深入剖析 WebKit
- HTML DOM 树的插入状态规范 https://html.spec.whatwg.org/multipage/parsing.html#the-insertion-mode
- HTML Tokenize 规范 https://html.spec.whatwg.org/multipage/parsing.html#tokenization https://dev.w3.org/html5/spec-preview/tokenization.html
- HTMLElement 堆栈规范 https://html.spec.whatwg.org/multipage/parsing.html#the-stack-of-open-elements
1990年 Berners-Lee 发明了 WorldWideWeb 浏览器,后改名 Nexus,在1991年公布了源码。
1993年 Marc Andreessen 的团队开发了 Mosaic,1994年推出我们熟悉的 Netscape Navigator 网景浏览器,在最火爆的时候曾占是绝大多数人的选择。同时他还成立了网景公司。
1995年微软推出了 Internet Explorer 浏览器,简称 IE,通过免费绑定进 Windows 95 系统最终替代了 Netscape,赢得了浏览器大战。
1998年网景公司成立了 Mozilla 基金会组织,同时开源浏览器代码,2004年推出有多标签和支持扩展的 Firefox 火狐浏览器开始慢慢的占领市场份额。
2003年苹果发布了 Safari 浏览器,2005年放出了核心源码 WebKit。
2008年 Google 以苹果的 WebKit 为内核,建立了新的项目 Chromium,在此基础上开发了自己浏览器 Chrome。
2012年 WHATWG 和 W3C 推出 HTML5 技术规范。HTML5 包含了10大类别,offline 离线,storage 存储,connectivity 连接,file access 文件访问,semantics 语义,audio / video 音频视频,3D/graphics 3D和图形,presentation 展示,performance 性能和 Nuts and bolts 其它。
完整的浏览器发展史可以在这里看:https://en.wikipedia.org/wiki/Timeline_of_web_browsers
可以看到浏览器技术的发展到了后期基本都是基于 WebKit 开发的,那么我们就来了解下 WebKit 吧。先看看它的全貌。
先看看它的大模块:
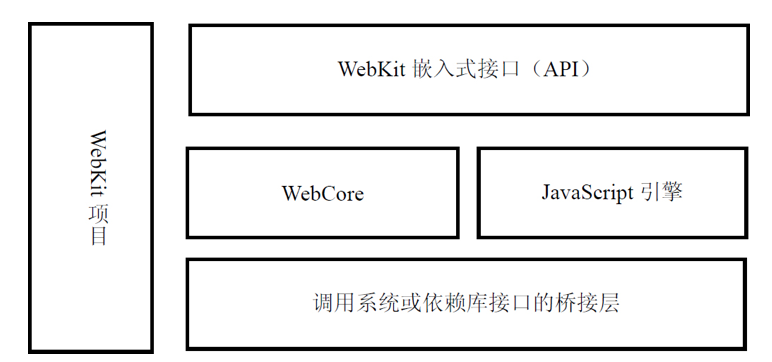
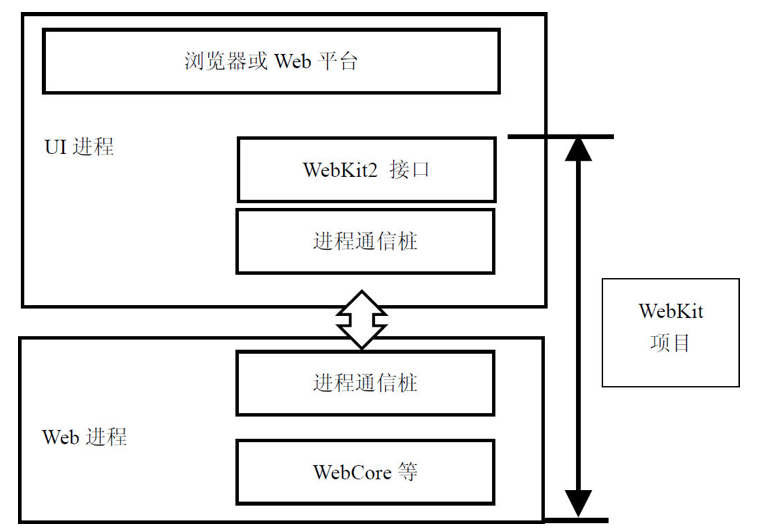
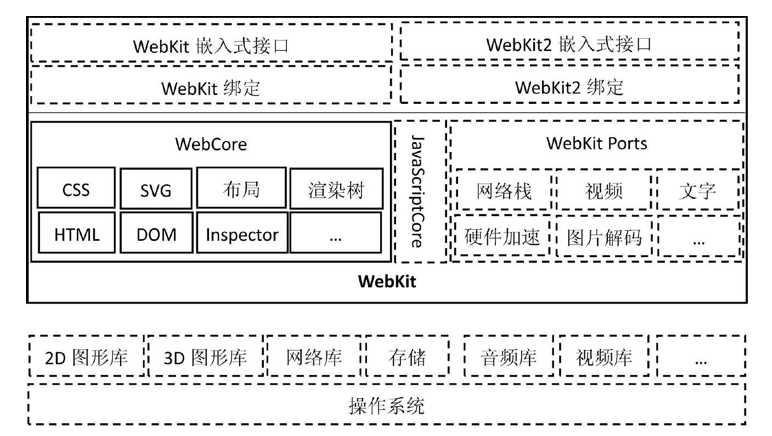
下面是 WebKit 最核心最复杂的排版引擎 WebCore 的结构图:
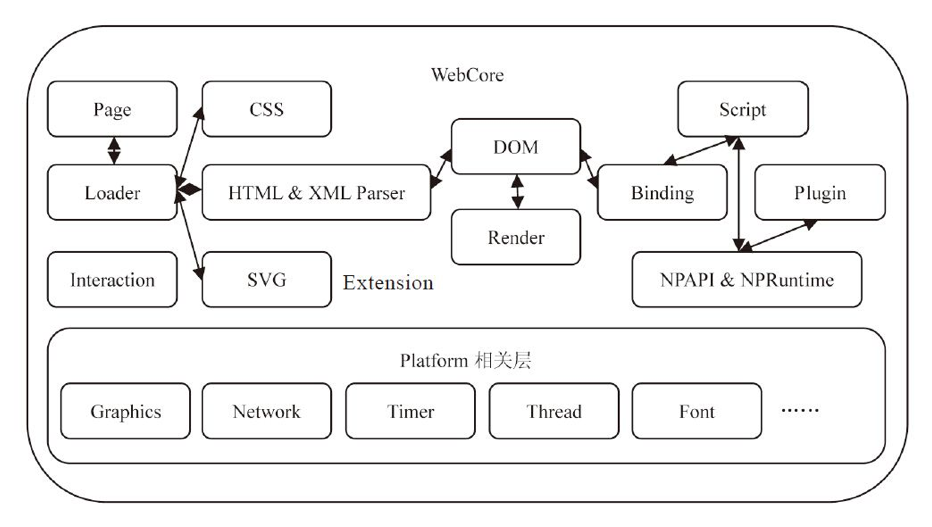
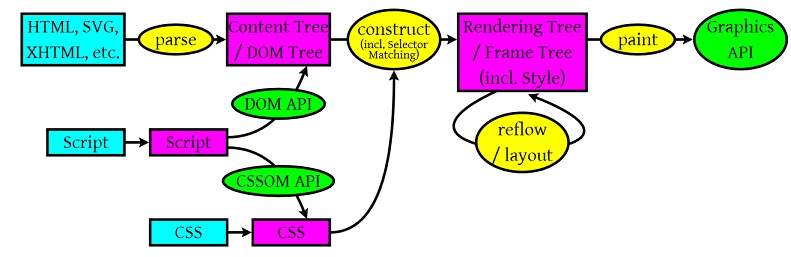
解析后会产生 DOM Tree,解析 CSS 会产生 CSS Rule Tree,Javascript 会通过 DOM API 和 CSS Object Model(CSSOM) API 来操作 DOM Tree 和 CSS Rule Tree。
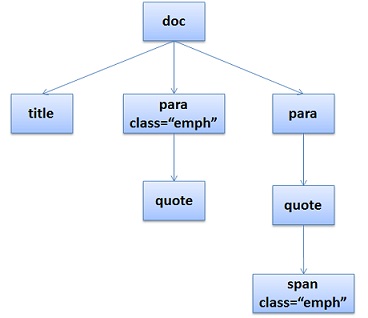
DOM Tree
CSS Rule Tree
通过上面的两个数构造的 Style Context Tree
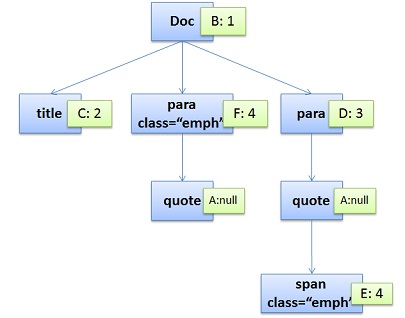
浏览器引擎最后会 通过 DOM Tree 和 CSS Rule Tree 来构造 Rendering Tree。这个过程如下:
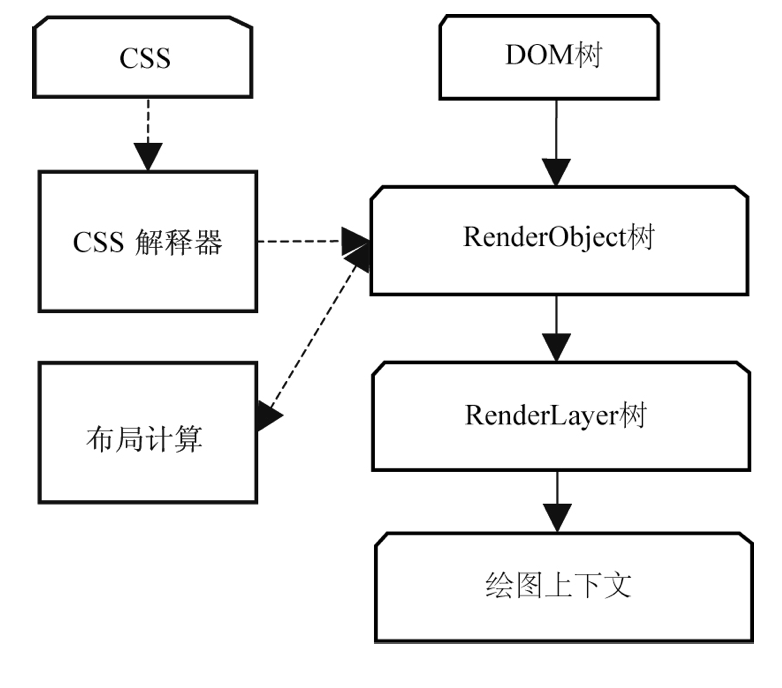
计算每个 Node 的位置,执行 Layout 过程
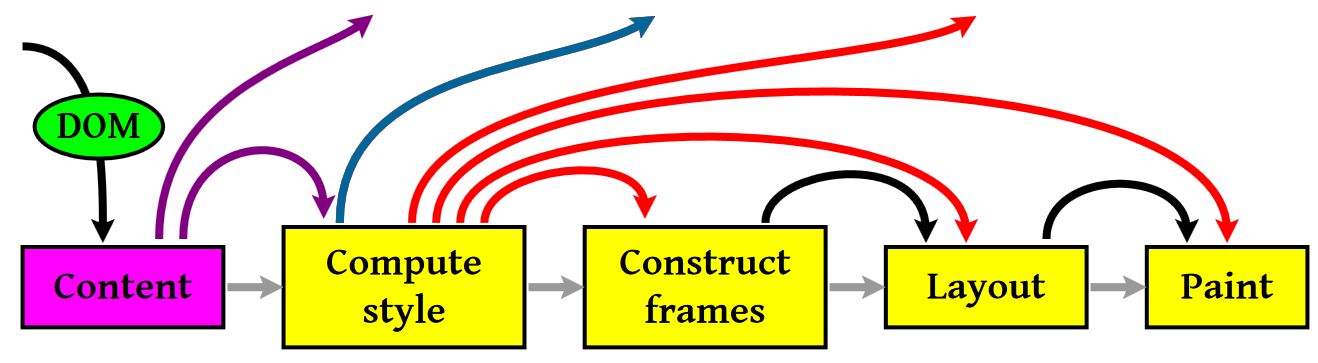
Compute style 是计算 CSS 样式,layout 是定位坐标和大小,各种 position,overflow,z-index 等。这些箭头表示动态修改了 DOM 属性和 CSS 属性会导致 Layout 执行。
- JavaScriptCore:默认 JavaScript 引擎,Google 已经使用了 V8 作为其 Chromium 的 JS 引擎。
- WebCore:浏览器渲染引擎,包含了各个核心模块。
- WebCore/css:CSS 解释器,CSS 规则等。
- WebCore/dom:各种 DOM 元素和 DOM Tree 结构相关的类。
- WebCore/html:HTML 解释器和各种 HTML 元素等相关内容。
- WebCore/rendering:Render Object 相关,还有页面渲染的样式和布局等。
- WebCore/inspector:网页调试工具。
- WebCore/loader:主资源和派生资源的加载相关实现,还有派生资源的 Memory Cache 等。
- WebCore/page:页面相关的操作,页面结构和交互事件等。
- WebCore/platform:各个平台相关的代码,比如 iOS,Mac 等
- WebCore/storage:存储相关,比如 WebStorage,Index DB 等接口的实现。
- WebCore/workers:Worker 线程封装,提供 JS 多线程执行环境。
- WebCore/xml:XML 相关比如 XML Parser,XPath,XSLT 等。
- WebCore/accessibility:图形控件访问接口。
- WebCore/bindings:DOM 元素和 JS 绑定的接口。
- WebCore/bridge:C,JavaScript 和 Objective-C 的桥接。
- WebCore/editing:页面编辑相关,比如 DOM 修改,拼写检查等。
- WebCore/history:Page Cache 实现前进后退浏览记录等。
- WebCore/mathml:数学表达式在网页中的规范代码实现。
- WebCore/plugins:NPPlugin 的支持接口
- WebCore/svg:矢量图形的支持。
- WebKit:平台相关的接口,每个目录都是不同的平台接口实现。
- WTF:基础类库,类似 C++ 的 STL 库,有比如字符串操作,智能指针,线程等。
- DumpRenderTree:用于生成 RenderTree
- TestWebKitAPI:测试 WebKit 的 API 的测试代码
- 内存管理:使用的引用计数,在 RefCounted 模板类里有 ref() 加和 unref() 减来进行控制,很多类都是继承了这个模板类。后期加入了 RefPtr 和 PassRefPtr 智能指针模板类,采用的是重载赋值操作符的方式能够自动完成计数加减,这样基本没有内存泄漏的可能。
- 代码自动生成:C++ 对象到 JS 对象的 Binding 实现使用的是代码自动生成,用 Perl 脚本 根据 IDL 接口描述文件完成代码自动生成。还有部分 CSS 和 HTML 解析也用到了,这样 CSS 属性值和 HTML 标签属性的添加也够节省大量时间,需要修改 .in 配置文件即可。
- 代码编写风格:可以在官网查看到:https://webkit.org/code-style-guidelines/ 想给 WebKit 做贡献的同学们可以好好看看了。
下面可以看看在 WebKit 里使用了哪些设计模式,是如何使用的。
- 单例:WebKit 里的 Loader 管理 CacheResource 就是单例模式。
- 工厂模式:可以在 WebKit 源码里搜索结尾是 Factory 的代码,它们一般都是用的工厂模式。
- 观察者模式:名称结尾是 Client 都是观察者模式,比如 FrameLoaderClient 可以看成是观察者类,被观察者 FrameLoader 会向 Client 观察者类通知自身状态的变化。
- 组合模式:用于树状结构对象,比如 DOM Tree,Render Tree,组成它们的类 ContainerNode 和 RenderObject 可以看成组合模式。
- 命令模式:DOM 模块的 Event 类和 Editing 模块的 Command 类都是命令模式。
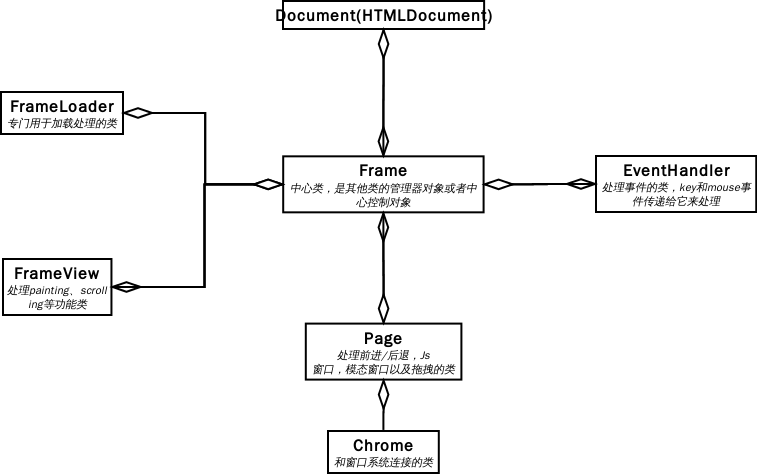
- Frame:中心类,通过它找其它类
- FrameLoader:加载资源用的
- Document:具体实现是 HTMLDocument
- Page:窗口的操作
- EventHandler:输入事件的处理,比如键盘,鼠标,触屏等
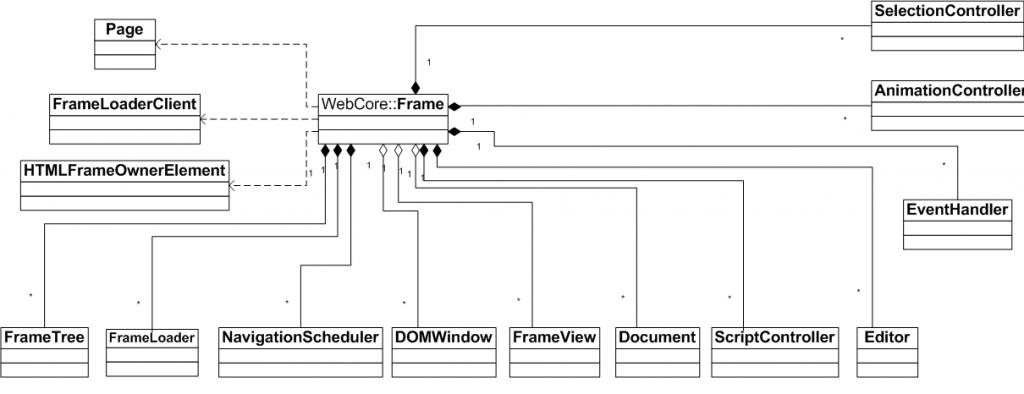
- FrameTree:管理父 Frame 和子 Frame 的关系,比如 main frame 里的 iframe。
- FrameLoader:frame 的加载
- NavigationScheduler:主要用来管理页面跳转,比如重定向,meta refresh 等。
- DOMWindow:管理 DOM 相关的事件,属性和消息。
- FrameView:Frame 的排版。
- Document:用来管理 DOM 里的 node,每个 tag 都会有对应的 DOM node 关联。
- ScriptController:管理 js 脚本。
- Editor:管理页面比如 copy,paste和输入等编辑操作。
- SelectionController:管理 Frame 里的选择操作。
- AnimationControlle:动画控制。
- EventHandler:处理事件比如鼠标,按键,滚动和 resize 等事件。
Ref<Frame> Frame::create(Page* page, HTMLFrameOwnerElement* ownerElement, FrameLoaderClient* client)
{
ASSERT(page);
ASSERT(client);
return adoptRef(*new Frame(*page, ownerElement, *client));
}Frame::create 里会调用到 Frame 的构造函数,创建 Frame 对象。 初始调用顺序
webPage::setView
webPage::setViewportSize
webPage::mainFrame
webPagePrivate::createMainFrame
webFrameData::webFrameData
Frame::create解析中发现 iframe 时的调用顺序
FrameLoader::finishedLoading
HTMLDocumentParser::append
HTMLTreeBuilder::processToken
HTMLElementBase::openURL
SubFrameLoader::requestFrame
FrameLoaderClient::creatFrame
webFrameData::webFrameData
Frame::createvoid Frame::createView(const IntSize& viewportSize, const Color& backgroundColor, bool transparent,
const IntSize& fixedLayoutSize, const IntRect& fixedVisibleContentRect,
bool useFixedLayout, ScrollbarMode horizontalScrollbarMode, bool horizontalLock,
ScrollbarMode verticalScrollbarMode, bool verticalLock)会创建出用于排版的 FrameView 对象。需要一些和排版相关的信息,比如初始 viewport 的大小,背景色,滚动条模式等,完成创建调用 Frame::setView 设置为当前 FrameView。 调用顺序
FrameLoader::commitProvisionalLoad
FrameLoader::transitionToCommitted
FrameLoaderClient::transitionToCommittedForNewPage
Frame::createViewvoid Frame::setDocument(RefPtr<Document>&& newDocument)用来关联 Frame 和 Document 对象 Frame 初始化调用顺序
WebFrame::webFrame
webFramePrivate::init
Frame::init
FrameLoader::init
DocumentWriter::begin
Frame::setDocumentjs 脚本更改数据时的调用顺序
DocumentLoader::receivedData
DocumentLoader::commitLoad
FrameLoaderClient::committedLoad
DocumentLoader::commitData
DocumentWriter::setEncoding
DocumentWriter::willSetEncoding
FrameLoader::receivedFirstData
DocumentWriter::begin
FrameLoader::clear
Frame::setDocument全称是 Web Template Library,是 WebKit 的基础库,实现了智能指针,字符串和 Container,提供跨平台原子操作,时间和线程的封装,能够高效的对内存进行管理。WebCore 里都是 WTF 的代码而没有 STL。
对原生指针的封装,这样 C++ 可以自动化的实现资源管理和指针衍生操作比如拷贝,引用计数,autoLocker 和 Lazy evaluation 等。
智能指针主要就是实现动态分配对象的内存并且能自动回收,原理就是智能指针的对象会作为栈上分配的自动变量在退出作用域时被自动析构。
智能指针的实现方式:
template <typename T>
class SmartPtr {
public:
typedef T ValueType;
typedef ValueType *PtrType;
//构造析构函数
SmartPtr() :m_ptr(NULL) {}
SmartPtr(PtrType ptr) :m_ptr(ptr) {}
~SmartPtr() {
if(m_ptr) delete m_ptr;
}
//拷贝构造函数
SmartPtr(const SmartPtr<T>& o); //堆上分配的对象
template<typename U> SmartPtr(const SmartPtr<U>& o);
//拷贝赋值运算符
template<typename U> SmartPtr& operator = (const SmartPtr<U>& o);
//指针运算,是为了让智能指针在行为上更类似原生指针
ValueType& operator*() const {
return *m_ptr;
}
PtrType operator->() const {
return m_ptr;
}
//逻辑运算符重载
//对指针是否为空的简洁判断 if(!ptr),如果定义了 operator!() 智能指针就可以用 if(!SmartPtr)
bool operator!() const {
return !m_ptr;
}
//转成 raw ptr
operator PtrType() {
return m_ptr;
}
private:
PtrType m_ptr;
}
//创建智能指针对象格式
SmartPtr(new ValueType());RefPtr 需要操作对象来引用计数,包含 ref() 和 deref() 方法的类对象才可以由 RefPtr 引用。为了不让 RefPtr 引用的类都用手工去添加 ref() 和 deref() WTF 提供了 RefCounted 类模板,在 WTF/Source/wtf/RefCounted.h 里。类模板的定义如下:
class RefCountedBase {
public:
void ref() const
{
#if CHECK_REF_COUNTED_LIFECYCLE
ASSERT_WITH_SECURITY_IMPLICATION(!m_deletionHasBegun);
ASSERT(!m_adoptionIsRequired);
#endif
++m_refCount;
}
bool hasOneRef() const
{
#if CHECK_REF_COUNTED_LIFECYCLE
ASSERT(!m_deletionHasBegun);
#endif
return m_refCount == 1;
}
unsigned refCount() const
{
return m_refCount;
}
void relaxAdoptionRequirement()
{
#if CHECK_REF_COUNTED_LIFECYCLE
ASSERT_WITH_SECURITY_IMPLICATION(!m_deletionHasBegun);
ASSERT(m_adoptionIsRequired);
m_adoptionIsRequired = false;
#endif
}
protected:
RefCountedBase()
: m_refCount(1)
#if CHECK_REF_COUNTED_LIFECYCLE
, m_deletionHasBegun(false)
, m_adoptionIsRequired(true)
#endif
{
}
~RefCountedBase()
{
#if CHECK_REF_COUNTED_LIFECYCLE
ASSERT(m_deletionHasBegun);
ASSERT(!m_adoptionIsRequired);
#endif
}
// Returns whether the pointer should be freed or not.
