuret, Alper T. Erdogan
{kind=link}
📄 NeurIPS 2022 - Main Paper with Appendix
- 15 Sep 2022 Self-Supervised Learning with an Information Maximization Criterion is accepted to NeurIPS 2022.
Citation:
@misc{ozsoy2022selfsupervised,
title={Self-Supervised Learning with an Information Maximization Criterion},
author={Serdar Ozsoy and Shadi Hamdan and Sercan Ö. Arik and Deniz Yuret and Alper T. Erdogan},
year={2022},
eprint={2209.07999},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
We provide 6 main folders for the code.
- cifars-tiny: includes pretraining and linear evaluation for CIFARs and Tiny Imagenet dataset.
- imagenet100_resnet18: includes pretraining and linear evaluation for ImageNet-100 dataset with ResNet18.
- imagenet100_resnet50: includes pretraining and linear evaluation for ImageNet-100 dataset with ResNet50.
- imagenet1k: includes pretraining and linear evaluation for ImageNet1K dataset.
- semi_supervised: includes semi-supervised learning task for ImageNet1K dataset.
- transfer_learning: includes transfer learning task for ImageNet1K dataset.
Required packages are listed in 'requirements.txt'. Packages will be installed by running 'pip install -r requirements.txt'.
CIFAR-10 and CIFAR-100 datasets are automatically loaded in the pretraining script with Pytorch torchvision package. Tiny-ImageNet is downloaded externally, and the folder structure is changed to be compatible with dataset loading setting of torchvision. ImageNet-100 is a subset of ImageNet, so ImageNet dataset is downloaded and then made a subset with a specified class list. Required scripts and explanations are provided in their run folder.
Codes are designed to run with CIFAR-10, CIFAR-100 and Tiny ImageNet dataset which are localized in "/data/" folder inside the code base. ImageNet-100 is "/data/" folder in home directory, outside of the code base.
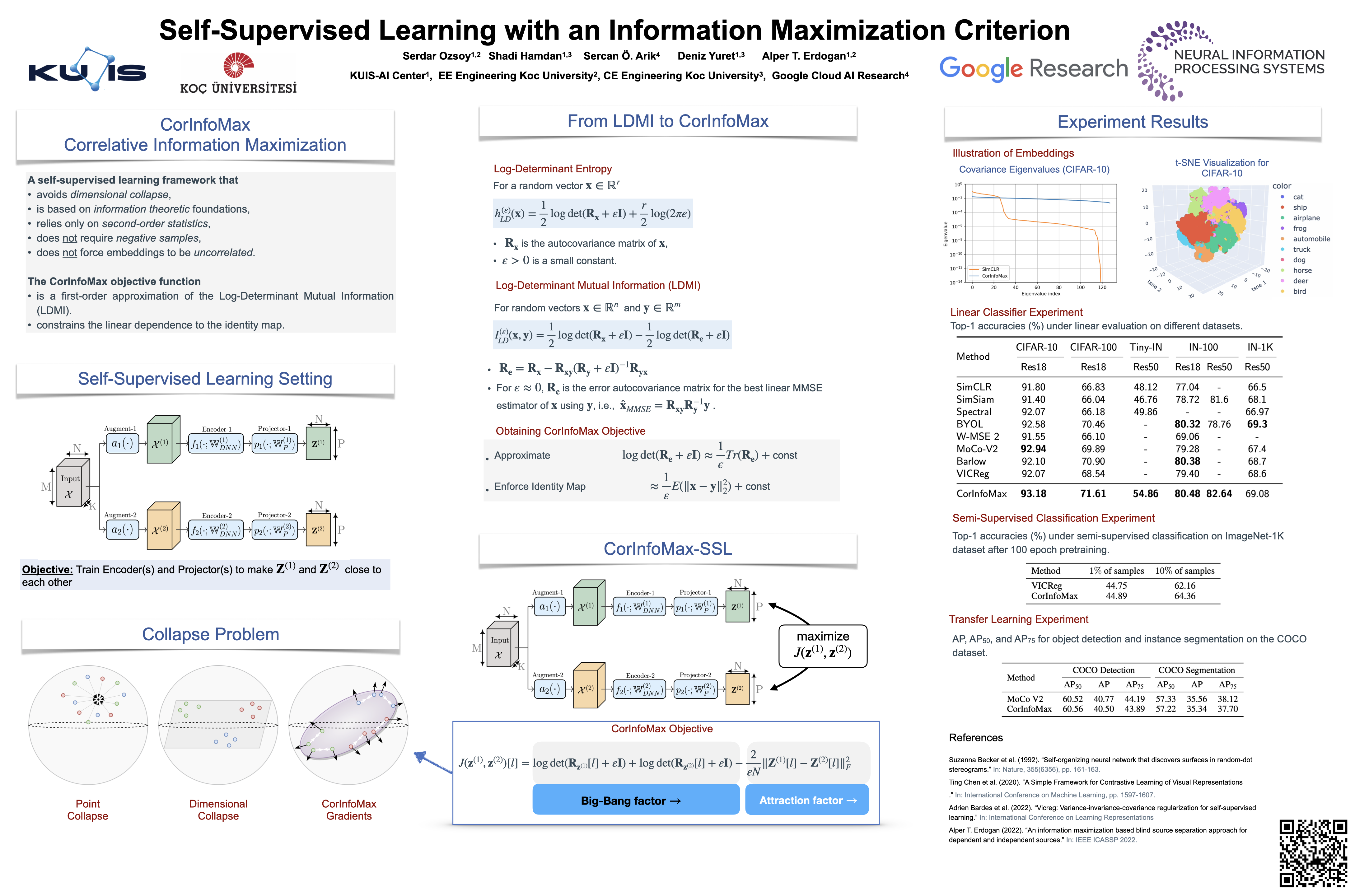
| Dataset | Encoder | Top-1 Accuracy |
|---|---|---|
| CIFAR-10 | ResNet-18 | 93.18 |
| CIFAR-100 | ResNet-18 | 71.61 |
| Tiny ImageNet | ResNet-50 | 54.86 |
| ImageNet-100 | ResNet-18 | 80.48 |
| ImageNet-100 | ResNet-50 | 82.64 |
| Imagenet-1K | ResNet-50 | 69.08 |
| Model | Top-1 Acc (1%) | Top-1 Acc (1%) |
|---|---|---|
| VICReg | 44.75 | 62.16 |
| CIFAR-100 | 44.89 | 64.36 |
- "sim_loss_weight" parameter in the code is correspond to "alpha" parameter, coefficient of attraction factor.
