Query - is there a way to bypass security restrictions on a pdf? #53
Comments
|
For PyPDF2 to be able to decrypt a file, you need either the owner password or the user password. However, PyPDF2 does not seem to have the algorithm necessary to decrypt your PDF anyway. Perhaps you could try saving the document as a new file (if you have permission) in Adobe Reader or similar and then it may be possible for you to access security settings, where you can turn security off. You may also be able to upload the file to Google Drive. The upload settings should be on 'convert text and images from uploaded PDF'. Once uploaded, you can open the file with Microsoft Word and convert it back to a PDF (with no restrictions). I haven't had to use any of these methods myself, so I don't know for sure if they'll work, but hopefully you can resolve this. There are also several 3rd party applications that claim to remove restrictions from PDFs. |
|
Thanks, I need to do this programmatically as I don't always have access to the file (users upload the files). Another service, that is similar to the service I'm building seems to handle the case fine (without converting to images). I'll give the google drive sdk a go and see if I can get this to work. |
|
@Rob1080 Did you ever resolve this? I am dealing with the same problem. |
|
I'd be very interested by a solution too |
|
I did some testing last night with a few secured pdfs. There is another screen you can get in adobe which shows the "Encryption Level". PDFs that show "128-bit AES" in this field raise |
|
Yeah, I have the case of 128b AES encryption so I can view it (in adobe or chrome) but not edit/merge it |
|
I spent a couple hours yesterday trying to hack away at this but wasn't able to make progress. PDF.JS is an open source library that implements support for this. You can see the code at the link below. I think a lot of the code could be replaced by using the PyCrypto library. However there a still some things I don't understand. Namely, how to expand the encryption key to the correct length. And what exactly to decrypt (obviously not the whole file, as some of it is unencrypted). https://github.com/mozilla/pdf.js/blob/master/src/core/crypto.js |
|
I used qpdf and the following hack-y code to decrypt the documents if PyPDF2 fails at decryption. Be careful not to accept any user input for the filename for your application using this code, if you do, be sure to sanitize it before os.system executes it. |
|
Hello, Thank you for your question, comments, and/or concerns regarding PyPDF2. Sincerely, Selma Kishwar Phaseit, Inc. On Mon, Aug 24, 2015 at 4:11 PM, lrehmann [email protected] wrote:
|
|
Hello, Thank you for your question, comments, and/or concerns regarding PyPDF2. Sincerely, Selma Kishwar Phaseit, Inc. On Tue, May 26, 2015 at 4:07 PM, Gordon Cassie [email protected]
|
Here's a very heavily commented explanation of how (and why) to do that subprocess call safely: import os, shutil, tempdir
# Things from the subprocess module don't rely on the shell unless you
# explicitly ask for it and can accept a pre-split list of arguments,
# making calling subprocesses much safer.
# (If you really do need to split quoted stuff, use shlex.split() instead)
from subprocess import check_call
# [...]
# Use try/finally to ensure our cleanup code gets run
try:
# There are a lot of ways to mess up creating temporary files in a way
# that's free of race conditions, so just use mkdtemp() to safely
# create a temporary folder that only we have permission to work inside
# (We ask for it to be made in the same folder as filename because /tmp
# might be on a different drive, which would make the final overwrite
# into a slow "copy and delete" rather than a fast os.rename())
tempdir = tempfile.mkdtemp(dir=os.path.dirname(filename))
# I'm not sure if a qpdf failure could leave the file in a halfway
# state, so have it write to a temporary file instead of reading from one
temp_out = os.path.join(tempdir, 'qpdf_out.pdf')
# Avoid the shell when possible and integrate with Python errors
# (check_call() raises subprocess.CalledProcessError on nonzero exit)
check_call(['qpdf', "--password=", '--decrypt', filename, temp_out])
# I'm not sure if a qpdf failure could leave the file in a halfway
# state, so write to a temporary file and then use os.rename to
# overwrite the original atomically.
# (We use shutil.move instead of os.rename so it'll fall back to a copy
# operation if the dir= argument to mkdtemp() gets removed)
shutil.move(temp_out, filename)
print 'File Decrypted (qpdf)'
finally:
# Delete all temporary files
shutil.rmtree(tempdir) |
|
Any workaround for windows? |
|
The |
|
Here is my workaround inspired by @ssokolow above. My setup requires files to be read from and output as bytes objects in the context of reader = PdfFileReader(io.BytesIO(document_data))
if reader.isEncrypted:
try:
reader.decrypt("")
except NotImplementedError:
# Decrypt the PDF with qpdf
temp_file = tempfile.NamedTemporaryFile(delete=False)
temp_file.write(document_data)
temp_file_name = temp_file.name
temp_file.close()
decrypted_filename = f"{temp_file_name}.decrypted"
command = f"qpdf --password= --decrypt {temp_file_name} {decrypted_filename}"
try:
status = subprocess.check_call(
command, shell=True, cwd="/tmp", timeout=300
)
with open(decrypted_filename, "rb") as f:
decrypted_document_data = f.read()
reader = PdfFileReader(
io.BytesIO(decrypted_document_data)
)
finally:
os.unlink(temp_file_name)
try:
# decrypted_filename may or may not have been created
os.unlink(decrypted_filename)
except FileNotFoundError:
pass |
@robsco-git Thanks, you can further get rid of |
Fixed: must have forgotten to delete that part 😅 |
|
The |
I have a pdf that has security restrictions. I need to merge some content into the secured pdf. I don't need the pdf to be secured after the merge.
When I open the file and check isEncrypted, it returns true.
When I try decrypt with empty string there's a notImplementedError raised "only algorithm code 1 and 2 are supported".
The restrictions on the file are shown below.
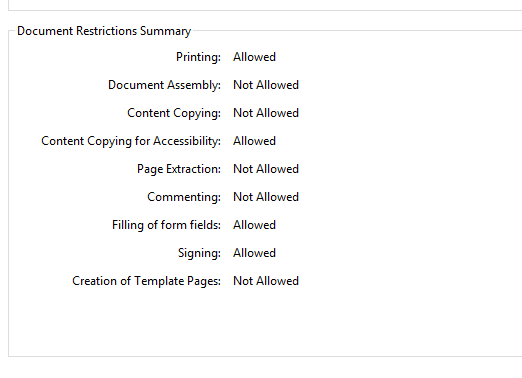
At the moment, to bypass the restrictions on the file, I print the pdf to images and create a new pdf with those images. This isn't ideal as the file size becomes large and the content isn't as crisp.
Is there a better way?
The text was updated successfully, but these errors were encountered: