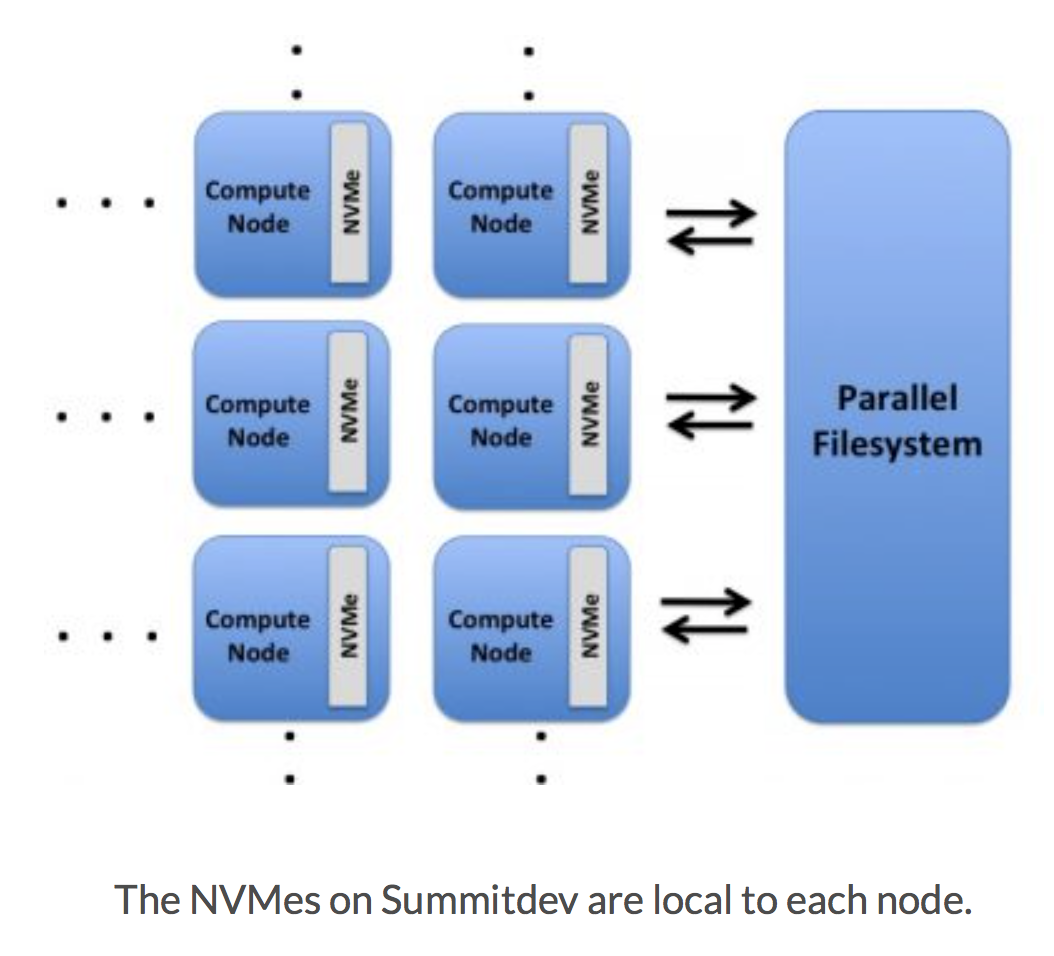
Each compute node on Summit has a Non-Volatile Memory (NVMe) storage device, colloquially known as a "Burst Buffer" with theoretical performance peak of 2.1 GB/s for writing and 6.0 GB/s for reading. Users will have access to an 1600 GB partition of each NVMe. The NVMes could be used to reduce the time that applications wait for I/O. Using an SSD drive per compute node, the burst buffer will be used to transfers data to or from the drive before the application reads a file or after it writes a file. The result will be that the application benefits from native SSD performance for a portion of its I/O requests.
