{kind=link}
The goal of this project was to measure open source software contribution activity at a national, regional, and local level using data from GitHub and adjacent platforms. This data is used to better understand how open source interacts with the rest of the economy, for instance as a complement or substitute for proprietary work.
For output data see: https://github.com/johanneswachs/OSS_Geography_Data.
For an analysis of this data, see:
J. Wachs, M. Nitecki, W. Schueller, A. Polleres. "The Geography of Open Source Software: Evidence from GitHub." Technological Forecasting and Social Change. (2022) https://www.sciencedirect.com/science/article/pii/S0040162522000105
We thank the City of Vienna for funding support.
The data collection scripts are written in Python.
The APIs of the services Github, Twitter, and Bing Maps are used.
The codes were implemented in Python 3 and tested on a Linux machine. The required dependencies for the scripts are: tweepy, urllib, github, nuts_finder and pandas.
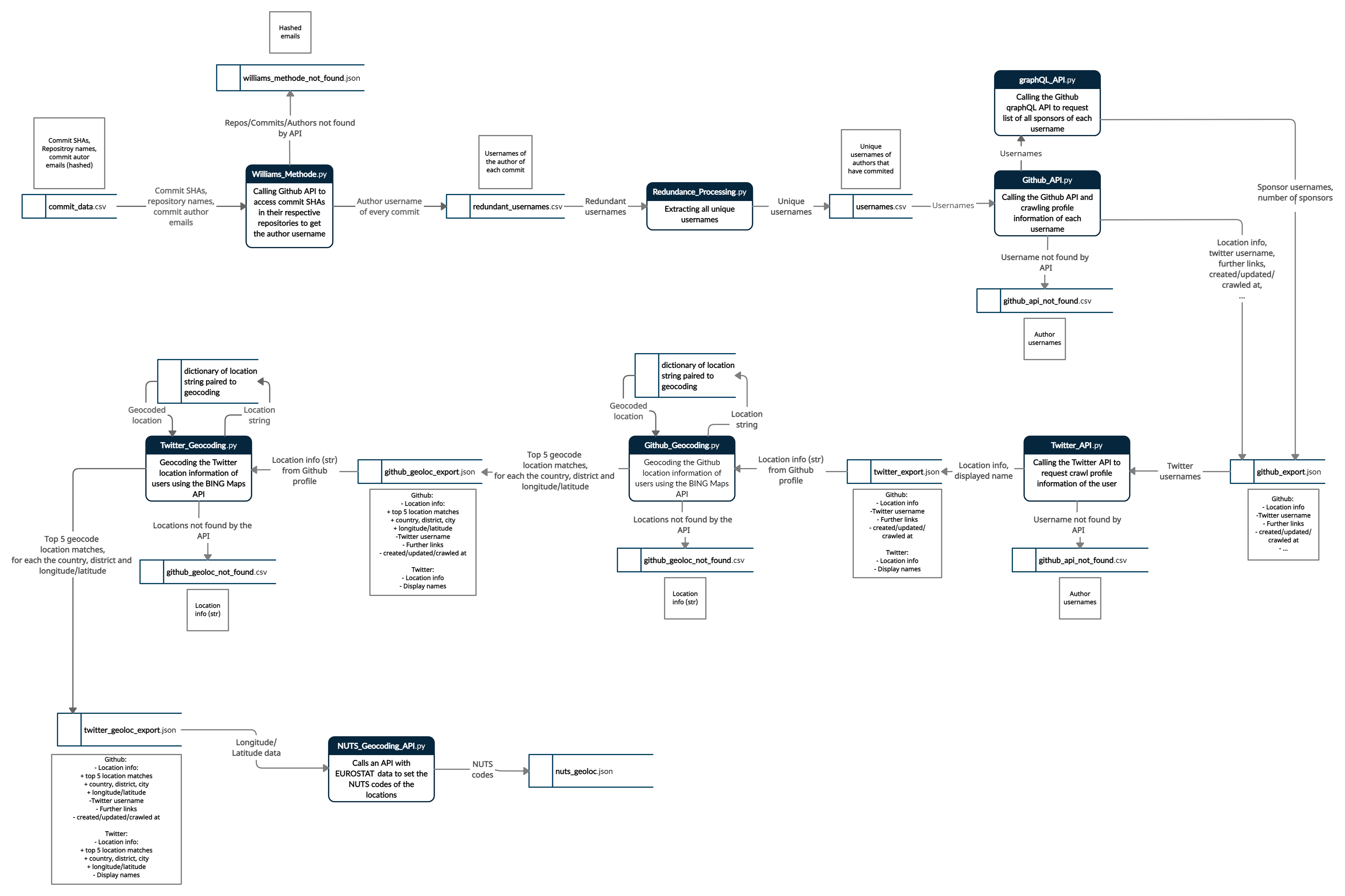
The codes can be used to collect all user-provided information from Github and Twitter, including usernames, location information, emails, Twitter usernames, other associated accounts/websites, workplaces, bios, sponsor information, etc. Users can also be gelocated based on their location information from said services or by analysis of their email suffixes against a list of country and university domains. Depending on the available data, the user can be located on a national or subnational level.
- Username Fetching
Depending on if the Github usernames of contributors are already available and known, this step can be skipped:
The data collection works as a data flow passing multiple scripts, with each script enriching the available data. In the first step, the usernames of Github contributors are extracted from the provided commit information. TheWilliams_Method.pyscript takes a CSV file containing commit SHAs of relevant users and calls it via the Github API. The author of that commit is then traced and his username exported into a CSV file. Commits that could not be traced to the author or no longer exist are exported into a separate CSV. To check for redundancies, theRedundance_Processing.pycode makes sure each username is unique. - Github Data Collection
The CSV file with unique usernames is passed on to theGithub_API.pyscript, which calls the Github API and gathers the data of the user. Additionally, thegraphQL_APIscript is called, which additionally collects sponsor information about each user via the Github GraphQL API. The resulting data is exported as a JSON file. Usernames that could not be found or no longer exist are exported into a separate CSV file. - Twitter Data Collection
TheTwitter_API.pytakes the JSON file with all the user information and calls the Twitter API to collect data about only those users, that had a Twitter username in their Github profile. The new data with Github as well as Twitter information is exported as a JSON file.
Many location strings provided by contributors are too ambiguous. Those strings are saved in a seperate CSV file. - Geocoding
In this step, theGithub_Geocoding.pyandTwitter_Geocoding.pyscripts forward the corresponding gathered location string provided by users to the Bing Maps API in order to geolocate them. The Bing Maps API query results in three most likely location matches, each containing information about the match probability. Each match contains the country, state and city information as a string, as well as the latitude and longitude coordinates. - NUTS Geocoding The JSON file with the geocoded contributors is then read by the
NUTS_Geocoding.pycode. This code sets the appropriate NUTS codes based on the latitude and longitude coordinates for users located in Europe and exports the enriched data as a JSON file. - Email Suffix Geocoding
To geocode as many contributors as possible, besides looking at the user-supplied location string, the infrastructure is also programmed to try and get country level location information based on email suffixes of users.Email_Suffix_Geocoding.pyis the script, that compares the email suffixes against a list of many university suffixes and a list of country domains to provide additional location information, exporting it as a JSON file.
The Data Flow Diagram below summarises the geocoding infrastructure: