[Discussion] Requirements for schema/column names #3225
Comments
|
I suppose it depends a lot on how structs are being implemented: if the relationship between columns (eg: is a column a field of a struct) is stored in a separate schema structure while data is stored in a flat array of columns, then it would make sense to store the name in the schema structure instead of the columns. However, if a column can have child columns (a tree, where fields of a struct are children of another column), then the name should be part of the column (for the name itself, I don't think we need anything besides a simple std::string). |
|
Spark tracks names in a schema structure that is separate from the data. Names are associated with structs (i.e.: a struct knows the names of the fields within it, but leaf types do not know nor care what their name is.) That being said, the Spark plugin should be able to adapt pretty easily to wherever the names are placed (separate schema struct, only in struct columns, or columns know their own names). We just need some way for the loaders to convey the schema that was loaded so we can align that with the schema Spark expects. |
|
From the Python side, columns can be named outside of tables, and those names are expected to be maintained through libcudf function calls. We could maintain this ourselves, but it would be more ideal if columns had the ability to have a name outside of a separate struct. |
Can you explain more about what you mean about "expected to be maintained"? |
|
Basically if I call something like |
|
What does SQL do? |
|
This is a blocker for cuIO porting to libcudf++ currently, so we need to come to an agreement. |
It's not specified. SQL has names associated with table columns but the SQL implementation can choose how to track it. Spark happens to track it in a separate schema. If it's easier for the Python side, I'm fine with keeping the name of a column associated directly with a cudf::column. The Spark plugin will likely not examine these names except after calling a loader to map what was loaded to Spark's expected schema. If we go with names in columns, only issue will be making sure libcudf knows when to propagate column names. For example, does the column name propagate on a filter? groupby? join? All the places where the code was copying names when allocating |
This is exactly my concern with putting the name directly inside My vote would be for cuIO to return a simple wrapper around a Then it's up to the user to do whatever they want to do with the name. |
|
I'm not sure I understand how adding a name in the column introduces new problems: don't we have the column name in the column today (in the legacy gdf_column structure) ? |
Yes, but it's 100% ignored in every libcudf compute function. It introduces new problems if we're expected to do anything with the name, like propagate it from input to output. |
|
@shwina and I had a discussion about this on the Python side and decided it's probably a better bet if we just handle this on the Python side. Columns can have arbitrary hashable Python objects as names (unfortunately) so it will likely be easier for us to just manage it on our own. @j-ieong @OlivierNV for the io readers / writers would it suffice to just pass a |
|
I think a string vector will be problematic when we support nested types. For example, if one of the loaded columns is named 'A' and is a structure of fields 'B', 'C', and 'D', I assume we would want a way to convey these nested names under 'A' back to the caller. There would need to be a tree-like schema descriptor returned to describe what was loaded in the general case. Or will we only be interested in top-level column names? |
Good point, I didn't really think through this other than we'd be happy with a separate object as opposed to baking the names into the column objects. |
|
Personally, I'd vote for just adding a std::string to the new column class, and have compute functions just return unnamed column (except perhaps for the copy constructor), where an unnamed column is just a column with an empty string as its name. (from writer point of view, it's better to have empty strings than duplicate made-up names). We could always change this later if we somehow need all column names consolidated in one object, and it pretty much matches the current behavior, so one less surprise for people trying to switch from cudf-0.10 to cudf-0.11 |
I'm not a fan of this approach. If a
Very little of libcudf's current behavior is worth emulating :) |
|
A cuIO loader could return a schema corresponding to the loaded column(s). The schema node object would just have a string name and a vector of child nodes, mirroring how children are handled in cudf::column. One approach would be to return a separate Or if tables don't need names, could just return a vector of |
|
Isn't that structure eerily similar to the cudf columns that can have child columns for nesting ? The client or python side can handle fancy name additions, but I would think that read_orc/write_orc would preserve the name without asking the client to enumerate and keep track of schema separately from columns. |
|
Yes, it is intentionally similar. The concern expressed in above discussion is that if we put the name in the column that libcudf's computation algorithms will be required to propagate the name, and the semantics of that propagation would then need to be clearly defined in a way that is agreeable to all clients (which may or may not be possible?). I suppose we could store the name in the column but ignore it in libcudf, but if we are doing that, what's the point? I was attempting to suggest a compromise solution: since the only APIs in cuDF that need to set the name are file loader APIs, why not define a structure that only cuIO APIs produce? |
|
I'm not sure what are the benefits of adding the extra complexity of an additional table/column class hierarchy to manage (the way I see it, the name would either need to go in the cudf table or in cudf column). |
|
The advantage is not having to deal with column names inside libcudf, since both Python and Spark have said they need to track the names separately from the data.
|
That's nice, but the whole point of libcudf++ is to present a C++ API (at least that's my understanding), so it seems we need a minimum amount of schema support within libcudf. |
|
The cudf column is not an internal type to libcudf since it is exposed through the API, so this "I don't need it therefore nobody needs it" argument does not apply. One alternative solution that does not require column names in libcudf++ and can be easily implemented for 0.11 while remaining simple for applications migrating from cudf-0.10 would be to keep io readers/writers using the old legacy interface and provide conversion from/to libcudf++ column types (also saves use a lot of duplicate code paths for "legacy"/"non-legacy") |
This is 100% a non-starter. |
This is literally what Arrow does. https://arrow.apache.org/docs/cpp/classarrow_1_1_schema.html All we are suggesting is to make a class like this: |
Not quite: you'll notice that unlike libcudf++, arrow keeps the column schema hierarchy separate from the columns (Somebody in libcudf++ already made the decision to not do that and put the schema hierarchy within the columns). But even with a separate schema, arrow still stores the column names within the columns themselves. |
|
Notice that they don't have any names.
Seeing as though
|
There is: you have columns with child columns: that tree structure is the schema. |
Something isn't adding up here. |
|
If the goal is to make libcudf++ cudf::column/cudf::table similar to low-level arrow::ChunkedArray instead of arrow::column/arrow::table then the decision to not have any column names in cudf has already been made, not sure what's up for discussion. |
In the same way that Arrow has more than just an What's up for discussion is creating a new data structure something like this: |
|
I'll let people more involved with these things than I am comment, but I'm not sure what would be left in the "schema" field of that structure besides column names if nesting information is already contained within cudf::table. |
|
I think the conclusion (after some off-github discussion) is to store the column name in My reasoning is that this is the simplest way forward. libcudf does not have plans currently to make any guarantees to propagate column names through its algorithms, other than in cuIO readers and writers. |
|
Had further discussion with @jrhemstad on this today, and he convinced me against my previous conclusion. Basically, the name is information that does not need to be carried in the columns. Analogy: if an application of cudf::column needed to always know the min and max elements in each column, we would not want to add those fields to the column itself, since they are not needed by the internals of libcudf. Instead, they would be stored in some wrapper data structure. Names are similar. We hear the argument about the fact that the structure of nested columns already mirrors the schema, but that structure is a necessary part of operating on the data in the columns. The name isn't. Moreover, multiple libcudf clients have told us that they need to maintain an external schema anyway, and that having the names in the column would cause them extra work to maintain consistency between two sources of truth. We think it's best to define a schema structure that stores the names, and use this in the cuIO readers/writers. |
|
We'll just return an array of strings for the names in readers and take in an array of names for the writer. No need to require the client to maintain a third schema structure. |
|
When we support nested columns this will not be sufficient. |
|
Yes, once we support nested columns we will have to revisit. |
|
A std::string vector will in fact be sufficient to return column names regardless of nesting support (the [unnecessary] complexity of having to handle a separate flattened schema introduced by not having names within the cudf column tree structure falls on the user/bindings). |
|
How is it sufficient to have a flat vector of names if the columns themselves contain columns? |
|
@harrism The same way it is done in parquet/orc format, where you need to serialize a tree into a file: a 'flattened' version of the column tree, with a left-to-right traversal convention (it will have to be clearly documented once we add nesting), though this depends on how cudf will implement nesting (with a separate schema, one would expect the top-level column array in the table to already be a flattened tree, though it looks like cudf is likely to go for the tree schema representation where fields of a struct are children of the parent struct column) |
|
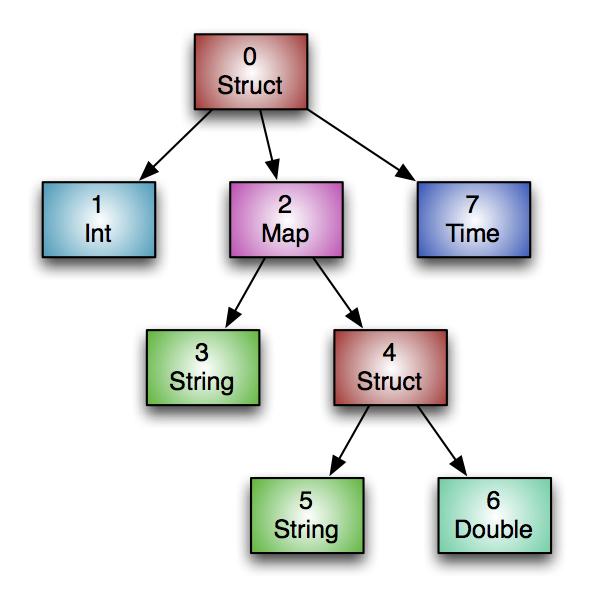
For example, for the following tree the column names could be stored in a vector as {"1", "2", "4", "6", "7", "5", "3"}. |
|
I don't know who and how the column names are being used. But does anyone have objections to storing the names in a flat vector? If so can you please explain what the problem is with a vector? |
|
As long as it's clearly documented how to map the nested structure to a flat list of names (e.g.: pre-order traversal as in the example above), I'm cool with using a vector of names rather than an explicit tree-like structure. |
|
The ORC specification has some nice graphics in the "Type Information' section. |
{kind=link}
There have been a number of requests related to adding column names, either to the
column's themselves and/or totables and their views.libcudfinternals don't use column names, so we need requirements to be driven by users that will make use of the names (cuIO/Spark/cuDF).For those who need column names, please discuss what you would like to see for column names.
CC @kkraus14 @revans2 @jlowe @j-ieong @shwina
The text was updated successfully, but these errors were encountered: