voice-fn is a Clojure framework for building real-time voice AI applications using a data-driven, functional approach. Built on top of clojure.core.async.flow, it provides a composable pipeline architecture for processing audio, text, and AI interactions with built-in support for major AI providers.
This project's status is experimental. Expect breaking changes.
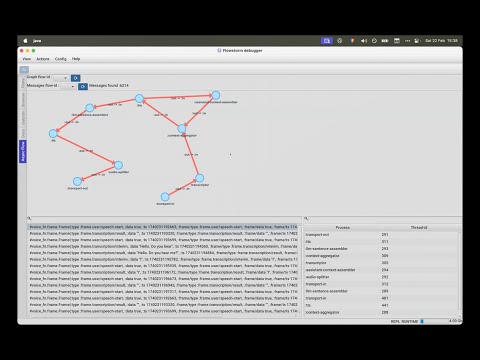
- Flow-Based Architecture: Built on
core.async.flowfor robust concurrent processing - Data-First Design: Define AI pipelines as data structures for easy configuration and modification
- Streaming Architecture: Efficient real-time audio and text processing
- Extensible Processors: Simple protocol-based system for adding new processing components
- Flexible Frame System: Type-safe message passing between pipeline components
- Built-in Services: Ready-to-use integrations with major AI providers
First, create a resources/secrets.edn:
{:deepgram {:api-key ""}
:elevenlabs {:api-key ""
:voice-id ""}
:groq {:api-key ""}
:openai {:new-api-sk ""}}Obtain the API keys from the respective providers and fill in the blank values.
Start a REPL and evaluate the snippets in the (comment ...) blocks to start the flows.
Allow Microphone access when prompted.
(ns voice-fn-examples.local
(:require
[clojure.core.async :as a]
[clojure.core.async.flow :as flow]
[taoensso.telemere :as t]
[voice-fn.processors.deepgram :as asr]
[voice-fn.processors.elevenlabs :as tts]
[voice-fn.processors.llm-context-aggregator :as context]
[voice-fn.processors.openai :as llm]
[voice-fn.secrets :refer [secret]]
[voice-fn.transport :as transport]
[voice-fn.utils.core :as u]))
(defn make-local-flow
"This example showcases a voice AI agent for the local computer. Audio is
usually encoded as PCM at 16kHz frequency (sample rate) and it is mono (1
channel).
"
([] (make-local-flow {}))
([{:keys [llm-context extra-procs extra-conns encoding debug?
sample-rate language sample-size-bits channels chunk-duration-ms]
:or {llm-context {:messages [{:role "system"
:content "You are a helpful assistant "}]}
encoding :pcm-signed
sample-rate 16000
sample-size-bits 16
channels 1
chunk-duration-ms 20
language :en
debug? false
extra-procs {}
extra-conns []}}]
(flow/create-flow
{:procs
(u/deep-merge
{;; Capture audio from microphone and send raw-audio-input frames further in the pipeline
:transport-in {:proc transport/microphone-transport-in
:args {:audio-in/sample-rate sample-rate
:audio-in/channels channels
:audio-in/sample-size-bits sample-size-bits}}
;; raw-audio-input -> transcription frames
:transcriptor {:proc asr/deepgram-processor
:args {:transcription/api-key (secret [:deepgram :api-key])
:transcription/interim-results? true
:transcription/punctuate? false
:transcription/vad-events? true
:transcription/smart-format? true
:transcription/model :nova-2
:transcription/utterance-end-ms 1000
:transcription/language language
:transcription/encoding encoding
:transcription/sample-rate sample-rate}}
;; user transcription & llm message frames -> llm-context frames
;; responsible for keeping the full conversation history
:context-aggregator {:proc context/context-aggregator
:args {:llm/context llm-context
:aggregator/debug? debug?}}
;; Takes llm-context frames and produces new llm-text-chunk & llm-tool-call-chunk frames
:llm {:proc llm/openai-llm-process
:args {:openai/api-key (secret [:openai :new-api-sk])
:llm/model "gpt-4o-mini"}}
;; llm-text-chunk & llm-tool-call-chunk -> llm-context-messages-append frames
:assistant-context-assembler {:proc context/assistant-context-assembler
:args {:debug? debug?}}
;; llm-text-chunk -> sentence speak frames (faster for text to speech)
:llm-sentence-assembler {:proc context/llm-sentence-assembler}
;; speak-frames -> audio-output-raw frames
:tts {:proc tts/elevenlabs-tts-process
:args {:elevenlabs/api-key (secret [:elevenlabs :api-key])
:elevenlabs/model-id "eleven_flash_v2_5"
