GoDevGuide
本文从服务器领域的问题本身出发,并不局限于Go语言,探讨服务器中常常遇到的问题,每个问题回到Go如何解决,从而提供Go开发的技术指南。服务器领域的问题包括常见的并发等问题,也涉及到了工程化相关的问题,也整理了C背景程序员对于Go的GC以及性能的疑问,探讨了Go的错误处理和类型系统最佳实践,以及依赖管理的难处,接口设计的正交性,当然也包含我们在RTC服务器中对于Go实践的总结,有时候也对一些有趣的问题做深度的挖掘,也列出了Go重要的事件和资料集合,还有Go2的进展和思考。
本文主要发布于简书,欢迎来简书阅读本文。完整的Markdown也在github。


原图链接地址:https://www.processon.com/view/link/5df22829e4b010171a411e7d#map
感谢阿里巴巴云原生微信公众号转载了这篇文章,给了很重要的改进建议,从Markdown转微信公众号也做了大量工作,配图和排版让阅读变成一种享受。如果你更习惯微信阅读,可以读下面四章:
- Go 开发关键技术指南 | 为什么你要选择 Go?
- Go 开发关键技术指南 | Go 面向失败编程
- Go 开发关键技术指南 | 带着服务器编程金刚经走进 2020 年
- Go 开发关键技术指南 | 敢问路在何方?
本文讨论了服务器领域常见的并发等问题,也涉及到了工程化相关的问题,也整理了C背景程序员对于Go的GC以及性能的疑问,探讨了Go的错误处理和类型系统最佳实践,以及依赖管理的难处,接口设计的正交性,当然也包含我们在服务器开发中对于Go实践的总结,有时候也对一些有趣的问题做深度的挖掘,也列出了Go重要的事件和资料集合,还有Go2的进展和思考。我更想从问题本身出发,不局限于Go语言,探讨服务器中常常遇到的问题,最后回到Go如何解决这些问题,提供Go开发的关键技术指南。
下面是各个章节以及简介:
- About the Name 为何Go有时候也叫Golang?
- Why Go? 为何要选择Go作为服务器开发的语言?是冲动?还是骚动?
- Milestones Go的重要里程碑和事件,当年吹的那些牛逼,都实现了哪些?
- Could Not Recover 君可知,有什么panic是无法recover的?包括超过系统线程限制,以及map的竞争写。当然一般都能recover,比如Slice越界、nil指针、除零、写关闭的chan等。
- Errors 为什么Go2的草稿3个有2个是关于错误处理的?好的错误处理应该怎么做?错误和异常机制的差别是什么?错误处理和日志如何配合?
- Logger 为什么标准库的Logger是完全不够用的?怎么做日志切割和轮转?怎么在混成一坨的服务器日志中找到某个连接的日志?甚至连接中的流的日志?怎么做到简洁又够用?
- Type System 什么是面向对象的SOLID原则?为何Go更符合SOLID?为何接口组合比继承多态更具有正交性?Go类型系统如何做到looser, organic, decoupled, independent, and therefore scalable?
- Orthogonal 一般软件中如果出现数学,要么真的牛逼要么装逼。正交性这个数学概念在Go中频繁出现,是神仙还是妖怪?为何接口设计要考虑正交性?
- Modules 如何避免依赖地狱(Dependency Hell)?小小的版本号为何会带来大灾难?Go为什么推出了GOPATH、Vendor还要搞module和vgo?新建了16个仓库做测试,碰到了9个坑,搞清楚了gopath和vendor如何迁移,以及vgo with vendor如何使用(毕竟生产环境不能每次都去外网下载)。
- Concurrency 服务器中的并发处理难在哪里?为什么说Go并发处理优势占领了云计算开发语言市场?什么是C10K、C10M问题?
- Context 如何管理goroutine的取消、超时和关联取消?为何Go1.7专门将context放到了标准库?context如何使用,以及问题在哪里?
- Engineering Go在工程化上的优势是什么?为什么说Go是一门面向工程的语言?覆盖率要到多少比较合适?什么叫代码可测性?为什么良好的库必须先写Example?
- Go2 Transition Go2会像Python3不兼容Python2那样作吗?C和C++的语言演进可以有什么不同的收获?Go2怎么思考语言升级的问题?
- GC Go的GC靠谱吗?Twitter说相当的靠谱,有图有真相
- Declaration Syntax 为何Go的声明语法是那样?C的又是怎样?是拍的大腿,还是拍的脑袋?
- Documents Go官网的重要文档分类,本屌丝读了四遍了,推荐阅读
- SRS Go在流媒体服务器中的使用。
The Go Programming Language到底是该叫GO还是GOLANG?Google搜Why Go is called Golang能搜到几篇经典帖子。
Rob Pike在Twitter上特意说明是Go,可以看这个The language is called Go:
Neither. The language is called Go, not Golang. http://golang.org is just the the web site address, not the name of the language.
那么在另外一个地方也说明了也是Go,可以看这个The name of our language is go:
The name of our language is Go
Ruby is called Ruby, not Rubylang.
Python is called Python, not Pythonlang.
C is called C, not Clang. No. Wait. That was a bad example.
Go is called Go, not Golang.
Yes, yes, I know all about the searching and meta tags. Sure, whatever,
but that doesn't change the fact that the name of the language is Go.
Thank you for your consideration.
这里举了各种例子说明为何不加lang的后缀,当然有个典型的语言是加的,就是Erlang。于是就有回复说“Erlang Erlang, Let's just call it Er.”
那么为何很多时候Go和Golang都很常用呢?在Why is the Go programming language usually called Golang中说的比较清楚:
It’s because “go domain” has been registered by Walt Disney and so Go creators couldn’t use it.
So, they have decided to use golang for the domain name. Then the rest came.
Also, it’s harder to search things on search engines just using the word Go. Although, Rob Pike is
against this idea but I disagree. Most of the time, for the correct results you need to search for
golang.
It’s just Go, not golang but it sticked to it.
讲个笑话先,用百度搜下为何Go叫做Golang,一大片都是类似本文的鸡汤煲,告诉你为何Go才是天地间最合适你的语言,当然本文要成为鸡汤煲中的战斗煲,告诉你全家都应该选择Go语言。
为何Go语言名字是Go,但是经常说成是Golang呢?有以下理由:
- go.org被注册了,正在卖,也不贵才1698万。所以Go只能用golang.org。
- 搜点啥信息如果搜go,太宽泛了,特别是go还没有这么多用户时,搜golang能更精确的找到答案。
为什么在名字上要这么纠结呢?嗯嗯,不纠结,让我们开始干鸡汤吧。
考虑一个商用的快速发展的业务后端服务器,最重要的是什么?当然是稳定性了,如果崩溃可能会造成用户服务中断,崩溃的问题在C/C++服务器中几乎是必然的:
- 稳定是一种假象。想象一个C服务器,一般不会重头码所有的代码,会从一个开源版本开始,或者从一些网络和线程库开始,然后不断改进和完善,由于业务前期并不复杂,上线也没有发现问题,这时候可以说C服务器是稳定的吗?当然不是,只是Bug没有触发而已,所有崩溃的Bug都几乎不是本次发布导致的问题。野指针和越界是C服务器中最难搞定的狼人,这些狼人还喜欢玩潜伏。
- 稳定是短暂,不稳定是必然和长期。一般业务会突飞猛进,特别是越偏上层的业务,需要后端处理的逻辑就越多,至于UTest和测试一般只存在于传说中,随着业务的发展,潜伏的狼人越来越多,甚至开源的库和服务器中的狼人也开始出来作妖。夜路走多了,总会碰到鬼。碰到鬼了怎么办,遇鬼杀鬼了,还能被它吓尿不成,所以就反思解决Bug,费了老劲了,又白了几根头发,终于迎来短暂安宁,然后继续写Bug。
- 最普遍的问题还是内存问题导致崩溃,一般就是野指针和越界。空指针问题相对很容易查,除零之类的典型错误也容易处理。最完善的解决办法,就是实现GC,让指针总是有效,无效后再释放,越界时能检测到这样容易解决问题;嗯,其实Go早期的版本就和这个很类似了,要实现带GC的C的同学,可以参考下Go的实现。
- 线上的CPU和内存的问题,一般不方便使用工具查看,而线上的问题有时候很难在本地重现。如何能直接获取线上的Profile数据,需要程序本身支持。比如提供HTTP API能获取到Profile数据?关键是如何采集这些数据。
Go的使命愿景和价值观:
Go is an open source programming language that makes it easy to build simple, reliable, and efficient software.
Go is a concurrent open source programming language developed at Google. Combines native compilation and static types with a lightweight dynamic feel. Fast, fun, and productive.
Go is an attempt to make programmers more productive. The first goal is to make a better language to meet the challenges of scalable concurrency. The larger goal is to make a better environment to meet the challenges of scalable software development, software worked on and used by many people, with limited coordination between them, and maintained for years.
Go语言的关键字:
- 运行性能高: Statically typed. Native code generation (compiled). Efficiency. Fast development cycle.
- 码农不苦逼: Memory safe. Garbage collected. Safety.
- 云计算专享: Native concurrency support. Concurrency. Scalability.
- 工程师思维: Composition via interfaces. Excellent standard library. Great tools.
参考The Path to Go1: What is Go?和Another Go at Language Design。
Go是面向软件工程的语言,Go在工程上的思考可以读Go at Google: Language Design in the Service of Software Engineering和Less is exponentially more。Go最初是解决Google遇到的大规模系统和计算的问题,这些问题如今被称为云计算,参考Go, Open Source, Community。
GITHUT上显示Go的项目和PR一直在上升,如下图所示。
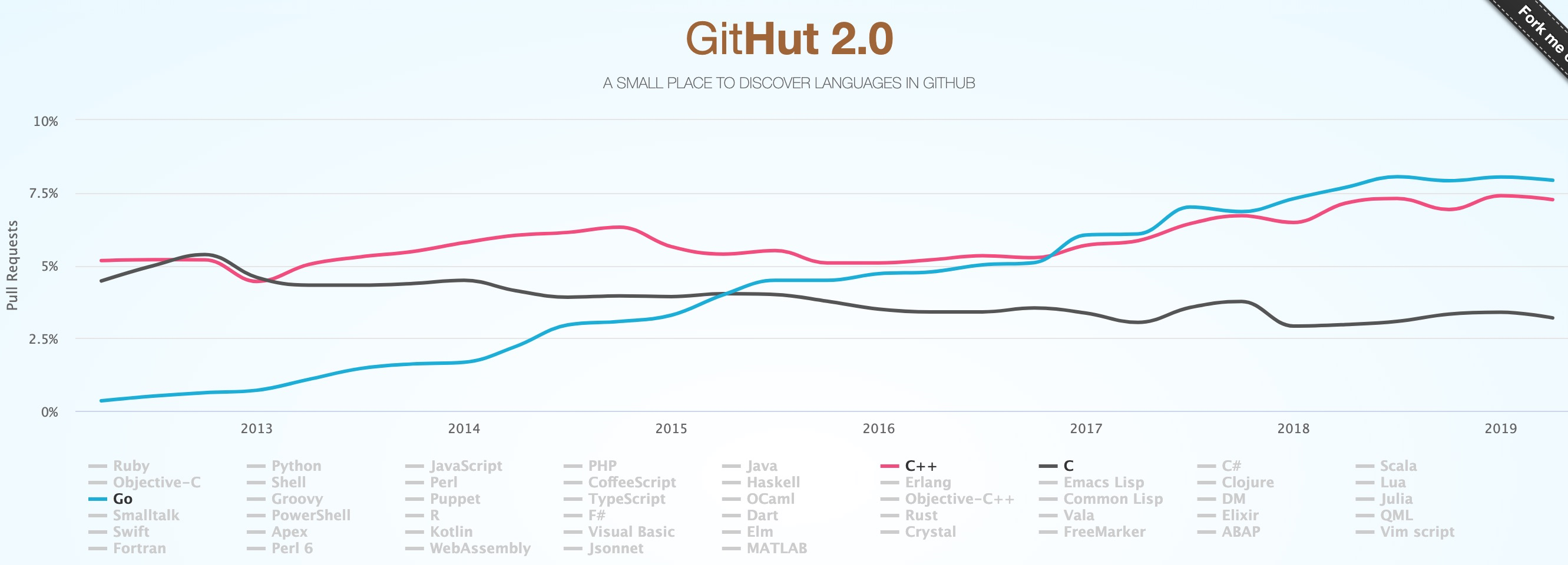
2014云计算行业中使用Go的有:Docker, Kubernetes, Packer, Serf, InfluxDB, Cloud Foundry’s gorouter and CLI, CoreOS’s etcd and fleet, Vitess, YouTube’s tooling for MySQL scaling, Canonical’s Juju (rewritten in Go), Mozilla’s Heka, A Go interface to OpenStack Swift, Heroku’s Force.com and hk CLIs, Apcera’s NATS and gnatsd。
2018年全球使用Go的公司数目有:US(329), Japan(79), Brazil(52), India(49), Indonesia(45), China(32), UK(32), Germany(28), Israel(24), France(17), Netherlands(16), Canada (15), Thailand(14), Turkey(14), Spain(12), Poland(11), Australia(9), Russia(9), Iran(8), Sweden(7), Korea(South)(6), Switzerland(6), Ukraine(5)。
参考Go as the emerging language of cloud infrastructure,以及The RedMonk Programming Language Rankings: June 2018,还有GoUsers,以及Success Stories。
参考Nine years of Go: Go Contributors,社区贡献的代码比例。
我们一起看看这些Go牛逼的特性,详细分析每个点,虽然不能涵盖所有的点,对于常用的Go的特性我们做一次探讨和分析。
看看Go做到了哪些,Go的重要事件:
- 2020.02, Go1.14发布。可在产品中使用modules,极大提高defer性能,抢占式goroutine调度。
- 2019.09, Go1.13发布。增强了modules,新增了环境变量GOPRIVATE和GOSUMDB,GOPROXY支持多个。支持了ErrorWraping。
- 2019.02, Go1.12发布,支持了TLS1.3,改进了modules,优化运行时和标准库。
- 2018.08, Go1.11发布,实验性支持modules,实验性支持WebAssembly
- 2018.02, Go1.10发布,go tool缓存编译,编译加速,很多细微的改进。
- 2018.01, Hello, 中国!, 中国站镜像上线,大陆可以访问官网资源。
- 2017.08, Go1.9发布,支持Type Alias,支持sync.Map,使用场景参考slides,time保持单增避免时间测量问题。
- 2017.02, Go1.8发布,显著的性能提升,GC延迟降低到了10us到100us,支持HTTP/2 Push,HTTP Server支持Shutdown,
sort.Slice使排序使用更简单。 - 2016.08, Go1.7发布,支持了Context,Context在K8S和Docker中都有应用,新的编译算法减少20-30%的二进制尺寸。
- 2016.02, Go1.6发布,支持HTTP/2,HTTPS时会默认开启HTTP/2,正式支持vendor。
- 2015.08, Go1.5发布,完全用Go代替了C代码,完全重新设计和重新实现GC,支持internal的package,实验性支持vendor,GOMAXPROCS默认为CPU个数。
- 2014.12, Go1.4发布,支持Android,从Mecurial迁移到了Git,从GoogleCode迁移到了Github: golang/go,大部分runtime的代码从C改成了Go,
for支持三种迭代写法。 - 2014.06, Go1.3发布,支持了FreeBSD,Plan9,Solaris等系统。
- 2013.12, Go1.2发布,新增收集覆盖率工具coverage,限制了最高线程数ThreadLimit。
- 2013.05, Go1.1发布,主要是包含性能优化,新增
Data Race Detector等。 - 2012.03, Go1.0发布,包含了基本的语言元素比如rune、error、map,标准库包括bufio、crypto、flag、http、net、os、regexp、runtime、unsafe、url、encoding等。
- 2009.11, Google宣布要开发一门新语言,既要开源,又有Python的好处,还要有C/C++的性能。GO是BSD的License,大部分GO的项目都是BSD或MIT或Apache等商业友好的协议。
在C/C++中最苦恼的莫过于上线后发现有野指针或内存越界,导致不可能崩溃的地方崩溃;最无语的是因为很早写的日志打印比如%s把整数当字符串,突然某天执行到了崩溃;最无奈的是无论因为什么崩溃都导致服务的所有用户收到影响。
如果能有一种方案,将指针和内存都管理起来,避免用户错误访问和释放,这样虽然浪费了一部分的CPU,但是可以在快速变化的业务中避免这些头疼的问题。在现代的高级语言中,比如Java、Python和JS的异常,Go的panic-recover都是这种机制。
毕竟,用一些CPU换得快速迭代中的不Crash,怎么算都是划得来的。
Go有Defer, Panic, and Recover。其中defer一般用在资源释放或者捕获panic。而panic是中止正常的执行流程,执行所有的defer,返回调用函数继续panic;主动调用panic函数,还有些运行时错误都会进入panic过程。最后recover是在panic时获取控制权,进入正常的执行逻辑。
注意recover只有在defer函数中才有用,在defer的函数调用的函数中recover不起作用,如下实例代码不会recover:
package main
import "fmt"
func main() {
f := func() {
if r := recover(); r != nil {
fmt.Println(r)
}
}
defer func() {
f()
} ()
panic("ok")
}执行时依旧会panic,结果如下:
$ go run t.go
panic: ok
goroutine 1 [running]:
main.main()
/Users/winlin/temp/t.go:16 +0x6b
exit status 2
有些情况是不可以被捕获,程序会自动退出,这种都是无法正常recover。当然,一般的panic都是能捕获的,比如Slice越界、nil指针、除零、写关闭的chan。
下面是Slice越界的例子,recover可以捕获到:
package main
import (
"fmt"
)
func main() {
defer func() {
if r := recover(); r != nil {
fmt.Println(r)
}
}()
b := []int{0, 1}
fmt.Println("Hello, playground", b[2])
}下面是nil指针被引用的例子,recover可以捕获到:
package main
import (
"bytes"
"fmt"
)
func main() {
defer func() {
if r := recover(); r != nil {
fmt.Println(r)
}
}()
var b *bytes.Buffer
fmt.Println("Hello, playground", b.Bytes())
}下面是除零的例子,recover可以捕获到:
package main
import (
"fmt"
)
func main() {
defer func() {
if r := recover(); r != nil {
fmt.Println(r)
}
}()
var v int
fmt.Println("Hello, playground", 1/v)
}下面是写关闭的chan的例子,recover可以捕获到:
package main
import (
"fmt"
)
func main() {
defer func() {
if r := recover(); r != nil {
fmt.Println(r)
}
}()
c := make(chan bool)
close(c)
c <- true
}一般recover后会判断是否为err,有可能需要处理特殊的error,一般也需要打印日志或者告警,给一个recover的例子:
package main
import (
"fmt"
)
type Handler interface {
Filter(err error, r interface{}) error
}
type Logger interface {
Ef(format string, a ...interface{})
}
// Handle panic by hdr, which filter the error.
