Rohit Bharadwaj*, Hanan Gani*, Muzammal Naseer, Fahad Khan, Salman Khan
Official code for our paper "VANE-Bench: Video Anomaly Evaluation Benchmark for Conversational LMMs"
*Authors marked with "*" contributed equally to this work.
- (Jan 26, 2025)
- Our paper has been accepted to NAACL 2025 🥳🎊
- (June 11, 2024)
- Our code, data, and the project website is now live!
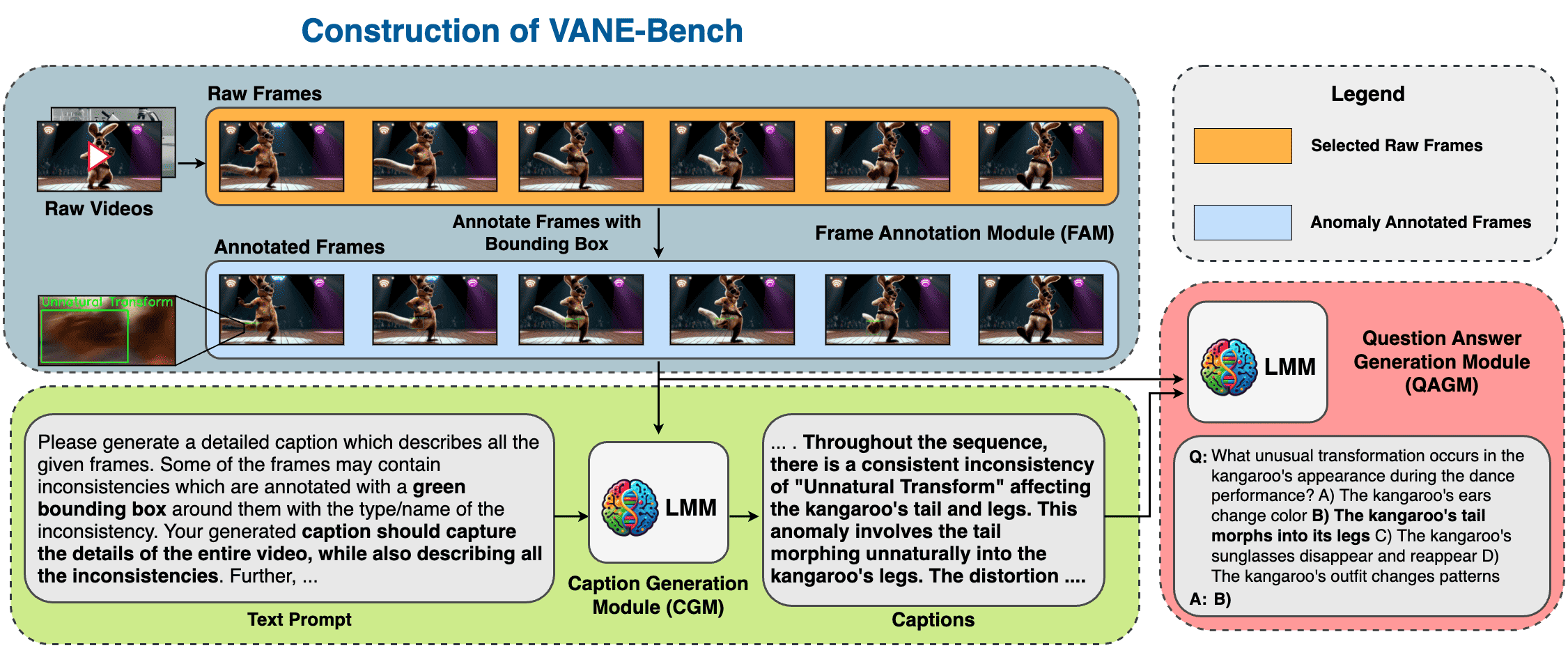
Abstract: The recent developments in Large Multi-modal Video Models (Video-LMMs) have significantly enhanced our ability to interpret and analyze video data. Despite their impressive capabilities, current Video-LMMs have not been evaluated for anomaly detection tasks, which is critical to their deployment in practical scenarios e.g., towards identifying deepfakes, manipulated video content, traffic accidents and crimes. In this paper, we introduce VANE-Bench, a benchmark designed to assess the proficiency of Video-LMMs in detecting and localizing anomalies and inconsistencies in videos. Our dataset comprises an array of videos synthetically generated using existing state-of-the-art text-to-video generation models, encompassing a variety of subtle anomalies and inconsistencies grouped into five categories: unnatural transformations, unnatural appearance, pass-through, disappearance and sudden appearance. Additionally, our benchmark features real-world samples from existing anomaly detection datasets, focusing on crime-related irregularities, atypical pedestrian behavior, and unusual events. The task is structured as a visual question-answering challenge to gauge the models' ability to accurately detect and localize the anomalies within the videos. We evaluate nine existing Video-LMMs, both open and closed sources, on this benchmarking task and find that most of the models encounter difficulties in effectively identifying the subtle anomalies. In conclusion, our research offers significant insights into the current capabilities of Video-LMMs in the realm of anomaly detection, highlighting the importance of our work in evaluating and improving these models for real-world applications. Our project website is live at link
- We present VANE-Bench: Video ANomaly Evaluation Benchmark, consisting of 325 video clips, and 559 challenging question-answer pairs from both real-world video surveillance, and AI-generated videos.
