A goal-driven autonomous exploration and mapping system that combines reactive and planned robot navigation. First, a navigation policy is learned through a deep reinforcement learning framework in a simulated environment. This policy guides an autonomous agent towards a goal while avoiding obstacles. We develop a navigation system where this learned policy is integrated into a motion planning stack as the local navigation layer to move the robot towards the intermediate goals. A global navigation strategy is used to mitigate the local optimum problem and guide the robot towards the global goal. Possible intermediate goal locations are extracted from the environment and used as local goals according to the navigation system heuristics. The fully autonomous navigation is performed without any prior knowledge while mapping is performed as the robot moves through the environment.
Article has been accepted and published in IEEE RA-L and accepted for ICRA 2022:
The article is available here
Can be cited as:
@ARTICLE{9645287,
author={Cimurs, Reinis and Suh, Il Hong and Lee, Jin Han},
journal={IEEE Robotics and Automation Letters},
title={Goal-Driven Autonomous Exploration Through Deep Reinforcement Learning},
year={2022},
volume={7},
number={2},
pages={730-737},
doi={10.1109/LRA.2021.3133591}}
Main dependencies:
Code of the experimental implementation is available in the "Code" folder.
Videos, images, and gifs of experiments are available in the "Experiments" folder.
Extended video of experiments:
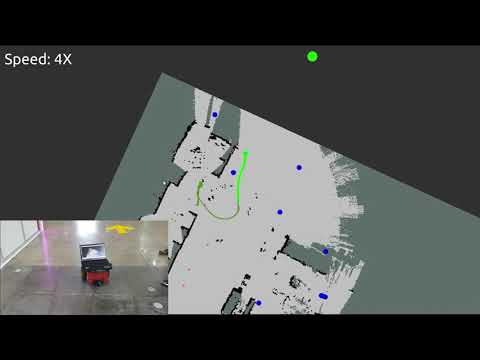
This includes experiments in a cluttered environment, hallway with backtracking and escape from local optimum, underground parking lot, and Robot World Expo with dynamic real-world obstacles. In Robot World Expo the navigation system has to navigate around pedestrians who are not familiar with the robots movements, its capabilities, and tasks which make for a good test of our systems navigation capabilities. At a point, a robot navigates into one of the booths and, when moving out of it, a person blocks its way out. Therefore, the robot spends significant amount of time trying to find a free direction to move towards. When the person moves, a way out of the booth becomes available and the robot resumes its navigation and mapping towards the initial global goal. Additional experiments are displayed below and even more experimental results are available in the "Experiments" folder.
Additional video of experiments:
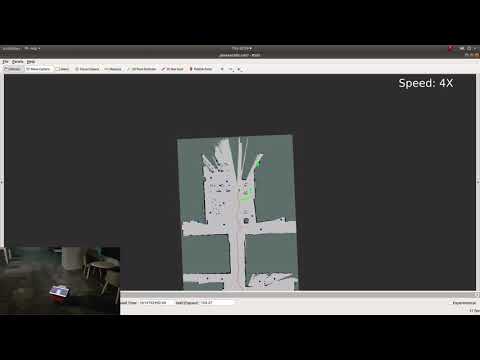
More videos at:
An example of network training available at:
https://github.com/reiniscimurs/DRL-robot-navigation
Robot World 2020 Expo
Robot navigates in a dynamic setting with booths, robots, unsuspecting pedestrians and others as obstacles. The goal is set the same as in the aforementioned video and is a different experiment with the same goal. Goal location (80, 25)

Final map

Testing exploration with return to initial position. Initially, the robot navigates to the set goal. Once it is reached, the goal is changed to the (0, 0) coordinate and the robot navigates back to its starting position. Robot uses path planning and previously obtained nodes for backtracking. This is still in testing phase, but we expect to be able to extend the system to multi-goal navigation with return to starting position. Goal location (23, -3)

Final map

Underground Parking Lot
Test in an underground parking lot with a lot of reoccuring similar features over a long distance of 120 meters. Moreover, the mapping does not register the parking bumpers, but the local learned navigation does and navigates around them. Goal location (120,0)

Final map

Hallway
A different hallway from the one seen in the video. The robot first needs to navigate outside of a room and then go straight towards the final goal. New intermediate goal points are extracted from the environment and the path planner. Goal location (12.5, -88)

Final map

Testing a setting with unreachable goal. Goal is located in a room that the robot cannot physically enter. Robot navigates to the vicinity of the goal and tries to find a way to it by entering a narrow hallway. Once the narrow hallway is explored, the robot backtracks and navigates towards other possible intermediate goals. Exploration continues until manual termination. Goal location (20, -65)