// Finally log err with logger.
func HandlePanic(hdr Handler, logger Logger) error {
return handlePanic(recover(), hdr, logger)
}
type hdrFunc func(err error, r interface{}) error
func (v hdrFunc) Filter(err error, r interface{}) error {
return v(err, r)
}
type loggerFunc func(format string, a ...interface{})
func (v loggerFunc) Ef(format string, a ...interface{}) {
v(format, a...)
}
// Handle panic by hdr, which filter the error.
// Finally log err with logger.
func HandlePanicFunc(hdr func(err error, r interface{}) error,
logger func(format string, a ...interface{}),
) error {
var f Handler
if hdr != nil {
f = hdrFunc(hdr)
}
var l Logger
if logger != nil {
l = loggerFunc(logger)
}
return handlePanic(recover(), f, l)
}
func handlePanic(r interface{}, hdr Handler, logger Logger) error {
if r != nil {
err, ok := r.(error)
if !ok {
err = fmt.Errorf("r is %v", r)
}
if hdr != nil {
err = hdr.Filter(err, r)
}
if err != nil && logger != nil {
logger.Ef("panic err %+v", err)
}
return err
}
return nil
}
func main() {
func() {
defer HandlePanicFunc(nil, func(format string, a ...interface{}) {
fmt.Println(fmt.Sprintf(format, a...))
})
panic("ok")
}()
logger := func(format string, a ...interface{}) {
fmt.Println(fmt.Sprintf(format, a...))
}
func() {
defer HandlePanicFunc(nil, logger)
panic("ok")
}()
}对于库如果需要启动goroutine,如何recover呢:
- 如果不可能出现panic,可以不用recover,比如tls.go中的一个goroutine:
errChannel <- conn.Handshake() - 如果可能出现panic,也比较明确的可以recover,可以用调用用户回调,或者让用户设置logger,比如http/server.go处理请求的goroutine:
if err := recover(); err != nil && err != ErrAbortHandler { - 如果完全不知道如何处理recover,比如一个cache库,丢弃数据可能会造成问题,那么就应该由用户来启动goroutine,返回异常数据和错误,用户决定如何recover如何重试。
- 如果完全知道如何recover,比如忽略panic继续跑,或者能使用logger打印日志,那就按照正常的panic-recover逻辑处理。
下面看看一些情况是无法捕获的,包括(不限于):
- Thread Limit,超过了系统的线程限制,详细参考下面的说明。
- Concurrent Map Writers,竞争条件,同时写map,参考下面的例子。推荐使用标准库的
sync.Map解决这个问题。
package main
import (
"fmt"
"time"
)
func main() {
m := map[string]int{}
p := func() {
defer func() {
if r := recover(); r != nil {
fmt.Println(r)
}
}()
for {
m["t"] = 0
}
}
go p()
go p()
time.Sleep(1 * time.Second)
}注意:如果编译时加了
-race,其他竞争条件也会退出,一般用于死锁检测,但这会导致严重的性能问题,使用需要谨慎。
备注:一般标准库中通过
throw抛出的错误都是无法recover的,搜索了下Go1.11一共有690个地方有调用throw。
Go1.2引入了能使用的最多线程数限制ThreadLimit,如果超过了就panic,这个panic是无法recover的。
fatal error: thread exhaustion
runtime stack:
runtime.throw(0x10b60fd, 0x11)
/usr/local/Cellar/go/1.8.3/libexec/src/runtime/panic.go:596 +0x95
runtime.mstart()
/usr/local/Cellar/go/1.8.3/libexec/src/runtime/proc.go:1132
默认是1万个物理线程,我们可以调用runtime的debug.SetMaxThreads设置最大线程数。
SetMaxThreads sets the maximum number of operating system threads that the Go program can use. If it attempts to use more than this many, the program crashes. SetMaxThreads returns the previous setting. The initial setting is 10,000 threads.
用这个函数设置程序能使用的最大系统线程数,如果超过了程序就crash。返回的是之前设置的值,默认是1万个线程。
The limit controls the number of operating system threads, not the number of goroutines. A Go program creates a new thread only when a goroutine is ready to run but all the existing threads are blocked in system calls, cgo calls, or are locked to other goroutines due to use of runtime.LockOSThread.
注意限制的并不是goroutine的数目,而是使用的系统线程的限制。goroutine启动时,并不总是新开系统线程,只有当目前所有的物理线程都阻塞在系统调用,cgo调用,或者显示有调用runtime.LockOSThread时。
SetMaxThreads is useful mainly for limiting the damage done by programs that create an unbounded number of threads. The idea is to take down the program before it takes down the operating system.
这个是最后的防御措施,可以在程序干死系统前把有问题的程序干掉。
举一个简单的例子,限制使用10个线程,然后用runtime.LockOSThread来绑定goroutine到系统线程,可以看到没有创建10个goroutine就退出了(runtime也需要使用线程)。参考下面的例子Playground: ThreadLimit:
package main
import (
"fmt"
"runtime"
"runtime/debug"
"sync"
"time"
)
func main() {
nv := 10
ov := debug.SetMaxThreads(nv)
fmt.Println(fmt.Sprintf("Change max threads %d=>%d", ov, nv))
var wg sync.WaitGroup
c := make(chan bool, 0)
for i := 0; i < 10; i++ {
fmt.Println(fmt.Sprintf("Start goroutine #%v", i))
wg.Add(1)
go func() {
c <- true
defer wg.Done()
runtime.LockOSThread()
time.Sleep(10 * time.Second)
fmt.Println("Goroutine quit")
}()
<- c
fmt.Println(fmt.Sprintf("Start goroutine #%v ok", i))
}
fmt.Println("Wait for all goroutines about 10s...")
wg.Wait()
fmt.Println("All goroutines done")
}运行结果如下:
Change max threads 10000=>10
Start goroutine #0
Start goroutine #0 ok
......
Start goroutine #6
Start goroutine #6 ok
Start goroutine #7
runtime: program exceeds 10-thread limit
fatal error: thread exhaustion
runtime stack:
runtime.throw(0xffdef, 0x11)
/usr/local/go/src/runtime/panic.go:616 +0x100
runtime.checkmcount()
/usr/local/go/src/runtime/proc.go:542 +0x100
......
/usr/local/go/src/runtime/proc.go:1830 +0x40
runtime.startm(0x1040e000, 0x1040e000)
/usr/local/go/src/runtime/proc.go:2002 +0x180从这次运行可以看出,限制可用的物理线程为10个,其中系统占用了3个物理线程,user-level可运行7个线程,开启第8个线程时就崩溃了。
注意这个运行结果在不同的go版本是不同的,比如Go1.8有时候启动4到5个goroutine就会崩溃。
而且加recover也无法恢复,参考下面的实例代码。可见这个机制是最后的防御,不能突破的底线。我们在线上服务时,曾经因为block的goroutine过多,导致触发了这个机制。
package main
import (
"fmt"
"runtime"
"runtime/debug"
"sync"
"time"
)
func main() {
defer func() {
if r := recover(); r != nil {
fmt.Println("main recover is", r)
}
} ()
nv := 10
ov := debug.SetMaxThreads(nv)
fmt.Println(fmt.Sprintf("Change max threads %d=>%d", ov, nv))
var wg sync.WaitGroup
c := make(chan bool, 0)
for i := 0; i < 10; i++ {
fmt.Println(fmt.Sprintf("Start goroutine #%v", i))
wg.Add(1)
go func() {
c <- true
defer func() {
if r := recover(); r != nil {
fmt.Println("main recover is", r)
}
} ()
defer wg.Done()
runtime.LockOSThread()
time.Sleep(10 * time.Second)
fmt.Println("Goroutine quit")
}()
<- c
fmt.Println(fmt.Sprintf("Start goroutine #%v ok", i))
}
fmt.Println("Wait for all goroutines about 10s...")
wg.Wait()
fmt.Println("All goroutines done")
}如何避免程序超过线程限制被干掉?一般可能阻塞在system call,那么什么时候会阻塞?还有,GOMAXPROCS又有什么作用呢?
The GOMAXPROCS variable limits the number of operating system threads that can execute user-level Go code simultaneously. There is no limit to the number of threads that can be blocked in system calls on behalf of Go code; those do not count against the GOMAXPROCS limit. This package's GOMAXPROCS function queries and changes the limit.
GOMAXPROCS sets the maximum number of CPUs that can be executing simultaneously and returns the previous setting. If n < 1, it does not change the current setting. The number of logical CPUs on the local machine can be queried with NumCPU. This call will go away when the scheduler improves.
可见GOMAXPROCS只是设置user-level并行执行的线程数,也就是真正执行的线程数 。实际上如果物理线程阻塞在system calls,实际上会开启更多的物理线程。关于这个参数的说明,这个文章Number of threads used by goroutine解释得很清楚:
There is no direct correlation. Threads used by your app may be less than, equal to or more than 10.
So if your application does not start any new goroutines, threads count will be less than 10.
If your app starts many goroutines (>10) where none is blocking (e.g. in system calls), 10 operating system threads will execute your goroutines simultaneously.
If your app starts many goroutines where many (>10) are blocked in system calls, more than 10 OS threads will be spawned (but only at most 10 will be executing user-level Go code).
设置GOMAXPROCS为10:如果开启的goroutine小于10个,那么物理线程也小于10个。如果有很多goroutines,但是没有阻塞在system calls,那么只有10个线程会并行执行。如果有很多goroutines同时超过10个阻塞在system calls,那么超过10个物理线程会被创建,但是只有10个活跃的线程执行user-level代码。
那么什么时候会阻塞在system blocking呢?这个例子Why does it not create many threads when many goroutines are blocked in writing解释很清楚,虽然设置了GOMAXPROCS为1,但是实际上还是开启了12个线程,每个goroutine一个物理线程,具体执行下面的代码Writing Large Block:
package main
import (
"io/ioutil"
"os"
"runtime"
"strconv"
"sync"
)
func main() {
runtime.GOMAXPROCS(1)
data := make([]byte, 128*1024*1024)
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func(n int) {
defer wg.Done()
for {
ioutil.WriteFile("testxxx"+strconv.Itoa(n), []byte(data), os.ModePerm)
}
}(i)
}
wg.Wait()
}运行结果如下:
Mac chengli.ycl$ time go run t.go
real 1m44.679s
user 0m0.230s
sys 0m53.474s虽然GOMAXPROCS设置为1,实际上创建了12个物理线程。
有大量的时间是在sys上面,也就是system calls。
So I think the syscalls were exiting too quickly in your original test to show the effect you were expecting.
Effective Go中的解释:
Goroutines are multiplexed onto multiple OS threads so if one should block, such as while waiting for I/O, others continue to run. Their design hides many of the complexities of thread creation and management.
由此可见,如果程序出现因为超过线程限制而崩溃,那么可以在出现瓶颈时,用linux工具查看系统调用的统计,看哪些系统调用导致创建了过多的线程。
错误处理是现实中经常碰到的、难以处理好的问题,下面会从下面几个方面探讨错误处理:
- 为什么Go没有选择异常,而是返回错误码(error)? 因为异常模型很难看出有没有写对,错误码方式也不容易,相对会简单点。
- Go的error有什么问题,为何Go2草案这么大篇幅说error改进? 因为Go虽然是错误码但还不够好,问题在于啰嗦、繁杂、缺失关键信息。
- 有哪些好用的error库,如何和日志配合使用? 推荐用库pkg/errors;另外,避免日志和错误混淆。
- Go的错误处理最佳实践是什么? 配合日志使用错误。错误需要带上上下文、堆栈等信息。
我们总会遇到非预期的非正常情况,有一种是符合预期的,比如函数返回error并处理,这种叫做可以预见到的错误,还有一种是预见不到的比如除零、空指针、数组越界等叫做panic,panic的处理主要参考Defer, Panic, and Recover。
错误处理的模型一般有两种,一般是错误码模型比如C/C++和Go,还有异常模型比如Java和C#。Go没有选择异常模型,因为错误码比异常更有优势,参考文章Cleaner, more elegant, and wrong 以及Cleaner, more elegant, and harder to recognize。看下面的代码:
try {
AccessDatabase accessDb = new AccessDatabase();
accessDb.GenerateDatabase();
} catch (Exception e) {
// Inspect caught exception
}
public void GenerateDatabase()
{
CreatePhysicalDatabase();
CreateTables();
CreateIndexes();
}
这段代码的错误处理有很多问题,比如如果CreateIndexes抛出异常,会导致数据库和表不会删除,造成脏数据。从代码编写者和维护者的角度看这两个模型,会比较清楚:
| Really Easy | Hard | Really Hard |
|---|---|---|
| Writing bad error-code-based code Writing bad exception-based code |
Writing good error-code-based code |
Writing good exception-based code |
错误处理不容易做好,要说容易那说明做错了;要把错误处理写对了,基于错误码模型虽然很难,但比异常模型简单。
| Really Easy | Hard | Really Hard |
|---|---|---|
| Recognizing that error-code-based code is badly-written Recognizing the difference between bad error-code-based code and not-bad error-code-based code. |
Recognizing that error-code-base code is not badly-written |
Recognizing that exception-based code is badly-written Recognizing that exception-based code is not badly-written Recognizing the difference between bad exception-based code and not-bad exception-based code |
如果使用错误码模型,非常容易就能看出错误处理没有写对,也能很容易知道做得好不好;要知道是否做得非常好,错误码模型也不太容易。 如果使用异常模型,无论做的好不好都很难知道,而且也很难知道怎么做好。
Go官方的error介绍,简单一句话就是返回错误对象的方式,参考Error handling and Go,解释了error是什么,如何判断具体的错误,显式返回错误的好处。文中举的例子就是打开文件错误:
func Open(name string) (file *File, err error)
Go可以返回多个值,最后一个一般是error,我们需要检查和处理这个错误,这就是Go的错误处理的官方介绍:
if err := Open("src.txt"); err != nil {
// Handle err
}
看起来非常简单的错误处理,有什么难的呢?骚等,在Go2的草案中,提到的三个点Error Handling、Error Values和Generics泛型,两个点都是错误处理的,这说明了Go1中对于错误是有改进的地方。
再详细看下Go2的草案,错误处理:Error Handling中,主要描述了发生错误时的重复代码,以及不能便捷处理错误的情况。比如草案中举的这个例子No Error Handling: CopyFile,没有做任何错误处理:
package main
import (
"fmt"
"io"
"os"
)
func CopyFile(src, dst string) error {
r, _ := os.Open(src)
defer r.Close()
w, _ := os.Create(dst)
io.Copy(w, r)
w.Close()
return nil
}
func main() {
fmt.Println(CopyFile("src.txt", "dst.txt"))
}还有草案中这个例子Not Nice and still Wrong: CopyFile,错误处理是特别啰嗦,而且比较明显有问题:
package main
import (
"fmt"
"io"
"os"
)
func CopyFile(src, dst string) error {
r, err := os.Open(src)
if err != nil {
return err
}
defer r.Close()
w, err := os.Create(dst)
if err != nil {
return err
}
defer w.Close()
if _, err := io.Copy(w, r); err != nil {
return err
}
if err := w.Close(); err != nil {
return err
}
return nil
}
func main() {
fmt.Println(CopyFile("src.txt", "dst.txt"))
}当io.Copy或w.Close出现错误时,目标文件实际上是有问题,那应该需要删除dst文件的。而且需要给出错误时的信息,比如是哪个文件,不能直接返回err。所以Go中正确的错误处理,应该是这个例子Good: CopyFile,虽然啰嗦繁琐不简洁:
package main
import (
"fmt"
"io"
"os"
)
func CopyFile(src, dst string) error {
r, err := os.Open(src)
if err != nil {
return fmt.Errorf("copy %s %s: %v", src, dst, err)
}
defer r.Close()
w, err := os.Create(dst)
if err != nil {
return fmt.Errorf("copy %s %s: %v", src, dst, err)
}
if _, err := io.Copy(w, r); err != nil {
w.Close()
os.Remove(dst)
return fmt.Errorf("copy %s %s: %v", src, dst, err)
}
if err := w.Close(); err != nil {
os.Remove(dst)
return fmt.Errorf("copy %s %s: %v", src, dst, err)
}
return nil
}
func main() {
fmt.Println(CopyFile("src.txt", "dst.txt"))
}具体应该如何简洁的处理错误,可以读Error Handling,大致是引入关键字handle和check,由于本文重点侧重Go1如何错误处理,就不展开分享了。
明显上面每次都返回的fmt.Errorf信息也是不够的,所以Go2还对于错误的值有提案,参考Error Values。大规模程序应该面向错误编程和测试,同时错误应该包含足够的信息。Go1中判断error具体是什么错误有几种办法:
- 直接比较,比如返回的是
io.EOF这个全局变量,那么可以直接比较是否是这个错误。 - 可以用类型转换type或switch,尝试来转换成具体的错误类型,看是哪种错误。
- 提供某些函数来判断是否是某个错误,比如
os.IsNotExist判断是否是指定错误。 - 当多个错误被糅合到一起时,只能用
error.Error()返回的字符串匹配,看是否是某个错误。
在复杂程序中,有用的错误需要包含调用链的信息。例如,考虑一次数据库写,可能调用了RPC,RPC调用了域名解析,最终是没有权限读/etc/resolve.conf文件,那么给出下面的调用链会非常有用:
write users database: call myserver.Method: \
dial myserver:3333: open /etc/resolv.conf: permission denied
由于Go1的错误值没有完整的解决这个问题,才导致出现非常多的错误处理的库,比如:
- 2017, 12, upspin.io/errors,带逻辑调用堆栈的错误库,而不是执行的堆栈,引入了
errors.Is、errors.As和errors.Match。 - 2015.12, github.com/pkg/errors,带堆栈的错误,引入了
%+v来格式化错误的额外信息比如堆栈。 - 2014.10, github.com/hashicorp/errwrap,可以wrap多个错误,引入了错误树,提供Walk函数遍历所有的错误。
- 2014.2, github.com/juju/errgo,Wrap时可以选择是否隐藏底层错误。和
pkg/errors的Cause返回最底层的错误不同,它只反馈错误链的下一个错误。 - 2013.7, github.com/spacemonkeygo/errors,是来源于一个大型Python项目,有错误的hierarchies,自动记录日志和堆栈,还可以带额外的信息。打印错误的消息比较固定,不能自己定义。
- 2019.09,Go1.13标准库扩展了error,支持了Unwrap、As和Is,但没有支持堆栈信息。
Go1.13改进了errors,参考如下实例代码:
package main
import (
"errors"
"fmt"
"io"
)
func foo() error {
return fmt.Errorf("read err: %w", io.EOF)
}
func bar() error {
if err := foo(); err != nil {
return fmt.Errorf("foo err: %w", err)
}
return nil
}
func main() {
if err := bar(); err != nil {
fmt.Printf("err: %+v\n", err)
fmt.Printf("unwrap: %+v\n", errors.Unwrap(err))
fmt.Printf("unwrap of unwrap: %+v\n", errors.Unwrap(errors.Unwrap(err)))
fmt.Printf("err is io.EOF? %v\n", errors.Is(err, io.EOF))
}
}运行结果如下:
err: foo err: read err: EOF
unwrap: read err: EOF
unwrap of unwrap: EOF
err is io.EOF? true
从上面的例子可以看出:
- 没有堆栈信息,主要是想通过Wrap的日志来标识堆栈,如果全部Wrap一层和堆栈差不多,不过对于没有Wrap的错误还是无法知道调用堆栈。
- Unwrap只会展开第一个嵌套的error,如果错误有多层嵌套,取不到最里面的那个error,需要多次Unwrap才行。
- 用
errors.Is能判断出是否是最里面的那个error。
另外,错误处理往往和log是容易混为一谈的,因为遇到错误一般会打日志,特别是在C/C++中返回错误码一般都会打日志记录下,有时候还会记录一个全局的错误码比如linux的errno,而这种习惯,造成了error和log混淆造成比较大的困扰。考虑以前写了一个C++的服务器,出现错误时会在每一层打印日志,所以就会形成堆栈式的错误日志,便于排查问题,如果只有一个错误,不知道调用上下文,排查会很困难:
avc decode avc_packet_type failed. ret=3001
Codec parse video failed, ret=3001
origin hub error, ret=3001
这种比只打印一条日志origin hub error, ret=3001要好,但是还不够好:
- 和Go的错误一样,比较啰嗦,有重复的信息。如果能提供堆栈信息,可以省去很多需要手动写的信息。
- 对于应用程序可以打日志,但是对于库,信息都应该包含在error中,不应该直接打印日志。如果底层的库都要打印日志,那会导致底层库都要依赖日志库,这是很多库都有日志打印函数供调用者重写。
- 对于多线程,看不到线程信息,或者看不到业务层ID的信息。对于服务器来说,有时候需要知道这个错误是哪个连接的,从而查询这个连接之前的上下文信息。
改进后的错误日志变成了在底层返回,而不在底层打印在调用层打印,有调用链和堆栈,有线程切换的ID信息,也有文件的行数:
Error processing video, code=3001 : origin hub : codec parser : avc decoder
[100] video_avc_demux() at [srs_kernel_codec.cpp:676]
[100] on_video() at [srs_app_source.cpp:1076]
[101] on_video_imp() at [srs_app_source:2357]
从Go2的描述来说,实际上这个错误处理也还没有考虑完备。从实际开发来说,已经比较实用了。
总结下Go的error,错误处理应该注意的点:
- 凡是有返回错误码的函数,必须显式的处理错误,如果要忽略错误,也应该显式的忽略和写注释。
- 错误必须带丰富的错误信息,比如堆栈,发生错误时的参数,调用链给的描述等等。特别要强调变量,我看过太多日志描述了一对常量,比如"Verify the nonce, timestamp and token of specified appid failed",而这个消息一般会提到工单中,然后就是再问用户,哪个session或request甚至时间点?这么一大堆常量有啥用呢,关键是变量,关键是变量呐。
- 尽量避免重复的信息,提高错误处理的开发体验,糟糕的体验会导致无效的错误处理代码比如拷贝和漏掉关键信息。
- 分离错误和日志,发生错误时返回带完整信息的错误,在调用的顶层决定是将错误用日志打印,还是发送到监控系统,还是转换错误,或者忽略。
推荐用github.com/pkg/errors这个错误处理的库,基本上是够用的,参考Refine: CopyFile,可以看到CopyFile中低级重复的代码已经比较少了:
package main
import (
"fmt"
"github.com/pkg/errors"
"io"
"os"
)
func CopyFile(src, dst string) error {
r, err := os.Open(src)
if err != nil {
return errors.Wrap(err, "open source")
}
defer r.Close()
w, err := os.Create(dst)
if err != nil {
return errors.Wrap(err, "create dest")
}
nn, err := io.Copy(w, r)
if err != nil {
w.Close()
os.Remove(dst)
return errors.Wrap(err, "copy body")
}
if err := w.Close(); err != nil {
os.Remove(dst)
return errors.Wrapf(err, "close dest, nn=%v", nn)
}
return nil
}
func LoadSystem() error {
src, dst := "src.txt", "dst.txt"
if err := CopyFile(src, dst); err != nil {
return errors.WithMessage(err, fmt.Sprintf("load src=%v, dst=%v", src, dst))
}
// Do other jobs.