bool derefBase() const
{
#if CHECK_REF_COUNTED_LIFECYCLE
ASSERT_WITH_SECURITY_IMPLICATION(!m_deletionHasBegun);
ASSERT(!m_adoptionIsRequired);
#endif
ASSERT(m_refCount);
unsigned tempRefCount = m_refCount - 1;
if (!tempRefCount) {
#if CHECK_REF_COUNTED_LIFECYCLE
m_deletionHasBegun = true;
#endif
return true;
}
m_refCount = tempRefCount;
return false;
}
#if CHECK_REF_COUNTED_LIFECYCLE
bool deletionHasBegun() const
{
return m_deletionHasBegun;
}
#endif
private:
#if CHECK_REF_COUNTED_LIFECYCLE
friend void adopted(RefCountedBase*);
#endif
mutable unsigned m_refCount;
#if CHECK_REF_COUNTED_LIFECYCLE
mutable bool m_deletionHasBegun;
mutable bool m_adoptionIsRequired;
#endif
};
template<typename T> class RefCounted : public RefCountedBase {
WTF_MAKE_NONCOPYABLE(RefCounted); WTF_MAKE_FAST_ALLOCATED;
public:
void deref() const
{
if (derefBase())
delete static_cast<const T*>(this);
}
protected:
RefCounted() { }
~RefCounted()
{
}
};上面可以看到 RefCounted 类定义有 RefCountedBase 类和 RefCounted 类,RefCounted 类会被大量继承,任何类如果想被 RefPtr 引用只需要继承 RefCounted即可。在 RefPtr.h 里可以看到 refIfNotNull 和 derefIfNotNull 定义了计数的增加和减少。
断言在 WTF 里是这样定义的
#define ASSERT(assertion) do { \
if (!(assertion)) { \
//打印用
WTFReportAssertionFailure(__FILE__, __LINE__, WTF_PRETTY_FUNCTION, #assertion); \
//重点
CRASH(); \
} \
} while (0)
#ifndef CRASH
#if defined(NDEBUG) && OS(DARWIN)
// Crash with a SIGTRAP i.e EXC_BREAKPOINT.
// We are not using __builtin_trap because it is only guaranteed to abort, but not necessarily
// trigger a SIGTRAP. Instead, we use inline asm to ensure that we trigger the SIGTRAP.
#define CRASH() do { \
//直接 inline 汇编代码
WTFBreakpointTrap(); \
__builtin_unreachable(); \
} while (0)
#else
#define CRASH() WTFCrash()
#endif
#endif // !defined(CRASH)
//根据不同 CPU 定义不同的 WTFBreakpointTrap() 汇编宏
#if CPU(X86_64) || CPU(X86)
#define WTFBreakpointTrap() __asm__ volatile ("int3")
#elif CPU(ARM_THUMB2)
#define WTFBreakpointTrap() __asm__ volatile ("bkpt #0")
#elif CPU(ARM64)
#define WTFBreakpointTrap() __asm__ volatile ("brk #0")
#else
#define WTFBreakpointTrap() WTFCrash() // Not implemented.
#endifWTF 提供的内存管理和 STL 类似,为容器和应用提供内存分配接口。先看 WTF_MAKE_FAST_ALLOCATED 这个宏
#define WTF_MAKE_FAST_ALLOCATED \
public: \
void* operator new(size_t, void* p) { return p; } \
void* operator new[](size_t, void* p) { return p; } \
\
void* operator new(size_t size) \
{ \
return ::WTF::fastMalloc(size); \
} \
\
void operator delete(void* p) \
{ \
::WTF::fastFree(p); \
} \
\
void* operator new[](size_t size) \
{ \
return ::WTF::fastMalloc(size); \
} \
\
void operator delete[](void* p) \
{ \
::WTF::fastFree(p); \
} \
void* operator new(size_t, NotNullTag, void* location) \
{ \
ASSERT(location); \
return location; \
} \
private: \
typedef int __thisIsHereToForceASemicolonAfterThisMacro这个宏定义了 operator new 和 operator delete。operator new 是直接调用 fastMalloc 完成内存分配,下面看看 fastMalloc 的实现:
void* fastMalloc(size_t size)
{
ASSERT_IS_WITHIN_LIMIT(size);
return bmalloc::api::malloc(size);
}可以看到 WTF 使用了 bmalloc 来 malloc,这个 bmalloc 被苹果号称在性能上要远超于 TCMalloc 和 STL 里在 malloc 之上实现一个内存池的的思路也完全不一样。关于 TCMalloc 的实现和原理可以参看:http://goog-perftools.sourceforge.net/doc/tcmalloc.html 。关于 STL 内存管理的实现可以在 《STL 源码分析》第二章里有详细说明。
WTF 里很多的容器,比如 BlockStack,Deque,Vector 和 HashTable。
WTF 里的 Vector 和 STL 里的 Vector 一样也是一种数据结构,相当于动态数组,当不知道需要的数组规模多大时可以达到最大节约空间的目的,那么看看 WTF 是如何实现 Vector 的吧,关键地方我在代码里做了注释说明。
template<typename T, size_t inlineCapacity = 0, typename OverflowHandler = CrashOnOverflow, size_t minCapacity = 16, typename Malloc = FastMalloc>
class Vector : private VectorBuffer<T, inlineCapacity, Malloc> {
WTF_MAKE_FAST_ALLOCATED;
private:
//VectorBuffer 是内部存储数据的容器
typedef VectorBuffer<T, inlineCapacity, Malloc> Base;
//Vector 里元素的初始化,复制和移动这些操作都在 VectorTypeOperations 里
typedef VectorTypeOperations<T> TypeOperations;
public:
typedef T ValueType;
//iterator 直接使用的原生指针
typedef T* iterator;
typedef const T* const_iterator;
typedef std::reverse_iterator<iterator> reverse_iterator;
typedef std::reverse_iterator<const_iterator> const_reverse_iterator;
Vector()
{
}
// Unlike in std::vector, this constructor does not initialize POD types.
explicit Vector(size_t size)
: Base(size, size)
{
asanSetInitialBufferSizeTo(size);
if (begin())
TypeOperations::initialize(begin(), end());
}
Vector(size_t size, const T& val)
: Base(size, size)
{
asanSetInitialBufferSizeTo(size);
if (begin())
TypeOperations::uninitializedFill(begin(), end(), val);
}
Vector(std::initializer_list<T> initializerList)
{
reserveInitialCapacity(initializerList.size());
asanSetInitialBufferSizeTo(initializerList.size());
for (const auto& element : initializerList)
uncheckedAppend(element);
}
~Vector()
{
if (m_size)
TypeOperations::destruct(begin(), end());
asanSetBufferSizeToFullCapacity(0);
}
Vector(const Vector&);
template<size_t otherCapacity, typename otherOverflowBehaviour, size_t otherMinimumCapacity, typename OtherMalloc>
explicit Vector(const Vector<T, otherCapacity, otherOverflowBehaviour, otherMinimumCapacity, OtherMalloc>&);
Vector& operator=(const Vector&);
template<size_t otherCapacity, typename otherOverflowBehaviour, size_t otherMinimumCapacity, typename OtherMalloc>
Vector& operator=(const Vector<T, otherCapacity, otherOverflowBehaviour, otherMinimumCapacity, OtherMalloc>&);
Vector(Vector&&);
Vector& operator=(Vector&&);
//返回 Vector 里元素个数
size_t size() const { return m_size; }
static ptrdiff_t sizeMemoryOffset() { return OBJECT_OFFSETOF(Vector, m_size); }
//返回的是 Vector 中的容量,容量随着元素增加和删除而变化
size_t capacity() const { return Base::capacity(); }
bool isEmpty() const { return !size(); }
//这里提供的是数组的访问功能
T& at(size_t i)
{
if (UNLIKELY(i >= size()))
OverflowHandler::overflowed();
return Base::buffer()[i];
}
const T& at(size_t i) const
{
if (UNLIKELY(i >= size()))
OverflowHandler::overflowed();
return Base::buffer()[i];
}
T& at(Checked<size_t> i)
{
RELEASE_ASSERT(i < size());
return Base::buffer()[i];
}
const T& at(Checked<size_t> i) const
{
RELEASE_ASSERT(i < size());
return Base::buffer()[i];
}
//返回数组中第几个元素
T& operator[](size_t i) { return at(i); }
const T& operator[](size_t i) const { return at(i); }
T& operator[](Checked<size_t> i) { return at(i); }
const T& operator[](Checked<size_t> i) const { return at(i); }
T* data() { return Base::buffer(); }
const T* data() const { return Base::buffer(); }
static ptrdiff_t dataMemoryOffset() { return Base::bufferMemoryOffset(); }
//迭代功能的实现,获取 begin 和 end,Vector 元素有了插入和删除操作都需要重新 begin 和 end。
iterator begin() { return data(); }
iterator end() { return begin() + m_size; }
const_iterator begin() const { return data(); }
const_iterator end() const { return begin() + m_size; }
reverse_iterator rbegin() { return reverse_iterator(end()); }
reverse_iterator rend() { return reverse_iterator(begin()); }
const_reverse_iterator rbegin() const { return const_reverse_iterator(end()); }
const_reverse_iterator rend() const { return const_reverse_iterator(begin()); }
T& first() { return at(0); }
const T& first() const { return at(0); }
T& last() { return at(size() - 1); }
const T& last() const { return at(size() - 1); }
T takeLast()
{
T result = WTFMove(last());
removeLast();
return result;
}
//O(n) 遍历查找的操作,所以数据量大时查找用 hashtable 效果会更好
template<typename U> bool contains(const U&) const;
template<typename U> size_t find(const U&) const;
template<typename MatchFunction> size_t findMatching(const MatchFunction&) const;
template<typename U> size_t reverseFind(const U&) const;
template<typename U> bool appendIfNotContains(const U&);
//实现 STL 里的方法,这里的 insert,append 和 resize 等操作的时候会通过 reserveCapacity 或 tryReserveCapacity 来进行空间扩展达到动态数组的能力
void shrink(size_t size);
void grow(size_t size);
void resize(size_t size);
void resizeToFit(size_t size);
void reserveCapacity(size_t newCapacity);
bool tryReserveCapacity(size_t newCapacity);
void reserveInitialCapacity(size_t initialCapacity);
void shrinkCapacity(size_t newCapacity);
void shrinkToFit() { shrinkCapacity(size()); }
void clear() { shrinkCapacity(0); }
void append(ValueType&& value) { append<ValueType>(std::forward<ValueType>(value)); }
template<typename U> void append(U&&);
template<typename... Args> void constructAndAppend(Args&&...);
template<typename... Args> bool tryConstructAndAppend(Args&&...);
void uncheckedAppend(ValueType&& value) { uncheckedAppend<ValueType>(std::forward<ValueType>(value)); }
template<typename U> void uncheckedAppend(U&&);
template<typename U> void append(const U*, size_t);
template<typename U, size_t otherCapacity> void appendVector(const Vector<U, otherCapacity>&);
template<typename U> bool tryAppend(const U*, size_t);
template<typename U> void insert(size_t position, const U*, size_t);
template<typename U> void insert(size_t position, U&&);
template<typename U, size_t c> void insertVector(size_t position, const Vector<U, c>&);
void remove(size_t position);
void remove(size_t position, size_t length);
template<typename U> bool removeFirst(const U&);
template<typename MatchFunction> bool removeFirstMatching(const MatchFunction&, size_t startIndex = 0);
template<typename U> unsigned removeAll(const U&);
template<typename MatchFunction> unsigned removeAllMatching(const MatchFunction&, size_t startIndex = 0);
void removeLast()
{
if (UNLIKELY(isEmpty()))
OverflowHandler::overflowed();
shrink(size() - 1);
}
void fill(const T&, size_t);
void fill(const T& val) { fill(val, size()); }
template<typename Iterator> void appendRange(Iterator start, Iterator end);
MallocPtr<T> releaseBuffer();
void swap(Vector<T, inlineCapacity, OverflowHandler, minCapacity>& other)
{
#if ASAN_ENABLED
if (this == std::addressof(other)) // ASan will crash if we try to restrict access to the same buffer twice.
return;
#endif
// Make it possible to copy inline buffers.
asanSetBufferSizeToFullCapacity();
other.asanSetBufferSizeToFullCapacity();
Base::swap(other, m_size, other.m_size);
std::swap(m_size, other.m_size);
asanSetInitialBufferSizeTo(m_size);
other.asanSetInitialBufferSizeTo(other.m_size);
}
void reverse();
void checkConsistency();
template<typename MapFunction, typename R = typename std::result_of<MapFunction(const T&)>::type> Vector<R> map(MapFunction) const;
private:
void expandCapacity(size_t newMinCapacity);
T* expandCapacity(size_t newMinCapacity, T*);
bool tryExpandCapacity(size_t newMinCapacity);
const T* tryExpandCapacity(size_t newMinCapacity, const T*);
template<typename U> U* expandCapacity(size_t newMinCapacity, U*);
template<typename U> void appendSlowCase(U&&);
template<typename... Args> void constructAndAppendSlowCase(Args&&...);
template<typename... Args> bool tryConstructAndAppendSlowCase(Args&&...);
void asanSetInitialBufferSizeTo(size_t);
void asanSetBufferSizeToFullCapacity(size_t);
void asanSetBufferSizeToFullCapacity() { asanSetBufferSizeToFullCapacity(size()); }
void asanBufferSizeWillChangeTo(size_t);
using Base::m_size;
using Base::buffer;
using Base::capacity;
using Base::swap;
using Base::allocateBuffer;
using Base::deallocateBuffer;
using Base::tryAllocateBuffer;
using Base::shouldReallocateBuffer;
using Base::reallocateBuffer;
using Base::restoreInlineBufferIfNeeded;
using Base::releaseBuffer;
#if ASAN_ENABLED
using Base::endOfBuffer;
#endif
};HashTable 实现代码如下:
template<typename Key, typename Value, typename Extractor, typename HashFunctions, typename Traits, typename KeyTraits>
class HashTable {
public:
typedef HashTableIterator<Key, Value, Extractor, HashFunctions, Traits, KeyTraits> iterator;
typedef HashTableConstIterator<Key, Value, Extractor, HashFunctions, Traits, KeyTraits> const_iterator;
typedef Traits ValueTraits;
typedef Key KeyType;
typedef Value ValueType;
typedef IdentityHashTranslator<ValueTraits, HashFunctions> IdentityTranslatorType;
typedef HashTableAddResult<iterator> AddResult;
#if DUMP_HASHTABLE_STATS_PER_TABLE
struct Stats {
Stats()
: numAccesses(0)
, numRehashes(0)
, numRemoves(0)
, numReinserts(0)
, maxCollisions(0)
, numCollisions(0)
, collisionGraph()
{
}
unsigned numAccesses;
unsigned numRehashes;
unsigned numRemoves;
unsigned numReinserts;
unsigned maxCollisions;
unsigned numCollisions;
unsigned collisionGraph[4096];
void recordCollisionAtCount(unsigned count)
{
if (count > maxCollisions)
maxCollisions = count;
numCollisions++;
collisionGraph[count]++;
}
void dumpStats()
{
dataLogF("\nWTF::HashTable::Stats dump\n\n");
dataLogF("%d accesses\n", numAccesses);
dataLogF("%d total collisions, average %.2f probes per access\n", numCollisions, 1.0 * (numAccesses + numCollisions) / numAccesses);
dataLogF("longest collision chain: %d\n", maxCollisions);
for (unsigned i = 1; i <= maxCollisions; i++) {
dataLogF(" %d lookups with exactly %d collisions (%.2f%% , %.2f%% with this many or more)\n", collisionGraph[i], i, 100.0 * (collisionGraph[i] - collisionGraph[i+1]) / numAccesses, 100.0 * collisionGraph[i] / numAccesses);
}
dataLogF("%d rehashes\n", numRehashes);
dataLogF("%d reinserts\n", numReinserts);
}
};
#endif
HashTable();
~HashTable()
{
invalidateIterators();
if (m_table)
deallocateTable(m_table, m_tableSize);
#if CHECK_HASHTABLE_USE_AFTER_DESTRUCTION
m_table = (ValueType*)(uintptr_t)0xbbadbeef;
#endif
}
HashTable(const HashTable&);
void swap(HashTable&);
HashTable& operator=(const HashTable&);
HashTable(HashTable&&);
HashTable& operator=(HashTable&&);
// When the hash table is empty, just return the same iterator for end as for begin.
