{kind=link}
ModulOM (for MODULar Output Mathematics) is proposed in the the following paper: ModulOM: Disseminating Deep Learning Research with Modular Output Mathematics. This repository, derived from the public Panoptic-Deeplab reimplementation by its original author, is meant to accompany our paper to illustrate ModulOM applied on some use case. For more information on Panoptic-Deeplab, please have a look at the Panoptic-Deeplab paper or at the second part of this README. This code is be released publicly under the Apache License 2.0. Here below is a list of the main modifications involved to the code base.
ModulOM is a first step towards Output Mathematics (OM) that are manageable to build atomic increments upon, to probe, and to transplant from one code base to another. The code implementing losses, the decoding process and target maps (what we consider as the simplest case of OM) is usually intricated because of inter-dependencies between those components, making it is difficult to impact them in a consistent fashion. We strongly believe ModulOM constitutes a way to make OM another shareable, plug-and-play component of Deep Learning experiments, just like optimizers, neural architectures, data-augmentation pipelines, ...
We denote Output Mathematics the set of math formulas that surround the neural network to make it solve a task. We consider at least the following to be part of it:
- the decoding of the network outputs to be turned into meaningful predictions
- the loss, as it shapes the feedback giving meaning to the network's outputs, and has to be consistent with the output decoding
- the ground-truth generation from the annotations, as it has to be consistent with the losses
We don't know yet if its responsibilities stop there. In case multiple neural networks are involved (e.g. GANs), it could encompass the routing of data between those networks as well. In case of transformers, it could acquire the responsibilities of preprocessing the signal and feeding it to the network.
It should probably encompass everything you consider as being part of the "mathematical system" of your method. We also propose to document code and the mathematical system jointly, as we did for instance with the illustration that follows.
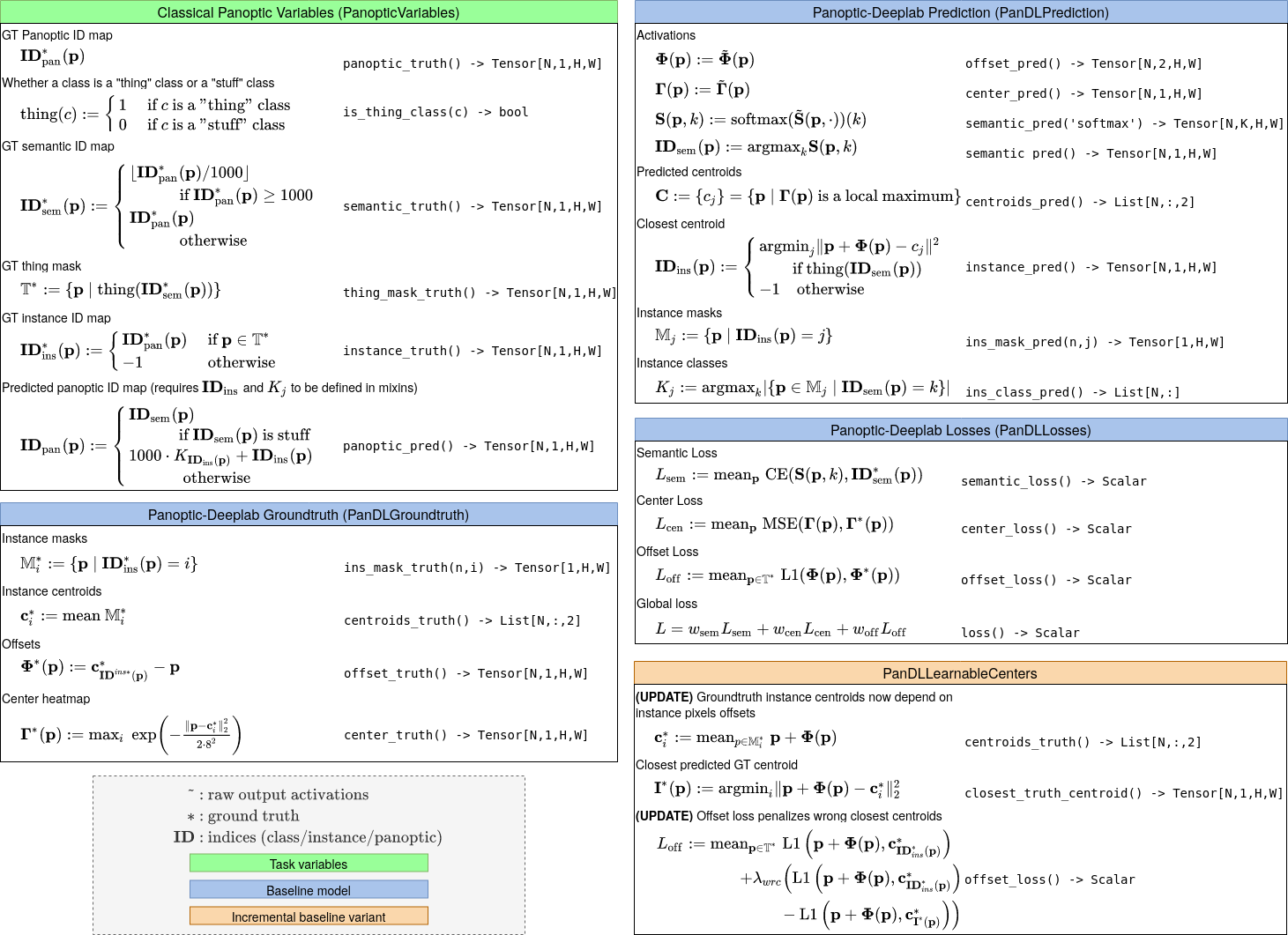
Modular output mathematics can be built from many from smaller building blocks themselves which can have single responsibilities. So it is probably specific to every implementation. We tried for this code base to provide a nice example of what a single responsibility modules can look like when describing such mathematical systems. (see the blocks in the illustration above)
Does wrapping more responsibilities inside ModulOM render existing components that address them useless?
Definitely not. Just like we wouldn't include the code of the neural network inside the OM code, but feed it inputs and collect its outputs. Existing modules for losses, decoding, data-augmentation, etc are still useful to interchange blocks within the OM which have a fixed interface.