return nil
}
func main() {
if err := LoadSystem(); err != nil {
fmt.Printf("err %+v\n", err)
}
}改写的函数中,用
errors.Wrap和errors.Wrapf代替了fmt.Errorf,我们不记录src和dst的值,因为在上层会记录这个值(参考下面的代码),而只记录我们这个函数产生的数据,比如nn。
import "github.com/pkg/errors"
func LoadSystem() error {
src, dst := "src.txt", "dst.txt"
if err := CopyFile(src, dst); err != nil {
return errors.WithMessage(err, fmt.Sprintf("load src=%v, dst=%v", src, dst))
}
// Do other jobs.
return nil
}
在这个上层函数中,我们用的是
errors.WithMessage添加了这一层的错误信息,包括src和dst,所以CopyFile里面就不用重复记录这两个数据了。同时我们也没有打印日志,只是返回了带完整信息的错误。
func main() {
if err := LoadSystem(); err != nil {
fmt.Printf("err %+v\n", err)
}
}
在顶层调用时,我们拿到错误,可以决定是打印还是忽略还是送监控系统。
比如我们在调用层打印错误,使用%+v打印详细的错误,有完整的信息:
err open src.txt: no such file or directory
open source
main.CopyFile
/Users/winlin/t.go:13
main.LoadSystem
/Users/winlin/t.go:39
main.main
/Users/winlin/t.go:49
runtime.main
/usr/local/Cellar/go/1.8.3/libexec/src/runtime/proc.go:185
runtime.goexit
/usr/local/Cellar/go/1.8.3/libexec/src/runtime/asm_amd64.s:2197
load src=src.txt, dst=dst.txt
但是这个库也有些小毛病:
-
CopyFile中还是有可能会有重复的信息,还是Go2的handle和check方案是最终解决。 - 有时候需要用户调用
Wrap,有时候是调用WithMessage(不需要加堆栈时),这个真是非常不好用的地方(这个我们已经修改了库,可以全部使用Wrap不用WithMessage,会去掉重复的堆栈)。
一直在码代码,对日志的理解总是不断在变,大致分为几个阶段:
- 日志是给人看的,是用来查问题的。出现问题后根据某些条件,去查不同进程或服务的日志。日志的关键是不能漏掉信息,漏了关键日志,可能就断了关键的线索。
- 日志必须要被关联起来,上下文的日志比单个日志更重要。长连接需要根据会话关联日志;不同业务模型有不同的上下文,比如服务器管理把服务器作为关键信息,查询这个服务器的相关日志;全链路跨机器和服务的日志跟踪,需要定义可追踪的逻辑ID。
- 海量日志是给机器看的,是结构化的,能主动报告问题,能从日志中分析潜在的问题。日志的关键是要被不同消费者消费,要输出不同主题的日志,不同的粒度的日志。日志可以用于排查问题,可以用于告警,可以用于分析业务情况。
Note: 推荐阅读Kafka对于Log的定义,广义日志是可以理解的消息,The Log: What every software engineer should know about real-time data's unifying abstraction。
考虑一个服务,处理不同的连接的请求:
package main
import (
"context"
"fmt"
"log"
"math/rand"
"os"
"time"
)
type Connection struct {
url string
logger *log.Logger
}
func (v *Connection) Process(ctx context.Context) {
go checkRequest(ctx, v.url)
duration := time.Duration(rand.Int()%1500) * time.Millisecond
time.Sleep(duration)
v.logger.Println("Process connection ok")
}
func checkRequest(ctx context.Context, url string) {
duration := time.Duration(rand.Int()%1500) * time.Millisecond
time.Sleep(duration)
logger.Println("Check request ok")
}
var logger *log.Logger
func main() {
ctx := context.Background()
rand.Seed(time.Now().UnixNano())
logger = log.New(os.Stdout, "", log.LstdFlags)
for i := 0; i < 5; i++ {
go func(url string) {
connecton := &Connection{}
connecton.url = url
connecton.logger = logger
connecton.Process(ctx)
}(fmt.Sprintf("url #%v", i))
}
time.Sleep(3 * time.Second)
}这个日志的主要问题,就是有了和没有差不多,啥也看不出来,常量太多变量太少,缺失了太多的信息。看起来这是个简单问题,却经常容易犯这种问题,需要我们在打印每个日志时,需要思考这个日志比较完善的信息是什么。上面程序输出的日志如下:
2019/11/21 17:08:04 Check request ok
2019/11/21 17:08:04 Check request ok
2019/11/21 17:08:04 Check request ok
2019/11/21 17:08:04 Process connection ok
2019/11/21 17:08:05 Process connection ok
2019/11/21 17:08:05 Check request ok
2019/11/21 17:08:05 Process connection ok
2019/11/21 17:08:05 Check request ok
2019/11/21 17:08:05 Process connection ok
2019/11/21 17:08:05 Process connection ok如果完善下上下文信息,代码可以改成这样:
type Connection struct {
url string
logger *log.Logger
}
func (v *Connection) Process(ctx context.Context) {
go checkRequest(ctx, v.url)
duration := time.Duration(rand.Int()%1500) * time.Millisecond
time.Sleep(duration)
v.logger.Println(fmt.Sprintf("Process connection ok, url=%v, duration=%v", v.url, duration))
}
func checkRequest(ctx context.Context, url string) {
duration := time.Duration(rand.Int()%1500) * time.Millisecond
time.Sleep(duration)
logger.Println(fmt.Sprintf("Check request ok, url=%v, duration=%v", url, duration))
}输出的日志如下:
2019/11/21 17:11:35 Check request ok, url=url #3, duration=32ms
2019/11/21 17:11:35 Check request ok, url=url #0, duration=226ms
2019/11/21 17:11:35 Process connection ok, url=url #0, duration=255ms
2019/11/21 17:11:35 Check request ok, url=url #4, duration=396ms
2019/11/21 17:11:35 Check request ok, url=url #2, duration=449ms
2019/11/21 17:11:35 Process connection ok, url=url #2, duration=780ms
2019/11/21 17:11:35 Check request ok, url=url #1, duration=1.01s
2019/11/21 17:11:36 Process connection ok, url=url #4, duration=1.099s
2019/11/21 17:11:36 Process connection ok, url=url #3, duration=1.207s
2019/11/21 17:11:36 Process connection ok, url=url #1, duration=1.257s完善日志信息后,对于服务器特有的一个问题,就是如何关联上下文,常见的上下文包括:
- 如果是短连接,一条日志就能描述,那可能要将多个服务的日志关联起来,将全链路的日志作为上下文。
- 如果是长连接,一般长连接一定会有定时信息,比如每隔5秒输出这个链接的码率和包数,这样每个链接就无法使用一条日志描述了,链接本身就是一个上下文。
- 进程内的逻辑上下文,比如代理的上下游就是一个上下文,合并回源,故障上下文,客户端重试等。
以上面的代码为例,可以用请求URL来作为上下文,
package main
import (
"context"
"fmt"
"log"
"math/rand"
"os"
"time"
)
type Connection struct {
url string
logger *log.Logger
}
func (v *Connection) Process(ctx context.Context) {
go checkRequest(ctx, v.url)
duration := time.Duration(rand.Int()%1500) * time.Millisecond
time.Sleep(duration)
v.logger.Println(fmt.Sprintf("Process connection ok, duration=%v", duration))
}
func checkRequest(ctx context.Context, url string) {
duration := time.Duration(rand.Int()%1500) * time.Millisecond
time.Sleep(duration)
logger.Println(fmt.Sprintf("Check request ok, url=%v, duration=%v", url, duration))
}
var logger *log.Logger
func main() {
ctx := context.Background()
rand.Seed(time.Now().UnixNano())
logger = log.New(os.Stdout, "", log.LstdFlags)
for i := 0; i < 5; i++ {
go func(url string) {
connecton := &Connection{}
connecton.url = url
connecton.logger = log.New(os.Stdout, fmt.Sprintf("[CONN %v] ", url), log.LstdFlags)
connecton.Process(ctx)
}(fmt.Sprintf("url #%v", i))
}
time.Sleep(3 * time.Second)
}运行结果如下所示:
[CONN url #2] 2019/11/21 17:19:28 Process connection ok, duration=39ms
2019/11/21 17:19:28 Check request ok, url=url #0, duration=149ms
2019/11/21 17:19:28 Check request ok, url=url #1, duration=255ms
[CONN url #3] 2019/11/21 17:19:28 Process connection ok, duration=409ms
2019/11/21 17:19:28 Check request ok, url=url #2, duration=408ms
[CONN url #1] 2019/11/21 17:19:29 Process connection ok, duration=594ms
2019/11/21 17:19:29 Check request ok, url=url #4, duration=615ms
[CONN url #0] 2019/11/21 17:19:29 Process connection ok, duration=727ms
2019/11/21 17:19:29 Check request ok, url=url #3, duration=1.105s
[CONN url #4] 2019/11/21 17:19:29 Process connection ok, duration=1.289s
如果需要查连接2的日志,可以grep这个url #2关键字:
Mac:gogogo chengli.ycl$ grep 'url #2' t.log
[CONN url #2] 2019/11/21 17:21:43 Process connection ok, duration=682ms
2019/11/21 17:21:43 Check request ok, url=url #2, duration=998ms
燃鹅,还是发现有不少问题:
- 如何实现隐式标识,调用时如何简单些,不用没打一条日志都需要传一堆参数?
- 一般logger是公共函数(或者是每个类一个logger),而上下文的生命周期会比logger长,比如checkRequest是个全局函数,标识信息必须依靠人打印,这往往是不可行的。
- 如何实现日志的logrotate(切割和轮转),如何收集多个服务器日志。
解决办法包括:
- 用Context的WithValue来将上下文相关的ID保存,在打印日志时将ID取出来。
- 如果有业务特征,比如可以取SessionID的hash的前8个字符形成ID,虽然容易碰撞,但是在一定范围内不容易碰撞。
- 可以变成json格式的日志,这样可以将level、id、tag、file、err都变成可以程序分析的数据,送到SLS中处理。
- 对于切割和轮转,推荐使用lumberjack这个库,程序的logger只要提供
SetOutput(io.Writer)将日志送给它处理就可以了。
当然,这要求函数传参时需要带context.Context,一般在自己的应用程序中可以要求这么做,凡是打日志的地方要带context。对于库,一般可以不打日志,而返回带堆栈的复杂错误的方式,参考Errors错误处理部分。
Go在类型和接口上的思考是:
Go的类型系统是比较容易和C++/Java混淆的,特别是习惯于类体系和虚函数的思路后,很容易想在Go走这个路子,可惜是走不通的。而interface因为太过于简单,而且和C++/Java中的概念差异不是特别明显,所以这个章节专门分析Go的类型系统。
先看一个典型的问题Is it possible to call overridden method from parent struct in golang?,代码如下所示:
package main
import (
"fmt"
)
type A struct {
}
func (a *A) Foo() {
fmt.Println("A.Foo()")
}
func (a *A) Bar() {
a.Foo()
}
type B struct {
A
}
func (b *B) Foo() {
fmt.Println("B.Foo()")
}
func main() {
b := B{A: A{}}
b.Bar()
}本质上它是一个模板方法模式(TemplateMethodPattern),A的Bar调用了虚函数Foo,期待子类重写虚函数Foo,这是典型的C++/Java解决问题的思路。
我们借用模板方法模式(TemplateMethodPattern)中的例子,考虑实现一个跨平台编译器,提供给用户使用的函数是crossCompile,而这个函数调用了两个模板方法collectSource和compileToTarget:
public abstract class CrossCompiler {
public final void crossCompile() {
collectSource();
compileToTarget();
}
//Template methods
protected abstract void collectSource();
protected abstract void compileToTarget();
}
C++版,不用OOAD思维参考C++: CrossCompiler use StateMachine,代码如下所示:
// g++ compiler.cpp -o compiler && ./compiler
#include <stdio.h>
void beforeCompile() {
printf("Before compile\n");
}
void afterCompile() {
printf("After compile\n");
}
void collectSource(bool isIPhone) {
if (isIPhone) {
printf("IPhone: Collect source\n");
} else {
printf("Android: Collect source\n");
}
}
void compileToTarget(bool isIPhone) {
if (isIPhone) {
printf("IPhone: Compile to target\n");
} else {
printf("Android: Compile to target\n");
}
}
void IDEBuild(bool isIPhone) {
beforeCompile();
collectSource(isIPhone);
compileToTarget(isIPhone);
afterCompile();
}
int main(int argc, char** argv) {
IDEBuild(true);
//IDEBuild(false);
return 0;
}C++版本使用OOAD思维,可以参考C++: CrossCompiler,代码如下所示:
// g++ compiler.cpp -o compiler && ./compiler
#include <stdio.h>
class CrossCompiler {
public:
void crossCompile() {
beforeCompile();
collectSource();
compileToTarget();
afterCompile();
}
private:
void beforeCompile() {
printf("Before compile\n");
}
void afterCompile() {
printf("After compile\n");
}
// Template methods.
public:
virtual void collectSource() = 0;
virtual void compileToTarget() = 0;
};
class IPhoneCompiler : public CrossCompiler {
public:
void collectSource() {
printf("IPhone: Collect source\n");
}
void compileToTarget() {
printf("IPhone: Compile to target\n");
}
};
class AndroidCompiler : public CrossCompiler {
public:
void collectSource() {
printf("Android: Collect source\n");
}
void compileToTarget() {
printf("Android: Compile to target\n");
}
};
void IDEBuild(CrossCompiler* compiler) {
compiler->crossCompile();
}
int main(int argc, char** argv) {
IDEBuild(new IPhoneCompiler());
//IDEBuild(new AndroidCompiler());
return 0;
}我们可以针对不同的平台实现这个编译器,比如Android和iPhone:
public class IPhoneCompiler extends CrossCompiler {
protected void collectSource() {
//anything specific to this class
}
protected void compileToTarget() {
//iphone specific compilation
}
}
public class AndroidCompiler extends CrossCompiler {
protected void collectSource() {
//anything specific to this class
}
protected void compileToTarget() {
//android specific compilation
}
}
在C++/Java中能够完美的工作,但是在Go中,使用结构体嵌套只能这么实现,让IPhoneCompiler和AndroidCompiler内嵌CrossCompiler,参考Go: TemplateMethod,代码如下所示:
package main
import (
"fmt"
)
type CrossCompiler struct {
}
func (v CrossCompiler) crossCompile() {
v.collectSource()
v.compileToTarget()
}
func (v CrossCompiler) collectSource() {
fmt.Println("CrossCompiler.collectSource")
}
func (v CrossCompiler) compileToTarget() {
fmt.Println("CrossCompiler.compileToTarget")
}
type IPhoneCompiler struct {
CrossCompiler
}
func (v IPhoneCompiler) collectSource() {
fmt.Println("IPhoneCompiler.collectSource")
}
func (v IPhoneCompiler) compileToTarget() {
fmt.Println("IPhoneCompiler.compileToTarget")
}
type AndroidCompiler struct {
CrossCompiler
}
func (v AndroidCompiler) collectSource() {
fmt.Println("AndroidCompiler.collectSource")
}
func (v AndroidCompiler) compileToTarget() {
fmt.Println("AndroidCompiler.compileToTarget")
}
func main() {
iPhone := IPhoneCompiler{}
iPhone.crossCompile()
}执行结果却让人手足无措:
# Expect
IPhoneCompiler.collectSource
IPhoneCompiler.compileToTarget
# Output
CrossCompiler.collectSource
CrossCompiler.compileToTargetGo并没有支持类继承体系和多态,Go是面向对象却不是一般所理解的那种面向对象,用老子的话说“道可道,非常道”。
实际上在OOAD中,除了类继承之外,还有另外一个解决问题的思路就是组合Composition,面向对象设计原则中有个很重要的就是The Composite Reuse Principle (CRP),Favor delegation over inheritance as a reuse mechanism,重用机制应该优先使用组合(代理)而不是类继承。类继承会丧失灵活性,而且访问的范围比组合要大;组合有很高的灵活性,另外组合使用另外对象的接口,所以能获得最小的信息。
C++如何使用组合代替继承实现模板方法?可以考虑让CrossCompiler使用其他的类提供的服务,或者说使用接口,比如CrossCompiler依赖于ICompiler:
public interface ICompiler {
//Template methods
protected abstract void collectSource();
protected abstract void compileToTarget();
}
public abstract class CrossCompiler {
public ICompiler compiler;
public final void crossCompile() {
compiler.collectSource();
compiler.compileToTarget();
}
}
C++版本可以参考C++: CrossCompiler use Composition,代码如下所示:
// g++ compiler.cpp -o compiler && ./compiler
#include <stdio.h>
class ICompiler {
// Template methods.