- "cov_loss_weight" parameter in the code is correspond to 1, constant coefficient of big-bang factor.
- "R_ini" parameter in the code is correspond to coefficient of initial covariance (identity matrix).
- "la_R" parameter in the code is correspond to forgetting factor for the covariance matrix.
- "la_mu" parameter in the code is correspond to forgetting factor for the projector output mean.
- "R_eps_weight" parameter in the code is correspond to diagonal perturbation factor of covariance matrix.
Other parameters details are included in parsing_file.py.
python main_traintest.py --epochs 1000 --batch_size 512 --lin_epochs 100 --lin_batch_size 256 --R_ini 1.0 --learning_rate 0.5 --cov_loss_weight 1.0 --sim_loss_weight 250.0 --la_R 0.01 --la_mu 0.01 --projector 2048-2048-64 --R_eps_weight 1e-8 --w_decay 1e-4 --pre_optimizer SGD --pre_scheduler lin_warmup_cos --lin_optimizer SGD --lin_learning_rate 0.2 --lin_w_decay 0 --lin_scheduler cos --n_workers 4 --dataset cifar10 --lin_dataset cifar10 --con_name cov_cifar10_best_rerun --model_name resnet18 --normalize_on --min_lr 1e-6 --lin_min_lr 0.002
python main_linear.py --lin_epochs 100 --lin_batch_size 256 --lin_optimizer SGD --lin_learning_rate 0.2 --lin_w_decay 0 --lin_scheduler cos --dataset cifar10 --lin_dataset cifar10 --con_name 1 --model_name resnet18 --lin_model_path results/t_1653402026_cov_cifar10_best_rerun_model1000.pth --n_workers 4 --gpu_no 0 --lin_min_lr 2e-3
python main_traintest.py --epochs 1000 --batch_size 512 --lin_epochs 100 --lin_batch_size 256 --R_ini 1.0 --learning_rate 0.5 --cov_loss_weight 1.0 --sim_loss_weight 1000.0 --la_R 0.01 --la_mu 0.01 --projector 4096-4096-128 --R_eps_weight 1e-8 --w_decay 1e-4 --lin_warmup_epochs 5 --pre_optimizer SGD --pre_scheduler lin_warmup_cos --lin_optimizer SGD --lin_learning_rate 0.2 --lin_w_decay 0 --lin_scheduler cos --n_workers 4 --dataset cifar100 --lin_dataset cifar100 --con_name cov_cifar100_best_rerun --model_name resnet18 --normalize_on --min_lr 1e-6 --lin_min_lr 0.002
python main_linear.py --lin_epochs 100 --lin_batch_size 256 --lin_optimizer SGD --lin_learning_rate 0.2 --lin_w_decay 0 --lin_scheduler cos --dataset cifar100 --lin_dataset cifar100 --con_name 1 --model_name resnet18 --lin_model_path results/t_1653488201_cov_cifar100_best_rerun_model1000.pth --n_workers 2 --gpu_no 0 --lin_min_lr 2e-3
python ./main_traintest.py --epochs 800 --batch_size 1024 --lin_epochs 100 --lin_batch_size 256 --R_ini 1.0 --learning_rate 0.5 --cov_loss_weight 1.0 --sim_loss_weight 500.0 --la_R 0.1 --la_mu 0.1 --projector 4096-4096-128 --R_eps_weight 1e-8 --w_decay 1e-4 --warmup_epochs 10 --pre_optimizer SGD --pre_scheduler lin_warmup_cos --lin_optimizer SGD --lin_learning_rate 0.2 --lin_w_decay 0 --lin_scheduler cos --n_workers 4 --dataset tiny_imagenet --lin_dataset tiny_imagenet --con_name cov_tiny --model_name resnet50 --normalize_on --min_lr 1e-6 --lin_min_lr 0.002
python main_linear.py --lin_epochs 100 --lin_batch_size 256 --lin_optimizer SGD --lin_learning_rate 0.2 --lin_w_decay 0 --lin_scheduler cos --dataset tiny_imagenet --lin_dataset tiny_imagenet --con_name 1 --model_name resnet50 --lin_model_path results/t_1655467683_cov_tiny_lamda_model800.pth --n_workers 4 --lin_min_lr 2e-3
Due to larger image sizes, it requires multiple GPUs to make experiments in reasonable time.
Note: Correct path for pretrained model must be added for "--lin_model_path" parameter.
Note: Linear evaluation during pretraining is only for indicator. For precise result, linear evaluation should be done for 100 epochs after obtaining the final pretraining model.
torchrun --nproc_per_node=8 main_traintest_cov_online_multi3_lin_img100_wmse_resnet18.py --epochs 400 --learning_rate 1.0 --lin_epochs 200 --lin_batch_size 256 --R_ini 1.0 --projector 4096-4096-128 --batch_size 1024 --sim_loss_weight 500.0 --cov_loss_weight 1.0 --la_R 0.01 --la_mu 0.01 --R_eps_weight 1e-08 --w_decay 1e-4 --pre_optimizer SGD --pre_scheduler lin_warmup_cos --lin_optimizer SGD --lin_learning_rate 0.2 --lin_w_decay 0 --lin_scheduler lin_warmup_cos --dataset imagenet-100 --lin_dataset imagenet-100 --con_name cov_imagenet100_ep400_norm_resnet18 --model_name resnet18 --n_workers 12 --normalize_on --min_lr 5e-3
torchrun --nproc_per_node=8 main_linear_multi_resnet18.py --epochs 100 --lin_epochs 100 --lin_batch_size 256 --lin_optimizer SGD --lin_learning_rate 0.2 --lin_w_decay 0 --lin_scheduler cos --dataset imagenet-100 --lin_dataset imagenet-100 --con_name 1 --model_name resnet18 --lin_model_path ~/imagenet100_resnet18/pretrain/results/t_1652904346_cov_imagenet100_ep400_norm_resnet18_model400.pth --n_workers 12 --lin_min_lr 2e-3
Due to larger image sizes, it requires multiple GPUs to make experiments in reasonable time.
Note: Correct path for pretrained model must be added for "--lin_model_path" parameter.
