System do analizy wpisów na portalu
Do uruchomienia konieczna jest Java w wersji 8 oraz baza danych mysql
- Kompilacja systemu
./gradlew clean build
- Uruchomienie systemu
java -jar build/libs/portal.jar
- Po całkowitym uruchomieniu systemu, możliwe będzie wpisywanie odpowiednich komend. Gdy system będzie gotowy zostanie wyświetlone
2020-01-12 16:50:13.006 INFO 61926 --- [ main] portal.Main : Started Main in 7.216 seconds (JVM running for 7.913)
shell:>
- crawl-git-hub: Pobiera komentarze z podanego repozytorium GitHub i zapisuje do bazy danych. Podczas przetwarzania inny wątek pobiera nowo powstałe wpisy i je analizuje
- statistic:all: Wyświetla statystki przetworzonych wpisów dla wszystkich projektów
- statistic:for:project: Wyświetla statystki przetworzonych wpisów dla konkretnego projektów
Głównym celem projektu jest stworzenie systemu do analizy tekstu wybranego portalu. System będzie pobierał zawartości wpisów użytkowników, a następnie korzystając z API NLP (Natural Language Processing) każdy wpis będzie klasyfikowany według kilku zdefiniowanych kategorii.
System nie będzie posiadał graficznego interfejsu użytkownika, natomiast użytkownik w konsoli będzie mógł przeglądać sklasyfikowane wpisy. WebScrapper będzie pobierał oraz przetwarzał wpisy, a następnie zapisywał je do bazy danych w celach statycznych.
System musi:
- posiadać dostęp do internetu
- posiadać dostęp do bazy danych, aby zapisywać sklasyfikowane wpisy w celach statystycznych