public:
virtual void collectSource() = 0;
virtual void compileToTarget() = 0;
};
class CrossCompiler {
public:
CrossCompiler(ICompiler* compiler) : c(compiler) {
}
void crossCompile() {
beforeCompile();
c->collectSource();
c->compileToTarget();
afterCompile();
}
private:
void beforeCompile() {
printf("Before compile\n");
}
void afterCompile() {
printf("After compile\n");
}
ICompiler* c;
};
class IPhoneCompiler : public ICompiler {
public:
void collectSource() {
printf("IPhone: Collect source\n");
}
void compileToTarget() {
printf("IPhone: Compile to target\n");
}
};
class AndroidCompiler : public ICompiler {
public:
void collectSource() {
printf("Android: Collect source\n");
}
void compileToTarget() {
printf("Android: Compile to target\n");
}
};
void IDEBuild(CrossCompiler* compiler) {
compiler->crossCompile();
}
int main(int argc, char** argv) {
IDEBuild(new CrossCompiler(new IPhoneCompiler()));
//IDEBuild(new CrossCompiler(new AndroidCompiler()));
return 0;
}我们可以针对不同的平台实现这个ICompiler,比如Android和iPhone。这样从继承的类体系,变成了更灵活的接口的组合,以及对象直接服务的调用:
public class IPhoneCompiler implements ICompiler {
protected void collectSource() {
//anything specific to this class
}
protected void compileToTarget() {
//iphone specific compilation
}
}
public class AndroidCompiler implements ICompiler {
protected void collectSource() {
//anything specific to this class
}
protected void compileToTarget() {
//android specific compilation
}
}
在Go中,推荐用组合和接口,小的接口,大的对象。这样有利于只获得自己应该获取的信息,或者不会获得太多自己不需要的信息和函数,参考Clients should not be forced to depend on methods they do not use. –Robert C. Martin,以及The bigger the interface, the weaker the abstraction, Rob Pike。关于面向对象的原则在Go中的体现,参考Go: SOLID或中文版Go: SOLID。
先看如何使用Go的思路实现前面的例子,跨平台编译器,Go Composition: Compiler,代码如下所示:
package main
import (
"fmt"
)
type SourceCollector interface {
collectSource()
}
type TargetCompiler interface {
compileToTarget()
}
type CrossCompiler struct {
collector SourceCollector
compiler TargetCompiler
}
func (v CrossCompiler) crossCompile() {
v.collector.collectSource()
v.compiler.compileToTarget()
}
type IPhoneCompiler struct {
}
func (v IPhoneCompiler) collectSource() {
fmt.Println("IPhoneCompiler.collectSource")
}
func (v IPhoneCompiler) compileToTarget() {
fmt.Println("IPhoneCompiler.compileToTarget")
}
type AndroidCompiler struct {
}
func (v AndroidCompiler) collectSource() {
fmt.Println("AndroidCompiler.collectSource")
}
func (v AndroidCompiler) compileToTarget() {
fmt.Println("AndroidCompiler.compileToTarget")
}
func main() {
iPhone := IPhoneCompiler{}
compiler := CrossCompiler{iPhone, iPhone}
compiler.crossCompile()
}这个方案中,将两个模板方法定义成了两个接口,CrossCompiler使用了这两个接口,因为本质上C++/Java将它的函数定义为抽象函数,意思也是不知道这个函数如何实现。而IPhoneCompiler和AndroidCompiler并没有继承关系,而它们两个实现了这两个接口,供CrossCompiler使用;也就是它们之间的关系,从之前的强制绑定,变成了组合。
type SourceCollector interface {
collectSource()
}
type TargetCompiler interface {
compileToTarget()
}
type CrossCompiler struct {
collector SourceCollector
compiler TargetCompiler
}
func (v CrossCompiler) crossCompile() {
v.collector.collectSource()
v.compiler.compileToTarget()
}
Rob Pike在Go Language: Small and implicit中描述Go的类型和接口,第29页说:
- Objects implicitly satisfy interfaces. A type satisfies an interface simply by implementing its methods. There is no "implements" declaration; interfaces are satisfied implicitly. 这种隐式的实现接口,实际中还是很灵活的,我们在Refector时可以将对象改成接口,缩小所依赖的接口时,能够不改变其他地方的代码。比如如果一个函数
foo(f *os.File),最初依赖于os.File,但实际上可能只是依赖于io.Reader就可以方便做UTest,那么可以直接修改成foo(r io.Reader)所有地方都不用修改,特别是这个接口是新增的自定义接口时就更明显。 - In Go, interfaces are usually small: one or two or even zero methods. 在Go中接口都比较小,非常小,只有一两个函数;但是对象却会比较大,会使用很多的接口。这种方式能够以最灵活的方式重用代码,而且保持接口的有效性和最小化,也就是接口隔离。
隐式实现接口有个很好的作用,就是两个类似的模块实现同样的服务时,可以无缝的提供服务,甚至可以同时提供服务。比如改进现有模块时,比如两个不同的算法。更厉害的时,两个模块创建的私有接口,如果它们签名一样,也是可以互通的,其实签名一样就是一样的接口,无所谓是不是私有的了。这个非常强大,可以允许不同的模块在不同的时刻升级,这对于提供服务的服务器太重要了。
比较被严重误认为是继承的,莫过于是Go的内嵌Embeding,因为Embeding本质上还是组合不是继承,参考Embeding is still composition。
Embeding在UTest的Mocking中可以显著减少需要Mock的函数,比如Mocking net.Conn,如果只需要mock Read和Write两个函数,就可以通过内嵌net.Conn来实现,这样loopBack也实现了整个net.Conn接口,不必每个接口全部写一遍:
type loopBack struct {
net.Conn
buf bytes.Buffer
}
func (c *loopBack) Read(b []byte) (int, error) {
return c.buf.Read(b)
}
func (c *loopBack) Write(b []byte) (int, error) {
return c.buf.Write(b)
}
Embeding只是将内嵌的数据和函数自动全部代理了一遍而已,本质上还是使用这个内嵌对象的服务。Outer内嵌了Inner,和Outer继承Inner的区别在于:内嵌Inner是不知道自己被内嵌,调用Inner的函数,并不会对Outer有任何影响,Outer内嵌Inner只是自动将Inner的数据和方法代理了一遍,但是本质上Inner的东西还不是Outer的东西;对于继承,调用Inner的函数有可能会改变Outer的数据,因为Outer继承Inner,那么Outer就是Inner,二者的依赖是更紧密的。
如果很难理解为何Embeding不是继承,本质上是没有区分继承和组合的区别,可以参考Composition not inheritance,Go选择组合不选择继承是深思熟虑的决定,面向对象的继承、虚函数、多态和类树被过度使用了。类继承树需要前期就设计好,而往往系统在演化时发现类继承树需要变更,我们无法在前期就精确设计出完美的类继承树;Go的接口和组合,在接口变更时,只需要变更最直接的调用层,而没有类子树需要变更。
The designs are nothing like hierarchical, subtype-inherited methods. They are looser (even ad hoc), organic, decoupled, independent, and therefore scalable.
组合比继承有个很关键的优势是正交性orthogonal,详细参考正交性。
真水无香,真的牛逼不用装。——来自网络
软件是一门科学也是艺术,换句话说软件是工程。科学的意思是逻辑、数学、二进制,比较偏基础的理论都是需要数学的,比如C的结构化编程是有论证的,那些关键字和逻辑是够用的。实际上Go的GC也是有数学证明的,还有一些网络传输算法,又比如奠定一个新领域的论文比如Google的论文。艺术的意思是,大部分时候都用不到严密的论证,有很多种不同的路,还需要看自己的品味或者叫偏见,特别容易引起口水仗和争论,从好的方面说,好的软件或代码,是能被感觉到很好的。
由于大部分时候软件开发是要靠经验的,特别是国内填鸭式教育培养了对于数学的莫名的仇恨(“莫名”主要是早就把该忘的不该忘记的都忘记了),所以在代码中强调数学,会激发起大家心中一种特别的鄙视和怀疑,而这种鄙视和怀疑应该是以葱白和畏惧为基础——大部分时候在代码中吹数学都会被认为是装逼。而Orthogonal(正交性)则不择不扣的是个数学术语,是线性代数(就是矩阵那个玩意儿)中用来描述两个向量相关性的,在平面中就是两个线条的垂直。比如下图:
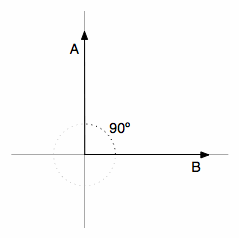
Vectors A and B are orthogonal to each other.
旁白:妮玛,两个线条垂直能和代码有个毛线关系,八竿子打不着关系吧,请继续吹。
先请看Go关于Orthogonal相关的描述,可能还不止这些地方:
Composition not inheritance Object-oriented programming provides a powerful insight: that the behavior of data can be generalized independently of the representation of that data. The model works best when the behavior (method set) is fixed, but once you subclass a type and add a method, the behaviors are no longer identical. If instead the set of behaviors is fixed, such as in Go's statically defined interfaces, the uniformity of behavior enables data and programs to be composed uniformly, orthogonally, and safely.
JSON-RPC: a tale of interfaces In an inheritance-oriented language like Java or C++, the obvious path would be to generalize the RPC class, and create JsonRPC and GobRPC subclasses. However, this approach becomes tricky if you want to make a further generalization orthogonal to that hierarchy.
实际上Orthogonal并不是只有Go才提,参考Orthogonal Software。实际上很多软件设计都会提正交性,比如OOAD里面也有不少地方用这个描述。我们先从实际的例子出发吧,关于线程一般Java、Python、C#等语言,会定义个线程的类Thread,可能包含以下的方法管理线程:
var thread = new Thread(thread_main_function);
thread.Start();
thread.Interrupt();
thread.Join();
thread.Stop();
如果把goroutine也看成是Go的线程,那么实际上Go并没有提供上面的方法,而是提供了几种不同的机制来管理线程:
-
go关键字启动goroutine。 -
sync.WaitGroup等待线程退出。 -
chan也可以用来同步,比如等goroutine启动或退出,或者传递退出信息给goroutine。 -
context也可以用来管理goroutine,参考Context。
s := make(chan bool, 0)
q := make(chan bool, 0)
go func() {
s <- true // goroutine started.
for {
select {
case <-q:
return
default:
// do something.
}
}
} ()
<- s // wait for goroutine started.
time.Sleep(10)
q <- true // notify goroutine quit.
注意上面只是例子,实际中推荐用Context管理goroutine。
如果把goroutine看成一个向量,把sync看成一个向量,把chan看成一个向量,这些向量都不相关,也就是它们是正交的。
再举在Orthogonal Software的例子,将对象存储到TEXT或XML文件,可以直接写对象的序列化函数:
def read_dictionary(file)
if File.extname(file) == ".xml"
# read and return definitions in XML from file
else
# read and return definitions in text from file
end
end
这个的坏处包括:
- 逻辑代码和序列化代码混合在一起,随处可见序列化代码,非常难以维护。
- 如果要新增序列化的机制比如将对象序列化存储到网络就很费劲了。
- 假设TEXT要支持JSON格式,或者INI格式呢?
如果改进下这个例子,将存储分离:
class Dictionary
def self.instance(file)
if File.extname(file) == ".xml"
XMLDictionary.new(file)
else
TextDictionary.new(file)
end
end
end
class TextDictionary < Dictionary
def write
# write text to @file using the @definitions hash
end
def read
# read text from @file and populate the @definitions hash
end
end
如果把Dictionay看成一个向量,把存储方式看成一个向量,再把JSON或INI格式看成一个向量,他们实际上是可以不相关的。
再看一个例子,考虑上面JSON-RPC: a tale of interfaces的修改,实际上是将序列化的部分,从*gob.Encoder变成了接口ServerCodec,然后实现了jsonCodec和gobCodec两种Codec,所以RPC和ServerCodec是正交的。非正交的做法,就是从RPC继承两个类jsonRPC和gobRPC,这样RPC和Codec是耦合的并不是不相关的。
Orthogonal不相关到底有什么好说的?
- 数学中不相关的两个向量,可以作为空间的基,比如平面上就是x和y轴,从向量看就是两个向量,这两个不相关的向量x和y可以组合出平面的任意向量,平面任一点都可以用x和y表示;如果向量不正交,有些区域就不能用这两个向量表达,有些点就不能表达。这个在接口设计上就是:正交的接口,能让用户灵活组合出能解决各种问题的调用方式,不相关的向量可以张成整个向量空间;同样的如果不正交,有时候就发现自己想要的功能无法通过现有接口实现,必须修改接口的定义。
- 比如goroutine的例子,我们可以用sync或chan达到自己想要的控制goroutine的方式。比如context也是组合了chan、timeout、value等接口提供的一个比较明确的功能库。这些语言级别的正交的元素,可以组合成非常多样和丰富的库。比如有时候我们需要等goroutine启动,有时候不用;有时候甚至不需要管理goroutine,有时候需要主动通知goroutine退出;有时候我们需要等goroutine出错后处理。
- 比如序列化TEXT或XML的例子,可以将对象的逻辑完全和存储分离,避免对象的逻辑中随处可见存储对象的代码,维护性可以极大的提升。另外,两个向量的耦合还可以理解,如果是多个向量的耦合就难以实现,比如要将对象序列化为支持注释的JSON先存储到网络有问题再存储为TEXT文件,同时如果是程序升级则存储为XML文件,这种复杂的逻辑实际上需要很灵活的组合,本质上就是空间的多个向量的组合表达出空间的新向量(新功能)。
- 当对象出现了自己不该有的特性和方法,会造成巨大的维护成本。比如如果TEXT和XML机制耦合在一起,那么维护TEXT协议时,要理解XML的协议,改动TEXT时竟然造成XML挂掉了。使用时如果出现自己不用的函数也是一种坏味道,比如
Copy(src, dst io.ReadWriter)就有问题,因为src明显不会用到Write而dst不会用到Read,所以改成Copy(src io.Reader, dst io.Writer)才是合理的。
由此可见,Orthogonal是接口设计中非常关键的要素,我们需要从概念上考虑接口,尽量提供正交的接口和函数。比如io.Reader、io.Writer和io.Closer是正交的,因为有时候我们需要的新向量是读写那么可以使用io.ReadWriter,这实际上是两个接口的组合。
我们如何才能实现Orthogonal的接口呢?特别对于公共库,这个非常关键,直接决定了我们是否能提供好用的库,还是很烂的不知道怎么用的库。有几个建议:
- 好用的公共库,使用者可以通过IDE的提示就知道怎么用,不应该提供多个不同的路径实现一个功能,会造成很大的困扰。比如Android的通讯录,超级多的完全不同的类可以用,实际上就是非常难用。
- 必须要有完善的文档。完全通过代码就能表达Why和How,是不可能的。就算是Go的标准库,也是大量的注释,如果一个公共库没有文档和注释,会非常的难用和维护。
- 一定要先写Example,一定要提供UTest完全覆盖。没有Example的公共库是不知道接口设计是否合理的,没有人有能力直接设计一个合理的库,只有从使用者角度分析才能知道什么是合理,Example就是使用者角度;标准库有大量的Example。UTest也是一种使用,不过是内部使用,也很必要。
如果上面数学上有不严谨的请原谅我,我数学很渣。
先把最重要的说了,关于modules的最新详细信息可以执行命令go help modules或者查这个长长的手册Go Modules,另外modules弄清楚后很好用迁移成本低。
Go Module的好处,可以参考Demo:
- 代码不用必须放GOPATH,可以放在任何目录,终于不用做软链了。
- Module依然可以用vendor,如果不需要更新依赖,可以不必从远程下载依赖代码,同样不必放GOPATH。
- 如果在一个仓库可以直接引用,会自动识别模块内部的package,同样不用链接到GOPATH。
Go最初是使用GOPATH存放依赖的包(项目和代码),这个GOPATH是公共的目录,如果依赖的库的版本不同就杯具了。2016年也就是7年后才支持vendor规范,就是将依赖本地化了,每个项目都使用自己的vendor文件夹,但这样也解决不了冲突的问题(具体看下面的分析),相反导致各种包管理项目天下混战,参考pkg management tools。2017年也就是8年后,官方的vendor包管理器dep才确定方案,看起来命中注定的TheOne终于尘埃落定。不料2018年也就是9年后,又提出比较完整的方案versioning和vgo,这年Go1.11支持了Modules,2019年Go1.12和Go1.13改进了不少Modules内容,Go官方文档推出一系列的Part 1 — Using Go Modules、Part 2 — Migrating To Go Modules和Part 3 — Publishing Go Modules,终于应该大概齐能明白,这次真的确定和肯定了,Go Modules是最终方案。
为什么要搞出GOPATH、Vendor和GoModules这么多技术方案?本质上是为了创造就业岗位,一次创造了index、proxy和sum三个官网,哈哈哈。当然技术上也是必须要这么做的,简单来说是为了解决古老的DLL Hell问题,也就是依赖管理和版本管理的问题。版本说起来就是几个数字,比如1.2.3,实际上是非常复杂的问题,推荐阅读Semantic Versioning,假设定义了良好和清晰的API,我们用版本号来管理API的兼容性;版本号一般定义为MAJOR.MINOR.PATCH,Major变更时意味着不兼容的API变更,Minor是功能变更但是是兼容的,Patch是BugFix也是兼容的,Major为0时表示API还不稳定。由于Go的包是URL的,没有版本号信息,最初对于包的版本管理原则是必须一直保持接口兼容:
If an old package and a new package have the same import path, the new package must be backwards compatible with the old package.
试想下如果所有我们依赖的包,一直都是接口兼容的,那就没有啥问题,也没有DLL Hell。可惜现实却不是这样,如果我们提供过包就知道,对于持续维护和更新的包,在最初不可能提供一个永远不变的接口,变化的接口就是不兼容的了。就算某个接口可以不变,还有依赖的包,还有依赖的依赖的包,还有依赖的依赖的依赖的包,以此往复,要求世界上所有接口都不变,才不会有版本问题,这么说起来,包管理是个极其难以解决的问题,Go花了10年才确定最终方案就是这个原因了,下面举例子详细分析这个问题。
备注:标准库也有遇到接口变更的风险,比如Context是Go1.7才引入标准库的,控制程序生命周期,后续有很多接口的第一个参数都是
ctx context.Context,比如net.DialContext就是后面加的一个函数,而net.Dial也是调用它。再比如http.Request.WithContext则提供了一个函数,将context放在结构体中传递,这是因为要再为每个Request的函数新增一个参数不太合适。从context对于标准库的接口的变更,可以看得到这里有些不一致性,有很多批评的声音比如Context should go away for Go 2,就是觉得在标准库中加context作为第一个参数不能理解,比如Read(ctx context.Context等。
咱们先看GOPATH的方式。Go引入外部的包,是URL方式的,先在环境变量$GOROOT中搜索,然后在$GOPATH中搜索,比如我们使用Errors,依赖包github.com/ossrs/go-oryx-lib/errors,代码如下所示:
package main
import (
"fmt"
"github.com/ossrs/go-oryx-lib/errors"
)
func main() {
fmt.Println(errors.New("Hello, playground"))
}如果我们直接运行会报错,错误信息如下:
prog.go:5:2: cannot find package "github.com/ossrs/go-oryx-lib/errors" in any of:
/usr/local/go/src/github.com/ossrs/go-oryx-lib/errors (from $GOROOT)
/go/src/github.com/ossrs/go-oryx-lib/errors (from $GOPATH)
需要先下载这个依赖包go get -d github.com/ossrs/go-oryx-lib/errors,然后运行就可以了。下载后放在GOPATH中:
Mac $ ls -lh $GOPATH/src/github.com/ossrs/go-oryx-lib/errors
total 72
-rw-r--r-- 1 chengli.ycl staff 1.3K Sep 8 15:35 LICENSE
-rw-r--r-- 1 chengli.ycl staff 2.2K Sep 8 15:35 README.md
-rw-r--r-- 1 chengli.ycl staff 1.0K Sep 8 15:35 bench_test.go
-rw-r--r-- 1 chengli.ycl staff 6.7K Sep 8 15:35 errors.go
-rw-r--r-- 1 chengli.ycl staff 5.4K Sep 8 15:35 example_test.go
-rw-r--r-- 1 chengli.ycl staff 4.7K Sep 8 15:35 stack.go
如果我们依赖的包还依赖于其他的包,那么go get会下载所有依赖的包到GOPATH。这样是下载到公共的GOPATH的,可以想到,这会造成几个问题:
- 每次都要从网络下载依赖,可能对于美国这个问题不存在,但是对于中国,要从GITHUB上下载很大的项目,是个很麻烦的问题,还没有断点续传。
- 如果两个项目,依赖了GOPATH了项目,如果一个更新会导致另外一个项目出现问题。比如新的项目下载了最新的依赖库,可能会导致其他项目出问题。
- 无法独立管理版本号和升级,独立依赖不同的包的版本。比如A项目依赖1.0的库,而B项目依赖2.0的库。注意:如果A和B都是库的话,这个问题还是无解的,它们可能会同时被一个项目引用,如果A和B是最终的应用是没有问题,应用可以用不同的版本,它们在自己的目录。
为了解决这些问题,引入了vendor,在src下面有个vendor目录,将依赖的库都下载到这个目录,同时会有描述文件说明依赖的版本,这样可以实现升级不同库的升级。参考vendor,以及官方的包管理器dep。但是vendor并没有解决所有的问题,特别是包的不兼容版本的问题,只解决了项目或应用,也就是会编译出二进制的项目所依赖库的问题。
咱们把上面的例子用vendor实现,先要把项目软链或者挪到GOPATH里面去,若没有dep工具可以参考Installation安装,然后执行下面的命令来将依赖导入到vendor目录:
dep init && dep ensure这样依赖的文件就会放在vendor下面,编译时也不再需要从远程下载了:
├── Gopkg.lock
├── Gopkg.toml
├── t.go
└── vendor
└── github.com
└── ossrs
└── go-oryx-lib
└── errors
├── errors.go
└── stack.goRemark: Vendor也会选择版本,也有版本管理,但每个包它只会选择一个版本,也就是本质上是本地化的GOPATH,如果出现钻石依赖和冲突还是无解,下面会详细说明。
我们来看GOPATH和Vencor无法解决的一个问题,版本依赖问题的一个例子Semantic Import Versioning,考虑钻石依赖的情况,用户依赖于两个云服务商的SDK,而他们可能都依赖于公共的库,形成一个钻石形状的依赖,用户依赖AWS和Azure而它们都依赖OAuth:
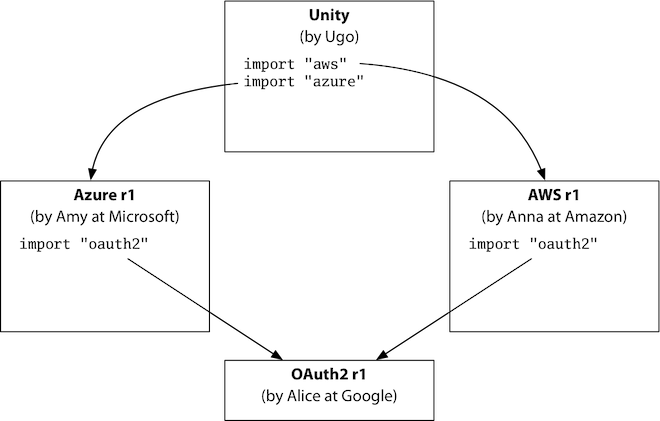
如果公共库package(这里是OAuth)的导入路径一样(比如是github.com/google/oauth),但是做了非兼容性变更,发布了OAuth-r1和OAuth-r2,其中一个云服务商更新了自己的依赖,另外一个没有更新,就会造成冲突,他们依赖的版本不同:
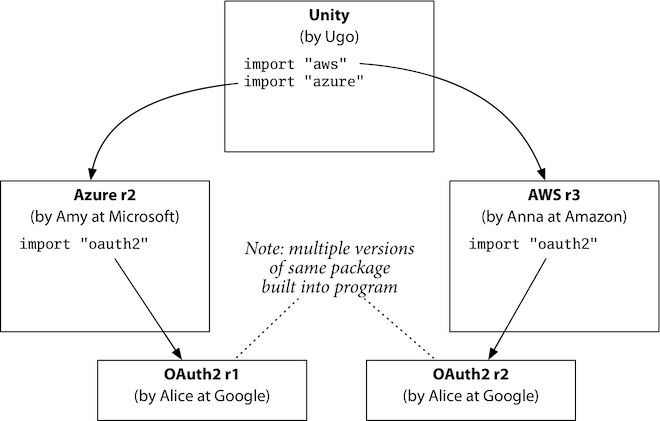
在Go中无论怎么修改都无法支持这种情况,除非在package的路径中加入版本语义进去,也就是在路径上带上版本信息(这就是Go Modules了),这和优雅没有关系,这实际上是最好的使用体验:
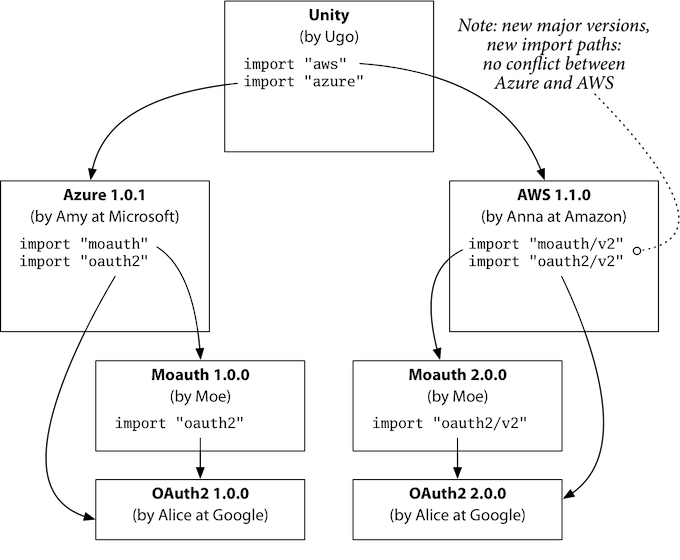
另外做法就是改变包路径,这要求包提供者要每个版本都要使用一个特殊的名字,但使用者也不能分辨这些名字代表的含义,自然也不知道如何选择哪个版本。
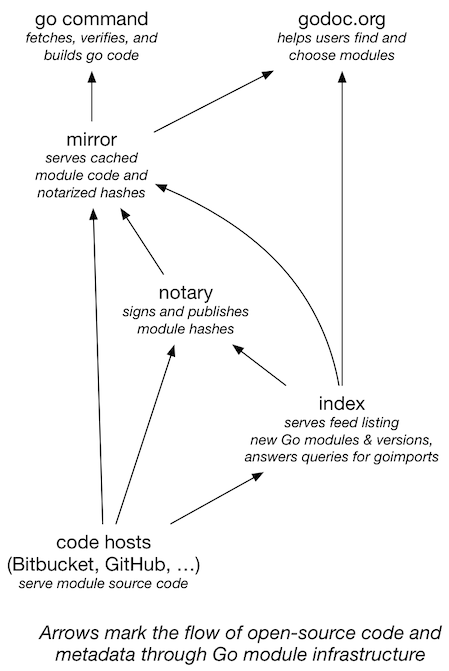
先看看Go Modules创造的三大就业岗位,index负责索引、proxy负责代理缓存和sum负责签名校验,它们之间的关系在Big Picture中有描述。可见go-get会先从index获取指定package的索引,然后从proxy下载数据,最后从sum来获取校验信息:
还是先跟着官网的三部曲,先了解下modules的基本用法,后面补充下特别要注意的问题就差不多齐了。首先是Using Go Modules,如何使用modules,还是用上面的例子,代码不用改变,只需要执行命令:
go mod init private.me/app && go run t.goRemark:和vendor并不相同,modules并不需要在GOPATH下面才能创建,所以这是非常好的。
执行的结果如下,可以看到vgo查询依赖的库,下载后解压到了cache,并生成了go.mod和go.sum,缓存的文件在$GOPATH/pkg下面:
Mac:gogogo chengli.ycl$ go mod init private.me/app && go run t.go
go: creating new go.mod: module private.me/app
go: finding github.com/ossrs/go-oryx-lib v0.0.7
go: downloading github.com/ossrs/go-oryx-lib v0.0.7
go: extracting github.com/ossrs/go-oryx-lib v0.0.7
Hello, playground
Mac:gogogo chengli.ycl$ cat go.mod
module private.me/app
go 1.13
require github.com/ossrs/go-oryx-lib v0.0.7 // indirect
Mac:gogogo chengli.ycl$ cat go.sum
github.com/ossrs/go-oryx-lib v0.0.7 h1:k8ml3ZLsjIMoQEdZdWuy8zkU0w/fbJSyHvT/s9NyeCc=
github.com/ossrs/go-oryx-lib v0.0.7/go.mod h1:i2tH4TZBzAw5h+HwGrNOKvP/nmZgSQz0OEnLLdzcT/8=
Mac:gogogo chengli.ycl$ tree $GOPATH/pkg
/Users/winlin/go/pkg
├── mod
│ ├── cache
│ │ ├── download
│ │ │ ├── github.com
│ │ │ │ └── ossrs
│ │ │ │ └── go-oryx-lib
│ │ │ │ └── @v
│ │ │ │ ├── list
│ │ │ │ ├── v0.0.7.info
│ │ │ │ ├── v0.0.7.zip
│ │ │ └── sumdb
│ │ │ └── sum.golang.org
│ │ │ ├── lookup
│ │ │ │ └── github.com
│ │ │ │ └── ossrs
│ │ │ │ └── [email protected]
│ └── github.com
│ └── ossrs
│ └── [email protected]
│ ├── errors
│ │ ├── errors.go
│ │ └── stack.go
└── sumdb
└── sum.golang.org
└── latest可以手动升级某个库,即go get这个库:
Mac:gogogo chengli.ycl$ go get github.com/ossrs/go-oryx-lib
go: finding github.com/ossrs/go-oryx-lib v0.0.8
go: downloading github.com/ossrs/go-oryx-lib v0.0.8
go: extracting github.com/ossrs/go-oryx-lib v0.0.8
Mac:gogogo chengli.ycl$ cat go.mod
module private.me/app
go 1.13
require github.com/ossrs/go-oryx-lib v0.0.8升级某个包到指定版本,可以带上版本号,例如go get github.com/ossrs/[email protected]。当然也可以降级,比如现在是v0.0.8,可以go get github.com/ossrs/[email protected]降到v0.0.7版本。也可以升级所有依赖的包,执行go get -u命令就可以。查看依赖的包和版本,以及依赖的依赖的包和版本,可以执行go list -m all命令。查看指定的包有哪些版本,可以用go list -m -versions github.com/ossrs/go-oryx-lib命令。
Note: 关于vgo如何选择版本,可以参考Minimal Version Selection。
如果依赖了某个包大版本的多个版本,那么会选择这个大版本最高的那个,比如:
- 若a依赖v1.0.1,b依赖v1.2.3,程序依赖a和b时,最终使用v1.2.3。
- 若a依赖v1.0.1,d依赖v0.0.7,程序依赖a和d时,最终使用v1.0.1,也就是认为v1是兼容v0的。
比如下面代码,依赖了四个包,而这四个包依赖了某个包的不同版本,分别选择不同的包,执行rm -f go.mod && go mod init private.me/app && go run t.go,可以看到选择了不同的版本,始终选择的是大版本最高的那个(也就是满足要求的最小版本):
package main
import (
"fmt"
"github.com/winlinvip/mod_ref_a" // 1.0.1
"github.com/winlinvip/mod_ref_b" // 1.2.3
"github.com/winlinvip/mod_ref_c" // 1.0.3
"github.com/winlinvip/mod_ref_d" // 0.0.7
)
func main() {
fmt.Println("Hello",
mod_ref_a.Version(),
mod_ref_b.Version(),
mod_ref_c.Version(),
mod_ref_d.Version(),
)
}若包需要升级大版本,则需要在路径上加上版本,包括本身的go.mod中的路径,依赖这个包的go.mod,依赖它的代码,比如下面的例子,同时使用了v1和v2两个版本(只用一个也可以):
package main
import (
"fmt"
"github.com/winlinvip/mod_major_releases"
v2 "github.com/winlinvip/mod_major_releases/v2"
)
func main() {
fmt.Println("Hello",
mod_major_releases.Version(),
v2.Version2(),
)
}运行这个程序后,可以看到go.mod中导入了两个包:
module private.me/app
go 1.13
require (
github.com/winlinvip/mod_major_releases v1.0.1
github.com/winlinvip/mod_major_releases/v2 v2.0.3
)Remark: 如果需要更新v2的指定版本,那么路径中也必须带v2,也就是所有v2的路径必须带v2,比如
go get github.com/winlinvip/mod_major_releases/[email protected]。
而库提供大版本也是一样的,参考mod_major_releases/v2,主要做的事情:
- 新建v2的分支,
git checkout -b v2,比如https://github.com/winlinvip/mod_major_releases/tree/v2。 - 修改go.mod的描述,路径必须带v2,比如
module github.com/winlinvip/mod_major_releases/v2。 - 提交后打v2的tag,比如
git tag v2.0.0,分支和tag都要提交到git。
其中go.mod更新如下:
module github.com/winlinvip/mod_major_releases/v2
go 1.13代码更新如下,由于是大版本,所以就变更了函数名称:
package mod_major_releases
func Version2() string {
return "mmv/2.0.3"
}Note: 更多信息可以参考Modules: v2,还有Russ Cox: From Repository to Modules介绍了两种方式,常见的就是上面的分支方式的例子,还有一种文件夹方式。
- 对于公开的package,如果go.mod中描述的package,和公开的路径不相同,比如go.mod是
private.me/app,而发布到github.com/winlinvip/app,当然其他项目import这个包时会出现错误。对于库,也就是希望别人依赖的包,go.mod描述的和发布的路径,以及package名字都应该保持一致。 - 如果一个包没有发布任何版本,则会取最新的commit和日期,格式为v0.0.0-日期-commit号,比如
v0.0.0-20191028070444-45532e158b41,参考Pseudo Versions。版本号可以从v0.0.x开始,比如v0.0.1或者v0.0.3或者v0.1.0或者v1.0.1之类,没有强制要求必须要是1.0开始的发布版本。 -
mod replace在子module无效,只在编译的那个top level有效,也就是在最终生成binary的go.mod中定义才有效,官方的说明是为了让最终生成时控制依赖。例如想要把
github.com/pkg/errors重写为github.com/winlinvip/errors这个包,正确做法参考分支replace_errors;若不在主模块(top level)中replace参考replace_in_submodule,只在子模块中定义了replace但会被忽略;如果在主模块replace会生效replace_errors,而且在主模块依赖掉子模快依赖的模块也生效replace_deps_of_submodule。不过在子模快中也能replace,这个预感到会是个混淆的地方。有一个例子就是fork仓库后修改后自己使用,这时候go.mod的package当然也变了,参考Migrating Go1.13 Errors,Go1.13的errors支持了Unwrap接口,这样可以拿到root error,而pkg/errors使用的则是Cause(err)函数来获取root error,而提的PR没有支持,pkg/errors不打算支持Go1.13的方式,作者建议fork来解决,所以就可以使用go mod replace来将fork的url替换pkg/errors。 -
go get并非将每个库都更新后取最新的版本,比如库github.com/winlinvip/mod_minor_versions有v1.0.1、v1.1.2两个版本,目前依赖的是v1.1.2版本,如果库更新到了v1.2.3版本,立刻使用go get -u并不会更新到v1.2.3,执行go get -u github.com/winlinvip/mod_minor_versions也一样不会更新,除非显式更新go get github.com/winlinvip/[email protected]才会使用这个版本,需要等一定时间后才会更新。 - 对于大版本比如v2,必须用go.mod描述,直接引用也可以比如
go get github.com/winlinvip/[email protected],会提示v2.0.0+incompatible,意思就是默认都是v0和v1,而直接打了v2.0.0的tag,虽然版本上匹配到了,但实际上是把v2当做v1在用,有可能会有不兼容的问题。或者说,一般来说v2.0.0的这个tag,一定会有接口的变更(否则就不能叫v2了),如果没有用go.mod会把这个认为是v1,自然可能会有兼容问题了。 - 更新大版本时必须带版本号比如
go get github.com/winlinvip/mod_major_releases/[email protected],如果路径中没有这个v2则会报错无法更新,比如go get github.com/winlinvip/[email protected],错误消息是invalid version: module contains a go.mod file, so major version must be compatible: should be v0 or v1,这个就是说mod_major_releases这个下面有go.mod描述的版本是v0或v1,但后面指定的版本是@v2所以不匹配无法更新。 - 和上面的问题一样,如果在go.mod中,大版本路径中没有带版本,比如
require github.com/winlinvip/mod_major_releases v2.0.3,一样会报错module contains a go.mod file, so major version must be compatible: should be v0 or v1,这个有点含糊因为包定义的go.mod是v2的,这个错误的意思是,require的那个地方,要求的是v0或v1,而实际上版本是v2.0.3,这个和手动要求更新go get github.com/winlinvip/[email protected]是一回事。 - 注意三大岗位有cache,比如[email protected]的go.mod描述有错误,应该是v5,而不是v3。如果在打完tag后,获取了这个版本
go get github.com/winlinvip/mod_major_error/v5,会提示错误but does not contain package github.com/winlinvip/mod_major_error/v5等错误,如果删除这个tag后再推v5.0.0,还是一样的错误,因为index和goproxy有缓存这个版本的信息。解决版本就是升一个版本v5.0.1,直接获取这个版本就可以,比如go get github.com/winlinvip/mod_major_error/[email protected],这样才没有问题。详细参考Semantic versions and modules。 - 和上面一样的问题,如果在版本没有发布时,就有go get的请求,会造成版本发布后也无法获取这个版本。比如
github.com/winlinvip/mod_major_error没有打版本v3.0.1,就请求go get github.com/winlinvip/mod_major_error/[email protected],会提示没有这个版本。如果后面再打这个tag,就算有这个tag后,也会提示401找不到reading https://sum.golang.org/lookup/github.com/winlinvip/mod_major_error/[email protected]: 410 Gone。只能再升级个版本,打个新的tag比如v3.0.2才能获取到。