// This is more efficient because we don't have to skip all the empty and deleted
// buckets, and iterating an empty table is a common case that's worth optimizing.
iterator begin() { return isEmpty() ? end() : makeIterator(m_table); }
iterator end() { return makeKnownGoodIterator(m_table + m_tableSize); }
const_iterator begin() const { return isEmpty() ? end() : makeConstIterator(m_table); }
const_iterator end() const { return makeKnownGoodConstIterator(m_table + m_tableSize); }
unsigned size() const { return m_keyCount; }
unsigned capacity() const { return m_tableSize; }
bool isEmpty() const { return !m_keyCount; }
AddResult add(const ValueType& value) { return add<IdentityTranslatorType>(Extractor::extract(value), value); }
AddResult add(ValueType&& value) { return add<IdentityTranslatorType>(Extractor::extract(value), WTFMove(value)); }
// A special version of add() that finds the object by hashing and comparing
// with some other type, to avoid the cost of type conversion if the object is already
// in the table.
template<typename HashTranslator, typename T, typename Extra> AddResult add(T&& key, Extra&&);
template<typename HashTranslator, typename T, typename Extra> AddResult addPassingHashCode(T&& key, Extra&&);
iterator find(const KeyType& key) { return find<IdentityTranslatorType>(key); }
const_iterator find(const KeyType& key) const { return find<IdentityTranslatorType>(key); }
bool contains(const KeyType& key) const { return contains<IdentityTranslatorType>(key); }
template<typename HashTranslator, typename T> iterator find(const T&);
template<typename HashTranslator, typename T> const_iterator find(const T&) const;
template<typename HashTranslator, typename T> bool contains(const T&) const;
void remove(const KeyType&);
void remove(iterator);
void removeWithoutEntryConsistencyCheck(iterator);
void removeWithoutEntryConsistencyCheck(const_iterator);
template<typename Functor>
void removeIf(const Functor&);
void clear();
static bool isEmptyBucket(const ValueType& value) { return isHashTraitsEmptyValue<KeyTraits>(Extractor::extract(value)); }
static bool isDeletedBucket(const ValueType& value) { return KeyTraits::isDeletedValue(Extractor::extract(value)); }
static bool isEmptyOrDeletedBucket(const ValueType& value) { return isEmptyBucket(value) || isDeletedBucket(value); }
ValueType* lookup(const Key& key) { return lookup<IdentityTranslatorType>(key); }
template<typename HashTranslator, typename T> ValueType* lookup(const T&);
template<typename HashTranslator, typename T> ValueType* inlineLookup(const T&);
#if !ASSERT_DISABLED
void checkTableConsistency() const;
#else
static void checkTableConsistency() { }
#endif
#if CHECK_HASHTABLE_CONSISTENCY
void internalCheckTableConsistency() const { checkTableConsistency(); }
void internalCheckTableConsistencyExceptSize() const { checkTableConsistencyExceptSize(); }
#else
static void internalCheckTableConsistencyExceptSize() { }
static void internalCheckTableConsistency() { }
#endif
private:
static ValueType* allocateTable(unsigned size);
static void deallocateTable(ValueType* table, unsigned size);
typedef std::pair<ValueType*, bool> LookupType;
typedef std::pair<LookupType, unsigned> FullLookupType;
LookupType lookupForWriting(const Key& key) { return lookupForWriting<IdentityTranslatorType>(key); };
template<typename HashTranslator, typename T> FullLookupType fullLookupForWriting(const T&);
template<typename HashTranslator, typename T> LookupType lookupForWriting(const T&);
template<typename HashTranslator, typename T, typename Extra> void addUniqueForInitialization(T&& key, Extra&&);
template<typename HashTranslator, typename T> void checkKey(const T&);
void removeAndInvalidateWithoutEntryConsistencyCheck(ValueType*);
void removeAndInvalidate(ValueType*);
void remove(ValueType*);
bool shouldExpand() const { return (m_keyCount + m_deletedCount) * m_maxLoad >= m_tableSize; }
bool mustRehashInPlace() const { return m_keyCount * m_minLoad < m_tableSize * 2; }
bool shouldShrink() const { return m_keyCount * m_minLoad < m_tableSize && m_tableSize > KeyTraits::minimumTableSize; }
ValueType* expand(ValueType* entry = nullptr);
void shrink() { rehash(m_tableSize / 2, nullptr); }
ValueType* rehash(unsigned newTableSize, ValueType* entry);
ValueType* reinsert(ValueType&&);
static void initializeBucket(ValueType& bucket);
static void deleteBucket(ValueType& bucket) { hashTraitsDeleteBucket<Traits>(bucket); }
FullLookupType makeLookupResult(ValueType* position, bool found, unsigned hash)
{ return FullLookupType(LookupType(position, found), hash); }
iterator makeIterator(ValueType* pos) { return iterator(this, pos, m_table + m_tableSize); }
const_iterator makeConstIterator(ValueType* pos) const { return const_iterator(this, pos, m_table + m_tableSize); }
iterator makeKnownGoodIterator(ValueType* pos) { return iterator(this, pos, m_table + m_tableSize, HashItemKnownGood); }
const_iterator makeKnownGoodConstIterator(ValueType* pos) const { return const_iterator(this, pos, m_table + m_tableSize, HashItemKnownGood); }
#if !ASSERT_DISABLED
void checkTableConsistencyExceptSize() const;
#else
static void checkTableConsistencyExceptSize() { }
#endif
#if CHECK_HASHTABLE_ITERATORS
void invalidateIterators();
#else
static void invalidateIterators() { }
#endif
static const unsigned m_maxLoad = 2;
static const unsigned m_minLoad = 6;
ValueType* m_table;
unsigned m_tableSize;
unsigned m_tableSizeMask;
unsigned m_keyCount;
unsigned m_deletedCount;
#if CHECK_HASHTABLE_ITERATORS
public:
// All access to m_iterators should be guarded with m_mutex.
mutable const_iterator* m_iterators;
// Use std::unique_ptr so HashTable can still be memmove'd or memcpy'ed.
mutable std::unique_ptr<Lock> m_mutex;
#endif
#if DUMP_HASHTABLE_STATS_PER_TABLE
public:
mutable std::unique_ptr<Stats> m_stats;
#endif
};完整具体的实现可以查看 WTF/Source/wtf/HashTable.h。这里需要注意的是 HashTable 是线性存储空间的起始地址是 bengin 和 end 来表示的,capacity 存储空间不足时会使用 doubleHash 的方法来扩容,将原空间大小变成两倍。调用 begin 或 end 时会创建 HashTable 的 const_iterator,它维持了一个指向 value_type 的指针,所以 iterator 的自增和自减就是指针的自增自减,这点比 STL 的 HashMap 采用数组加链表实现要简单。
WebKit 对线程的处理就是在一个 loop 循环里处理消息队列,在 WTF/Source/wtf/MessageQueue.h 里有对消息队列的定义:
// The queue takes ownership of messages and transfer it to the new owner
// when messages are fetched from the queue.
// Essentially, MessageQueue acts as a queue of std::unique_ptr<DataType>.
template<typename DataType>
class MessageQueue {
WTF_MAKE_NONCOPYABLE(MessageQueue);
public:
MessageQueue() : m_killed(false) { }
~MessageQueue();
void append(std::unique_ptr<DataType>);
void appendAndKill(std::unique_ptr<DataType>);
bool appendAndCheckEmpty(std::unique_ptr<DataType>);
void prepend(std::unique_ptr<DataType>);
std::unique_ptr<DataType> waitForMessage();
std::unique_ptr<DataType> tryGetMessage();
Deque<std::unique_ptr<DataType>> takeAllMessages();
std::unique_ptr<DataType> tryGetMessageIgnoringKilled();
template<typename Predicate>
std::unique_ptr<DataType> waitForMessageFilteredWithTimeout(MessageQueueWaitResult&, Predicate&&, WallTime absoluteTime);
template<typename Predicate>
void removeIf(Predicate&&);
void kill();
bool killed() const;
// The result of isEmpty() is only valid if no other thread is manipulating the queue at the same time.
bool isEmpty();
private:
//m_mutex 是访问 Deque 的互斥锁,是对 pthread_mutex_t 类型的一个封装
mutable Lock m_mutex;
//Condition 是对 pthread_cond_t 类型的封装,m_condition 提供了挂起线程
Condition m_condition;
//内部主要存储结构
Deque<std::unique_ptr<DataType>> m_queue;
bool m_killed;
};可以看出 MessageQueue 是通过 pthread_mutex_t 来保证线程安全的。WebKit 在运行时会有很多线程,有网络资源加载的线程,解析页面布局的线程,绘制线程,I/O 线程,解码线程等线程。最核心的是解析页面布局线程,其它线程都由它触发,所以可以称为主线程,这个线程在 Mac 端是 MainThread 定义和实现的,在 iOS 端是 WebCoreThread 定义实现的。这些定义比如 callOnMainThread 就是其它异步线程做回调时调用的函数。
主要作用就是加载资源,有 MainResourceLoader 和 SubResourceLoader。加载的资源有来自网络,本地或者缓存的。Loader 模块本身是平台无关的,只是将需要获得资源的请求传给平台相关的网络模块,接受网络模块返回资源。平台相关的网络模块在 WebCore/platform/network 里。如果是 iOS 就在 WebCore/platform/network/iOS 里,如果 Mac 就在 WebCore/platform/network/mac 里。
网页本身就是一种资源,同时网页还需要其它的一些资源,比如图片,视频,js 代码等。下面是主要资源的类型:
- HTML:页面主文件
- JavaScript:单独的文件后者直接在 HTML 代码里
- CSS:同 JavaScript 一样可以是单独文件也可以直接写在 HTML 代码里
- 图片:各种编码图片比如 jpg 和 png
- SVG:矢量图片
- CSS Shader:为 CSS 带来 3D 图形特性
- 音频视频:多媒体资源以及视频字幕
- 字体:自定义的字体
- XSL:对 XSLT 语言编写的文件支持
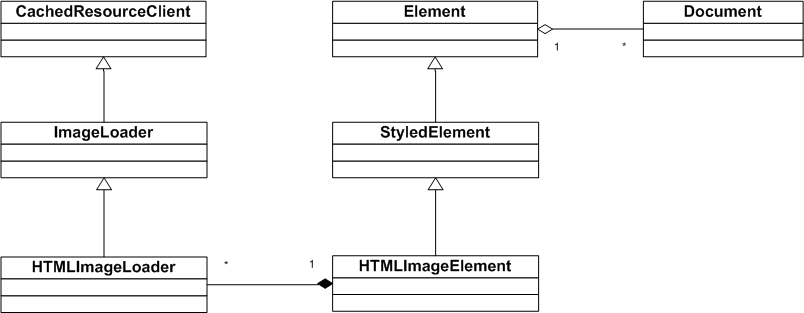
WebKit 里会有不同的类来表示这些资源,它们都会有个共同的基类 CachedResource。如下图所示,其中 HTML 的资源类型是 CachedRawResource 类,类型叫 MainResource 类。
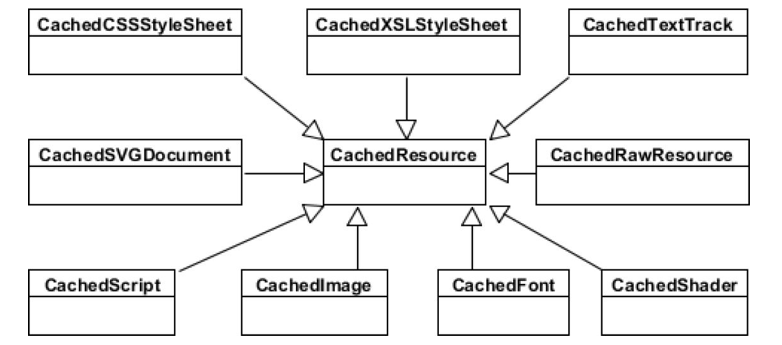
加载的入口,最终会调到异步 load 过程。主要是提供一个下载一个 Frame 的一些接口。任何一个页面都需要至少一个 mainframe,因此 load 一般都是从 load 一个 mainframe 开始。
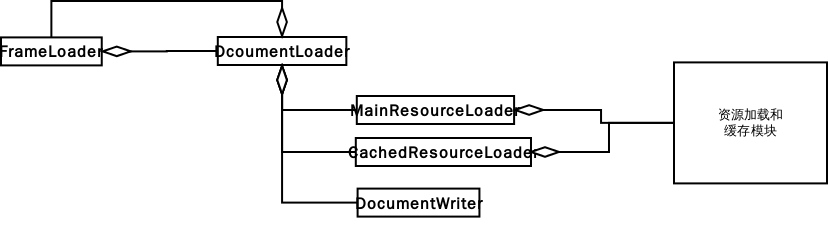
- MainResourceLoader:加载资源,html 也是资源,还有 css,javascript 和 image 等这些是 SubresourceLoader 来管理的。
- CacheResourceLoader:缓存资源读取。
- 资源加载和缓存是由 ResourceLoader 和 Cache 这两个独立性高的模块来实现。
- DocumentWriter:辅助类,将获取的数据写到 writer 里,会创建 DOM 树的根节点 HTMLDocument 对象,作为一个缓冲区进行 DocumentParser 解析操作,同时该类还包含了文档字符解码类和 HTMLDocumentParser 类。
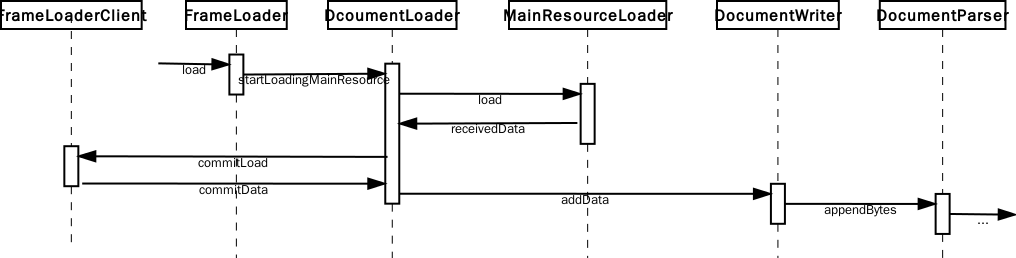
解析前会创建不同的 Dcoument,DocumentLoader 的 commitData 第一次收到数据时会调 DcumentWriter 的 begin,这个 begin 会调用 DocumentWriter::createDocument 创建一个 Document 对象。
这里创建的对象会根据 URL 来创建不同的 Document,这里有 HTMLDocument ,详细实现可以看看 DOMImplementation::createDocument 的实现。
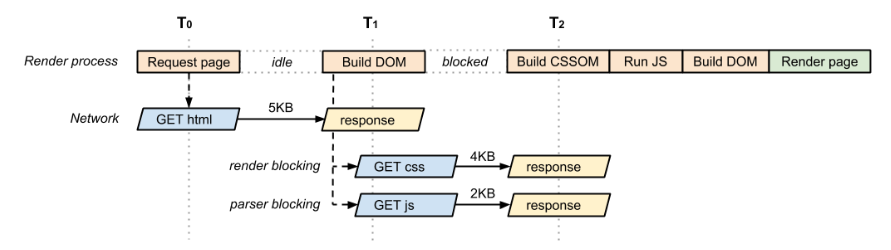
整个资源加载过程,这篇文章有详细的介绍:https://hacks.mozilla.org/2017/09/building-the-dom-faster-speculative-parsing-async-defer-and-preload/
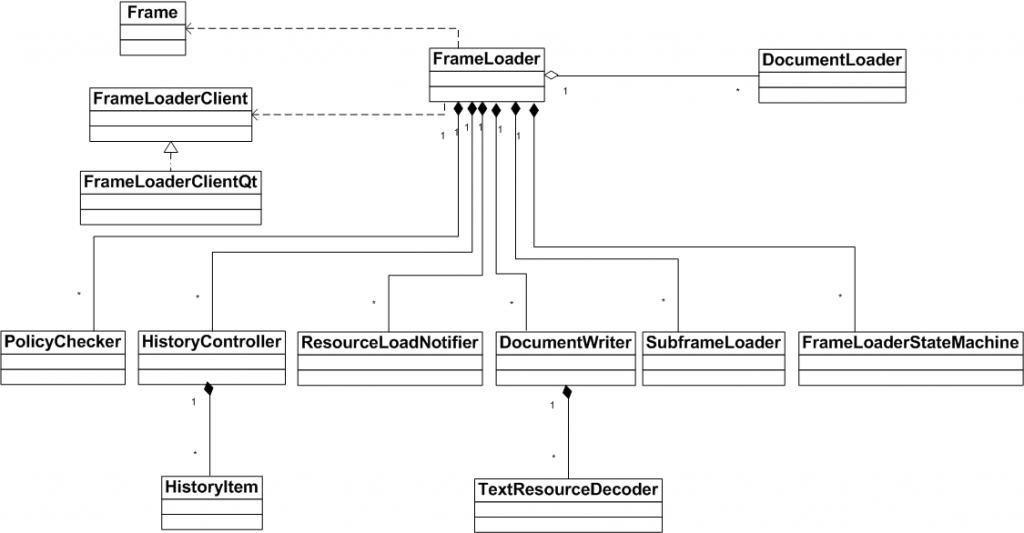
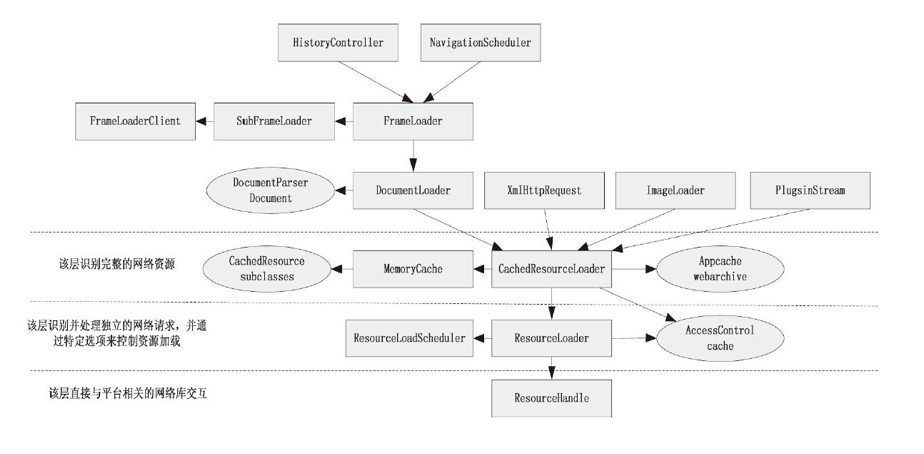
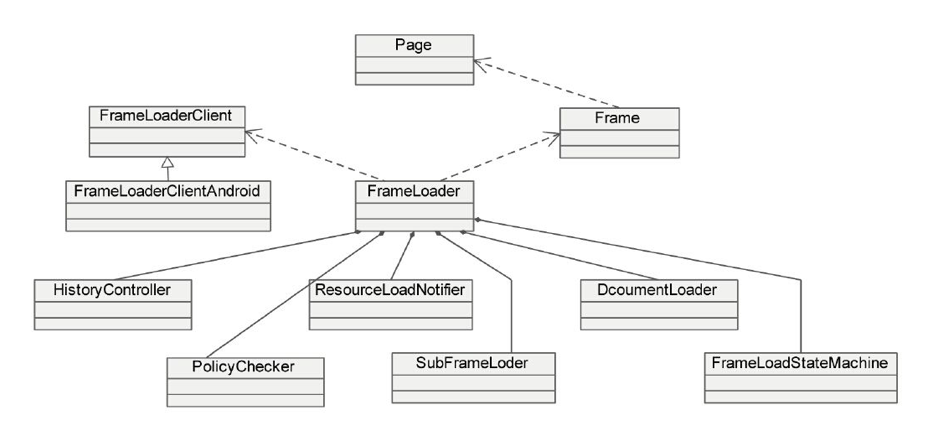
- Frame 和 FrameLoaderClient:在 Frame 的构造函数中调用 FrameLoader 的构造函数需要传入 Frame 指针和 FrameLoaderClient 指针。一般作为不同平台适配代码,控制 WebKit 的使用逻辑。FrameLoader 会把加载过程的状态,还有结果等信息传递给 FrameLoaderClient,这样的话 FrameLoaderClient 就能够掌控 FrameLoader 的动作。
- SubFrameLoader:维护子 Frame。
- DocumentWriter:有一个 m_writer 对象在 Frame 的数据 load 完成时进行下一步比如解码处理。
- DocumentLoader:FrameLoader 会维护三个 DocumentLoader。m_policyDocumentLoader 是 policy check 的阶段。m_provisionalDocumentLoader 会负责 startLoadingMainResource 的调用。m_documentLoader 是数据到了后使用的,前一个 Frame 的 DocumentLoader 不能再用。
- HistoryController:管理历史记录,保存和恢复 Document 和 Page 的状态到 HistoryItem,维护浏览页面的前进后退队列,这样就可以实现前进和后退等操作。FrameLoader 通过 HistoryController 来操作 m_backForwardController 对象。
- ResourceLoadNotifier:当 ResourceLoader 有变化时来通知 FrameLoader,用于它们之间的通信。
- SubframeLoader:用来控制 MainFrame 里的 iframe 的加载。
- FrameLoaderStateMachine:描述 FrameLoader 处理 DocumentLoader 的节点的状态,看是在创建状态还是显示状态。
- PolicyChecker:对 FrameLoader 做校验,有三种,第一种 NewWindow Policy,指对新开 tab 或 window 时校验。第二种 NavigationPolicy 是对页面请求的校验。第三种 ContentPolicy 是对请求收到的数据判断 Mime type 等的校验。PolicyChecker 会提供对应几口,由 FrameLoaderClient 来对这些请求校验确定是否继续加载或者做其它操作。
FrameLoader 自身的初始化。 初始化的调用顺序
WebFrame::WebFrame(webPage* parent,WebFrameData *frameData)
WebFramePrivate::init(WebFrame* webframe,WebFrameData* frameData)
Frame::init()
FrameLoader::init()提交 provisional 阶段时下载的数据 完成 Document loading 的调用顺序
DocumentLoader::finishLoading
DocumentLoader::commitIfReady
FrameLoader::commitProvisionalLoad资源数据接受提交调用顺序
ResourceLoader::didReceiveData
MainResourceLoader::addData
DocumentLoader::receiveData
DocumentLoader::commitLoad
DocumentLoader::commitIfReady
DocumentLoader::commitProvisionalLoad网络加载完成的接口,作用是通知 DocumentLoader 和 DocumentWriter 已经完成,可以进行后面的提交数据和解析工作。 函数的调用顺序
ResourceLoader::didFinishLoading
MainResourceLoader::didFinishLoading
FrameLoader::finishedLoading
FrameLoader::init()完成解析时调用的接口 调用顺序
DocumentWritter::end
Document::finishParsing
Document::finishedParsing
FrameLoader::finishedParsing加载请求,将 Frame 相关的数据封装成 ResourceRequest 作为参数带入,这个接口会创建出 DocumentLoader。
//创建 DocumentLoader
void FrameLoader::load(FrameLoadRequest&& request)
{
if (m_inStopAllLoaders)
return;
if (!request.frameName().isEmpty()) {
Frame* frame = findFrameForNavigation(request.frameName());
if (frame) {
request.setShouldCheckNewWindowPolicy(false);
if (&frame->loader() != this) {
frame->loader().load(WTFMove(request));
return;
}
}
}
if (request.shouldCheckNewWindowPolicy()) {
NavigationAction action { request.requester(), request.resourceRequest(), InitiatedByMainFrame::Unknown, NavigationType::Other, request.shouldOpenExternalURLsPolicy() };
policyChecker().checkNewWindowPolicy(WTFMove(action), request.resourceRequest(), nullptr, request.frameName(), [this] (const ResourceRequest& request, FormState* formState, const String& frameName, const NavigationAction& action, bool shouldContinue) {
continueLoadAfterNewWindowPolicy(request, formState, frameName, action, shouldContinue, AllowNavigationToInvalidURL::Yes, NewFrameOpenerPolicy::Suppress);
});
return;
}
if (!request.hasSubstituteData())
request.setSubstituteData(defaultSubstituteDataForURL(request.resourceRequest().url()));
//FrameLoader 使用空 SubStituteData 来创建 DocumentLoader 完成 MainResource 的加载。
Ref<DocumentLoader> loader = m_client.createDocumentLoader(request.resourceRequest(), request.substituteData());
applyShouldOpenExternalURLsPolicyToNewDocumentLoader(m_frame, loader, request);
load(loader.ptr());
}
//完善 request 信息
void FrameLoader::load(DocumentLoader* newDocumentLoader)
{
ResourceRequest& r = newDocumentLoader->request();
//ResourceRequest 包含了 HTTP Header 的内容,addExtraFieldsToMainResourceRequest 这个方法会添加一些类似 Cookie 策略,User Agent,Cache-Control,Content-type 等信息。
addExtraFieldsToMainResourceRequest(r);
FrameLoadType type;
if (shouldTreatURLAsSameAsCurrent(newDocumentLoader->originalRequest().url())) {
r.setCachePolicy(ReloadIgnoringCacheData);
type = FrameLoadType::Same;
} else if (shouldTreatURLAsSameAsCurrent(newDocumentLoader->unreachableURL()) && m_loadType == FrameLoadType::Reload)
type = FrameLoadType::Reload;
else if (m_loadType == FrameLoadType::RedirectWithLockedBackForwardList && !newDocumentLoader->unreachableURL().isEmpty() && newDocumentLoader->substituteData().isValid())
type = FrameLoadType::RedirectWithLockedBackForwardList;
else
type = FrameLoadType::Standard;
if (m_documentLoader)
newDocumentLoader->setOverrideEncoding(m_documentLoader->overrideEncoding());
if (shouldReloadToHandleUnreachableURL(newDocumentLoader)) {
history().saveDocumentAndScrollState();
ASSERT(type == FrameLoadType::Standard);
type = FrameLoadType::Reload;
}
loadWithDocumentLoader(newDocumentLoader, type, 0, AllowNavigationToInvalidURL::Yes);
}
//校验检查
void FrameLoader::loadWithDocumentLoader(DocumentLoader* loader, FrameLoadType type, FormState* formState, AllowNavigationToInvalidURL allowNavigationToInvalidURL)
{
// Retain because dispatchBeforeLoadEvent may release the last reference to it.
Ref<Frame> protect(m_frame);
ASSERT(m_client.hasWebView());
ASSERT(m_frame.view());
if (!isNavigationAllowed())
return;
if (m_frame.document())
m_previousURL = m_frame.document()->url();
const URL& newURL = loader->request().url();
// Log main frame navigation types.
if (m_frame.isMainFrame()) {
if (auto* page = m_frame.page())
page->mainFrameLoadStarted(newURL, type);
static_cast<MainFrame&>(m_frame).performanceLogging().didReachPointOfInterest(PerformanceLogging::MainFrameLoadStarted);
}
policyChecker().setLoadType(type);
bool isFormSubmission = formState;
const String& httpMethod = loader->request().httpMethod();
if (shouldPerformFragmentNavigation(isFormSubmission, httpMethod, policyChecker().loadType(), newURL)) {
RefPtr<DocumentLoader> oldDocumentLoader = m_documentLoader;
NavigationAction action { *m_frame.document(), loader->request(), InitiatedByMainFrame::Unknown, policyChecker().loadType(), isFormSubmission };
oldDocumentLoader->setTriggeringAction(action);
oldDocumentLoader->setLastCheckedRequest(ResourceRequest());
policyChecker().stopCheck();
policyChecker().checkNavigationPolicy(loader->request(), false /* didReceiveRedirectResponse */, oldDocumentLoader.get(), formState, [this] (const ResourceRequest& request, FormState*, bool shouldContinue) {
continueFragmentScrollAfterNavigationPolicy(request, shouldContinue);
});
return;
}
if (Frame* parent = m_frame.tree().parent())
loader->setOverrideEncoding(parent->loader().documentLoader()->overrideEncoding());
policyChecker().stopCheck();
//把 DocumentLoader 赋给 m_policyDocumentLoader
setPolicyDocumentLoader(loader);
//将请求信息记在 loader.m_triggeringAction 中
if (loader->triggeringAction().isEmpty())
loader->setTriggeringAction({ *m_frame.document(), loader->request(), InitiatedByMainFrame::Unknown, policyChecker().loadType(), isFormSubmission });
if (Element* ownerElement = m_frame.ownerElement()) {
if (!m_stateMachine.committedFirstRealDocumentLoad()
&& !ownerElement->dispatchBeforeLoadEvent(loader->request().url().string())) {
continueLoadAfterNavigationPolicy(loader->request(), formState, false, allowNavigationToInvalidURL);
return;
}
}
//使用 loader.m_triggeringAction 做校验,处理空白等,用来决定怎么处理请求
policyChecker().checkNavigationPolicy(loader->request(), false /* didReceiveRedirectResponse */, loader, formState, [this, allowNavigationToInvalidURL] (const ResourceRequest& request, FormState* formState, bool shouldContinue) {
//shouldContinue 的不同流程会不同,formState 是用来判断 HTMLFormElement 表单 FormSubmissionTrigger 枚举状态的,这样也会有不同的流程,接下来看看 continueLoadAfterNavigationPolicy 会怎么去处理这些参数不同的值吧。
continueLoadAfterNavigationPolicy(request, formState, shouldContinue, allowNavigationToInvalidURL);
});
}
//
void FrameLoader::continueLoadAfterNavigationPolicy(const ResourceRequest& request, FormState* formState, bool shouldContinue, AllowNavigationToInvalidURL allowNavigationToInvalidURL)
{
// If we loaded an alternate page to replace an unreachableURL, we'll get in here with a
// nil policyDataSource because loading the alternate page will have passed
// through this method already, nested; otherwise, policyDataSource should still be set.
ASSERT(m_policyDocumentLoader || !m_provisionalDocumentLoader->unreachableURL().isEmpty());
bool isTargetItem = history().provisionalItem() ? history().provisionalItem()->isTargetItem() : false;
bool urlIsDisallowed = allowNavigationToInvalidURL == AllowNavigationToInvalidURL::No && !request.url().isValid();
// Three reasons we can't continue:
// 1) Navigation policy delegate said we can't so request is nil. A primary case of this
// is the user responding Cancel to the form repost nag sheet.
// 2) User responded Cancel to an alert popped up by the before unload event handler.
// 3) The request's URL is invalid and navigation to invalid URLs is disallowed.
bool canContinue = shouldContinue && shouldClose() && !urlIsDisallowed;
if (!canContinue) {
// If we were waiting for a quick redirect, but the policy delegate decided to ignore it, then we
// need to report that the client redirect was cancelled.
// FIXME: The client should be told about ignored non-quick redirects, too.
if (m_quickRedirectComing)
clientRedirectCancelledOrFinished(false);
setPolicyDocumentLoader(nullptr);
// If the navigation request came from the back/forward menu, and we punt on it, we have the
// problem that we have optimistically moved the b/f cursor already, so move it back. For sanity,
// we only do this when punting a navigation for the target frame or top-level frame.
if ((isTargetItem || m_frame.isMainFrame()) && isBackForwardLoadType(policyChecker().loadType())) {
if (Page* page = m_frame.page()) {
if (HistoryItem* resetItem = m_frame.mainFrame().loader().history().currentItem()) {
page->backForward().setCurrentItem(resetItem);
m_frame.loader().client().updateGlobalHistoryItemForPage();
}
}
}
return;
}
FrameLoadType type = policyChecker().loadType();
// A new navigation is in progress, so don't clear the history's provisional item.
stopAllLoaders(ShouldNotClearProvisionalItem);
// <rdar://problem/6250856> - In certain circumstances on pages with multiple frames, stopAllLoaders()
// might detach the current FrameLoader, in which case we should bail on this newly defunct load.
if (!m_frame.page())
return;
//把 DocumentLoader 赋值给 m_provisionalDocumentLoader
setProvisionalDocumentLoader(m_policyDocumentLoader.get());
m_loadType = type;
//设置 FrameLoader 状态为 Provisional
setState(FrameStateProvisional);
setPolicyDocumentLoader(nullptr);
if (isBackForwardLoadType(type)) {
auto& diagnosticLoggingClient = m_frame.page()->diagnosticLoggingClient();
if (history().provisionalItem()->isInPageCache()) {
diagnosticLoggingClient.logDiagnosticMessageWithResult(DiagnosticLoggingKeys::pageCacheKey(), DiagnosticLoggingKeys::retrievalKey(), DiagnosticLoggingResultPass, ShouldSample::Yes);
loadProvisionalItemFromCachedPage();
return;
}
diagnosticLoggingClient.logDiagnosticMessageWithResult(DiagnosticLoggingKeys::pageCacheKey(), DiagnosticLoggingKeys::retrievalKey(), DiagnosticLoggingResultFail, ShouldSample::Yes);
}
if (!formState) {
continueLoadAfterWillSubmitForm();
return;
}
m_client.dispatchWillSubmitForm(*formState, [this] (PolicyAction action) {
policyChecker().continueLoadAfterWillSubmitForm(action);
});
}接着在 continueLoadAfterWillSubmitForm() 方法里 m_provisionalDocumentLoader 会做些准备工作并将状态设置成正在加载资源的状态。在 prepareForLoadStart 中抛出加载状态,回调给 FrameLoaderClient,调用 DocumentLoader 的 startLoadingMainResource。
WebKit 资源的加载都是由其移植方实现的,网络部分代码都在 WebCore/platform/network 里,里面包含了 HTTP Header,MIME,状态码等信息的处理。
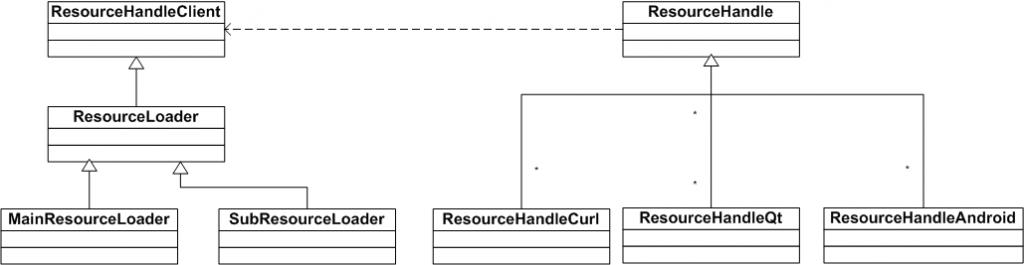
- ResouceHandleClient:跟网络传输过程相关,是网络事件对应的回调。
- MainResourceLoader:主资源,指的 HTML 页面,会立刻发起,下载失败会向用户报错。没有缓存
- SubResourceLoader:派生资源,HTML 页面里内嵌的图片和脚本链接等,会通过 ResourceScheduler 这个类来管理资源加载调度。下载失败不向用户报错。有缓存机制,通过 ResourceCach 保存 CSS JS 等资源原始数据以及解码后的图片数据,一方面可以节省流量一方面可以节省解码时间。
- ResourceLoader:是主资源和派生资源加载器的基类,会通过 ResourceNotifier 将回调传给 FrameLoaderClient。
ResourceHandleClient 定义了一些对应网络加载事件回调处理的虚函数。下面就是 ResourceHandleClient 的定义
class ResourceHandleClient {
public:
WEBCORE_EXPORT ResourceHandleClient();
WEBCORE_EXPORT virtual ~ResourceHandleClient();
WEBCORE_EXPORT virtual ResourceRequest willSendRequest(ResourceHandle*, ResourceRequest&&, ResourceResponse&&);
virtual void didSendData(ResourceHandle*, unsigned long long /*bytesSent*/, unsigned long long /*totalBytesToBeSent*/) { }
//收到服务器端第一个响应包,通过里面的 HTTP Header 可以判断是否成功
virtual void didReceiveResponse(ResourceHandle*, ResourceResponse&&) { }
//收到服务器端包含请求数据的响应包
virtual void didReceiveData(ResourceHandle*, const char*, unsigned, int /*encodedDataLength*/) { }
WEBCORE_EXPORT virtual void didReceiveBuffer(ResourceHandle*, Ref<SharedBuffer>&&, int encodedDataLength);
//接受过程结束
virtual void didFinishLoading(ResourceHandle*) { }
//接受失败
virtual void didFail(ResourceHandle*, const ResourceError&) { }
virtual void wasBlocked(ResourceHandle*) { }
virtual void cannotShowURL(ResourceHandle*) { }
virtual bool usesAsyncCallbacks() { return false; }
virtual bool loadingSynchronousXHR() { return false; }
// Client will pass an updated request using ResourceHandle::continueWillSendRequest() when ready.
WEBCORE_EXPORT virtual void willSendRequestAsync(ResourceHandle*, ResourceRequest&&, ResourceResponse&&);
// Client will call ResourceHandle::continueDidReceiveResponse() when ready.
WEBCORE_EXPORT virtual void didReceiveResponseAsync(ResourceHandle*, ResourceResponse&&);
#if USE(PROTECTION_SPACE_AUTH_CALLBACK)
// Client will pass an updated request using ResourceHandle::continueCanAuthenticateAgainstProtectionSpace() when ready.
WEBCORE_EXPORT virtual void canAuthenticateAgainstProtectionSpaceAsync(ResourceHandle*, const ProtectionSpace&);
#endif
// Client will pass an updated request using ResourceHandle::continueWillCacheResponse() when ready.