Note: Linear evaluation during pretraining is only for indicator. For precise result, linear evaluation should be done for 100 epochs after obtaining the final pretraining model.
torchrun --nproc_per_node=8 main_traintest_cov_online_multi3_lin_img100.py --epochs 200 --learning_rate 1.0 --lin_epochs 200 --lin_batch_size 256 --R_ini 1.0 --projector 4096-4096-128 --batch_size 1024 --sim_loss_weight 500.0 --cov_loss_weight 1.0 --la_R 0.01 --la_mu 0.01 --R_eps_weight 1e-08 --w_decay 1e-4 --pre_optimizer SGD --pre_scheduler lin_warmup_cos --lin_optimizer SGD --lin_learning_rate 0.2 --lin_w_decay 0 --lin_scheduler lin_warmup_cos --warmup_epochs 5 --dataset imagenet-100 --lin_dataset imagenet-100 --con_name cov_imagenet100_ep200_norm --model_name resnet50 --n_workers 12 --normalize_on --min_lr 5e-3
torchrun --nproc_per_node=8 main_linear_multi.py --epochs 100 --lin_epochs 100 --lin_batch_size 256 --lin_optimizer SGD --lin_learning_rate 0.2 --lin_w_decay 0 --lin_scheduler cos --dataset imagenet-100 --lin_dataset imagenet-100 --con_name 1 --model_name resnet50 --lin_model_path ~/imagenet100_resnet50/pretrain/results/t_1652883735_cov_imagenet100_ep200_norm_model200.pth --n_workers 12 --lin_min_lr 2e-3
Due to larger image sizes, it requires multiple GPUs to make experiments in reasonable time.
Note: Correct path for pretrained model must be added for "--lin_model_path" parameter.
torchrun --nproc_per_node=8 main_orig_tinyimg_clone_mgpu_corrected_offline_bn.py --epochs 100 --lin_epochs 100 --R_ini 1.0 --pre_optimizer SGD --pre_scheduler lin_warmup_cos --lin_optimizer SGD --lin_learning_rate 2.0 --lin_min_lr 1e-1 --lin_w_decay 0 --lin_scheduler cos --n_workers 12 --dataset imagenet --lin_dataset imagenet --con_name imagenet_mgpu_amp_4gpu_a100_bn --model_name resnet50 --normalize_on --min_lr 1e-6 --learning_rate 0.2 --cov_loss_weight 1.0 --sim_loss_weight 2000.0 --la_R 0.1 --la_mu 0.1 --projector 8192-8192-512 --R_eps_weight 1e-08 --w_decay 1e-4 --batch_size 1536 --lin_batch_size 256 --amp
torchrun --nproc_per_node=8 main_linear_multi_offline_t4.py --epochs 100 --lin_epochs 100 --lin_batch_size 256 --lin_optimizer SGD --lin_learning_rate 25.0 --lin_w_decay 0 --lin_scheduler step --lin_step_size 20 --dataset imagenet --lin_dataset imagenet --con_name 1 --model_name resnet50 --lin_model_path ./results/t_1659716263_imagenet_mgpu_amp_4gpu_a100_bn_model100.pth --n_workers 12
Added step scheduler for each header and backbone. Code exists in semi_supervised folder.
Code Source: VICReg
- 1% of data
python evaluate_step.py --data-dir ~/data --pretrained ./pretrained_corinfomax/resnet50.pth --exp-dir ./experiment_ft1_corinfomax/ --weights finetune --train-perc 1 --epochs 20 --lr-backbone 0.005 --lr-head 10 --weight-decay 0
- 10% of data
python evaluate_step.py --data-dir ~/data --pretrained ./pretrained_corinfomax/resnet50.pth --exp-dir ./experiment_ft10_corinfomax/ --weights finetune --train-perc 10 --epochs 20 --lr-backbone 0.005 --lr-head 20 --weight-decay 0
Code Source: MoCo
For details please refer README.md in transfer_learning folder.
- Linear evaluation is not started: Correct path or name for pretrained model must be added for "--lin_model_path" parameter.
- Pretraining is not started: wrong "--gpu_no" parameters (for CIFAR-10, CIFAR-100, Tiny ImageNet experiments)
- Any unexpected low accuracy results: dataset folder can be in different path. (for Tiny ImageNet and ImageNet-100 experiments)
- If runtime takes much more than reported: --n_workers may be incompatible with your running system. We choose number of CPU core in our all experiments.