总结起来说:
- GOPATH,自从默认为
$HOME/go后,很好用,依赖的包都缓存在这个公共的地方,只要项目不大,完全是很直接很好用的方案。一般情况下也够用了,估计GOPATH可能会被长期使用,毕竟习惯才是最可怕的,习惯是活的最久的,习惯就成为了一种生活方式,用余老师的话说“文化是一种精神价值和生活方式,最终体现了集体人格”。 - vendor,vendor缓存依赖在项目本地,能解决很多问题了,比GOPATH更好的是对于依赖可以定期更新,一般的项目中,对于依赖都是有需要了去更新,而不是每次编译都去取最新的代码。所以vendor还是非常实用的,如果能保持比较克制,不要因为要用一个函数就要依赖一个包,结果这个包依赖了十个,这十个又依赖了百个。
- vgo/modules,代码使用上没有差异;在版本更新时比如明确需要导入v2的包,才会在导入url上有差异;代码缓存上使用proxy来下载,缓存在GOPATH的pkg中,由于有版本信息所以不会有冲突;会更安全,因为有sum在;会更灵活,因为有index和proxy在。
现有GOPATH和vendor的项目,如何迁移到modules呢?官方的迁移指南Migrating to Go Modules,说明了项目会有三种状态:
- 完全新的还没开始的项目。那么就按照上面的方式,用modules就好了。
- 现有的项目,使用了其他依赖管理,也就是vendor,比如dep或glide等。go mod会将现有的格式转换成modules,支持的格式参考这里。其实modules还是会继续支持vendor,参考下面的详细描述。
- 现有的项目,没有使用任何依赖管理,也就是GOPATH。注意go mod init的包路径,需要和之前导出的一样,特别是Go1.4支持的import comment,可能和仓库的路径并不相同,比如仓库在
https://go.googlesource.com/lint,而包路径是golang.org/x/lint。
Note: 特别注意如果是库支持了v2及以上的版本,那么路径中一定需要包含v2,比如
github.com/russross/blackfriday/v2。而且需要更新引用了这个包的v2的库,比较蛋疼,不过这种情况还好是不多的。
咱们先看一个使用GOPATH的例子,我们新建一个测试包,先以GOPATH方式提供,参考github.com/winlinvip/mod_gopath,依赖于github.com/pkg/errors,rsc.io/quote和github.com/gorilla/websocket。
再看一个vendor的例子,将这个GOPATH的项目,转成vendor项目,参考github.com/winlinvip/mod_vendor,安装完dep后执行dep init就可以了,可以查看依赖:
chengli.ycl$ dep status
PROJECT CONSTRAINT VERSION REVISION LATEST PKGS USED
github.com/gorilla/websocket ^1.4.1 v1.4.1 c3e18be v1.4.1 1
github.com/pkg/errors ^0.8.1 v0.8.1 ba968bf v0.8.1 1
golang.org/x/text v0.3.2 v0.3.2 342b2e1 v0.3.2 6
rsc.io/quote ^3.1.0 v3.1.0 0406d72 v3.1.0 1
rsc.io/sampler v1.99.99 v1.99.99 732a3c4 v1.99.99 1接下来转成modules包,先拷贝一份github.com/winlinvip/mod_gopath代码(这里为了演示差别所以拷贝了一份,直接转换也是可以的),变成github.com/winlinvip/mod_gopath_vgo,然后执行命令go mod init github.com/winlinvip/mod_gopath_vgo && go test ./... && go mod tidy,接着发布版本比如git add . && git commit -am "Migrate to vgo" && git tag v1.0.1 && git push origin v1.0.1:
Mac:mod_gopath_vgo chengli.ycl$ cat go.mod
module github.com/winlinvip/mod_gopath_vgo
go 1.13
require (
github.com/gorilla/websocket v1.4.1
github.com/pkg/errors v0.8.1
rsc.io/quote v1.5.2
)depd的vendor的项目也是一样的,先拷贝一份github.com/winlinvip/mod_vendor成github.com/winlinvip/mod_vendor_vgo,执行命令go mod init github.com/winlinvip/mod_vendor_vgo && go test ./... && go mod tidy,接着发布版本比如git add . && git commit -am "Migrate to vgo" && git tag v1.0.3 && git push origin v1.0.3:
module github.com/winlinvip/mod_vendor_vgo
go 1.13
require (
github.com/gorilla/websocket v1.4.1
github.com/pkg/errors v0.8.1
golang.org/x/text v0.3.2 // indirect
rsc.io/quote v1.5.2
rsc.io/sampler v1.99.99 // indirect
)这样就可以在其他项目中引用它了:
package main
import (
"fmt"
"github.com/winlinvip/mod_gopath"
"github.com/winlinvip/mod_gopath/core"
"github.com/winlinvip/mod_vendor"
vcore "github.com/winlinvip/mod_vendor/core"
"github.com/winlinvip/mod_gopath_vgo"
core_vgo "github.com/winlinvip/mod_gopath_vgo/core"
"github.com/winlinvip/mod_vendor_vgo"
vcore_vgo "github.com/winlinvip/mod_vendor_vgo/core"
)
func main() {
fmt.Println("mod_gopath is", mod_gopath.Version(), core.Hello(), core.New("gopath"))
fmt.Println("mod_vendor is", mod_vendor.Version(), vcore.Hello(), vcore.New("vendor"))
fmt.Println("mod_gopath_vgo is", mod_gopath_vgo.Version(), core_vgo.Hello(), core_vgo.New("vgo(gopath)"))
fmt.Println("mod_vendor_vgo is", mod_vendor_vgo.Version(), vcore_vgo.Hello(), vcore_vgo.New("vgo(vendor)"))
}Note: 对于私有项目,可能无法使用三大件来索引校验,那么可以设置GOPRIVATE来禁用校验,参考Module configuration for non public modules。
Vendor并非不能用,可以用modules同时用vendor,参考How do I use vendoring with modules? Is vendoring going away?,其实vendor并不会消亡,Go社区有过详细的讨论vgo & vendoring决定在modules中支持vendor,有人觉得,把vendor作为modules的存储目录挺好的啊。在modules中开启vendor有几个步骤:
- 先转成modules,参考前面的步骤,也可以新建一个modules例如
go mod init xxx,然后把代码写好,就是一个标准的module,不过文件是存在$GOPATH/pkg的,参考github.com/winlinvip/[email protected]。 -
go mod vendor,这一步做的事情,就是将modules中的文件都放到vendor中来。当然由于go.mod也存在,当然也知道这些文件的版本信息,也不会造成什么问题,只是新建了一个vendor目录而已。在别人看起来这就是这正常的modules,和vendor一点影响都没有。参考github.com/winlinvip/[email protected]。 -
go build -mod=vendor,修改mod这个参数,默认是会忽略这个vendor目录了,加上这个参数后就会从vendor目录加载代码(可以把$GOPATH/pkg删掉发现也不会下载代码)。当然其他也可以加这个flag,比如go test -mod=vendor ./...或者go run -mod=vendor .。
调用这个包时,先使用modules把依赖下载下来,比如go mod init private.me/app && go run t.go:
package main
import (
"fmt"
"github.com/winlinvip/mod_vendor_vgo"
vcore_vgo "github.com/winlinvip/mod_vendor_vgo/core"
"github.com/winlinvip/mod_vgo_with_vendor"
vvgo_core "github.com/winlinvip/mod_vgo_with_vendor/core"
)
func main() {
fmt.Println("mod_vendor_vgo is", mod_vendor_vgo.Version(), vcore_vgo.Hello(), vcore_vgo.New("vgo(vendor)"))
fmt.Println("mod_vgo_with_vendor is", mod_vgo_with_vendor.Version(), vvgo_core.Hello(), vvgo_core.New("vgo with vendor"))
}然后一样的也要转成vendor,执行命令go mod vendor && go run -mod=vendor t.go。如果有新的依赖的包需要导入,则需要先使用modules方式导入一次,然后go mod vendor拷贝到vendor。其实一句话来说,modules with vendor就是最后提交代码时,把依赖全部放到vendor下面的一种方式。
Note: IDE比如goland的设置里面,有个
Preferences /Go /Go Modules(vgo) /Vendoring mode,这样会从项目的vendor目录解析,而不是从全局的cache。如果不需要导入新的包,可以默认开启vendor方式,执行命令go env -w GOFLAGS='-mod=vendor'。
并发是服务器的基本问题,并发控制当然也是基本问题,Go并不能避免这个问题,只是将这个问题更简化。
早在十八年前的1999年,千兆网卡还是一个新玩意儿,想当年有吉比特带宽却只能支持10K客户端,还是个值得研究的问题,毕竟Nginx在2009年才出来,在这之前大家还在内核折腾过HTTP服务器,服务器领域还在讨论如何解决C10K问题,C10K中文翻译在这里。读这个文章,感觉进入了繁忙服务器工厂的车间,成千上万错综复杂的电缆交织在一起,甚至还有古老的惊群(thundering herd)问题,惊群像远古狼人一样就算是在21世纪还是偶然能听到它的传说。现在大家讨论的都是如何支持C10M,也就是千万级并发的问题。
并发,无疑是服务器领域永远无法逃避的话题,是服务器软件工程师的基本能力。Go的撒手锏之一无疑就是并发处理,如果要从Go众多优秀的特性中挑一个,那就是并发和工程化,如果只能选一个的话,那就是并发的支持。大规模软件,或者云计算,很大一部分都是服务器编程,服务器要处理的几个基本问题:并发、集群、容灾、兼容、运维,这些问题都可以因为Go的并发特性得到改善,按照《人月神话》的观点,并发无疑是服务器领域的固有复杂度(Essential Complexity)之一。Go之所以能迅速占领云计算的市场,Go的并发机制是至关重要的。
借用《人月神话》中关于固有复杂度(Essential Complexity)的概念,能比较清晰的说明并发问题。就算没有读过这本书,也肯定听过软件开发“没有银弹”,要保持软件的“概念完整性”,Brooks作为硬件和软件的双重专家和出色的教育家始终活跃在计算机舞台上,在计算机技术的诸多领域中都作出了巨大的贡献,在1964年(33岁)领导了IBM System/360和IBM OS/360的研发,于1993年(62岁)获得冯诺依曼奖,并于1999年(68岁)获得图灵奖,在2010年(79岁)获得虚拟现实(VR)的奖项IEEE Virtual Reality Career Award (2010)。
在软件领域,很少能有像《人月神话》一样具有深远影响力和畅销不衰的著作。Brooks博士为人们管理复杂项目提供了具有洞察力的见解,既有很多发人深省的观点,又有大量软件工程的实践。本书内容来自Brooks博士在IBM公司System/360家族和OS/360中的项目管理经验,该项目堪称软件开发项目管理的典范。该书英文原版一经面世,即引起业内人士的强烈反响,后又译为德、法、日、俄、中、韩等多种文字,全球销售数百万册。确立了其在行业内的经典地位。
Brooks是我最崇拜的人,有理论有实践,懂硬件懂软件,致力于大规模软件(当初还没有云计算)系统,足够(长达十年甚至二十年)的预见性,孜孜不倦奋斗不止,强烈推荐软件工程师读《人月神话》。
短暂的广告回来,继续讨论并发(Concurrency)的问题,要理解并发的问题就必须从了解并发问题本身,以及并发处理模型开始。2012年我在当时中国最大的CDN公司蓝汛设计和开发流媒体服务器时,学习了以高并发闻名的NGINX的并发处理机制EDSM(Event-Driven State Machine Architecture),自己也照着这套机制实现了一个流媒体服务器,和HTTP的Request-Response模型不同,流媒体的协议比如RTMP非常复杂中间状态非常多,特别是在做到集群Edge时和上游服务器的交互会导致系统的状态机翻倍,当时请教了公司的北美研发中心的架构师Michael,Michael推荐我用一个叫做ST(StateThreads)的技术解决这个问题,ST实际上使用setjmp和longjmp实现了用户态线程或者叫协程,协程和goroutine是类似的都是在用户空间的轻量级线程,当时我本没有懂为什么要用一个完全不懂的协程的东西,后来我花时间了解了ST后豁然开朗,原来服务器的并发处理有几种典型的并发模型,流媒体服务器中超级复杂的状态机,也广泛存在于各种服务器领域中,属于这个复杂协议服务器领域不可Remove的一种固有复杂度(Essential Complexity)。
我翻译了ST(StateThreads)总结的并发处理模型高性能、高并发、高扩展性和可读性的网络服务器架构:State Threads for Internet Applications,这篇文章也是理解Go并发处理的关键,本质上ST就是C语言的协程库(腾讯微信也开源过一个libco协程库),而goroutine是Go语言级别的实现,本质上他们解决的领域问题是一样的,当然goroutine会更广泛一些,ST只是一个网络库。我们一起看看并发的本质目标,一起看图说话吧,先从并发相关的性能和伸缩性问题说起:
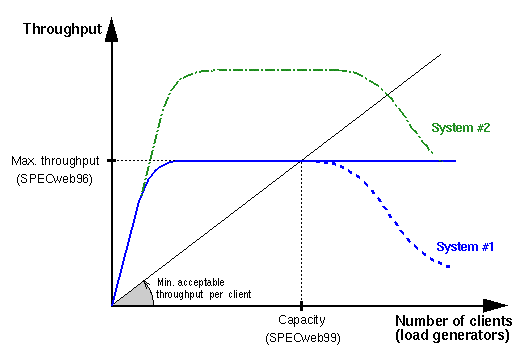
- 横轴是客户端的数目,纵轴是吞吐率也就是正常提供服务需要能吐出的数据,比如
1000个客户端在观看500Kbps码率的视频时,意味着每个客户端每秒需要500Kb的数据,那么服务器需要每秒吐出500*1000Kb=500Mb的数据才能正常提供服务,如果服务器因为性能问题CPU跑满了都无法达到500Mbps的吞吐率,客户端必定就会开始卡顿。 - 图中黑色的线是客户端要求的最低吞吐率,假设每个客户端都是一样的,那么黑色的线就是一条斜率固定的直线,也就是客户端越多吞吐率就越多,基本上和客户端数目成正比。比如1个客户端需要500Kbps的吞吐率,1000个就是500Mbps吞吐率。
- 图中蓝色的实线,是服务器实际能达到的吞吐率。在客户端比较少时,由于CPU空闲,服务器(如果有需要)能够以超过客户端要求的最低吞吐率给数据,比如点播服务器的场景,客户端看500Kbps码率的点播视频,每秒最少需要500Kb的数据,那么服务器可以以800Kbps的吞吐率给客户端数据,这样客户端自然不会卡顿,客户端会将数据保存在自己的缓冲区,只是如果用户放弃播放这个视频时会导致缓存的数据浪费。
- 图中蓝色实线会有个天花板,也就是服务器在给定的CPU资源下的最高吞吐率,比如某个版本的服务器再4CPU下由于性能问题只能达到1Gbps的吞吐率,那么黑线和蓝线的交叉点,就是这个服务器能正常服务的最多客户端比如2000个。理论上如果超过这个最大值比如10K个,服务器吞吐率还是保持在最大吞吐率比如1Gbps,但是由于客户端的数目持续增加需要继续消耗系统资源,比如10K个FD和线程的切换会抢占用于网络收发的CPU时间,那么就会出现蓝色虚线,也就是超负载运行的服务器,吞吐率会降低,导致服务器无法正常服务已经连接的客户端。
- 负载伸缩性(Load Scalability)就是指黑线和蓝线的交叉点,系统的负载能力如何,或者说是否并发模型能否尽可能的将CPU用在网络吞吐上,而不是程序切换上,比如多进程的服务器,负载伸缩性就非常差,有些空闲的客户端也会Fork一个进程服务,这无疑是浪费了CPU资源的。同时多进程的系统伸缩性会很好,增加CPU资源时吞吐率基本上都是线性的。
- 系统伸缩性(System Scalability)是指吞吐率是否随系统资源线性增加,比如新增一倍的CPU,是否吞吐率能翻倍。图中绿线,就是增加了一倍的CPU,那么好的系统伸缩性应该系统的吞吐率也要增加一倍。比如多线程程序中,由于要对竞争资源加锁或者多线程同步,增加的CPU并不能完全用于吞吐率,多线程模型的系统伸缩性就不如多进程模型。
并发的模型包括几种,总结Existing Architectures如下表:
| Arch | Load Scalability | System Scalability | Robust | Complexity | Example |
|---|---|---|---|---|---|
| Multi-Process | Poor | Good | Great | Simple | Apache1.x |
| Multi-Threaded | Good | Poor | Poor | Complex | Tomcat, FMS/AMS |
| Event-Driven State Machine |
Great | Great | Good | Very Complex |
Nginx, CRTMPD |
| StateThreads | Great | Great | Good | Simple | SRS, Go |
- MP(Multi-Process)多进程模型:每个连接Fork一个进程服务。系统的鲁棒性非常好,连接彼此隔离互不影响,就算有进程挂掉也不会影响其他连接。负载伸缩性(Load Scalability)非常差(Poor),系统在大量进程之间切换的开销太大,无法将尽可能多的CPU时间使用在网络吞吐上,比如4CPU的服务器启动1000个繁忙的进程基本上无法正常服务。系统伸缩性(System Scalability)非常好,增加CPU时一般系统吞吐率是线性增长的。目前比较少见纯粹的多进程服务器了,特别是一个连接一个进程这种。虽然性能很低,但是系统复杂度低(Simple),进程很独立,不需要处理锁或者状态。
- MT(Multi-Threaded)多线程模型:有的是每个连接一个线程,改进型的是按照职责分连接,比如读写分离的线程,几个线程读,几个线程写。系统的鲁棒性不好(Poor),一个连接或线程出现问题,影响其他的线程,彼此互相影响。负载伸缩性(Load Scalability)比较好(Good),线程比进程轻量一些,多个用户线程对应一个内核线程,但出现被阻塞时性能会显著降低,变成和多进程一样的情况。系统伸缩性(System Scalability)比较差(Poor),主要是因为线程同步,就算用户空间避免锁,在内核层一样也避免不了;增加CPU时,一般在多线程上会有损耗,并不能获得多进程那种几乎线性的吞吐率增加。多线程的复杂度(Complex)也比较高,主要是并发和锁引入的问题。
- EDSM(Event-Driven State Machine)事件驱动的状态机。比如select/poll/epoll,一般是单进程单线程,这样可以避免多进程的锁问题,为了避免单程的系统伸缩问题可以使用多进程单线程,比如NGINX就是这种方式。系统鲁棒性比较好(Good),一个进程服务一部分的客户端,有一定的隔离。负载伸缩性(Load Scalability)非常好(Great),没有进程或线程的切换,用户空间的开销也非常少,CPU几乎都可以用在网络吞吐上。系统伸缩性(System Scalability)很好,多进程扩展时几乎是线性增加吞吐率。虽然效率很高,但是复杂度也非常高(Very Complex),需要维护复杂的状态机,特别是两个耦合的状态机,比如客户端服务的状态机和回源的状态机。