#if USE(CFURLCONNECTION)
WEBCORE_EXPORT virtual void willCacheResponseAsync(ResourceHandle*, CFCachedURLResponseRef);
#elif PLATFORM(COCOA)
WEBCORE_EXPORT virtual void willCacheResponseAsync(ResourceHandle*, NSCachedURLResponse *);
#endif
#if USE(SOUP)
virtual char* getOrCreateReadBuffer(size_t /*requestedLength*/, size_t& /*actualLength*/) { return 0; }
#endif
virtual bool shouldUseCredentialStorage(ResourceHandle*) { return false; }
virtual void didReceiveAuthenticationChallenge(ResourceHandle*, const AuthenticationChallenge&) { }
#if USE(PROTECTION_SPACE_AUTH_CALLBACK)
virtual bool canAuthenticateAgainstProtectionSpace(ResourceHandle*, const ProtectionSpace&) { return false; }
#endif
virtual void receivedCancellation(ResourceHandle*, const AuthenticationChallenge&) { }
#if PLATFORM(IOS) || USE(CFURLCONNECTION)
virtual RetainPtr<CFDictionaryRef> connectionProperties(ResourceHandle*) { return nullptr; }
#endif
#if USE(CFURLCONNECTION)
virtual CFCachedURLResponseRef willCacheResponse(ResourceHandle*, CFCachedURLResponseRef response) { return response; }
#if PLATFORM(WIN)
virtual bool shouldCacheResponse(ResourceHandle*, CFCachedURLResponseRef) { return true; }
#endif // PLATFORM(WIN)
#elif PLATFORM(COCOA)
virtual NSCachedURLResponse *willCacheResponse(ResourceHandle*, NSCachedURLResponse *response) { return response; }
#endif
};与 ResourceHandleClient 相关的类如下
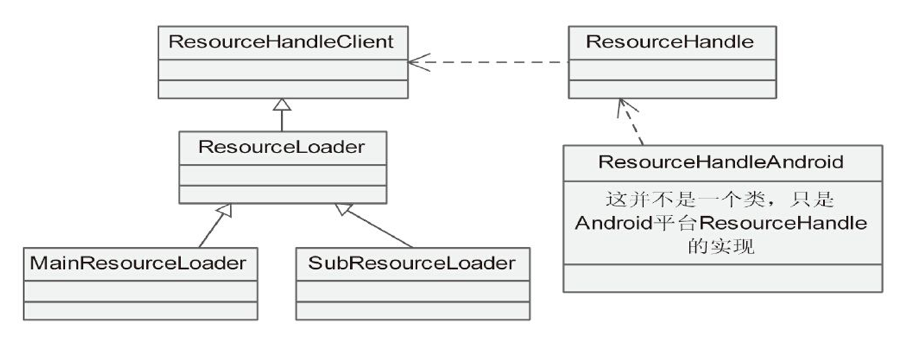
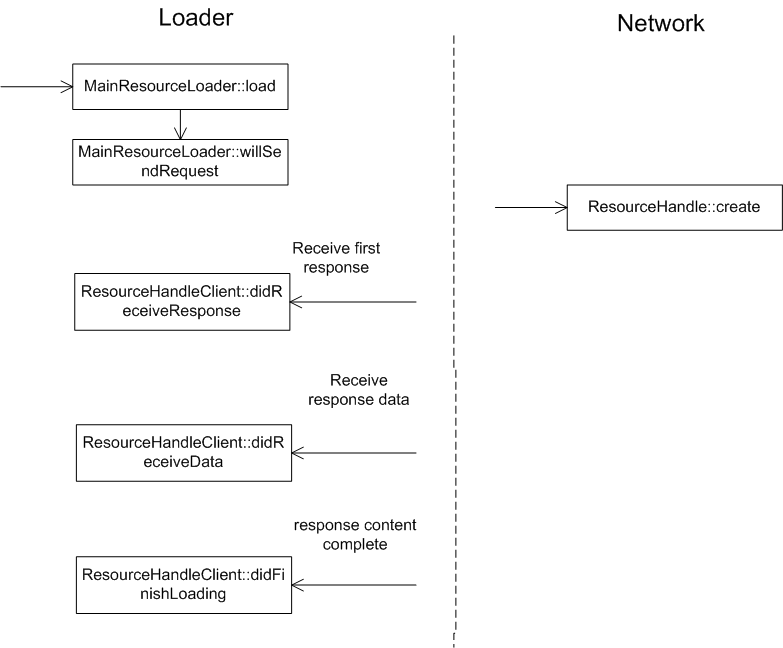
MainResourceLoader 加载的是 html 文本资源。
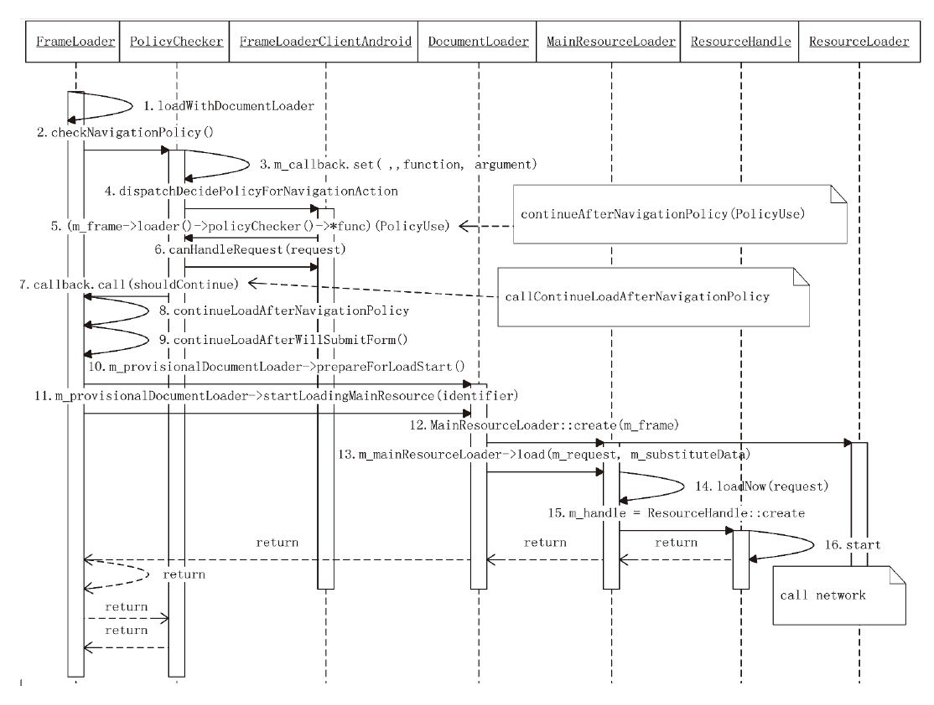
MainResourceLoader::load
MainResourceLoader::loadNow
MainResourceLoader::willSendRequest
ResourceLoader::willSendRequest //基类 ResourceLoader 会将回调通过 ResourceNotifier 传给 FrameLoaderClient 这样可以操作 ResourceRequest 来做些设置 request header 的操作。
PolicyChecker::checkNavigationPolicy //检查 NavigationPolicy 可以过滤一些重复的请求
ResourceHandle::create 开始发网络请求
MainResourceLoader::didReceiveResponse //主资源收到第一个 HTTP 的响应回调,处理 HTTP header
PolicyChecker:: checkContentPolicy //进行 ContentPolicy 的检查,通过 dispatchDecidePolicyForMIMEType 来判断是否是下载的请求
MainResourceLoader::continueAfterContentPolicy //看看 ContentPolicy 检查后是否有错误
ResourceLoader::didReceiveResponse //基类 ResourceLoader 会将回调通过 ResourceNotifier 传给 FrameLoaderClient
MainResourceLoader::didReceiveData //主资源开始接受 body 数据
ResourceLoader::didReceiveData //基类 ResourceLoader 会将回调通过 ResourceNotifier 传给 FrameLoaderClient
MainResourceLoader::addData
DocumentLoader::receivedData
DocumentLoader::commitLoad
FrameLoader::commitProvisionalLoad //从 provisional 状态到 Committed 状态
FrameLoaderClientQt::committedLoad
DocumentLoader::commitData
DocumentWriter::setEncoding
DocumentWriter::addData
DocumentParser::appendByte
DecodedDataDocumentParser::appendBytes //编码处理
HTMLDocumentParser::append //解析 HTML
MainResourceLoader::didFinishLoading
FrameLoader::finishedLoading
DocumentLoader::finishedLoading
FrameLoader::finishedLoadingDocument
DocumentWriter::end
Document::finishParsing
HTMLDocumentParser::finish在收到第一个响应包后会回调给 MainResourceLoader 的 didReceiveResponse 函数处理 Header 使用 PolicyChecker 的 checkContentPolicy 做校验,当 PolicyAction 为 PolicyUse 回调给 MainResourceLoader 的 continueAfterContentPolicy。结果 ResourceResponse 会通过 ResourceNotifier 通知给外部接受回调的不同平台的 FrameLoaderClient。
在收到后面的带数据的响应包会回调给 MainResourceLoader 的 didReceiveData,通过 ResourceLoader 的 addDataOrBuffer 把收到的数据存到 m_resourceData 里。下面是 addDataOrBuffer 方法的实现代码:
void ResourceLoader::addDataOrBuffer(const char* data, unsigned length, SharedBuffer* buffer, DataPayloadType dataPayloadType)
{
if (m_options.dataBufferingPolicy == DoNotBufferData)
return;
if (!m_resourceData || dataPayloadType == DataPayloadWholeResource) {
if (buffer)
m_resourceData = buffer;
else
m_resourceData = SharedBuffer::create(data, length);
return;
}
if (buffer)
m_resourceData->append(*buffer);
else
m_resourceData->append(data, length);
}接收到的 receiveData 会进入到 DocumentLoader 的 commitLoad 里
void DocumentLoader::commitLoad(const char* data, int length)
{
// Both unloading the old page and parsing the new page may execute JavaScript which destroys the datasource
// by starting a new load, so retain temporarily.
RefPtr<Frame> protectedFrame(m_frame);
Ref<DocumentLoader> protectedThis(*this);
commitIfReady();
FrameLoader* frameLoader = DocumentLoader::frameLoader();
if (!frameLoader)
return;
#if ENABLE(WEB_ARCHIVE) || ENABLE(MHTML)
if (ArchiveFactory::isArchiveMimeType(response().mimeType()))
return;
#endif
//FrameLoader 通过 transitionToCommitted 从 Provisional 的状态变为 Committed 状态
frameLoader->client().committedLoad(this, data, length);
if (isMultipartReplacingLoad())
frameLoader->client().didReplaceMultipartContent();
}随后 DocumentLoader 执行 commitData 将前面的内容进行编码 encoding,这些数据会通过 DocumentParser 来解码,解码后的数据 会创建 HTMLDocument 和 Document 对象,后通过 DocumentWriter 传给 DocumentParser。这个过程会在 DocumentWriter 的 begin 方法里完成,具体实现代码如下:
void DocumentWriter::begin(const URL& urlReference, bool dispatch, Document* ownerDocument)
{
// We grab a local copy of the URL because it's easy for callers to supply
// a URL that will be deallocated during the execution of this function.
// For example, see <https://bugs.webkit.org/show_bug.cgi?id=66360>.
URL url = urlReference;
// Create a new document before clearing the frame, because it may need to
// inherit an aliased security context.
//创建了 Document 对象
Ref<Document> document = createDocument(url);
// If the new document is for a Plugin but we're supposed to be sandboxed from Plugins,
// then replace the document with one whose parser will ignore the incoming data (bug 39323)
if (document->isPluginDocument() && document->isSandboxed(SandboxPlugins))
document = SinkDocument::create(m_frame, url);
// FIXME: Do we need to consult the content security policy here about blocked plug-ins?
bool shouldReuseDefaultView = m_frame->loader().stateMachine().isDisplayingInitialEmptyDocument() && m_frame->document()->isSecureTransitionTo(url);
if (shouldReuseDefaultView)
document->takeDOMWindowFrom(m_frame->document());
else
document->createDOMWindow();
// Per <http://www.w3.org/TR/upgrade-insecure-requests/>, we need to retain an ongoing set of upgraded
// requests in new navigation contexts. Although this information is present when we construct the
// Document object, it is discard in the subsequent 'clear' statements below. So, we must capture it
// so we can restore it.
HashSet<RefPtr<SecurityOrigin>> insecureNavigationRequestsToUpgrade;
if (auto* existingDocument = m_frame->document())
insecureNavigationRequestsToUpgrade = existingDocument->contentSecurityPolicy()->takeNavigationRequestsToUpgrade();
m_frame->loader().clear(document.ptr(), !shouldReuseDefaultView, !shouldReuseDefaultView);
clear();
// m_frame->loader().clear() might fire unload event which could remove the view of the document.
// Bail out if document has no view.
if (!document->view())
return;
if (!shouldReuseDefaultView)
m_frame->script().updatePlatformScriptObjects();
m_frame->loader().setOutgoingReferrer(url);
m_frame->setDocument(document.copyRef());
document->contentSecurityPolicy()->setInsecureNavigationRequestsToUpgrade(WTFMove(insecureNavigationRequestsToUpgrade));
if (m_decoder)
document->setDecoder(m_decoder.get());
if (ownerDocument) {
document->setCookieURL(ownerDocument->cookieURL());
document->setSecurityOriginPolicy(ownerDocument->securityOriginPolicy());
document->setStrictMixedContentMode(ownerDocument->isStrictMixedContentMode());
}
m_frame->loader().didBeginDocument(dispatch);
document->implicitOpen();
// We grab a reference to the parser so that we'll always send data to the
// original parser, even if the document acquires a new parser (e.g., via
// document.open).
m_parser = document->parser();
if (m_frame->view() && m_frame->loader().client().hasHTMLView())
m_frame->view()->setContentsSize(IntSize());
m_state = StartedWritingState;
}Document 对象时 DOM 树的根节点,m_writer 在 addData 时会用 DocumentParser 来解码,这个解码是在 DecodedDataDocumentParser 的 appendBytes 里做的。代码如下:
void DecodedDataDocumentParser::appendBytes(DocumentWriter& writer, const char* data, size_t length)
{
if (!length)
return;
//解码 Loader 模块传来的字节流,解码后的 String 会被 HTMLDocumentParser 的 HTMLInputStream 所持有。
String decoded = writer.createDecoderIfNeeded()->decode(data, length);
if (decoded.isEmpty())
return;
//解码成功会交给 Parser 处理生成 DOM Tree,形成 Parser 和 MainResourceLoader 同步
writer.reportDataReceived();
append(decoded.releaseImpl());
}数据接收完毕会回调 MainResourceLoader 的 didFinishLoading。接下来再调用 FrameLoader 的 finishedLoading 和 finishedLoadingDocument,调用 DocumentWriter 的 end。最后调用 Document 的 finishParsing,这样 MainResource 的加载完成。
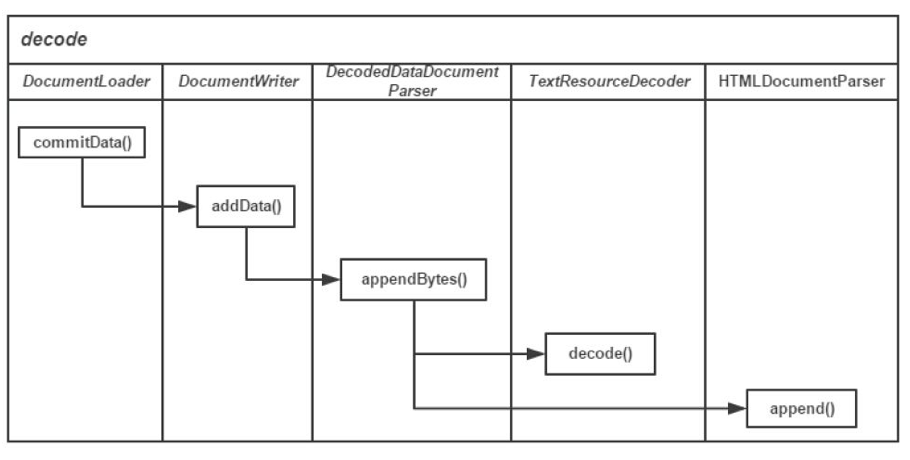
下面看看解码的流程:
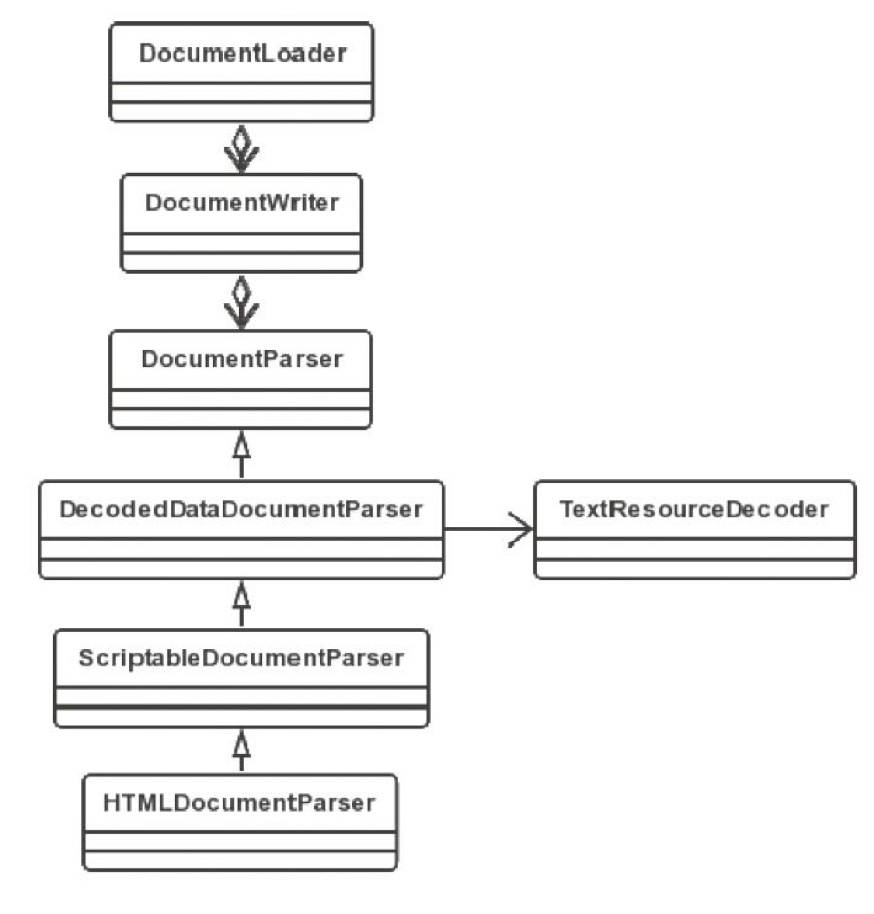
SubResourceLoader 加载的都是派生资源,加载派生资源的时序图如下:

会在创建 HTMLElement 设置 src 属性时会判断 tagName 是否是 img,是的话就会触发 SubResourceLoader。设置属性和判断的代码在 HTMLConstructionSite 这个类里,具体实现代码如下:
RefPtr<Element> HTMLConstructionSite::createHTMLElementOrFindCustomElementInterface(AtomicHTMLToken& token, JSCustomElementInterface** customElementInterface)
{
auto& localName = token.name();
// FIXME: This can't use HTMLConstructionSite::createElement because we
// have to pass the current form element. We should rework form association
// to occur after construction to allow better code sharing here.