- posiadać zdefiniowaną strukturę wpisów konkretnego portalu (nie można użyć jednej struktury do kilku portali, ze względu na zupełnie różne podejścia tworzenia witryn internetowych)
- posiadać dostęp do API NLP (Natural Language Processing)
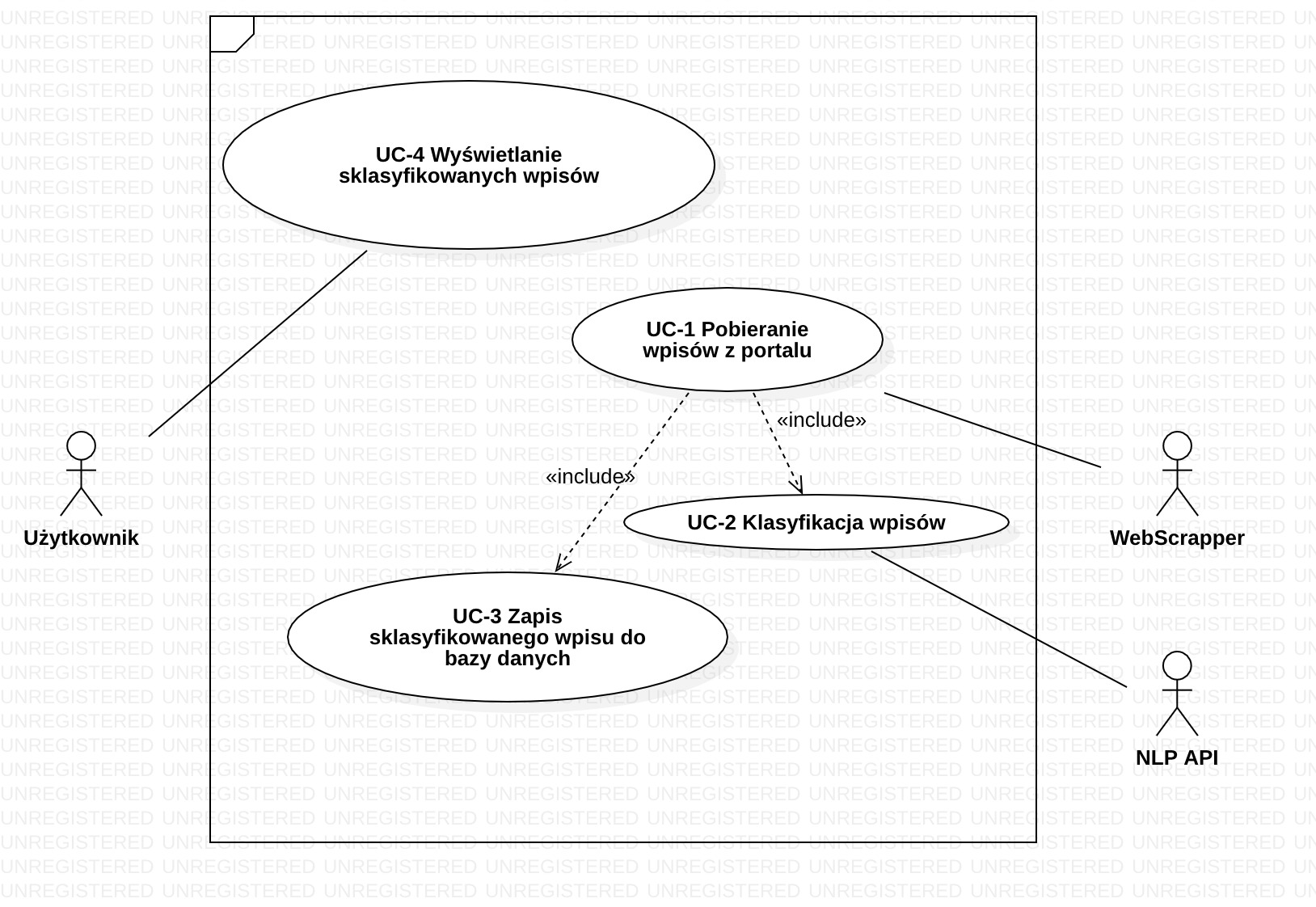
Użytkownik - posiada dostęp do konsoli, w której może przeglądać oraz wyświetlać sklasyfikowane wpisy WebScrapper - zajmuję się przetwarzaniem wpisów. Jest odpowiedzialny tylko za dostarczanie danych do systemu
UC-1 Pobieranie wpisów z portalu
- Cel: Pobranie zawartości portalu oraz wybranie przydatnych danych ze struktury html
- Aktor główny: WebScrapper
- Warunek początkowy: Wpis nie istnieje w bazie danych
-
Gł. scenariusz:
- WebScrapper wchodzi na stronę internetową portalu
- Pobiera zawartość
- Przetwarza w poszukiwaniu wpisu
- Pobiera kolejne linki z wpisami
UC-2 Klasyfikacja wpisów
- Cel: Pobrany wpis zostaje przetworzony przez API NLP, która dokona klasyfikacji wpisu
- Aktor główny: WebScrapper
- Warunek początkowy: Wpis posiada zawartość oraz jest w języku angielskim
-
Gł. scenariusz:
- WebScrapper przekazuje pobrany wpis do API NLP
- Biblioteka po przetworzeniu zwraca informacje o klasyfikacji
UC-3 Zapis sklasyfikowanego wpisu do bazy danych
- Cel: Sklasyfikowany wpis zostaje zapisy do bazy danych
- Aktor główny: WebScrapper
- Warunek początkowy: Wpis został poprawnie sklasyfikowany przez API NLP
-
Gł. scenariusz:
- WebScrapper zapisuje wpis do bazy danych
UC-4 Wyświetlanie sklasyfikowanych wpisów
- Cel: Udostępnienie użytkowniki możliwości przeglądania sklasyfikowanych wpisów