- ST(StateThreads)协程模型。在EDSM的基础上,解决了复杂状态机的问题,从堆开辟协程的栈,将状态保存在栈中,在异步IO等待(EAGAIN)时,主动切换(setjmp/longjmp)到其他的协程完成IO。也就是ST是综合了EDSM和MT的优势,不过ST的线程是用户空间线程而不是系统线程,用户空间线程也会有调度的开销,不过比系统的开销要小很多。协程的调度开销,和EDSM的大循环的开销差不多,需要循环每个激活的客户端,逐个处理。而ST的主要问题,在于平台的适配,由于glibc的setjmp/longjmp是加密的无法修改SP栈指针,所以ST自己实现了这个逻辑,对于不同的平台就需要自己适配,目前Linux支持比较好,Windows不支持,另外这个库也不在维护有些坑只能绕过去,比较偏僻使用和维护者都很少,比如ST Patch修复了一些问题。
我将Go也放在了ST这种模型中,虽然它是
多线程+协程,和SRS不同是多进程+协程(SRS本身是单进程+协程可以扩展为多进程+协程)。
从并发模型看Go的goroutine,Go有ST的优势,没有ST的劣势,这就是Go的并发模型厉害的地方了。当然Go的多线程是有一定开销的,并没有纯粹多进程单线程那么高的负载伸缩性,在活跃的连接过多时,可能会激活多个物理线程,导致性能降低。也就是Go的性能会比ST或EDSM要差,而这些性能用来交换了系统的维护性,个人认为很值得。除了goroutine,另外非常关键的就是chan。Go的并发实际上并非只有goroutine,而是goroutine+chan,chan用来在多个goroutine之间同步。实际上在这两个机制上,还有标准库中的context,这三板斧是Go的并发的撒手锏。
- goroutine: Go对于协程的语言级别原生支持,一个go就可以启动一个协程。ST是通过函数来实现。
- chan和select: goroutine之间通信的机制,ST如果要实现两个协程的消息传递和等待,只能自己实现queue和cond。如果要同步多个呢?比如一个协程要处理多种消息,包括用户取消,超时,其他线程的事件,Go提供了select关键字。参考
Share Memory By Communicating。 - context: 管理goroutine的组件,参考GOLANG使用Context管理关联goroutine以及GOLANG使用Context实现传值、超时和取消。参考
Go Concurrency Patterns: Timing out, moving on和Go Concurrency Patterns: Context。
由于Go是多线程的,关于多线程或协程同步,除了chan也提供了Mutex,其实这两个都是可以用的,而且有时候比较适合用chan而不是用Mutex,有时候适合用Mutex不适合用chan,参考Mutex or Channel。
| Channel | Mutex |
|---|---|
| passing ownership of data, distributing units of work, communicating async results |
caches, state |
特别提醒:不要惧怕使用Mutex,不要什么都用chan,千里马可以一日千里却不能抓老鼠,HelloKitty跑不了多快抓老鼠却比千里马强。
实际上goroutine的管理,在真正高可用的程序中是非常必要的,我们一般会需要支持几种gorotine的控制方式:
- 错误处理:比如底层函数发生错误后,我们是忽略并告警(比如只是某个连接受到影响),还是选择中断整个服务(比如LICENSE到期)。
- 用户取消:比如升级时,我们需要主动的迁移新的请求到新的服务,或者取消一些长时间运行的goroutine,这就叫热升级。
- 超时关闭:比如请求的最大请求时长是30秒,那么超过这个时间,我们就应该取消请求。一般客户端的服务响应是有时间限制的。
- 关联取消:比如客户端请求服务器,服务器还要请求后端很多服务,如果中间客户端关闭了连接,服务器应该中止,而不是继续请求完所有的后端服务。
而goroutine的管理,最开始只有chan和sync,需要自己手动实现goroutine的生命周期管理,参考Go Concurrency Patterns: Timing out, moving on和Go Concurrency Patterns: Context,这些都是goroutine的并发范式。
直接使用原始的组件管理goroutine太繁琐了,后来在一些大型项目中出现了context这些库,并且Go1.7之后变成了标准库的一部分。具体参考GOLANG使用Context管理关联goroutine以及GOLANG使用Context实现传值、超时和取消。
Context也有问题:
- 支持Cancel、Timeout和Value,这些都是扩张Context树的节点。Cancel和Timeout在子树取消时会删除子树,不会一直膨胀;Value没有提供删除的函数,如果他们有公共的根节点,会导致这个Context树越来越庞大;所以Value类型的Context应该挂在Cancel的Context树下面,这样在取消时GC会回收。
- 会导致接口不一致或者奇怪,比如io.Reader其实第一个参数应该是context,比如
Read(Context, []byte)函数。或者提供两套接口,一种带Contex,一种不带Context。这个问题还蛮困扰人的,一般在应用程序中,推荐第一个参数是Context。 - 注意Context树,如果因为Closure导致树越来越深,会有调用栈的性能问题。比如十万个长链,会导致CPU占用500%左右。
备注:关于对Context的批评,可以参考Context should go away for Go 2,作者觉得在标准库中加context作为第一个参数不能理解,比如
Read(ctx context.Context等。
我觉得Go在工程上良好的支持,是Go能够在服务器领域有一席之地的重要原因。这里说的工程友好包括:
- gofmt保证代码的基本一致,增加可读性,避免在争论不清楚的地方争论。
- 原生支持的profiling,为性能调优和死锁问题提供了强大的工具支持。
- utest和coverage,持续集成,为项目的质量提供了良好的支撑。
- example和注释,让接口定义更友好合理,让库的质量更高。
这几天朋友圈霸屏的新闻是码农因为代码不规范问题枪击同事,虽然实际上枪击案可能不是因为代码规范,但可以看出大家对于代码规范问题能引发枪击是毫不怀疑的。这些年在不同的公司码代码,和不同的人一起码代码,每个地方总有人喜欢纠结于if ()中是否应该有空格,甚至还大开怼戒。Go语言从来不会有这种争论,因为有gofmt,语言的工具链支持了格式化代码,避免大家在代码风格上白费口舌。
比如,下面的代码看着真是揪心,任何语言都可以写出类似的一坨代码:
package main
import (
"fmt"
"strings"
)
func foo()[]string {
return []string{"gofmt","pprof","cover"}}
func main() {
if v:=foo();len(v)>0{fmt.Println("Hello",strings.Join(v,", "))}
}如果有几万行代码都是这样,是不是有扣动扳机的冲动?如果我们执行下gofmt -w t.go之后,就变成下面的样子:
package main
import (
"fmt"
"strings"
)
func foo() []string {
return []string{"gofmt", "pprof", "cover"}
}
func main() {
if v := foo(); len(v) > 0 {
fmt.Println("Hello", strings.Join(v, ", "))
}
}是不是心情舒服多了?gofmt只能解决基本的代码风格问题,虽然这个已经节约了不少口舌和唾沫,我想特别强调几点:
- 有些IDE会在保存时自动gofmt,如果没有手动运行下命令
gofmt -w .,可以将当前目录和子目录下的所有文件都格式化一遍,也很容易的是不是。 - gofmt不识别空行,因为空行是有意义的,因为空行有意义所以gofmt不知道如何处理,而这正是很多同学经常犯的问题。
- gofmt有时候会因为对齐问题,导致额外的不必要的修改,这不会有什么问题,但是会干扰CR从而影响CR的质量。
先看空行问题,不能随便使用空行,因为空行有意义。不能在不该空行的地方用空行,不能在该有空行的地方不用空行,比如下面的例子:
package main
import (
"fmt"
"io"
"os"
)
func main() {
f, err := os.Open(os.Args[1])
if err != nil {
fmt.Println("show file err %v", err)
os.Exit(-1)
}
defer f.Close()
io.Copy(os.Stdout, f)
}上面的例子看起来就相当的奇葩,if和os.Open之间没有任何原因需要个空行,结果来了个空行;而defer和io.Copy之间应该有个空行却没有个空行。空行是非常好的体现了逻辑关联的方式,所以空行不能随意,非常严重影响可读性,要么就是一坨东西看得很费劲,要么就是突然看到两个紧密的逻辑身首异处,真的让人很诧异。上面的代码可以改成这样,是不是看起来很舒服了:
package main
import (
"fmt"
"io"
"os"
)
func main() {
f, err := os.Open(os.Args[1])
if err != nil {
fmt.Println("show file err %v", err)
os.Exit(-1)
}
defer f.Close()
io.Copy(os.Stdout, f)
}再看gofmt的对齐问题,一般出现在一些结构体有长短不一的字段,比如统计信息,比如下面的代码:
package main
type NetworkStat struct {
IncomingBytes int `json:"ib"`
OutgoingBytes int `json:"ob"`
}
func main() {
}如果新增字段比较长,会导致之前的字段也会增加空白对齐,看起来整个结构体都改变了:
package main
type NetworkStat struct {
IncomingBytes int `json:"ib"`
OutgoingBytes int `json:"ob"`
IncomingPacketsPerHour int `json:"ipp"`
DropKiloRateLastMinute int `json:"dkrlm"`
}
func main() {
}比较好的解决办法就是用注释,添加注释后就不会强制对齐了。
性能调优是一个工程问题,关键是测量后优化,而不是盲目优化。Go提供了大量的测量程序的工具和机制,包括Profiling Go Programs, Introducing HTTP Tracing,我们也在性能优化时使用过Go的Profiling,原生支持是非常便捷的。
对于多线程同步可能出现的死锁和竞争问题,Go提供了一系列工具链,比如Introducing the Go Race Detector, Data Race Detector,不过打开race后有明显的性能损耗,不应该在负载较高的线上服务器打开,会造成明显的性能瓶颈。
推荐服务器开启http profiling,侦听在本机可以避免安全问题,需要profiling时去机器上把profile数据拿到后,拿到线下分析原因。实例代码如下:
package main
import (
"net/http"
_ "net/http/pprof"
"time"
)
func main() {
go http.ListenAndServe("127.0.0.1:6060", nil)
for {
b := make([]byte, 4096)
for i := 0; i < len(b); i++ {
b[i] = b[i] + 0xf
}
time.Sleep(time.Nanosecond)
}
}编译成二进制后启动go mod init private.me && go build . && ./private.me,在浏览器访问页面可以看到各种性能数据的导航:http://localhost:6060/debug/pprof/
例如分析CPU的性能瓶颈,可以执行go tool pprof private.me http://localhost:6060/debug/pprof/profile,默认是分析30秒内的性能数据,进入pprof后执行top可以看到CPU使用最高的函数:
(pprof) top
Showing nodes accounting for 42.41s, 99.14% of 42.78s total
Dropped 27 nodes (cum <= 0.21s)
Showing top 10 nodes out of 22
flat flat% sum% cum cum%
27.20s 63.58% 63.58% 27.20s 63.58% runtime.pthread_cond_signal
13.07s 30.55% 94.13% 13.08s 30.58% runtime.pthread_cond_wait
1.93s 4.51% 98.64% 1.93s 4.51% runtime.usleep
0.15s 0.35% 98.99% 0.22s 0.51% main.main除了top,还可以输入web命令看调用图,还可以用go-torch看火焰图等。
当然工程化少不了UTest和覆盖率,关于覆盖Go也提供了原生支持The cover story,一般会有专门的CISE集成测试环境。集成测试之所以重要,是因为随着代码规模的增长,有效的覆盖能显著的降低引入问题的可能性。
什么是有效的覆盖?一般多少覆盖率比较合适?80%覆盖够好了吗?90%覆盖一定比30%覆盖好吗?我觉得可不一定了,参考Testivus On Test Coverage。对于UTest和覆盖,我觉得重点在于:
- UTest和覆盖率一定要有,哪怕是0.1%也必须要有,为什么呢?因为出现故障时让老板心里好受点啊,能用数据衡量出来裸奔的代码有多少。
- 核心代码和业务代码一定要分离,强调核心代码的覆盖率才有意义,比如整体覆盖了80%,核心代码占5%,核心代码覆盖率为10%,那么这个覆盖就不怎么有效了。
- 除了关键正常逻辑,更应该重视异常逻辑,异常逻辑一般不会执行到,而一旦藏有bug可能就会造成问题。有可能有些罕见的代码无法覆盖到,那么这部分逻辑代码,CR时需要特别人工Review。
分离核心代码是关键。可以将核心代码分离到单独的package,对这个package要求更高的覆盖率,比如我们要求98%的覆盖(实际上做到了99.14%的覆盖)。对于应用的代码,具备可测性是非常关键的,举个我自己的例子,go-oryx这部分代码是判断哪些url是代理,就不具备可测性,下面是主要的逻辑:
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
if o := r.Header.Get("Origin"); len(o) > 0 {
w.Header().Set("Access-Control-Allow-Origin", "*")
}
if proxyUrls == nil {
......
fs.ServeHTTP(w, r)
return
}
for _, proxyUrl := range proxyUrls {
srcPath, proxyPath := r.URL.Path, proxyUrl.Path
......
if proxy, ok := proxies[proxyUrl.Path]; ok {
p.ServeHTTP(w, r)
return
}
}
fs.ServeHTTP(w, r)
})可以看得出来,关键需要测试的核心代码,在于后面如何判断URL符合定义的规范,这部分应该被定义成函数,这样就可以单独测试了:
func shouldProxyURL(srcPath, proxyPath string) bool {
if !strings.HasSuffix(srcPath, "/") {
// /api to /api/
// /api.js to /api.js/
// /api/100 to /api/100/
srcPath += "/"
}
if !strings.HasSuffix(proxyPath, "/") {
// /api/ to /api/
// to match /api/ or /api/100
// and not match /api.js/
proxyPath += "/"
}
return strings.HasPrefix(srcPath, proxyPath)
}
func run(ctx context.Context) error {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
......
for _, proxyUrl := range proxyUrls {
if !shouldProxyURL(r.URL.Path, proxyUrl.Path) {
continue
}代码参考go-oryx: Extract and test URL proxy,覆盖率请看gocover: For go-oryx coverage,这样的代码可测性就会比较好,也能在有限的精力下尽量让覆盖率有效。
Note: 可见,单元测试和覆盖率,并不是测试的事情,而是代码本身应该提高的代码“可测试性”。
另外,对于Go的测试还有几点值得说明:
- helper:测试时如果调用某个函数,出错时总是打印那个共用的函数的行数,而不是测试的函数。比如test_helper.go,如果
compare不调用t.Helper(),那么错误显示是hello_test.go:26: Returned: [Hello, world!], Expected: [BROKEN!],调用t.Helper()之后是hello_test.go:18: Returned: [Hello, world!], Expected: [BROKEN!]`,实际上应该是18行的case有问题,而不是26行这个compare函数的问题。 - benchmark:测试时还可以带Benchmark的,参数不是
testing.T而是testing.B,执行时会动态调整一些参数,比如testing.B.N,还有并行执行的testing.PB. RunParallel,参考Benchamrk。 - main: 测试也是有个main函数的,参考TestMain,可以做一些全局的初始化和处理。
- doc.go: 整个包的文档描述,一般是在
package http前面加说明,比如http doc的使用例子。
对于Helper还有一种思路,就是用带堆栈的error,参考前面关于errors的说明,不仅能将所有堆栈的行数给出来,而且可以带上每一层的信息。
注意如果package只暴露了interface,比如go-oryx-lib: aac通过
NewADTS() (ADTS, error)返回的是接口ADTS,无法给ADTS的函数加Example;因此我们专门暴露了一个ADTSImpl的结构体,而New函数返回的还是接口,这种做法不是最好的,让用户有点无所适从,不知道该用ADTS还是ADTSImpl。所以一种可选的办法,就是在包里面有个doc.go放说明,例如net/http/doc.go文件,就是在package http前面加说明,比如http doc的使用例子。
注释和Example是非常容易被忽视的,我觉得应该注意的地方包括:
- 项目的README.md和Wiki,这实际上就是新人指南,因为新人如果能懂那么就很容易了解这个项目的大概情况,很多项目都没有这个。如果没有README,那么就需要看文件,该看哪个文件?这就让人很抓狂了。
- 关键代码没有注释,比如库的API,关键的函数,不好懂的代码段落。如果看标准库,绝大部分可以调用的API都有很好的注释,没有注释怎么调用呢?只能看代码实现了,如果每次调用都要看一遍实现,真的很难受了。
- 库没有Example,库是一种要求很高的包,就是给别人使用的包,比如标准库。绝大部分的标准库的包,都有Example,因为没有Example很难设计出合理的API。
先看关键代码的注释,有些注释完全是代码的重复,没有任何存在的意义,唯一的存在就是提高代码的“注释率”,这又有什么用呢,比如下面代码:
wsconn *Conn //ws connection
// The RPC call.
type rpcCall struct {
// Setup logger.
if err := SetupLogger(......); err != nil {
// Wait for os signal
server.WaitForSignals(如果注释能通过函数名看出来(比较好的函数名要能看出来它的职责),那么就不需要写重复的注释,注释要说明一些从代码中看不出来的东西,比如标准库的函数的注释:
// Serve accepts incoming connections on the Listener l, creating a
// new service goroutine for each. The service goroutines read requests and
// then call srv.Handler to reply to them.
//
// HTTP/2 support is only enabled if the Listener returns *tls.Conn
// connections and they were configured with "h2" in the TLS
// Config.NextProtos.
//
// Serve always returns a non-nil error and closes l.
// After Shutdown or Close, the returned error is ErrServerClosed.
func (srv *Server) Serve(l net.Listener) error {
// ParseInt interprets a string s in the given base (0, 2 to 36) and
// bit size (0 to 64) and returns the corresponding value i.
