Added SamplingResult cdef class to return cupy "views" for PLC sampling algos instead of copying result data
#2684
Conversation
…still need to manage lifecycle of device memory, will probably need to do this differently.
…oming) new SampleResult type
…ating SamplingResult instances from host arrays.
…code cleanup, added docstrings, updated test_sample_result() to add more thorough assertions and extra reference test.
…0-device_array_pybuffer
…dated SG uniform_neighbor_sample test to add benchmark and check for leaks.
… is fixed, allowing CI to make any other failures more noticeable. This will be uncommented before the PR is moved out of Draft.
Codecov ReportBase: 60.04% // Head: 57.76% // Decreases project coverage by
Additional details and impacted files@@ Coverage Diff @@
## branch-22.10 #2684 +/- ##
================================================
- Coverage 60.04% 57.76% -2.28%
================================================
Files 111 111
Lines 6184 6069 -115
================================================
- Hits 3713 3506 -207
- Misses 2471 2563 +92
Help us with your feedback. Take ten seconds to tell us how you rate us. Have a feature suggestion? Share it here. ☔ View full report at Codecov. |
|
I believe the CI test failures are related to the changes in this PR, so I'm looking into those. |
…0-device_array_pybuffer
…g ninja in build.sh, added handling of NULL in create_cupy_array_view_for_device_ptr()
| auto p_handle = reinterpret_cast<cugraph::c_api::cugraph_resource_handle_t const*>(handle); | ||
| auto host_srcs = | ||
| reinterpret_cast<const cugraph::c_api::cugraph_type_erased_host_array_view_t*>(srcs); | ||
| auto new_device_srcs = new cugraph::c_api::cugraph_type_erased_device_array_t( |
There was a problem hiding this comment.
I would be inclined to do this a bit differently. The values new_device_srcs, new_device_dsts, new_device_wgts and new_device_counts that you're creating here are a potential for a memory leak, since they are not in RAII objects.
You could:
- Do type dispatching and create these as
rmm::device_uvector<appropriate_type>and then convert to the return value. This would mimic the pattern of the algorithm implementation. - Create these as
std::unique_ptrvalues and release them when you convert to the return value - Create the return value as a
std::unique_ptr(releasing upon return) with the new calls for these operators inside and then just use the values from the return object. We do know the sizes a priori
There was a problem hiding this comment.
Instead of this suggestion, I changed the implementation to use other cugraph C API calls (as suggested below), which included using cugraph_type_erased_device_array_create_from_view() from #2712 . Let me know if you'd prefer I use the rmm:device_uvector/type dispatching approach instead.
…0-device_array_pybuffer
…0-device_array_pybuffer
…0-device_array_pybuffer
…0-device_array_pybuffer
…s an API intended for use in testing, changed implementation of cugraph_sampling_result_ctreate() to use new APIs fro creating and copying a device array from a device array view (which required pulling in cugraph_type_erased_device_array_create_from_view() from another dev branch), changed tests to use device array instead of host array, style check fixes.
…leak is being addressed.
…ng new cugraph_sample_result_t, in order to guarantee they are cleaned up on error.
|
is there, or should there, be a macro for |
…ckages in build/artifact dirs instead of what it thinks are better candidates from other channels. This may fix the problem of CI testing against some other version of cugraph instead of the version built in the PR.
…y error message in CI log.
|
rerun tests |
|
@gpucibot merge |
In #2684, the CMake build system was switched from `make` to `ninja`, which broke these doc builds. This PR updates the scripts for the nightly docs builds to use a generic `cmake` build option, rather than a build-system specific invocation to fix the issue and prevent a similar issue from occurring in the future. **Note**: this PR targets `branch-22.10` since the the `22.10` docs aren't currently up-to-date because of this issue.