:elevenlabs/voice-id (secret [:elevenlabs :voice-id])
:voice/stability 0.5
:voice/similarity-boost 0.8
:voice/use-speaker-boost? true
:flow/language language
:audio.out/encoding encoding
:audio.out/sample-rate sample-rate}}
;; audio-output-raw -> smaller audio-output-raw frames (used for sending audio in realtime)
:audio-splitter {:proc transport/audio-splitter
:args {:audio.out/sample-rate sample-rate
:audio.out/sample-size-bits sample-size-bits
:audio.out/channels channels
:audio.out/duration-ms chunk-duration-ms}}
;; speakers out
:transport-out {:proc transport/realtime-speakers-out-processor
:args {:audio.out/sample-rate sample-rate
:audio.out/sample-size-bits sample-size-bits
:audio.out/channels channels
:audio.out/duration-ms chunk-duration-ms}}}
extra-procs)
:conns (concat
[[[:transport-in :out] [:transcriptor :in]]
[[:transcriptor :out] [:context-aggregator :in]]
[[:context-aggregator :out] [:llm :in]]
;; Aggregate full context
[[:llm :out] [:assistant-context-assembler :in]]
[[:assistant-context-assembler :out] [:context-aggregator :in]]
;; Assemble sentence by sentence for fast speech
[[:llm :out] [:llm-sentence-assembler :in]]
[[:llm-sentence-assembler :out] [:tts :in]]
[[:tts :out] [:audio-splitter :in]]
[[:audio-splitter :out] [:transport-out :in]]]
extra-conns)})))
(def local-ai (make-local-flow))
(comment
;; Start local ai flow - starts paused
(let [{:keys [report-chan error-chan]} (flow/start local-ai)]
(a/go-loop []
(when-let [[msg c] (a/alts! [report-chan error-chan])]
(when (map? msg)
(t/log! {:level :debug :id (if (= c error-chan) :error :report)} msg))
(recur))))
;; Resume local ai -> you can now speak with the AI
(flow/resume local-ai)
;; Stop the conversation
(flow/stop local-ai)
,)Which roughly translates to:

See examples for more usages.
- ElevenLabs
- Models:
eleven_multilingual_v2,eleven_turbo_v2,eleven_flash_v2and more. - Features: Real-time streaming, multiple voices, multilingual support
- Models:
- Deepgram
- Models:
nova-2,nova-2-general,nova-2-meetingand more. - Features: Real-time transcription, punctuation, smart formatting
- Models:
- OpenAI
- Models:
gpt-4o-mini(fastest, cheapest),gpt-4,gpt-3.5-turboand more - Features: Function calling, streaming responses
- Models:
The core building block of voice-fn pipelines:
- Composed of processes connected by channels
- Processes can be:
- Input/output handlers
- AI service integrations
- Data transformers
- Managed by
core.async.flowfor lifecycle control
The modality through which audio comes and goes from the voice ai pipeline. Example transport modalities:
- local (microphone + speakers)
- telephony (twilio through websocket)
- webRTC (browser support) - TODO
- async (through in & out core async channels)
You will see processors like :transport-in & :transport-out
The basic unit of data flow, representing typed messages like:
:audio/input-raw- Raw audio data:transcription/result- Transcribed text:llm/text-chunk- LLM response chunks:system/start,:system/stop- Control signals
Each frame has a type and optionally a schema for the data contained in it.
See frame.clj for all possible frames.
Components that transform frames:
- Define input/output requirements
- Can maintain state
- Use core.async for async processing
- Implement the
flow/processprotocol
(defn custom-processor []
(flow/process
{:describe (fn [] {:ins {:in "Input channel"}
:outs {:out "Output channel"}})
:init identity
:transform (fn [state in msg]
[state {:out [(process-message msg)]}])}))Read core.async.flow docs for more information about flow precesses.
- core.async - Concurrent processing
- core.async.flow - Flow control
- Hato - WebSocket support
- Malli - Schema validation
Voice-fn takes heavy inspiration from pipecat. Differences:
- voice-fn uses a graph instead of a bidirectional queue for frame transport
- voice-fn has a data centric implementation. The processors in voice-fn are
pure functions in the
core.async.flowtransform syntax
MIT