// http://www.whatwg.org/specs/web-apps/current-work/multipage/tree-construction.html#create-an-element-for-the-token
Document& ownerDocument = ownerDocumentForCurrentNode();
bool insideTemplateElement = !ownerDocument.frame();
//将 tagName 和节点构造创建成 HTMLImageElement
RefPtr<Element> element = HTMLElementFactory::createKnownElement(localName, ownerDocument, insideTemplateElement ? nullptr : form(), true);
if (UNLIKELY(!element)) {
auto* window = ownerDocument.domWindow();
if (customElementInterface && window) {
auto* registry = window->customElementRegistry();
if (UNLIKELY(registry)) {
if (auto* elementInterface = registry->findInterface(localName)) {
*customElementInterface = elementInterface;
return nullptr;
}
}
}
QualifiedName qualifiedName(nullAtom(), localName, xhtmlNamespaceURI);
if (Document::validateCustomElementName(localName) == CustomElementNameValidationStatus::Valid) {
element = HTMLElement::create(qualifiedName, ownerDocument);
element->setIsCustomElementUpgradeCandidate();
} else
element = HTMLUnknownElement::create(qualifiedName, ownerDocument);
}
ASSERT(element);
// FIXME: This is a hack to connect images to pictures before the image has
// been inserted into the document. It can be removed once asynchronous image
// loading is working.
if (is<HTMLPictureElement>(currentNode()) && is<HTMLImageElement>(*element))
downcast<HTMLImageElement>(*element).setPictureElement(&downcast<HTMLPictureElement>(currentNode()));
//设置属性,这里会判断是否是 src,如果 element 的 tagName 是 img 就会触发派生资源下载
setAttributes(*element, token, m_parserContentPolicy);
ASSERT(element->isHTMLElement());
return element;
}在 HTMLImageElement 这个类里会用 parseAttribute 方法处理,在这个方法里判断到属性是 srcAttr 时会触发 selectImageSource 方法,方法实现如下:
void HTMLImageElement::selectImageSource()
{
// First look for the best fit source from our <picture> parent if we have one.
ImageCandidate candidate = bestFitSourceFromPictureElement();
if (candidate.isEmpty()) {
// If we don't have a <picture> or didn't find a source, then we use our own attributes.
auto sourceSize = SizesAttributeParser(attributeWithoutSynchronization(sizesAttr).string(), document()).length();
candidate = bestFitSourceForImageAttributes(document().deviceScaleFactor(), attributeWithoutSynchronization(srcAttr), attributeWithoutSynchronization(srcsetAttr), sourceSize);
}
setBestFitURLAndDPRFromImageCandidate(candidate);
//updateFromElementIgnoringPreviousError 是 ImageLoader 类的一个方法,它会调用 updateFromElement 方法来判断资源来源
m_imageLoader.updateFromElementIgnoringPreviousError();
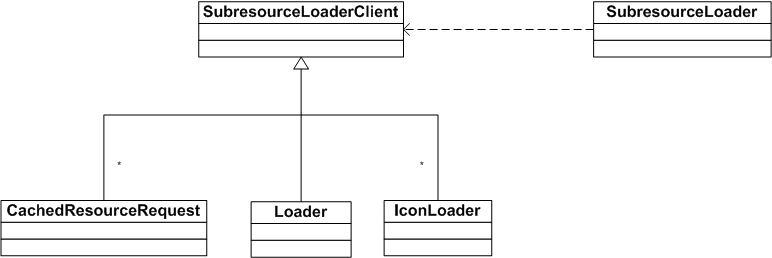
}SubResourceLoader 主要是转给 SubResourceLoaderClient 类来完成,如下图:
ResourceLoadScheduler 会对 SubResourceLoader 进行调度管理
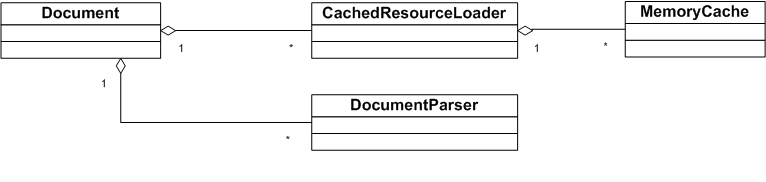
- Document:会创建拥有一个 CachedResourceLoader 类的对象实例 m_cachedResourceLoader,这个类有访问派生资源的接口,比如 requestImage,requestCSSStyleSheet,requestUserCSSStyleSheet,requestScript,requestFont,requestXSLStyleSheet,requestLinkPrefetch 等。这里 requestImage 有条件判断,这样外部实现接口就可以通过设置不加载图片,达到很多浏览器里提供那种无图模式了。
- CacheResourceLoader:会创建 CachedResourceRequest 对象发请求。在它的构造函数里会传入一个 CachedResource 对象作为参数。还会通过 m_requests 来记录资源请求数量,这样就可以把加载状态回调出去了。
- MemoryCache:会维护一个 HashMap ,里面的 value 存储 CachedResource 类缓存的内容。HashMap 定义为 HashMap <String,CachedResource> m_resources;
在 CachedResourceLoader 里会通过 resourceForUrl 在 Memory Cache 里找对应 url 对应的缓存资源,determineRevalidationPolicy 会返回一个枚举值用来确定用哪种方式加载资源:
enum RevalidationPolicy { Use, Revalidate, Reload, Load };
RevalidationPolicy determineRevalidationPolicy(CachedResource::Type, CachedResourceRequest&, CachedResource* existingResource, ForPreload, DeferOption) const;可以看到 RevalidationPolicy 有四种,Use,Revalidate,Reload 和 Load。Use 表示资源已经在缓存里可以直接使用。Revalidate 表示缓存资源已失效,需删除旧资源,重新在缓存里加新资源。Reload 表示已缓存但由于资源类型不同或者 Cache-control:no-cache 设置不用 Cache 的情况需要重新加载。Load 表示缓存里没有,需直接加载。这段逻辑处理在 CachedResourceLoader 里的 requestResource 里有实现,具体代码如下:
RevalidationPolicy policy = determineRevalidationPolicy(type, request, resource.get(), forPreload, defer);
switch (policy) {
case Reload:
memoryCache.remove(*resource);
FALLTHROUGH;
case Load:
if (resource)
logMemoryCacheResourceRequest(frame(), DiagnosticLoggingKeys::memoryCacheEntryDecisionKey(), DiagnosticLoggingKeys::unusedKey());
resource = loadResource(type, WTFMove(request));
break;
case Revalidate:
if (resource)
logMemoryCacheResourceRequest(frame(), DiagnosticLoggingKeys::memoryCacheEntryDecisionKey(), DiagnosticLoggingKeys::revalidatingKey());
resource = revalidateResource(WTFMove(request), *resource);
break;
case Use:
ASSERT(resource);
if (shouldUpdateCachedResourceWithCurrentRequest(*resource, request)) {
resource = updateCachedResourceWithCurrentRequest(*resource, WTFMove(request));
if (resource->status() != CachedResource::Status::Cached)
policy = Load;
} else {
ResourceError error;
if (!shouldContinueAfterNotifyingLoadedFromMemoryCache(request, *resource, error))
return makeUnexpected(WTFMove(error));
logMemoryCacheResourceRequest(frame(), DiagnosticLoggingKeys::memoryCacheEntryDecisionKey(), DiagnosticLoggingKeys::usedKey());
loadTiming.setResponseEnd(MonotonicTime::now());
memoryCache.resourceAccessed(*resource);
if (RuntimeEnabledFeatures::sharedFeatures().resourceTimingEnabled() && document() && !resource->isLoading()) {
auto resourceTiming = ResourceTiming::fromCache(url, request.initiatorName(), loadTiming, resource->response(), *request.origin());
if (initiatorContext == InitiatorContext::Worker) {
ASSERT(is<CachedRawResource>(resource.get()));
downcast<CachedRawResource>(resource.get())->finishedTimingForWorkerLoad(WTFMove(resourceTiming));
} else {
ASSERT(initiatorContext == InitiatorContext::Document);
m_resourceTimingInfo.storeResourceTimingInitiatorInformation(resource, request.initiatorName(), frame());
m_resourceTimingInfo.addResourceTiming(*resource.get(), *document(), WTFMove(resourceTiming));
}
}
if (forPreload == ForPreload::No)
resource->setLoadPriority(request.priority());
}
break;
}在 CachedResourceLoader 的 loadResource 方法里会通过工厂方法 createResource 来创建不同的 CacheResource。
CachedResource 加载
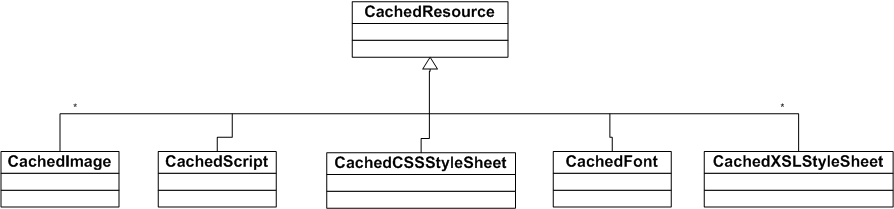
CachedResource 实现了 RFC2616 https://www.w3.org/Protocols/rfc2616/rfc2616-sec13.html 的 w3c 缓存标准,根据资源类型还派生出不同的子类如图所示:
会有一个 CachedResourceClient 的集合 m_clients 来记录所有的 CachedResource,同时 CachedResourceClientWalker 这个接口可以遍历这个集合。 CacheResource 会通过 CachedResourceClient::notifyFinished 接口来在数据都到位后来进行通知。
在 CachedResource 里 type 枚举定义了派生资源的类型,通过 defaultPriorityForResourceType 函数方法的返回可以看到各资源加载的优先级具体定义如下:
ResourceLoadPriority CachedResource::defaultPriorityForResourceType(Type type)
{
switch (type) {
case CachedResource::MainResource:
return ResourceLoadPriority::VeryHigh;
case CachedResource::CSSStyleSheet:
case CachedResource::Script:
return ResourceLoadPriority::High;
#if ENABLE(SVG_FONTS)
case CachedResource::SVGFontResource:
#endif
case CachedResource::MediaResource:
case CachedResource::FontResource:
case CachedResource::RawResource:
case CachedResource::Icon:
return ResourceLoadPriority::Medium;
case CachedResource::ImageResource:
return ResourceLoadPriority::Low;
#if ENABLE(XSLT)
case CachedResource::XSLStyleSheet:
return ResourceLoadPriority::High;
#endif
case CachedResource::SVGDocumentResource:
return ResourceLoadPriority::Low;
case CachedResource::Beacon:
return ResourceLoadPriority::VeryLow;
#if ENABLE(LINK_PREFETCH)
case CachedResource::LinkPrefetch:
return ResourceLoadPriority::VeryLow;
case CachedResource::LinkSubresource:
return ResourceLoadPriority::VeryLow;
#endif
#if ENABLE(VIDEO_TRACK)
case CachedResource::TextTrackResource:
return ResourceLoadPriority::Low;
#endif
}
ASSERT_NOT_REACHED();
return ResourceLoadPriority::Low;
}整个加载的安排是通过 WebResourceLoadScheduler 里的 scheduleLoad 通过上面返回的优先级来的。当然这些实现和平台是相关的会根据不同平台有不同的处理,具体处理如下:
void WebResourceLoadScheduler::scheduleLoad(ResourceLoader* resourceLoader)
{
ASSERT(resourceLoader);
#if PLATFORM(IOS)
// If there's a web archive resource for this URL, we don't need to schedule the load since it will never touch the network.
if (!isSuspendingPendingRequests() && resourceLoader->documentLoader()->archiveResourceForURL(resourceLoader->iOSOriginalRequest().url())) {
resourceLoader->startLoading();
return;
}
#else
if (resourceLoader->documentLoader()->archiveResourceForURL(resourceLoader->request().url())) {
resourceLoader->start();
return;
}
#endif
//根据 url 创建 host,然后加到 ResourceLoadSchedule 的 m_hosts 属性里
#if PLATFORM(IOS)
HostInformation* host = hostForURL(resourceLoader->iOSOriginalRequest().url(), CreateIfNotFound);
#else
HostInformation* host = hostForURL(resourceLoader->url(), CreateIfNotFound);
#endif
ResourceLoadPriority priority = resourceLoader->request().priority();
bool hadRequests = host->hasRequests();
//把优先级存放到 host 的 m_requestsPending 属性里
host->schedule(resourceLoader, priority);
#if PLATFORM(COCOA) || USE(CFURLCONNECTION)
if (ResourceRequest::resourcePrioritiesEnabled() && !isSuspendingPendingRequests()) {
// Serve all requests at once to keep the pipeline full at the network layer.
// FIXME: Does this code do anything useful, given that we also set maxRequestsInFlightPerHost to effectively unlimited on these platforms?
servePendingRequests(host, ResourceLoadPriority::VeryLow);
return;
}
#endif
//这里就是如何根据优先级来进行安排的
#if PLATFORM(IOS)
if ((priority > ResourceLoadPriority::Low || !resourceLoader->iOSOriginalRequest().url().protocolIsInHTTPFamily() || (priority == ResourceLoadPriority::Low && !hadRequests)) && !isSuspendingPendingRequests()) {
//重要资源立刻进行
servePendingRequests(host, priority);
return;
}
#else
if (priority > ResourceLoadPriority::Low || !resourceLoader->url().protocolIsInHTTPFamily() || (priority == ResourceLoadPriority::Low && !hadRequests)) {
//重要资源立刻进行
servePendingRequests(host, priority);
return;
}
#endif
// Handle asynchronously so early low priority requests don't
// get scheduled before later high priority ones.
//不重要的就延迟进行,然后根据优先级,由高到低依次加载
scheduleServePendingRequests();
}servePendingRequests 有两个重载实现,第一个会根据 host 来遍历,然后由第二个重载来具体实现,具体代码如下:
void WebResourceLoadScheduler::servePendingRequests(HostInformation* host, ResourceLoadPriority minimumPriority)
{
auto priority = ResourceLoadPriority::Highest;
while (true) {
auto& requestsPending = host->requestsPending(priority);
while (!requestsPending.isEmpty()) {
RefPtr<ResourceLoader> resourceLoader = requestsPending.first();
// For named hosts - which are only http(s) hosts - we should always enforce the connection limit.
// For non-named hosts - everything but http(s) - we should only enforce the limit if the document isn't done parsing
// and we don't know all stylesheets yet.
Document* document = resourceLoader->frameLoader() ? resourceLoader->frameLoader()->frame().document() : 0;
bool shouldLimitRequests = !host->name().isNull() || (document && (document->parsing() || !document->haveStylesheetsLoaded()));
if (shouldLimitRequests && host->limitRequests(priority))
return;
requestsPending.removeFirst();
host->addLoadInProgress(resourceLoader.get());
#if PLATFORM(IOS)
if (!IOSApplication::isWebProcess()) {
resourceLoader->startLoading();
return;
}
#endif
//在这个函数里创建了 ResourceHandle
resourceLoader->start();
}
if (priority == minimumPriority)
return;
--priority;
}
}加载完数据后,处理过程和 MainResource 类似,SubResourceLoader 会作为 ResourceHandle 的接受者,会接受 ResourceHandle 的回调,和 MainResource 不同的只是 Memeory Cache 部分,这部分的实现是在 SubResourceLoader 的 didReceiveData 里。实现代码如下:
void SubresourceLoader::didReceiveDataOrBuffer(const char* data, int length, RefPtr<SharedBuffer>&& buffer, long long encodedDataLength, DataPayloadType dataPayloadType)
{
ASSERT(m_resource);
if (m_resource->response().httpStatusCode() >= 400 && !m_resource->shouldIgnoreHTTPStatusCodeErrors())
return;
ASSERT(!m_resource->resourceToRevalidate());
ASSERT(!m_resource->errorOccurred());
ASSERT(m_state == Initialized);
// Reference the object in this method since the additional processing can do
// anything including removing the last reference to this object; one example of this is 3266216.
Ref<SubresourceLoader> protectedThis(*this);
//ResourceLoader 里会掉 addDataOrBuffer 会把数据存在 SubResourceLoader 的 m_resourceData 里
ResourceLoader::didReceiveDataOrBuffer(data, length, buffer.copyRef(), encodedDataLength, dataPayloadType);
if (!m_loadingMultipartContent) {
if (auto* resourceData = this->resourceData())
m_resource->addDataBuffer(*resourceData);
else
m_resource->addData(buffer ? buffer->data() : data, buffer ? buffer->size() : length);
}
}以 image 为例如图所示:
举个例子 image 加载的顺序。DocLoader 是负责子资源的加载,要加载一个图像,首先 DocLoader 要检查 Cache 中是否有对应的 CacheImage 对象,如果有就不用再次下载和解码直接用之。不在会创建一个新的 CacheImage 对象,这个 CacheImage 会要求 Loader 对象创建 SubresourceLoader 来启动网络请求。
CacheImage 的加载过程如下图:
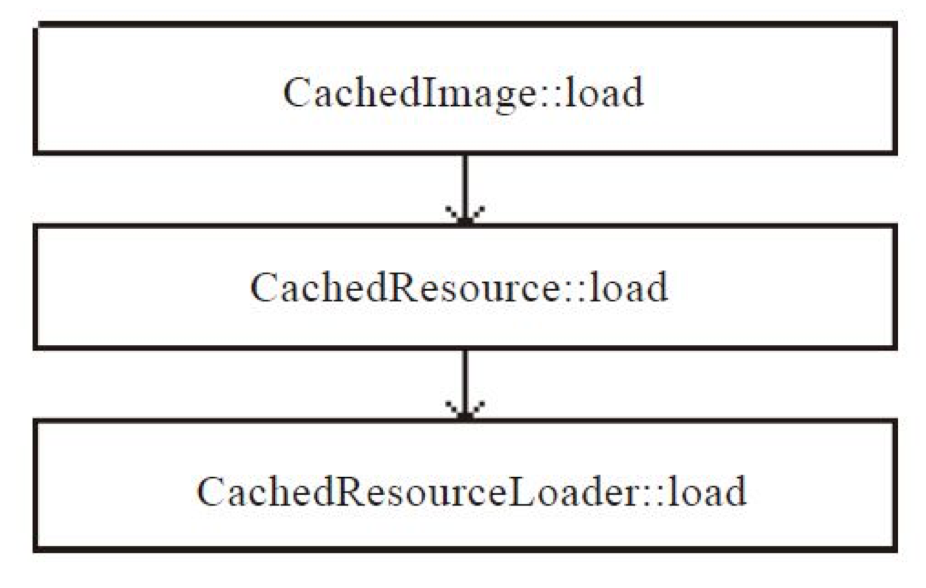
具体调用方法顺序如下:
HTMLImageElement::create //解析到 img 标签 会创建 HTMLImageElement 对象,里面包含 HTMLImageLoader 对象
ImageLoader::updateFromElementIgnoringPreviousError //解析到 img 的 href 属性
ImageLoader::updateFromElement
CachedResourceLoader::requestImage
CachedResourceLoader::requestResource //判断是否从缓存读取,还是网络获取
CachedResourceLoader::loadResource //创建不同类型的 CachedResource,这里是 CachedImage
MemoryCache::add //创建对应的 cache 项目
CachedImage::load
CachedResource::load
CachedResourceLoader::load
CachedResourceRequest::load
ResourceLoaderScheduler::scheduleSubresourceLoad
SubresourceLoader::create
ResourceLoadScheduler::requestTimerFired
ResourceLoader::start
ResourceHandle::create
ResourceLoader::didReceiveResponse //收到 HTTP Header 的 response
SubresourceLoader::didiReceiveResponse
CachedResourceRequest::didReceiveResponse //处理响应
ResourceLoader::didReceiveResponse
ResourceLoader::didReceiveData //收到 body 数据
SubresourceLoader::didReceiveData
ResourceLoader::didReceiveData
ResourceLoader::addData
CachedResourceRequest::didReceiveData
ResourceLoader::didFinishLoading //数据读取完成
SubresourceLoader::didFinishLoading
CachedResourceRequest::didFinishLoading
CachedResource::finish
CachedResourceLoader::loadDone
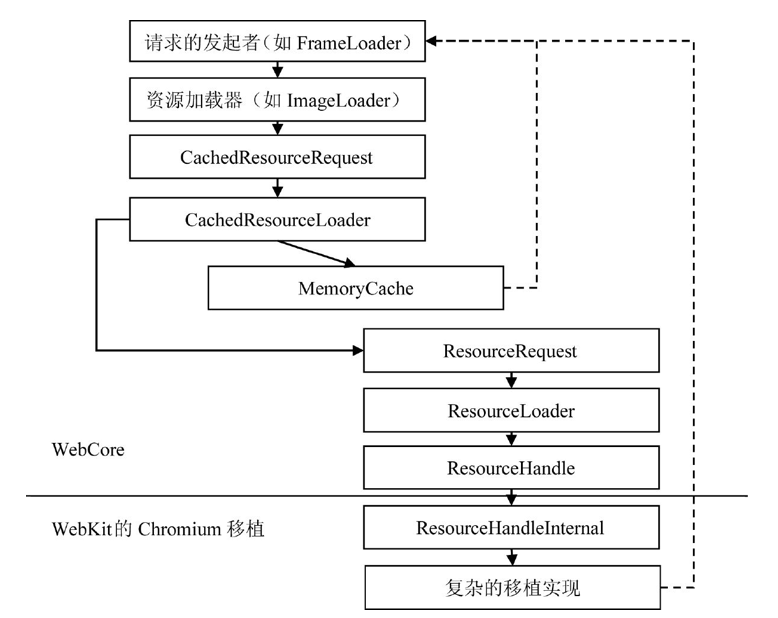
CachedImage::data //创建 Image 对象,进行解码可以用下图概括下:
资源池采用的是 Least Recent Used 最少使用算法 LRU。通过 HTTP 协议规范中更新规范来确定下次是否需要更新资源。具体做法是先判断资源是否在资源池里,在的话就发一个 HTTP 请求带上一些信息比如资源的修改时间,然后服务器根据这个信息判断是否有更新,如果没有更新就返回 304 状态码,这样就直接使用资源池的原资源,不然就下载最新资源。
WebKit 主要有三种 Cache。
对浏览页面的缓存用来使页面历史操作加速。单例模式,会有页面上限,会缓存 DOM Tree,Render Tree。在打开一个新页面的时候会在 FrameLoader 的 commitProvisionalLoad 方法里把前一个页面加入 Page Cache。截取相关代码如下:
if (!m_frame.tree().parent() && history().currentItem()) {
// Check to see if we need to cache the page we are navigating away from into the back/forward cache.