//
// If base == 0, the base is implied by the string's prefix:
// base 2 for "0b", base 8 for "0" or "0o", base 16 for "0x",
// and base 10 otherwise. Also, for base == 0 only, underscore
// characters are permitted per the Go integer literal syntax.
// If base is below 0, is 1, or is above 36, an error is returned.
//
// The bitSize argument specifies the integer type
// that the result must fit into. Bit sizes 0, 8, 16, 32, and 64
// correspond to int, int8, int16, int32, and int64.
// If bitSize is below 0 or above 64, an error is returned.
//
// The errors that ParseInt returns have concrete type *NumError
// and include err.Num = s. If s is empty or contains invalid
// digits, err.Err = ErrSyntax and the returned value is 0;
// if the value corresponding to s cannot be represented by a
// signed integer of the given size, err.Err = ErrRange and the
// returned value is the maximum magnitude integer of the
// appropriate bitSize and sign.
func ParseInt(s string, base int, bitSize int) (i int64, err error) {标准库做得很好的是,会把参数名称写到注释中(而不是用@param这种方式),而且会说明大量的背景信息,这些信息是从函数名和参数看不到的重要信息。
咱们再看Example,一种特殊的test,可能不会执行,它的主要作用是为了推演接口是否合理,当然也就提供了如何使用库的例子,这就要求Example必须覆盖到库的主要使用场景。举个例子,有个库需要方式SSRF攻击,也就是检查HTTP Redirect时的URL规则,最初我们是这样提供这个库的:
func NewHttpClientNoRedirect() *http.Client {看起来也没有问题,提供一种特殊的http.Client,如果发现有Redirect就返回错误,那么它的Example就会是这样:
func ExampleNoRedirectClient() {
url := "http://xxx/yyy"
client := ssrf.NewHttpClientNoRedirect()
Req, err := http.NewRequest("GET", url, nil)
if err != nil {
fmt.Println("failed to create request")
return
}
resp, err := client.Do(Req)
fmt.Printf("status :%v", resp.Status)
}这时候就会出现问题,我们总是返回了一个新的http.Client,如果用户自己有了自己定义的http.Client怎么办?实际上我们只是设置了http.Client.CheckRedirect这个回调函数。如果我们先写Example,更好的Example会是这样:
func ExampleNoRedirectClient() {
client := http.Client{}
//Must specify checkRedirect attribute to NewFuncNoRedirect
client.CheckRedirect = ssrf.NewFuncNoRedirect()
Req, err := http.NewRequest("GET", url, nil)
if err != nil {
fmt.Println("failed to create request")
return
}
resp, err := client.Do(Req)
}那么我们自然知道应该如何提供接口了。
最近得知WebRTC有4GB的代码,包括它自己的以及依赖的代码,就算去掉一般的测试文件和文档,也有2GB的代码!!!编译起来真的是非常的耗时间,而Go对于编译速度的优化,据说是在Google有过验证的,具体我们还没有到这个规模。具体可以参考Why so fast?,主要是编译器本身比GCC快(5X),以及Go的依赖管理做的比较好。
Go的内存和异常处理也做得很好,比如不会出现野指针,虽然有空指针问题可以用recover来隔离异常的影响。而C或C++服务器,目前还没有见过没有内存问题的,上线后就是各种的野指针满天飞,总有因为野指针搞死的时候,只是或多或少罢了。
按照Go的版本发布节奏,6个月就发一个版本,基本上这么多版本都很稳定,Go1.11的代码一共有166万行Go代码,还有12万行汇编代码,其中单元测试代码有32万行(占17.9%),使用实例Example有1.3万行。Go对于核心API是全部覆盖的,提交有没有导致API不符合要求都有单元测试保证,Go有多个集成测试环境,每个平台是否测试通过也能看到,这一整套机制让Go项目虽然越来越庞大,但是整体研发效率却很高。
Go2的设计草案在Go 2 Draft Designs或者这里,而Go1如何迁移到Go2也是我个人特别关心的问题,Python2和Python3的那种不兼容的迁移方式简直就是噩梦一样的记忆。Go的提案中,有一个专门说了迁移的问题,参考Go2 Transition。
Go2 Transition还不是最终方案,不过它也对比了各种语言的迁移,还是很有意思的一个总结。这个提案描述了在非兼容性变更时,如何给开发者挖的坑最小。
目前Go1的标准库是遵守兼容性原则的,参考Go 1 compatibility guarantee,这个规范保证了Go1没有兼容性问题,几乎可以没有影响的升级比如从Go1.2升级到Go1.11。几乎的意思,是很大概率是没有问题,当然如果用了一些非常冷门的特性,可能会有坑,我们遇到过json解析时,内嵌结构体的数据成员也得是exposed的才行,而这个在老版本中是可以非exposed;还遇到过cgo对于链接参数的变更导致编译失败,这些问题几乎很难遇到,都可以算是兼容的吧,有时候只是把模糊不清的定义清楚了而已。
Go2在语言和标准库上,会打破Go1的兼容性规范,也就是和Go1不再兼容。不过Go是分布式开源社区在维护,不能依赖于flag day,还是要容许不同Go版本写的package的互操作性。先了解下各个语言如何考虑兼容性:
-
C是严格向后兼容的,很早写的程序总是能在新的编译器中编译。另外新的编译器也支持指定之前的标准,比如
-std=c90使用ISO C90标准编译程序。关键的特性是编译成目标文件后,不同版本的C的目标文件,能完美的链接成执行程序。C90实际上是对之前K&R C版本不兼容的,主要引入了volatile关键字,还有整数精度问题,还引入了trigraphs,最糟糕的是引入了undefined行为比如数组越界和整数溢出的行为未定义。从C上可以学到的是:后向兼容非常重要;非常小的打破兼容性也问题不大特别是可以通过编译器选项来处理;能将不同版本的目标文件链接到一起是非常关键的;undefined行为严重困扰开发者容易造成问题。 - C++也是ISO组织驱动的语言,和C一样也是向后兼容的。C++和C一样坑爹的地方坑到吐血,比如undefined行为等等。尽管一直保持向后兼容,但是新的C++代码比如C++11看起来完全不同,这是因为有新的改变的特性,比如很少会用裸指针,比如range代替了传统的for循环,这导致熟悉老C++语法的程序员看新的代码非常难受甚至看不懂。C++毋庸置疑是非常流行的,但是新的语言标准在这方面没有贡献。从C++上可以学到的新东西是:尽管保持向后兼容,语言的新版本可能也会带来巨大的不同的感受(保持向后兼容并不能保证能持续看懂)。
- Java也是向后兼容的,是在字节码层面和语言层面都向后兼容,尽管语言上不断的新增了关键字。Java的标准库非常庞大,也不断的在更新,过时的特性会被标记为deprecated并且编译时会有警告,理论上一定版本后deprecated的特性会不可用。Java的兼容性问题主要在JVM解决,如果用新的版本编译的字节码,得用新的JVM才能执行。Java还做了一些前向兼容,这个影响了字节码啥的(我本身不懂Java,作者也不说自己不是专家,我就没仔细看了)。Java上可以学到的新东西是:要警惕因为保持兼容性而限制语言未来的改变。
-
Python2.7是2010年发布的,目前主要是用这个版本。Python3是2006年开始开发,2008年发布,十年后的今天还没有迁移完成,甚至主要是用的Python2而不是Python3,这当然不是Go2要走的路。看起来是因为缺乏向后兼容导致的问题,Python3刻意的和之前版本不兼容,比如print从语句变成了一个函数,string也变成了Unicode(这导致和C调用时会有很多问题)。没有向后兼容,同时还是解释型语言,这导致Python2和3的代码混着用是不可能的,这以为着程序依赖的所有库必须支持两个版本。Python支持
from __future__ import FEATURE,这样可以在Python2中用Python3的特性。Python上可以学到的东西是:向后兼容是生死攸关的;和其他语言互操作的接口兼容是非常重要的;能否升级到新的语言是由调用的库支持的。 - Perl6是2000年开始开发的,15年后才正式发布,这也不是Go2应该走的路。这么漫长的主要原因包括,刻意没有向后兼容,只有语言的规范没有实现而这些规范不断的修改。Perl上可以学到的东西是:不要学Perl;设置期限按期交付;别一下子全部改了。
特别说明的是,非常高兴的是Go2不会重新走Python3的老路子,当初被Python的版本兼容问题坑得不要不要的。
虽然上面只是列举了各种语言的演进,确实也了解得更多了,有时候描述问题本身,反而更能明白解决方案。C和C++的向后兼容确实非常关键,但也不是他们能有今天地位的原因,C++11的新特性到底增加了多少DAU呢,确实是值得思考的。另外C++11加了那么多新的语言特性,比如WebRTC代码就是这样,很多老C++程序员看到后一脸懵逼,和一门新的语言一样了,是否保持完全的兼容不能做一点点变更,其实也不是的。
应该将Go的语言版本和标准库的版本分开考虑,这两个也是分别演进的,例如alias是1.9引入的向后兼容的特性,1.9之前的版本不支持,1.9之后的都支持。语言方面包括:
- Language additions新增的特性,比如1.9新增的type alias。这些向后兼容的新特性,并不要求代码中指定特殊的版本号,比如用了alias的代码不用指定要1.9才能编译,用之前的版本会报错。向后兼容的语言新增的特性,是依靠程序员而不是工具链来维护的,要用这个特性或库升级到要求的版本就可以。
-
Language removals删除的特性。比如有个提案#3939去掉
string(int),字符串构造函数不支持整数,假设这个在Go1.20版本去掉,那么Go1.20之后这种string(1000)代码就要编译失败了。这种情况没有特别好的办法能解决,我们可以提供工具,将代码自动替换成新的方式,这样就算库维护者不更新,使用者自己也能更新。这种场景引出了指定最大版本,类似C的-std=C90,可以指定最大编译的版本比如-lang=go1.19,当然必须能和Go1.20的代码链接。指定最大版本可以在go.mod中指定,这需要工具链兼容历史的版本,由于这种特性的删除不会很频繁,维护负担还是可以接受的。 -
Minimum language version最小要求版本。为了可以更明确的错误信息,可以允许模块在
go.mod中指定最小要求的版本,这不是强制性的,只是说明了这个信息后编译工具能明确的给出错误,比如给出应该用具体哪个版本。 - Language redefinitions语言重定义。比如Go1.1时,int在64位系统中长度从4字节变成了8字节,这会导致很多潜在的问题。比如#20733修改了变量在for中的作用域,看起来是解决潜在的问题,但也可能会引入问题。引入关键字一般不会有问题,不过如果和函数冲突就会有问题,比如error: check。为了让Go的生态能迁移到Go2,语言重定义的事情应该尽量少做,因为我们不再能依赖编译器检查错误。虽然指定版本能解决这种问题,但是这始终会导致未知的结果,很有可能一升级Go版本就挂了。**我觉得对于语言重定义,应该完全禁止。**比如#20733可以改成禁止这种做法,这样就会变成编译错误,可能会帮助找到代码中潜在的BUG。
- Build tags编译tags。在指定文件中指定编译选项,是现有的机制,不过是指定的release版本号,它更多是指定了最小要求的版本,而没有解决最大依赖版本问题。
-
Import go2导入新特性。和Python的特性一样,可以在Go1中导入Go2的新特性,比如可以显示的导入
import "go2/type-aliases",而不是在go.mod中隐式的指定。这会导致语言比较复杂,将语言打乱成了各种特性的组合。而且这种方式一旦使用,将无法去掉。这种方式看起来不太适合Go。
如果有更多的资源来维护和测试,标准库后续会更快发布,虽然还是6个月的周期。标准库方面的变更包括:
-
Core standard library核心标准库。有些和编译工具链相关的库,还有其他的一些关键的库,应该遵守6个月的发布周期,而且这些核心标准库应该保持Go1的兼容性,比如
os/signal、reflect、runtime、sync、testing、time、unsafe等等。我可能乐观的估计net,os, 和syscall不在这个范畴。 -
Penumbra standard library边缘标准库。它们被独立维护,但是在一个release中一起发布,当前核心库大部分都属于这种。这使得可以用
go get等工具来更新这些库,比6个月的周期会更快。标准库会保持和前面版本的编译兼容,至少和前面一个版本兼容。 -
Removing packages from the standard library去掉一些不太常用的标准库,比如
net/http/cgi等。
如果上述的工作做得很好的话,开发者会感觉不到有个大版本叫做Go2,或者这种缓慢而自然的变化逐渐全部更新成了Go2。甚至我们都不用宣传有个Go2,既然没有C2.0为何要Go2.0呢?主流的语言比如C、C++和Java从来没有2.0,一直都是1.N的版本,我们也可以模仿他们。事实上,一般所认为的全新的2.0版本,若出现不兼容性的语言和标准库,对用户也不是个好结果,甚至还是有害的。
关于Go,还有哪些重要的技术值得了解的,下面详细分享。
GC一般是C/C++程序员对于Go最常见,也是最先想到的一个质疑,GC这玩意儿能行吗?我们以前C/C++程序都是自己实现内存池的,我们内存分配算法非常牛逼的。
Go的GC优化之路,可以详细读Getting to Go: The Journey of Go's Garbage Collector。
2014年Go1.4,GC还是很弱的,是决定Go生死的大短板。
上图是Twitter的线上服务监控。Go1.4的STW(Stop the World) Pause time是300毫秒,而Go1.5优化到了30毫秒。
而Go1.6的GC暂停时间降低到了3毫秒左右。
Go1.8则降低到了0.5毫秒左右,也就是500微秒。从Go1.4到Go1.8,优化了600倍性能。
如何看GC的STW时间呢?可以引入net/http/pprof这个库,然后通过curl来获取数据,实例代码如下:
package main
import (
"net/http"
_ "net/http/pprof"
)
func main() {
http.ListenAndServe("localhost:6060", nil)
}
启动程序后,执行命令就可以拿到结果(由于上面的例子中没有GC,下面的数据取的是另外程序的部分数据):
$ curl 'http://localhost:6060/debug/pprof/allocs?debug=1' 2>/dev/null |grep PauseNs
# PauseNs = [205683 79032 202102 82216 104853 142320 90058 113638 152504
145965 72047 49690 158458 60499 99610 112754 122262 52252 49234 68420 159857
97940 226085 103644 135428 245291 141997 92470 79974 132817 74634 65653 73582
47399 51653 86107 48619 62583 68906 131868 111903 85482 44531 74585 50162
31445 107397 10903081771 92603 58585 96620 40416 29763 102248 32804 49394
83715 77099 108983 66133 47832 35379 143949 69235 27820 35677 99430 104303
132657 63542 39434 126418 63845 167969 116438 68904 77899 136506 119708 47501]
可以用python计算最大值是322微秒,最小是26微秒,平均值是81微秒。
关于Go的声明语法Go Declaration Syntax,和C语言有对比,在The "Clockwise/Spiral Rule"这个文章中也详细描述了C的顺时针语法规则。其中有个例子:
int (*signal(int, void (*fp)(int)))(int);
这个是个什么呢?翻译成Go语言就能看得很清楚:
func signal(a int, b func(int)) func(int)int
signal是个函数,有两个参数,返回了一个函数指针。signal的第一个参数是int,第二个参数是一个函数指针。
当然实际上C语言如果借助typedef也是能获得比较好的可读性的:
typedef void (*PFP)(int);
typedef int (*PRET)(int);
PRET signal(int a, PFP b);
只是从语言的语法设计上来说,还是Go的可读性确实会好一些。这些点点滴滴的小傲娇,是否可以支撑我们够浪程序员浪起来的资本呢?至少Rob Pike不是拍脑袋和大腿想出来的规则嘛,这种认真和严谨是值得佩服和学习的。
新的语言文档支持都很好,不用买本书看,Go也是一样,Go官网历年比较重要的文章包括:
- 语法特性及思考:
Go Declaration Syntax,The Laws of Reflection,Constants,Generics Discussion,Another Go at Language Design,Composition not inheritance,Interfaces and other types - 并发相关特性:
Share Memory By Communicating,Go Concurrency Patterns: Timing out, moving on,Concurrency is not parallelism,Advanced Go Concurrency Patterns,Go Concurrency Patterns: Pipelines and cancellation,Go Concurrency Patterns: Context,Mutex or Channel - 错误处理相关:
Defer, Panic, and Recover,Error handling and Go,Errors are values,Stack traces and the errors package,Error Handling In Go,The Error Model - 性能和优化:
Profiling Go Programs,Introducing the Go Race Detector,The cover story,Introducing HTTP Tracing,Data Race Detector - 标准库说明:
Go maps in action,Go Slices: usage and internals,Arrays, slices (and strings): The mechanics of append,Strings, bytes, runes and characters in Go - 和C的结合:
C? Go? Cgo! - 项目相关:
Organizing Go code,Package names,Effective Go,versioning,Russ Cox: vgo - 关于GC:
Go GC: Prioritizing low latency and simplicity,Getting to Go: The Journey of Go Garbage Collector,Proposal: Eliminate STW stack re-scanning
其中,文章中有引用其他很好的文章,我也列出来哈:
-
Go Declaration Syntax,引用了一篇神作,介绍C的螺旋语法,写C的多,读过这个的不多,The "Clockwise/Spiral Rule" -
Strings, bytes, runes and characters in Go,引用了很好的一篇文章,号称每个人都要懂的,关于字符集和Unicode的文章,Every Software Developer Must Know (No Excuses!) - 为何错误码模型,比异常模型更有优势,参考Cleaner, more elegant, and wrong 以及Cleaner, more elegant, and harder to recognize。
- Go中的面向对象设计原则SOLID。
- Go的版本语义Semantic Versioning,如何在大型项目中规范版本,避免导致依赖地狱(Dependency Hell)问题。
SRS是使用ST,单进程单线程,性能是EDSM模型的nginx-rtmp的3到5倍,参考SRS: Performance,当然不是ST本身性能是EDSM的三倍,而是说ST并不会比EDSM性能低,主要还是要根据业务上的特征做优化。
关于ST和EDSM,参考本文前面关于Concurrency对于协程的描述,ST它是C的一个协程库,EDSM是异步事件驱动模型。
SRS是单进程单线程,可以扩展为多进程,可以在SRS中改代码Fork子进程,或者使用一个TCP代理,比如TCP代理go-oryx: rtmplb。
在2016年和2017年我用Go重写过SRS,验证过Go使用2CPU可以跑到C10K,参考go-oryx,v0.1.13 Supports 10k(2CPUs) for RTMP players。由于仅仅是语言的差异而重写一个项目,没有找到更好的方式或理由,觉得很不值得,所以还是放弃了Go语言版本,只维护C++版本的SRS。Go目前一般在API服务器用得比较多,能否在流媒体服务器中应用?答案是肯定的,我已经实现过了。
后来在2017年,终于找到相对比较合理的方式来用Go写流媒体,就是只提供库而不是二进制的服务器,参考go-oryx-lib。
目前Go可以作为SRS前面的代理,实现多核的优势,参考go-oryx。
<<大结局-END>>
<<谢谢观赏>>