More information: https://www.olcf.ornl.gov/for-users/system-user-guides/summit/summit-user-guide/#burst-buffer
In this tutorial we will use IOR benchmark to execute on GPFS and NVMe devices, while we will showcase the Spectral library
We will follow three examples, one executing IOR on GPFS, then on NVMe and the differences while using Spectral library. In all the cases we do write/read one file per MPI process. The IOR flags are outside the scope of this tutorial to be explained.
module load gcc
git clone https://github.com/hpc/ior.git
cd ior
./bootstrap
./configure --prefix=/declare_path/
make install
Select below the prefix from the configure command above
cd /declare_path/
Edit the file and declare your account
#!/bin/bash
#BSUB -P #ACCOUNT
#BSUB -J GPFS_IOR
#BSUB -o gpfs_ior.o%J
#BSUB -e gpfs_ior.e%J
#BSUB -W 10
#BSUB -nnodes 2
jsrun -n 2 -r 1 -a 16 -c 16 ./bin/ior -t 16m -b 19200m -F -g -G 27 -k -e -o ./output/ior_file_easy
submit the job script:
bsub gpfs_ior.sh
You can open the output/error files if you want or just execute the following on the output file, where XXXXX is your job ID:
$ grep Max gpfs_ior.oXXXXX | head -n 2
Max Write: 24640.02 MiB/sec (25836.93 MB/sec)
Max Read: 26941.26 MiB/sec (28249.96 MB/sec)
In this result from Summit, we could achieve 25836 MB/s and 28249 MB/s from two compute nodes, and because it runs for short time we could use some caching that achieves higher results. We can see from the output file:
Started at Mon May 13 16:48:49 2019
Terminated at Mon May 13 16:49:41 2019
So, it took 52 seconds
Edit the file and declare your account Here there are some changes:
- You need to declare the alloc_flags NVME
- If you want to copy either into/from NVME, you need to use the jsrun command, it is not available from the login node otherwise.
- We copy the data from NVMe, one process per compute node, so, per NVMe device and we save them in a fold er with timestamp to avoid overwriting
- The copy from NVme, takes time, that's why the time limit for the NVMe job could be longer than the GPFS job in some cases.
- Delete your data to avoid fill in your space.
#!/bin/bash
#BSUB -P #ACCOUNT
#BSUB -J NVME_IOR
#BSUB -o nvme_ior.o%J
#BSUB -e nvme_ior.e%J
#BSUB -W 20
#BSUB -nnodes 2
#BSUB -alloc_flags NVME
jsrun -n 2 -r 1 -a 16 -c 16 ./bin/ior -t 16m -b 19200m -F -g -G 27 -k -e -o /mnt/bb/$USER/ior_file_easy
timest=$(date +%s)
mkdir nvme_output_$timest
jsrun -n 2 -r 1 ls -l /mnt/bb/$USER/
jsrun -n 2 -r 1 cp -r /mnt/bb/$USER/ ./nvme_output_$timest/
submit the job script:
bsub nvme_ior.sh
You can open the output/error files if you want or just execute the following on the output file, where XXXXX is your job ID:
grep Max nvme_ior.oXXXXX | head -n 2
Max Write: 4173.36 MiB/sec (4376.08 MB/sec)
Max Read: 11161.54 MiB/sec (11703.73 MB/sec)
In this case the NVMe performance for two nodes is 4376 MB/s and 11703 MB/s for write/read, which is 5.9 and 2.4 times slower than the GPFS.
From the output file, we can see the following:
Started at Mon May 13 16:56:30 2019
Terminated at Mon May 13 16:59:58 2019
So, it took 223 seconds to finish. One question that arises, is why NVMe performance is worse than GPFS?

From the Summit architecture figure above, we have two observations. Initially, the maximum bandwidth per node is 12-14 GB/s while the performance of the NVMe is 6 GB/s and 2.1 GB/s for read and write respectively. This means that GPFS performance can be faster for many cases. The maximum bandwidth for GPFS is 2.5TB/s and while we scale, the performance per node drops to adjust to the total limitations. Thus, up to around 1000-1100 compute nodes, could perform better on GPFS than NVMe in some cases.
We did repeat the experiments on 1100 compute nodes and we got the following results:
Max Write: 1076349.75 MiB/sec (1128634.52 MB/sec) Max Read: 1335291.40 MiB/sec (1400154.51 MB/sec)
Max Write: 2228057.73 MiB/sec (2336287.86 MB/sec) Max Read: 6104023.86 MiB/sec (6400532.93 MB/sec)
Now, the NVMe performance is 2 and 4.57 times faster than GPFS in write and read respectively.
Of course, the results depend on the utilization of the system that moment and what the I/O workload and pattern is.