// We are doing this here because we know for sure that a new page is about to be loaded.
PageCache::singleton().addIfCacheable(*history().currentItem(), m_frame.page());
WebCore::jettisonExpensiveObjectsOnTopLevelNavigation();
}PageCache 的 addIfCacheable 会对缓存进行管理,实现代码如下:
void PageCache::addIfCacheable(HistoryItem& item, Page* page)
{
if (item.isInPageCache())
return;
if (!page || !canCache(*page))
return;
ASSERT_WITH_MESSAGE(!page->isUtilityPage(), "Utility pages such as SVGImage pages should never go into PageCache");
setPageCacheState(*page, Document::AboutToEnterPageCache);
// Focus the main frame, defocusing a focused subframe (if we have one). We do this here,
// before the page enters the page cache, while we still can dispatch DOM blur/focus events.
if (page->focusController().focusedFrame())
page->focusController().setFocusedFrame(&page->mainFrame());
// Fire the pagehide event in all frames.
firePageHideEventRecursively(page->mainFrame());
// Check that the page is still page-cacheable after firing the pagehide event. The JS event handlers
// could have altered the page in a way that could prevent caching.
if (!canCache(*page)) {
setPageCacheState(*page, Document::NotInPageCache);
return;
}
destroyRenderTree(page->mainFrame());
setPageCacheState(*page, Document::InPageCache);
// Make sure we no longer fire any JS events past this point.
NoEventDispatchAssertion assertNoEventDispatch;
//创建一个新的 CachedPage 存放到 HistoryItem 里
item.m_cachedPage = std::make_unique<CachedPage>(*page);
item.m_pruningReason = PruningReason::None;
//将 HistoryItem 添加到 m_items 列表中
m_items.add(&item);
//检查是否有超过回收的限制,进行资源回收
prune(PruningReason::ReachedMaxSize);
}当 Page 的 goBack 方法调用时会调用 FrameLoader 的 loadDifferentDocumentItem,同时加载类型设置为 FrameLoadTypeBack,然后页面将会从 Page Cache 里恢复。
使得相同 url 的资源能够快速获得。单例模式,在浏览器打开时创建,关闭时释放。关联类结构图如下:
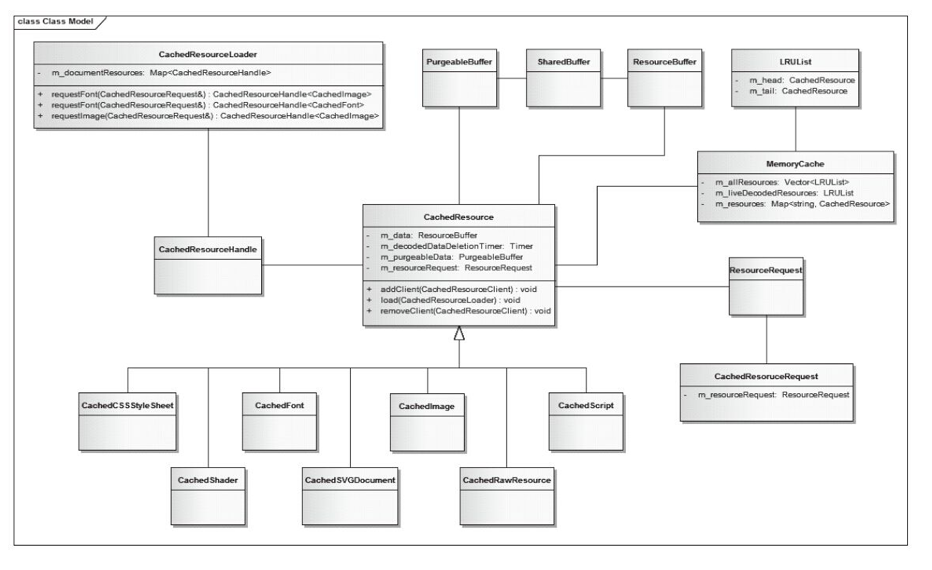
- m_resources:类型是 HashMap,key 是 url,值是 CacheResource。
- m_allResources:采用的是 LRU 算法,类型是 Vector<LRUList,32> 有 32 个向量,具体实现是在 MemeoryCache 的 lruListFor。回收资源是通过 MemoryCache 里的 prune 来的,会从链表尾开始进行回收直到空间大小达标为止。
- m_liveDecodedResource:类型为 LRUList,解码后的数据会记录在里面。
根据 HTTP 的头信息来设置缓存。属于持久化缓存存储,重新打开浏览器还能节省下载的流量和时间浪费。使用的也是 LRU 算法来控制缓存磁盘空间大小。具体实现是由平台相关代码来完成。
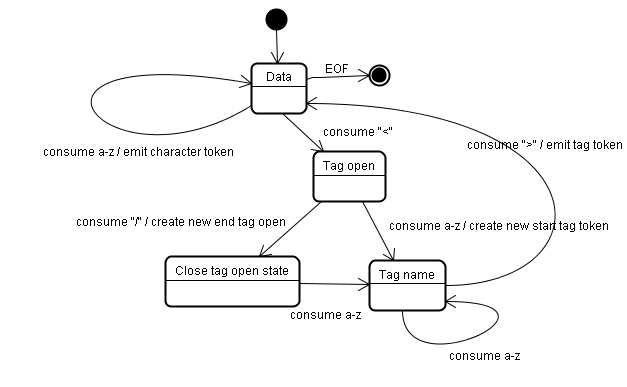
在 Tag open state 状态时如果碰到 / 字符那么就会创建 End tag token,同时状态变成 Tag name state。
在 WebKit 中有两个类是专门做词法分析的,一个是做标记的 HTMLToken,另一个是词法解析器 HTMLTokenizer 类,解析任务就是要把字节流解析成一个个 HTMLToken 给语法解析器分析。在 html 解析中一个 element 对应 三个 HTMLToken,一个是起始标签,一个是 element 内容,一个是结束标签 HTMLToken。在 DOM 树上起始结束标签对应一个 element node,内容是另一个 node。
HTMLToken 的所有类型定义在 HTMLToken.h 里
enum Type {
Uninitialized, //默认类型
DOCTYPE, //文档类型
StartTag, //起始标签
EndTag, //结束标签
Comment, //注释
Character, //元素内容
EndOfFile, //文档结束
};接下来看看 HTMLToken 的成员变量,HTMLTokenizer 类会解析出的这样的结构体。
private:
Type m_type; //那种类型
DataVector m_data; //根据类型来,不同类型内容不一样
UChar m_data8BitCheck;
// For StartTag and EndTag
bool m_selfClosing; //是否是自封闭
AttributeList m_attributes; //属性列表
Attribute* m_currentAttribute; //当前属性
// For DOCTYPE
std::unique_ptr<DoctypeData> m_doctypeData;
unsigned m_attributeBaseOffset { 0 }; // Changes across document.write() boundaries.
};在说 HTMLTokenizer 具体解析实现之前我们先了解下有限状态机。先看看数学模型

HTMLTokenizer 里的 processToken 方法具体实现了整个状态机,实现主要是根据 w3c 的 tokenization 标准来实现的:https://dev.w3.org/html5/spec-preview/tokenization.html 。html 的字符集合就是数学模型里的字母表,状态的非空集合都定义在 HTMLTokenizer.h 的 state 枚举里。state 枚举值 DataState 表示初始状态。processToken 里对不同 state 所做的 case 处理就是状态转移函数。下面是 HTMLTokenizer 里的 state 枚举:
//HTML 有限状态机的状态非空集合
enum State {
DataState, //初始状态,一般最开始和其它地方碰到 > 符号为截止再次进入这个状态。碰到字母需要设置 HTMLToken 的 type 为 character
CharacterReferenceInDataState,
RCDATAState,
CharacterReferenceInRCDATAState,
RAWTEXTState,
ScriptDataState,
PLAINTEXTState,
TagOpenState, //碰到 < 符号。如果前面的 DataState 有值需要提取值到 HTMLToken 的 m_data 里
EndTagOpenState, //TagOpenState 状态碰见 / 进入。HTMLToken 的 type 为 endTag
TagNameState, //在 TagOpenState 或 EndTagOpenState 状态碰到字母。HTMLToken 的 type 为 StartTag
RCDATALessThanSignState,
RCDATAEndTagOpenState,
RCDATAEndTagNameState,
RAWTEXTLessThanSignState,
RAWTEXTEndTagOpenState,
RAWTEXTEndTagNameState,
ScriptDataLessThanSignState,
ScriptDataEndTagOpenState,
ScriptDataEndTagNameState,
ScriptDataEscapeStartState,
ScriptDataEscapeStartDashState,
ScriptDataEscapedState,
ScriptDataEscapedDashState,
ScriptDataEscapedDashDashState,
ScriptDataEscapedLessThanSignState,
ScriptDataEscapedEndTagOpenState,
ScriptDataEscapedEndTagNameState,
ScriptDataDoubleEscapeStartState,
ScriptDataDoubleEscapedState,
ScriptDataDoubleEscapedDashState,
ScriptDataDoubleEscapedDashDashState,
ScriptDataDoubleEscapedLessThanSignState,
ScriptDataDoubleEscapeEndState,
BeforeAttributeNameState, //TagNameState 碰到空格。HTMLToken 的 m_data 会记录前面的 tagname
AttributeNameState, //BeforeAttributeNameState 碰见字母进入
AfterAttributeNameState,
BeforeAttributeValueState, //AttributeNameState 状态碰到 = 会进入,同时会在 HTMLToken 属性列表里增加一个属性,属性名为前面状态记录的
AttributeValueDoubleQuotedState, //BeforeAttributeValueState 碰到 " 符号
AttributeValueSingleQuotedState, //BeforeAttributeValueState 碰到 ' 符号
AttributeValueUnquotedState,
CharacterReferenceInAttributeValueState,
AfterAttributeValueQuotedState, // 再次碰到 " 或 ' 符号。HTMLToken 记录属性的值
SelfClosingStartTagState,
BogusCommentState,
ContinueBogusCommentState, // Not in the HTML spec, used internally to track whether we started the bogus comment token.
MarkupDeclarationOpenState, //TagOpenState 后遇到! 比如<!
//解析comment
CommentStartState, //MarkupDeclarationOpenState 状态后跟了两个 - 比如 <!-- 。HTMLToken 的 type 为 COMMENT
CommentStartDashState,
CommentState, //CommentStartState 碰到字母进入这个状态
CommentEndDashState, //在 CommentState 状态碰见 - 进入。HTMLToken 的 m_data 为 前面记录的 comment 内容
CommentEndState, //在 CommentEndDashState 状态碰见 - 进入
CommentEndBangState,
//解析 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> 这种标签
DOCTYPEState, //匹配到 DOCTYPE,<!DOCTYPE
BeforeDOCTYPENameState, //DOCTYPE 状态后遇到空格
DOCTYPENameState, //BeforeDOCTYPENameState 状态遇到字母,提取 html。HTMLToken 的 m_data 为 html
AfterDOCTYPENameState, //DOCTYPENameState 遇到空格 <!DOCTYPE html
AfterDOCTYPEPublicKeywordState, //AfterDOCTYPENameState 后匹配到 public。<!DOCTYPE html PUBLIC
BeforeDOCTYPEPublicIdentifierState, //AfterDOCTYPEPublicKeywordState 状态后碰到空格
DOCTYPEPublicIdentifierDoubleQuotedState, //BeforeDOCTYPEPublicIdentifierState 状态碰到 " 进入
DOCTYPEPublicIdentifierSingleQuotedState, //BeforeDOCTYPEPublicIdentifierState 状态碰到 ' 进入
AfterDOCTYPEPublicIdentifierState, //再次遇到 " 或 ' 。可将 HTMLToken 的 m_publicIdentifier 确定
BetweenDOCTYPEPublicAndSystemIdentifiersState,
AfterDOCTYPESystemKeywordState,
BeforeDOCTYPESystemIdentifierState,
DOCTYPESystemIdentifierDoubleQuotedState,
DOCTYPESystemIdentifierSingleQuotedState,
AfterDOCTYPESystemIdentifierState,
BogusDOCTYPEState,
CDATASectionState,
// These CDATA states are not in the HTML5 spec, but we use them internally.
CDATASectionRightSquareBracketState,
CDATASectionDoubleRightSquareBracketState,
};词法解析主要接口是 nextToken 函数,下图展示了 HTMLTokenizer 的主要工作流程:
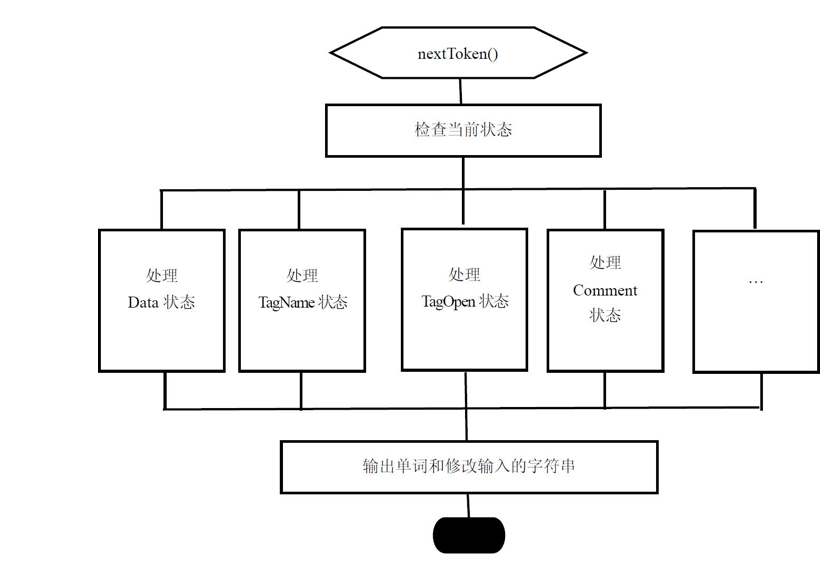
HTML 的语法规范是由 w3c 组织创建和定义的。语法语句可以使用正式的比如 BNF 来定义,不过对于 html 这种会在创建后允许再插入代码的语言 w3c 使用了 DTD 来定义 HTML,定义的文件可以在这里:https://www.w3.org/TR/html4/strict.dtd
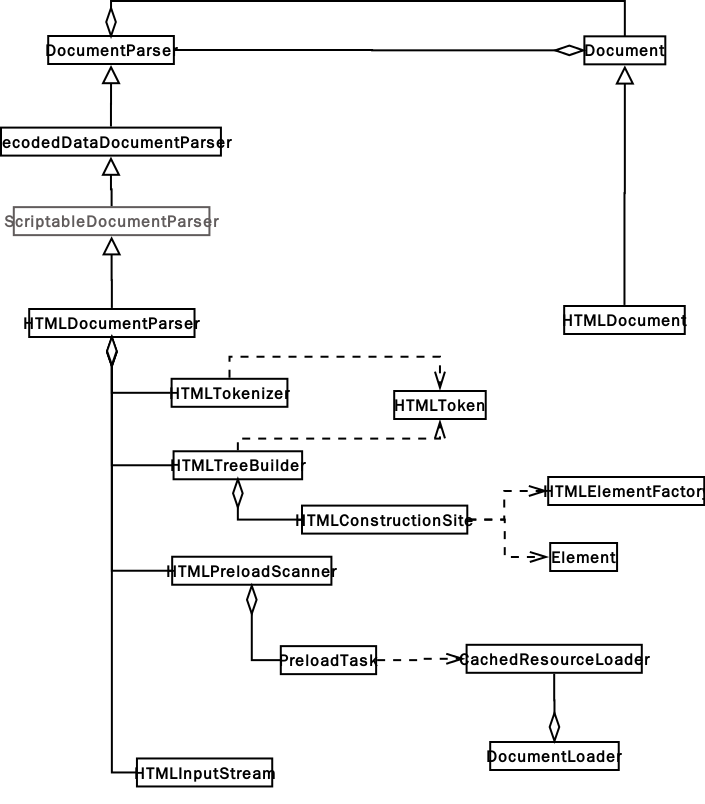
- Document 和 DocumentParser 相互引用
- HTMLDocumentParser 父类是 ScriptableDocumentParser,DecodedDataDocumentParser(字符解码功能) 最后是 DocumentParser。
- HTMLInputStream:解码后的字符流的保存,作为缓冲区。
- HTMLTokenizer:对字符流进行解析,将解析后的信息比如 tag 名属性列表,注释,Doc 声明,结束 tag,文本都存在 HTMLToken 类中。
- HTMLTreeBuilder:生成 DOM Tree,这里会做些语义上的检查,比如 head tag 里不能包含 body tag。
- HTMLToken:HTMLTokenizer 生成,HTMLTreeBuilder 来使用
- HTMLConstructionSite:创建各种 HTMLElement,再完成 DOM Tree,关键标签比如 body,head 和 html 以外都是通过 HTMLElementFactory 来实现。属性使用生成的 Element 里对应的函数来实现。
- HTMLPreloadScanner:专门用来查找类似 src,link 这样的属性,获取外部资源,通过 CachedResourceLoader 这个类进行加载。
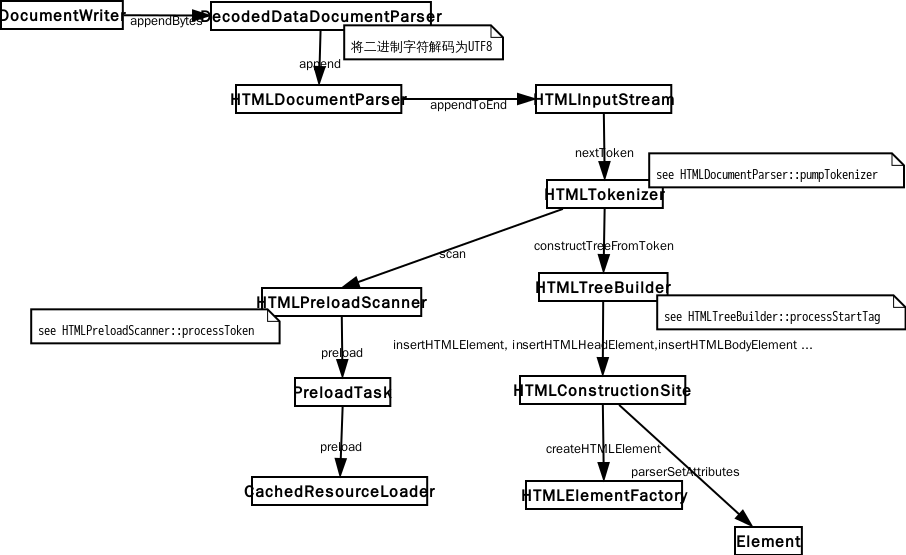
-
DocumentWriter 调用 DocumentParser::appendBytes 将结果存入 HTMLInputStream 中。
-
HTMLDocumentParser::pumpTokenizer 函数里的 nextToken 会把字符流解析成 HTMLToken。
-
把 HTMLToken 对象交给 HTMLTreeBuild,通过 HTMLTreeBuild::processToken 来分析标签是否 OK,再用 HTMLConstructionSite 的 insertHTMLElement,insertHTMLHeadElement 来插入到 HTMLConstructionSite 里,原理是 stack of open elements 栈的方式构造,具体可以看这里:https://html.spec.whatwg.org/multipage/parsing.html#the-stack-of-open-elements。HTMLConstructionSite 通过 HTMLElementFactory 里的 createHTMLElement 来创建 HTMLElement 对象。Element 的 parserSetAttributes 函数用来解析属性。创建完一个 Element 会被加到当前 Node 里,通过 HTMLConstructionSite 的 attachLater 函数异步完成。
-
然后 HTMLToken 对象还会交给 HTMLPreloadScanner,它会先调用 scan 函数,生成一个 PreloadTask,调用 preload 函数或 CachedResourceLoader 的 preload 进行资源预加载。在 CachedResourceLoader 里的资源是以 url 作为 key,通过 url 来获取资源。具体实现可以看 HTMLPreloadScanner::processToken。
是通过 Element::parserSetAttributes 来设置的
void Element::parserSetAttributes(const Vector<Attribute>& attributeVector)
{
ASSERT(!isConnected());
ASSERT(!parentNode());
ASSERT(!m_elementData);
if (!attributeVector.isEmpty()) {
if (document().sharedObjectPool())
m_elementData = document().sharedObjectPool()->cachedShareableElementDataWithAttributes(attributeVector);
else
m_elementData = ShareableElementData::createWithAttributes(attributeVector);
}
parserDidSetAttributes();
// Use attributeVector instead of m_elementData because attributeChanged might modify m_elementData.