In #2684, the CMake build system was switched from `make` to `ninja`, which broke the nightly doc builds. This PR updates the scripts for the nightly doc builds to use a generic `cmake` build option, rather than a build-system specific invocation to fix the issue and prevent a similar issue from occurring in the future. **Note**: this PR targets `branch-22.10` since the the `22.10` docs aren't currently up-to-date because of this issue. Authors: - AJ Schmidt (https://github.com/ajschmidt8) Approvers: - Jordan Jacobelli (https://github.com/Ethyling)
…ure to allow for a client-side device to directly receive results (#2715) closes rapidsai/GaaS#23 ### Summary * Adds an API option to `uniform_neighbor_sample()` to allow clients to specify a client-side GPU (using device number) which will receive the results, eliminating the expensive server-side device-host copy in order to serialize and send via RPC. * Adds test(s) and benchmarks to cover the new feature * Also adds a `--pydevelop` option to `build.sh` for building python components that allow for making edits without re-installing (runs `setup.py` with the `develop` option) ### Details * This PR depends on #2684 ### Benchmarks New benchmarks have been added by this PR, with the results shown below. The results to take note of are in the red rectangles. `device=None` is the previous version using serialization and transfer from the server to the client using host memory (using Apache Thrift), and `device=0` is a GPU-GPU transfer using UCX-Py from the server on GPU1 to the client on GPU0. A typical data transfer for many GNN use cases involves ~1M values, which is what the highlighted benchmark simulates. For smaller transfers, the Thrift-based RPC is faster, but increases significantly as the payload increases (so much so that the largest size that could be run in a reasonable time for Thrift was 1e6, vs UCX-Py sizes of 2e9 still being much faster). UCX-Py seems to have some amount of fixed overhead, but the benefits are dramatic at larger sizes. 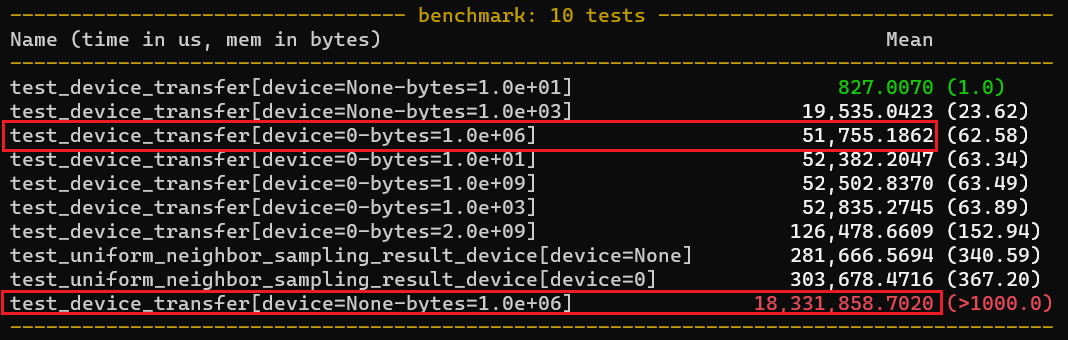 Authors: - Rick Ratzel (https://github.com/rlratzel) Approvers: - Joseph Nke (https://github.com/jnke2016) - Alex Barghi (https://github.com/alexbarghi-nv) - Brad Rees (https://github.com/BradReesWork) URL: #2715
{kind=link}
Summary
SamplingResultcython extension class that corresponds to the C API'scugraph_sample_result_ttype, which removes a copy operation in sampling algos.test_neighborhood_sampling.py::test_sample_result)build.shto useninjaby default.Background
As part of a larger effort to provide GPU-GPU data transfer in
cugraph_serviceto improve performance, the need to minimize redundant data copy operations was also something to address.Prior to this change, PLC algos would copy their results from the C API device data structures into one or more cupy ndarrays, which allowed the algo to then delete the result data owned by the C API and leave the lifecycle management of the results returned to python to the python interpreter/GC. The copy operation not only slowed down sampling algo calls (slightly) but also caused spikes in GPU memory usage where two copies of results existed in GPU memory for a short time immediately after the copy but before the original was deleted.
This PR adds a cython extension class that corresponds to the C API's
cugraph_sample_result_ttype, which is used to pass ownership of the sampling results to python. The extension class callscugraph_sample_result_free()when all references to the result data in python are removed and the garbage collector runs. The owningSamplingResultobject allows PLC sampling algos to instead return cupy ndarray "views" for results instead of copying them to new cupy ndarrays.New test APIs to create sampling result objects in C and PLC were added and used in the new tests to verify that the ownership of the result data was properly transferred to Python, and that the lifecycle management of results was done properly when clients keep references to data (eg. pass results to other parts of code for use long after the algo completes).
A benchmark was also added to verify the (minor) speedup. Runs

0001-2were before the change, runs0003-5(red box) were after: