First check the development of my newest LLM-related project: https://github.com/nenad1002/KajkavskiGPT
Thank you!
This repo is an on-going implementation of a research in the area of sentiment analysis of Croatian language in Python and Tensorflow with Keras. As a part of this project the sentiment analysis of the comments found on Booking.com (and similar sites) has been processed to predict whether the comments express a positive or negative review of an accomondation place.
In the research project, sentiment analysis is framed as supervised classification problem where the primary choice of the modeling strategy includes recurrent neural networks with LSTM cells.
Since Croatian is morphologically very complex language (one word can take many different forms), stemming is crucial to the success of the classification algorithm, and the embedding words layer has been applied after the input layer to gain a better understanding of the context.
With having about 1000 samples (balanced set), a model that contains 2 LSTM layers and one regular densely-connected NN layer achieved optimal results while trained with the ADAM optimizer and recurrent dropout as a regularization technique. Running k-fold validation yielded an accuracy of 89% with precision and recall being just above 0.85. Other parameters can be found in the code.
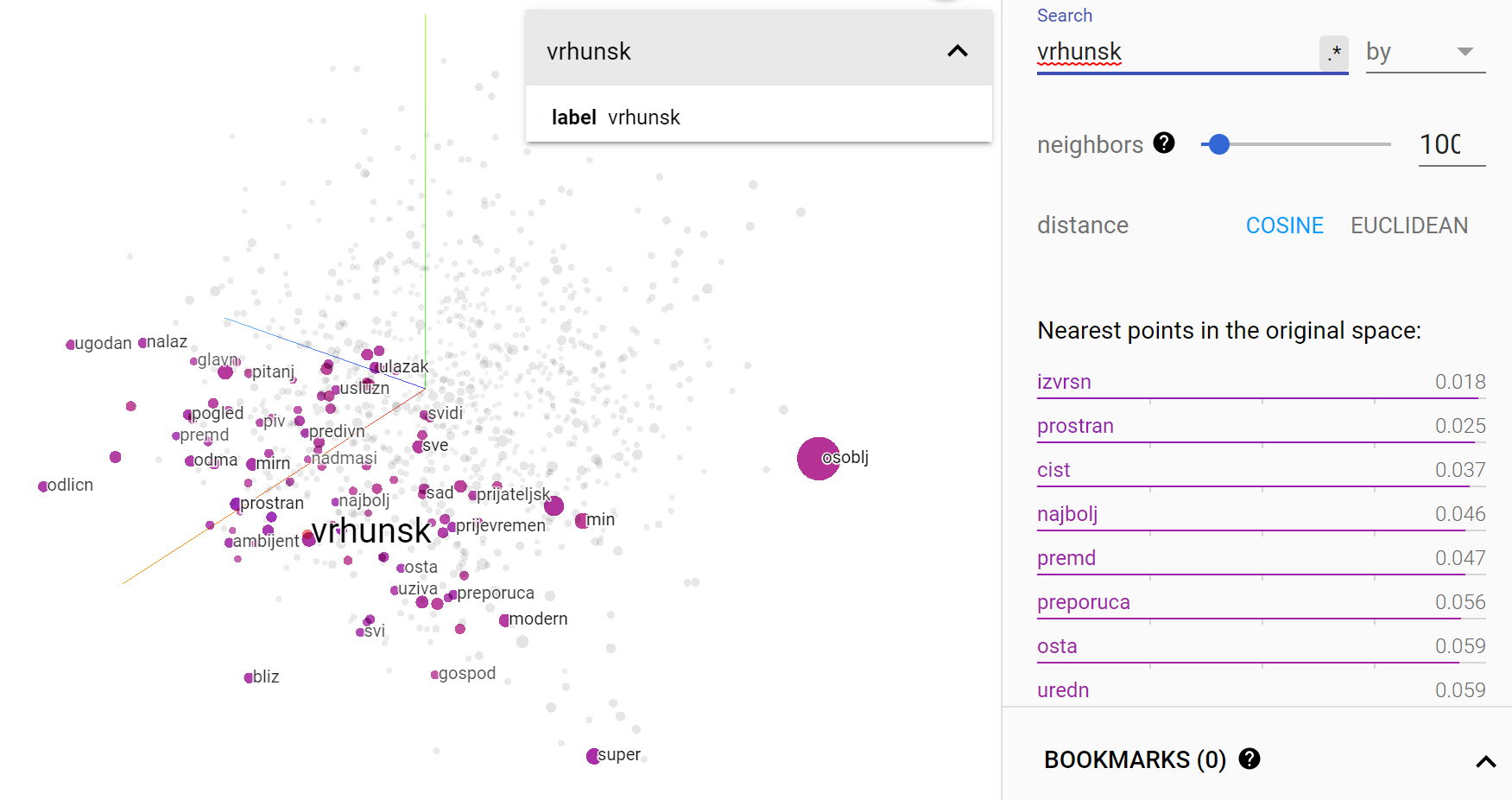
The word embeddings results are also astonishing. As an example you can see how the stemmed word vrhunsk (top, top notch) is very closely related semantically to the words izvrsn (great), cist (clean) and najbolj (the best).
Future work will focus on more research with respect to applications of different kinds of RNN cells, as well as looking into alternatives regarding regularization and representation of the input. The paper will also be published with the new findings.