If your criterion is a L1Loss or a L2Loss, you can call it from inside a, let's say, OutputMath.loss() method. Yet, other people can still deviate from calling a L1Loss-like module if more complex data flow is needed by overriding OutputMath.loss().
Features provided by object-oriented programming happened to fit nicely our practical requirements, and helped us to define our expectations regarding the scope of variables, how overriding variables should work, the lifespan of the cache, ... Yet, it is to be expected that code generation can provide, if not even more convenience, the same by simulating all those mechanisms. We don't think we could have had quickly such a coherent solution if starting with code generation directly, because of its inherent freedom and all the scenarios we would have had to think about. Instead, many of our design choices were guided by features of OOP and multiple inheritance. We believe to have created something convenient, but it could now be replicated/improved using other techniques. We think for instance about languages that don't have those features.
In this very particular repository of PanopticDeeplab + ModulOM with OOP features in Python, there are also a numbers of arbitrary choices that are worth mentioning:
-
About the cache policy: every method call is cached by default, unless the method name starts with a
_, or keyword-only arguments are passed to the call, or the method has been decorated with@no_cache(expression_string)(andexpression_stringis satisfied at call,'True'by default)This helps the practitioner strike the right balance between terms of interest he wants to see cached, and methods that are there for doing computations. (but that can be interesting to override as well)
-
When instantiating an object from an OM class for the first time, a subclass of the OM class is created that adds the caching mechanism to the required methods. So an object instantiate from the
PanDLBaseconstructor will in fact be aPanDLBaseWithCacheobject. -
The cache doesn't create any reference cycle, this would be deadly.
As a side note, to implement particular OMs, we usually prefer to cache a full [N,C,H,W] tensor than N [C,H,W] tensors created by a function having a n parameter. It is a bit less ambiguous (should I use something(n) or something()[n]?) and does not risk retaining double the memory (stacking N something(n) that are each cached could use double the memory).
How compliant is ModulOM based on multiple inheritance with Pytorch or Tensorflow features? (and possibly other frameworks)
We have understood that most code analyzers were not ready yet to follow what happens behind an OutputMath class. So we currently expect features that require analysis of the code to be in trouble (e.g. TorchScript, Tensorflow in a mode that it infers the graph from analyzing the code). However, for plain dynamic-graph Pytorch, or static-graph Tensorflow where the graph is instantiated by running code with placeholders, ModulOM should is definitely adequate.