- We perform detailed evaluation of over nine state-of-the-art closed-source and open-source Video-LMMs on VANE-Bench, and show that most models exhibit poor performance, highlighting the challenging nature of our proposed benchmark.
- We conduct detailed result analysis, and also perform human evaluation on VANE-Bench to set a reasonable benchmark target.
- We open-source our code, and describe the data construction process of VANE-Bench along with making our data publicly available.
To replicate our experiments, and to use our code:
- First clone the repository:
git clone [email protected]:rohit901/VANE-Bench.gitor
git clone https://github.com/rohit901/VANE-Bench.git- Change directory:
cd VANE-BenchWe used python=3.11.8 in our experiments involving closed-source LMMs like GPT-4o and Gemini-1.5 Pro.
- Setup a new conda environment with the specified python version:
conda create --name vane_bench python=3.11- Activate the environment
conda activate vane_bench- Install Libraries:
pip install openai opencv-python python-dotenv tqdm google-generativeai pillow- Create a new
.envfile inscripts/closed_source_models/, and populate it with your OpenAI and Gemini API keys:
OPENAI_API_KEY=<your_key_here>
GOOGLE_API_KEY=<your_key_here>CGM requires path to the directory containing frames annotated with bounding boxes. The path argument in the script is the absolute path to annotated dataset directory like 'SORA', 'ModelScope', 'UCFCrime', etc, and each of these dataset directories will contain multiple subdirectories (one per video clip in the dataset) containing the annotated frames. You can use our CGM with your own annotated data.
To run the code:
python scripts/closed_source_models/CGM.py --path="<path_to_annotated_dataset>"The above script will then generate caption for each video clip in the same directory as path.
Once the captions are obtained from CGM, we can use QAGM to generate the final QA pairs. QAGM also requires path to the annotated data, and assumes that the captions are also in the same path.
To run the code:
python scripts/closed_source_models/QAGM.py --path="<path_to_annotated_dataset_and_captions>"- Download and unzip the VANE-Bench dataset by following Dataset.
- Evaluate GPT-4o one dataset at a time. For example, to evaluate it on "SORA" dataset, run the following:
python scripts/closed_source_models/evaluate_vqa_GPT.py --data_path="/path/to/VQA_Data/AI-Generated/SORA" --out_path="/path/to/GPT-4o/SORA"- Download and unzip the VANE-Bench dataset by following Dataset.
- Evaluate Gemini-1.5 Pro one dataset at a time. For example, to evaluate it on "SORA" dataset, run the following:
python scripts/closed_source_models/eval_vqa_gemini.py --data_path="/path/to/VQA_Data/AI-Generated/SORA" --out_path="/path/to/Gemini-Pro/SORA"Following the previous instruction, once the prediction files for a LMM is generated, we can evaluate the LMM's accuracy by running:
python scripts/calc_lmm_vqa_accuracy.py --path="/path/to/GPT-4o/SORA"The above command evaluates the accuracy of GPT-4o on the SORA dataset. To evaluate different models on different datasets, just modify the path variable accordingly.
Follow the instructions here for setting up and evaluating open-source Video-LMMs.
Our VANE-Bench dataset can be downloaded from Huggingface Hub. Users can either directly load the dataset using 🤗 Datasets, or download the zip file present in that repository.
Should you have any questions, please create an issue in this repository or contact [email protected] or [email protected].
We thank OpenAI and Google for their Python SDKs.
If you found our work helpful, please consider starring the repository ⭐⭐⭐ and citing our work as follows:
@misc{bharadwaj2024vanebench,
title={VANE-Bench: Video Anomaly Evaluation Benchmark for Conversational LMMs},
author={Rohit Bharadwaj and Hanan Gani and Muzammal Naseer and Fahad Shahbaz Khan and Salman Khan},
year={2024},
eprint={2406.10326},
archivePrefix={arXiv},
primaryClass={id='cs.CV' full_name='Computer Vision and Pattern Recognition' is_active=True alt_name=None in_archive='cs' is_general=False description='Covers image processing, computer vision, pattern recognition, and scene understanding. Roughly includes material in ACM Subject Classes I.2.10, I.4, and I.5.'}
}