-
Notifications
You must be signed in to change notification settings - Fork 540
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
ARIMA: pre-allocation of temporary memory to reduce latencies (#3895)
This PR can speed up the evaluation of the log-likelihood in ARIMA by 5x for non-seasonal datasets (the impact is smaller for seasonal datasets). It achieves this by pre-allocating all the temporary memory only once instead of every iteration and providing all the pointers with a very low overhead thanks to a dedicated structure. Additionally, I removed some unnecessary copies.  Regarding the unnecessary synchronizations, I'll fix that later in a separate PR. Note that non-seasonal ARIMA performance is now even more limited by the python-side solver bottleneck: 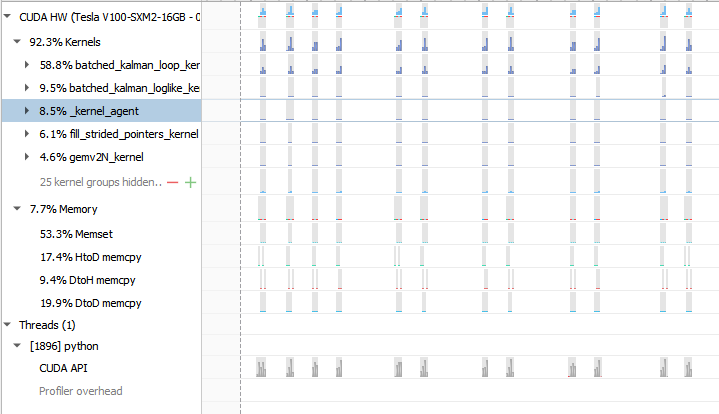 One problem is that batched matrix operations are quite memory-hungry so I've duplicated or refactored some bits to avoid allocating extra memory there, but that leads to some duplication that I'm not entirely happy with. Both the ARIMA code and batched matrix prims are due some refactoring. Authors: - Louis Sugy (https://github.com/Nyrio) Approvers: - Tamas Bela Feher (https://github.com/tfeher) - Dante Gama Dessavre (https://github.com/dantegd) URL: #3895
{kind=link}
{kind=link}
- Loading branch information
Showing
9 changed files
with
759 additions
and
306 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.