We believe this incompatibility is only a question of time, because the support for such analysis has never been requested before. The code of an OutputMath class contains all the information required to create a graph from it. (as stated in the paper, no external code has any reason to be anymore in the routing of data inside the OM, so this is close to the ideal case for such analyzers). We truly hope that our request will encourage efforts to cope with those limitations, or to propose equally powerful constructs integrated to those frameworks directly. We would of course like to help making it happen.
Listed below are the main modifications brought to the Panoptic-Deeplab codebase:
- An "OM" section has been added to the configuration, and the
segmentation.model.output_mathmodule has been created, containing: - When
OM.NAMEis defined, the model is wrapped into a MetaArchitectureWrapper that returns an OM object instead of a dictionary. (but OM exposes the same elements for compatibility)OM.NAMEcan currently be set to'panoptic-deeplab'to use thePanDLBaseOM class.
- If
OM.NAMEandOM.MIXINSare defined, the definitive OM class will inherit classes specified withinOM.MIXINS- currently,
learnable-centers,oracle[-centers][-offsets][-semantics]mixins are available.
- currently,
- PanopticTargetGenerator provides the panoptic map to the OutputMathematics, as this is a more convenient way to infer instance masks.
DATASET.PAN_ONLYcan be set toTrueto avoid computation of ground-truth maps in the dataloader workers.
@inproceedings{istasse2021modulom,
title={Modul{OM}: Disseminating Deep Learning Research with Modular Output Mathematics},
author={Maxime Istasse and Kim Mens and Christophe De Vleeschouwer},
booktitle={Beyond static papers: Rethinking how we share scientific understanding in ML - ICLR 2021 workshop},
year={2021},
url={https://openreview.net/forum?id=264iXDLnD59}
}- File an issue here
- maxime (DOT) istasse (AT) (UCLouvain in lower case) (DOT) be
Panoptic-DeepLab is a state-of-the-art bottom-up method for panoptic segmentation, where the goal is to assign semantic labels (e.g., person, dog, cat and so on) to every pixel in the input image as well as instance labels (e.g. an id of 1, 2, 3, etc) to pixels belonging to thing classes.

This is the PyTorch re-implementation of our CVPR2020 paper based on Detectron2: Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation. Segmentation models with DeepLabV3 and DeepLabV3+ are also supported in this repo now!
- [2021/01/25] Found a bug in old config files for COCO experiments (need to change
MAX_SIZE_TRAINfrom 640 to 960 for COCO). Now we have also reproduced COCO results (35.5 PQ)! - [2020/12/17] Support COCO dataset!
- [2020/12/11] Support DepthwiseSeparableConv2d in the Detectron2 version of Panoptic-DeepLab. Now the Panoptic-DeepLab in Detectron2 is exactly the same as the implementation in our paper, except the post-processing has not been optimized.
- [2020/09/24] I have implemented both DeepLab and Panoptic-DeepLab in the official Detectron2, the implementation in the repo will be deprecated and I will mainly maintain the Detectron2 version. However, this repo still support different backbones for the Detectron2 Panoptic-DeepLab.
- [2020/07/21] Check this Google AI Blog for Panoptic-DeepLab.
- [2020/07/01] More Cityscapes pre-trained backbones in model zoo (MobileNet and Xception are supported).
- [2020/06/30] Panoptic-DeepLab now supports HRNet, using HRNet-w48 backbone achieves 63.4% PQ on Cityscapes. Thanks to @PkuRainBow.
- The implementation in this repo will be depracated, please refer to my Detectron2 implementation which gives slightly better results.
- This is a re-implementation of Panoptic-DeepLab, it is not guaranteed to reproduce all numbers in the paper, please refer to the original numbers from Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation when making comparison.
- When comparing speed with Panoptic-DeepLab, please refer to the speed in Table 9 of the original paper.
- We release a detailed technical report with implementation details and supplementary analysis on Panoptic-DeepLab. In particular, we find center prediction is almost perfect and the bottleneck of bottom-up method still lies in semantic segmentation
- It is powered by the PyTorch deep learning framework.