- Aktor główny: Użytkownik
- Warunek początkowy: W bazie danych znajdują się sklasyfikowane wpisy
-
Gł. scenariusz:
- Użytkownik uruchamia konsolę
- W oknie konsoli wybiera dostępne klasyfikacje
- System zwraca dostępne klasyfikacje oraz powiązane z nimi wpisy
Aplikacja
- system powinien być wydajny
- system powinien w szybko sposób reagować na wydarzenia
Baza danych
- Baza danych zrealizowana w MySQL
- Pełen backup bazy danych powinien być tworzony przynajmniej raz w tygodniu
Wsparcie techniczne
- Dostępna instrukcja użytkownika
- Po wdrożeniu systemu możliwość jego aktualizacji oraz rozbudowy aplikacji o nowe funkcjonalności
Aspekty prawne
- System powinien przestrzegać zarządzenia RODO o ochronie praw osobowych
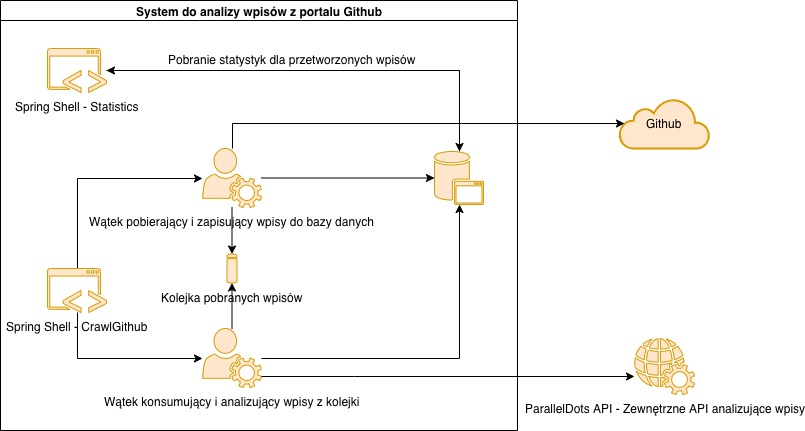
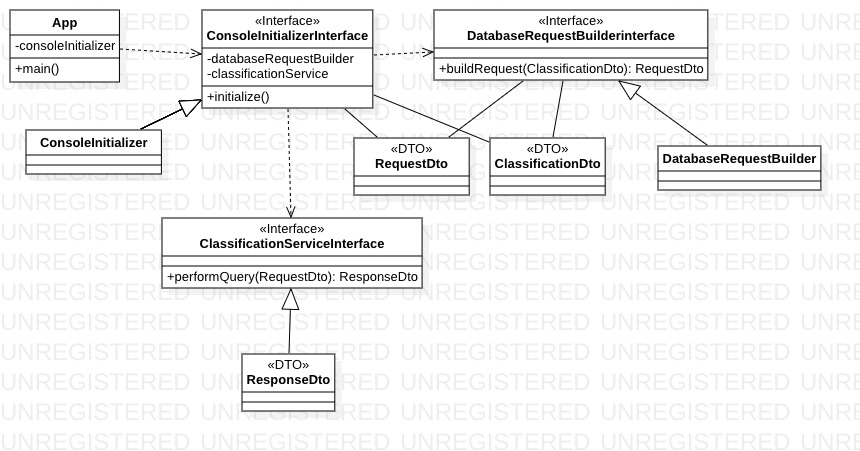
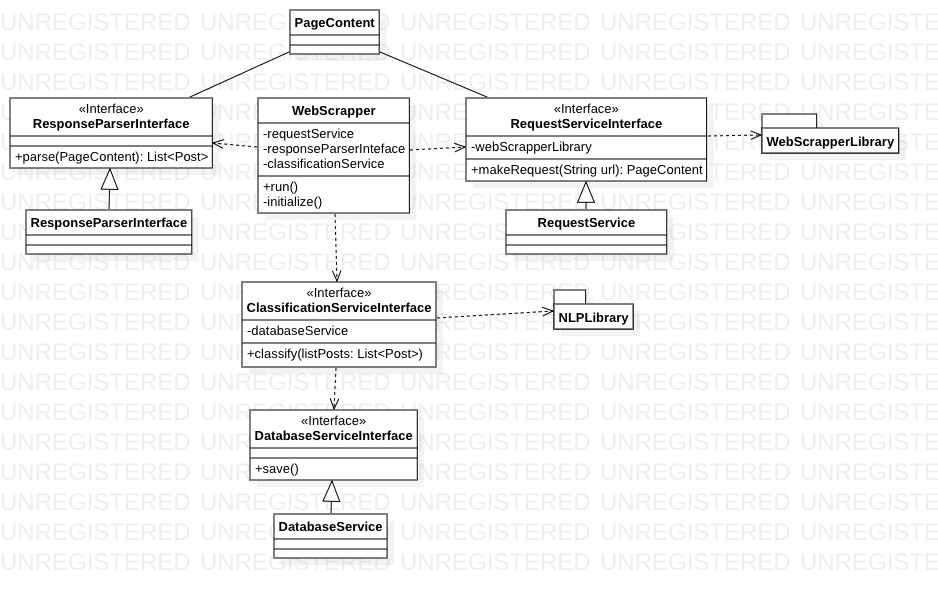
- System zostanie zaimplementowany w języku Java
- Użytkownik będzie korzystał z konsoli
- WebScrapper będzie korzystał z biblioteki Apache Nutch, do pobierania wpisów z portalu
- WebScrapper będzie korzystał z API ParallelDots-Java-API, do klasyfikowania wpisów
- Dane będą zapisywane w bazie danych MySQL
- Testy jednostkowe poszczególnych klas
- Testy integracyjne zapisu danych do bazy danych
- Testy integracyjne odczytu danych z bazy danych
- Testy sprawdzające funkcjonalność pobierania wpisów z portalu
- Webscrapping portalu
- Analiza wpisów
- Konsola użytkownika
- Testy
- Prezentacja projektu
- Dokumentacja systemu