Spectral is a portable and transparent middleware library to enable use of the node-local burst buffers for accelerated application output on Summit. It is used to transfer files from node-local NVMe back to the parallel GPFS file system without the need of the user to interact during the job execution. Spectral runs on the isolated core of each reserved node, so it does not occupy resources and based on some parameters the user could define which folder to be copied to the GPFS. In order to use Spectral, the user has to do the following steps in the submission script:
- Request Spectral resources instead of NVMe
- Load spectrum module
- Declare the path where the files will be saved in the node-local NVMe (PERSIST_DIR)
- Declare the path on GPFS where the files will be copied (PFS_DIR)
- Execute the script spectral_wait.py when the application is finished in order to copy the files from NVMe to GPFS
- No need to copy the files manually, it is dome automatically.
#!/bin/bash
#BSUB -P #Account
#BSUB -J NVME_SPECTRAL_IOR
#BSUB -o nvme_spectral_ior.o%J
#BSUB -e nvme_spectral_ior.e%J
#BSUB -W 20
#BSUB -nnodes 2
#BSUB -alloc_flags spectral
module load spectral
export PERSIST_DIR=/mnt/bb/$USER
timest=$(date +%s)
mkdir nvme_output_$timest
export PFS_DIR=$PWD/nvme_output_$timest
jsrun -n 2 -r 1 -a 16 -c 16 ./bin/ior -t 16m -b 19200m -F -g -G 27 -k -e -o /mnt/bb/$USER/ior_file_easy
jsrun -n 2 -r 1 ls -l /mnt/bb/$USER/
spectral_wait.py
Submit the script
bsub spectral_ior.sh
In this case the output folder is named nvme_output_XXXX where XXXX is timestamp. Inside in this folder a file called spectral.log is created where it demonstrates if a file is copied yet, for example:
Spectral Work ENQUEUE File : /gpfs/alpine/stf007/scratch/gmarkoma/bb_training/install/nvme_output_1557776904/ior_file_easy.00000026
Spectral Work DEQUEUE File : /gpfs/alpine/stf007/scratch/gmarkoma/bb_training/install/nvme_output_1557776904/ior_file_easy.00000004
Spectral Work DONE File : /gpfs/alpine/stf007/scratch/gmarkoma/bb_training/install/nvme_output_1557776904/ior_file_easy.00000004
Enqueue means that the file will be copied, Dequeue that the file is under transfer, and Done that the transfer finished.
In the output file you can information such as:
...
Enqueued:32 Dequeued:32 Done:31
Enqueued:32 Dequeued:32 Done:31
All files moved
The file are transferred without a manual copy from the user. You can check the results as before.
More information about Spectral library: https://www.olcf.ornl.gov/spectral-library/
For the application that there are a lot of timesteps with I/O, the Spectral library transfers the data to GPFS on the background and not at the end of the execution.
A simple explanation of what is metadata, when we access a file, for example open/close, we send metadata request. It depends on how many requests occur, this couldbe stressful for the system. We have a test code called metadata.f90 which on purpose is quite not efficient on metadata. Just to remind on machine learning workloads, there are a lot of metadata while reading data to train the models.
cd metadata
module load gcc
mpif90 -o metadata metadata.f90
This application, for each MPI processes open a file, writes a value and close the file for 1 million times. This stress the metadata.
Execute the application on GPFS, edit the account on the gpfs_metadata.sh submission script:
#!/bin/bash
#BSUB -P #Account
#BSUB -J GPFS_Metadata
#BSUB -o gpfs_metadata.o%J
#BSUB -e gpfs_metadata.e%J
#BSUB -W 2
#BSUB -nnodes 1
jsrun -n 2 -r 2 -a 1 -c 1 ./metadata
We create only two processes and in the output file (gpfs_metadata.oXXX), you will have something like this:
Duration: 38.1130
This is 38.11 seconds to be executed on GPFS, 2 MPI processes on a single node.
However, if we execute the NVMe version:
#!/bin/bash
#BSUB -P #Account
#BSUB -J NVME_Metadata
#BSUB -o nvme_medatata.o%J
#BSUB -e nvme_medatata.e%J
#BSUB -W 2
#BSUB -nnodes 1
#BSUB -alloc_flags NVME
export BBPATH=/mnt/bb/$USER
jsrun -n 1 cp metadata ${BBPATH}
jsrun -n 2 -r 2 -a 1 -c 1 --chdir ${BBPATH} ./metadata
Just to note that in this submission script we copy the executable on the NVMe path (
Then, you will have something like that:
Duration: 23.0020
Then, NVMe, is 1.65 times faster than GPFS for a single node. This is an interesting example to illustrate that NVMe can benefit you even in small scale, depending on your application.