- Can be trained even on 4 1080TI GPUs (no need for 32 TPUs!).
We suggest using the Detectron2 implementation. You can either use it directly from the Detectron2 projects or use it from this repo from tools_d2/README.md.
The differences are, official Detectron2 implementation only supports ResNet or ResNeXt as the backbone. This repo gives you an example of how to use your a custom backbone within Detectron2.
Note:
- Please check the usage of this code in tools_d2/README.md.
- If you are still interested in the old code, please check tools/README.md.
| Method | Backbone | Output resolution |
PQ | SQ | RQ | mIoU | AP | download |
|---|---|---|---|---|---|---|---|---|
| Panoptic-DeepLab (DSConv) | R52-DC5 | 1024×2048 | 60.3 | 81.0 | 73.2 | 78.7 | 32.1 | model |
| Panoptic-DeepLab (DSConv) | X65-DC5 | 1024×2048 | 61.4 | 81.4 | 74.3 | 79.8 | 32.6 | model |
| Panoptic-DeepLab (DSConv) | HRNet-48 | 1024×2048 | 63.4 | 81.9 | 76.4 | 80.6 | 36.2 | model |
Note:
- This implementation uses DepthwiseSeparableConv2d (DSConv) in ASPP and decoder, which is same as the original paper.
- This implementation does not include optimized post-processing code needed for deployment. Post-processing the network outputs now takes more time than the network itself.
| Method | Backbone | Output resolution |
PQ | SQ | RQ | Box AP | Mask AP | download |
|---|---|---|---|---|---|---|---|---|
| Panoptic-DeepLab (DSConv) | R52-DC5 | 640×640 | 35.5 | 77.3 | 44.7 | 18.6 | 19.7 | model |
| Panoptic-DeepLab (DSConv) | X65-DC5 | 640×640 | - | - | - | - | - | model |
| Panoptic-DeepLab (DSConv) | HRNet-48 | 640×640 | - | - | - | - | - | model |
Note:
- This implementation uses DepthwiseSeparableConv2d (DSConv) in ASPP and decoder, which is same as the original paper.
- This implementation does not include optimized post-processing code needed for deployment. Post-processing the network outputs now takes more time than the network itself.
If you find this code helpful in your research or wish to refer to the baseline results, please use the following BibTeX entry.
@inproceedings{cheng2020panoptic,
title={Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation},
author={Cheng, Bowen and Collins, Maxwell D and Zhu, Yukun and Liu, Ting and Huang, Thomas S and Adam, Hartwig and Chen, Liang-Chieh},
booktitle={CVPR},
year={2020}
}
@inproceedings{cheng2019panoptic,
title={Panoptic-DeepLab},
author={Cheng, Bowen and Collins, Maxwell D and Zhu, Yukun and Liu, Ting and Huang, Thomas S and Adam, Hartwig and Chen, Liang-Chieh},
booktitle={ICCV COCO + Mapillary Joint Recognition Challenge Workshop},
year={2019}
}If you use the Xception backbone, please consider citing
@inproceedings{deeplabv3plus2018,
title={Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation},
author={Liang-Chieh Chen and Yukun Zhu and George Papandreou and Florian Schroff and Hartwig Adam},
booktitle={ECCV},
year={2018}
}
@inproceedings{qi2017deformable,
title={Deformable convolutional networks--coco detection and segmentation challenge 2017 entry},
author={Qi, Haozhi and Zhang, Zheng and Xiao, Bin and Hu, Han and Cheng, Bowen and Wei, Yichen and Dai, Jifeng},
booktitle={ICCV COCO Challenge Workshop},
year={2017}
}If you use the HRNet backbone, please consider citing
@article{WangSCJDZLMTWLX19,
title={Deep High-Resolution Representation Learning for Visual Recognition},
author={Jingdong Wang and Ke Sun and Tianheng Cheng and
Borui Jiang and Chaorui Deng and Yang Zhao and Dong Liu and Yadong Mu and
Mingkui Tan and Xinggang Wang and Wenyu Liu and Bin Xiao},
journal={TPAMI},
year={2019}
}We have used utility functions from other wonderful open-source projects, we would espeicially thank the authors of:
Bowen Cheng (bcheng9 AT illinois DOT edu)