for (const auto& attribute : attributeVector)
attributeChanged(attribute.name(), nullAtom(), attribute.value(), ModifiedDirectly);
}m_attributeData 存储属性的对象,attributeChange 函数会调用 parseAttribute 函数,作用是让 Element 能够处理 src 这样的属性加载图片
HTMLPreloadScanner 调用 CachedResourceLoader 来加载的。
构建 DOM Tree 需要经过的四个阶段,分别是解码,分词,解析(创建与 Tag 相对应的 Node),创建树(有 DOM Tree,Render Tree,RenderLayer Tree)
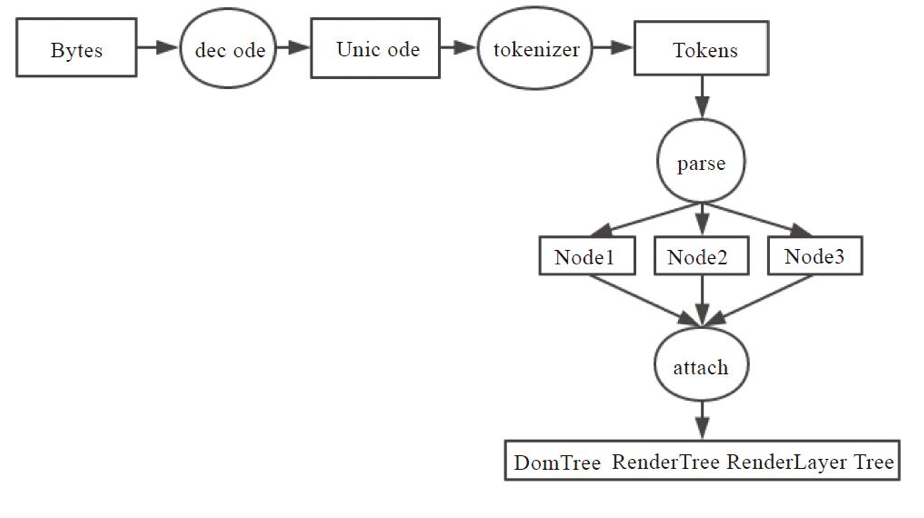
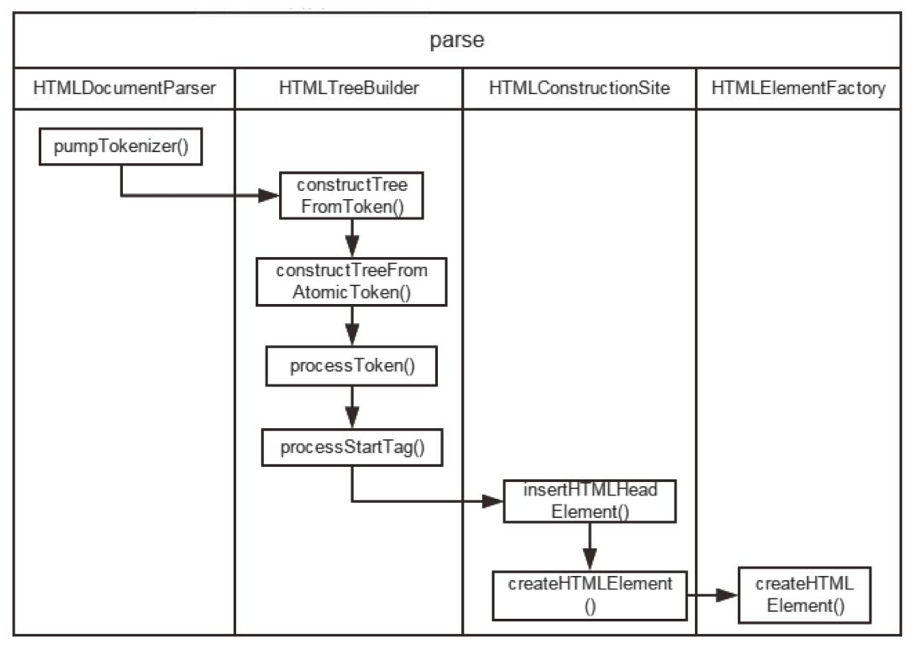
前三个阶段前面已经介绍,下面主要介绍下创建 DOM 树
Document Object Model 简称 DOM,全称文档对象模型,可以是 HTML,XML 和 XHTML,DOM 是以面向对象的方式来描述文档的,这样可以通过 JavaScript 或其它面向对象的语言进行访问,创建,删除和修改 DOM 结构。DOM 的接口与平台和语言无关。W3C 定义了一系列的 DOM 接口,目前已经有了四个 level 标准,每个标准都是基于上个标准基础上进行的迭代,如下图是 DOM 规范的演进过程:
- Core:底层接口,接口支持 XML 等任何结构化文档。
- HTML:把 HTML 内容定义为 Document 文档,Node 节点,Attribute 属性,Element 元素,Text 文本。
DOM level 2
- Core:对 level 1 的 Core 部分进行扩展,比如 getElementById,还有 namespace 的接口。
- HTML:允许动态访问修改文档。
- Views:文档的各种视图。
- Events:鼠标事件等。
- Style:可以修改 HTML 样式的一个属性。
- Traveral and range:NodeIterator 和 TreeWalker 遍历树对文档修改,删除等操作。
节点DOM level 3
- Core:加入了新接口 adoptNode 和 textContent。
- Load and Save:加载 XML 转成 DOM 表示的文档结构。
- Validation:验证文档有效性。
- Events:加入键盘支持。
- XPath:一种简单直观检索 DOM 节点的方式。
DOM 结构构成的基本要素是节点,节点概念比较大,Document 也是一个节点,叫 Document 节点,HTML 里的 Tag 也是一种节点,叫 Element 节点,还有属性节点,Entity 节点,ProcessingIntruction 节点,CDataSection 节点,Comment 节点。下面看看 Document 节点提供的接口,这个接口的描述文件路径是在 WebCore/dom/Document.idl 文件里
interface Document : Node {
readonly attribute DOMImplementation implementation; // FIXME: Should be [SameObject].
[ImplementedAs=urlForBindings] readonly attribute USVString URL;
[ImplementedAs=urlForBindings] readonly attribute USVString documentURI;
readonly attribute USVString origin;
readonly attribute DOMString compatMode;
[ImplementedAs=characterSetWithUTF8Fallback] readonly attribute DOMString characterSet;
[ImplementedAs=characterSetWithUTF8Fallback] readonly attribute DOMString charset; // Historical alias of .characterSet,
[ImplementedAs=characterSetWithUTF8Fallback] readonly attribute DOMString inputEncoding; // Historical alias of .characterSet.
readonly attribute DOMString contentType;
readonly attribute DocumentType? doctype;
[DOMJIT=Getter] readonly attribute Element? documentElement;
HTMLCollection getElementsByTagName(DOMString qualifiedName);
HTMLCollection getElementsByTagNameNS(DOMString? namespaceURI, DOMString localName);
HTMLCollection getElementsByClassName(DOMString classNames);
[NewObject, MayThrowException, ImplementedAs=createElementForBindings] Element createElement(DOMString localName); // FIXME: missing options parameter.
[NewObject, MayThrowException] Element createElementNS(DOMString? namespaceURI, DOMString qualifiedName); // FIXME: missing options parameter.
[NewObject] DocumentFragment createDocumentFragment();
[NewObject] Text createTextNode(DOMString data);
[NewObject, MayThrowException] CDATASection createCDATASection(DOMString data);
[NewObject] Comment createComment(DOMString data);
[NewObject, MayThrowException] ProcessingInstruction createProcessingInstruction(DOMString target, DOMString data);
[CEReactions, MayThrowException, NewObject] Node importNode(Node node, optional boolean deep = false);
[CEReactions, MayThrowException] Node adoptNode(Node node);
[NewObject, MayThrowException] Attr createAttribute(DOMString localName);
[NewObject, MayThrowException] Attr createAttributeNS(DOMString? namespaceURI, DOMString qualifiedName);
[MayThrowException, NewObject] Event createEvent(DOMString type);
[NewObject] Range createRange();
// NodeFilter.SHOW_ALL = 0xFFFFFFFF.
[NewObject] NodeIterator createNodeIterator(Node root, optional unsigned long whatToShow = 0xFFFFFFFF, optional NodeFilter? filter = null);
[NewObject] TreeWalker createTreeWalker(Node root, optional unsigned long whatToShow = 0xFFFFFFFF, optional NodeFilter? filter = null);
// Extensions from HTML specification (https://html.spec.whatwg.org/#the-document-object).
[PutForwards=href, Unforgeable] readonly attribute Location? location;
[SetterMayThrowException] attribute USVString domain;
readonly attribute USVString referrer;
[GetterMayThrowException, SetterMayThrowException] attribute USVString cookie;
readonly attribute DOMString lastModified;
readonly attribute DocumentReadyState readyState;
// DOM tree accessors.
[CEReactions] attribute DOMString title;
[CEReactions] attribute DOMString dir;
[CEReactions, DOMJIT=Getter, ImplementedAs=bodyOrFrameset, SetterMayThrowException] attribute HTMLElement? body;
readonly attribute HTMLHeadElement? head;
readonly attribute HTMLCollection images; // Should be [SameObject].
readonly attribute HTMLCollection embeds; // Should be [SameObject].
readonly attribute HTMLCollection plugins; // Should be [SameObject].
readonly attribute HTMLCollection links; // Should be [SameObject].
readonly attribute HTMLCollection forms; // Should be [SameObject].
readonly attribute HTMLCollection scripts; // Should be [SameObject].
NodeList getElementsByName([AtomicString] DOMString elementName);
readonly attribute HTMLScriptElement? currentScript; // FIXME: Should return a HTMLOrSVGScriptElement.
// dynamic markup insertion
// FIXME: The HTML spec says this should consult the "responsible document". We should ensure
// that the caller document matches those semantics. It is possible we should replace it with
// the existing 'incumbent document' concept.
[CEReactions, CallWith=ResponsibleDocument, ImplementedAs=openForBindings, MayThrowException] Document open(optional DOMString type = "text/html", optional DOMString replace = "");
[CallWith=ActiveWindow&FirstWindow, ImplementedAs=openForBindings, MayThrowException] DOMWindow open(USVString url, DOMString name, DOMString features);
[CEReactions, ImplementedAs=closeForBindings, MayThrowException] void close();
[CEReactions, CallWith=ResponsibleDocument, MayThrowException] void write(DOMString... text);
[CEReactions, CallWith=ResponsibleDocument, MayThrowException] void writeln(DOMString... text);
// User interaction.
readonly attribute DOMWindow? defaultView;
boolean hasFocus();
[CEReactions] attribute DOMString designMode;
[CEReactions] boolean execCommand(DOMString commandId, optional boolean showUI = false, optional DOMString? value = null); // FIXME: value should not be nullable.
boolean queryCommandEnabled(DOMString commandId);
boolean queryCommandIndeterm(DOMString commandId);
boolean queryCommandState(DOMString commandId);
boolean queryCommandSupported(DOMString commandId);
DOMString queryCommandValue(DOMString commandId);
// Special event handler IDL attributes that only apply to Document objects.
[LenientThis] attribute EventHandler onreadystatechange;
// Extensions from the CSSOM specification (https://drafts.csswg.org/cssom/#extensions-to-the-document-interface).
// FIXME: Should likely be moved to DocumentOrShadowRoot.
readonly attribute StyleSheetList styleSheets; // FIXME: Should be [SameObject].
// Extensions from the CSSOM-View specification (https://drafts.csswg.org/cssom-view/#extensions-to-the-document-interface).
readonly attribute Element? scrollingElement;
// Extensions from Selection API (https://www.w3.org/TR/selection-api/#extensions-to-document-interface).
// FIXME: Should likely be moved to DocumentOrShadowRoot.
DOMSelection? getSelection();
// XPath extensions (https://www.w3.org/TR/DOM-Level-3-XPath/xpath.html#XPathEvaluator).
[MayThrowException] XPathExpression createExpression(optional DOMString expression = "undefined", optional XPathNSResolver? resolver); // FIXME: Using "undefined" as default parameter value is wrong.
XPathNSResolver createNSResolver(Node? nodeResolver);
[MayThrowException] XPathResult evaluate(optional DOMString expression = "undefined", optional Node? contextNode, optional XPathNSResolver? resolver, optional unsigned short type = 0, optional XPathResult? inResult); // FIXME: Using "undefined" as default parameter value is wrong.
// Extensions from FullScreen API (https://fullscreen.spec.whatwg.org/#api).
// FIXME: Should probably be unprefixed.
[Conditional=FULLSCREEN_API] readonly attribute boolean webkitFullscreenEnabled;
[Conditional=FULLSCREEN_API, ImplementedAs=webkitFullscreenElementForBindings] readonly attribute Element? webkitFullscreenElement;
[Conditional=FULLSCREEN_API] void webkitExitFullscreen();
[Conditional=FULLSCREEN_API] readonly attribute boolean webkitIsFullScreen; // Mozilla version.
[Conditional=FULLSCREEN_API] readonly attribute boolean webkitFullScreenKeyboardInputAllowed; // Mozilla version.
[Conditional=FULLSCREEN_API, ImplementedAs=webkitCurrentFullScreenElementForBindings] readonly attribute Element webkitCurrentFullScreenElement; // Mozilla version.
[Conditional=FULLSCREEN_API] void webkitCancelFullScreen(); // Mozilla version.
[NotEnumerable, Conditional=FULLSCREEN_API] attribute EventHandler onwebkitfullscreenchange;
[NotEnumerable, Conditional=FULLSCREEN_API] attribute EventHandler onwebkitfullscreenerror;
// Extensions from Pointer Lock API (https://www.w3.org/TR/pointerlock/#extensions-to-the-document-interface).
[NotEnumerable, Conditional=POINTER_LOCK] attribute EventHandler onpointerlockchange; // FIXME: Should be enumerable.
[NotEnumerable, Conditional=POINTER_LOCK] attribute EventHandler onpointerlockerror; // FIXME: Should be enumerable.
[Conditional=POINTER_LOCK] void exitPointerLock();
// Extensions from CSS Font Loading API (https://drafts.csswg.org/css-font-loading/#font-face-source).
// FIXME: Should be in a separate FontFaceSource interface.
readonly attribute FontFaceSet fonts;
// Extensions from Page visibility API (https://www.w3.org/TR/page-visibility/#sec-document-interface).
readonly attribute boolean hidden;
readonly attribute VisibilityState visibilityState;
attribute EventHandler onvisibilitychange;
// FIXME: Those were dropped from the CSSOM specification.
readonly attribute DOMString? preferredStylesheetSet;
attribute DOMString? selectedStylesheetSet;
// FIXME: Those have been dropped from the DOM specification.
readonly attribute DOMString? xmlEncoding;
[SetterMayThrowException] attribute DOMString? xmlVersion;
attribute boolean xmlStandalone;
// FIXME: Blink has already dropped this (https://groups.google.com/a/chromium.org/forum/#!topic/blink-dev/s3ezjTuC8ig).
CSSStyleDeclaration getOverrideStyle(optional Element? element = null, optional DOMString pseudoElement = "undefined");
// FIXME: Should be moved to GlobalEventHandlers (http://w3c.github.io/selection-api/#extensions-to-globaleventhandlers).
[NotEnumerable] attribute EventHandler onselectstart; // FIXME: Should be enumerable.
[NotEnumerable] attribute EventHandler onselectionchange; // FIXME: Should be enumerable.
// Non standard: It has been superseeded by caretPositionFromPoint which we do not implement yet.
Range caretRangeFromPoint(optional long x = 0, optional long y = 0);
// FIXME: This is not standard and has been dropped from Blink already.
RenderingContext? getCSSCanvasContext(DOMString contextId, DOMString name, long width, long height);
// Non standard (https://developer.apple.com/reference/webkitjs/document/1633863-webkitgetnamedflows).
[Conditional=CSS_REGIONS] DOMNamedFlowCollection webkitGetNamedFlows();
// Obsolete features from https://html.spec.whatwg.org/multipage/obsolete.html
[CEReactions] attribute [TreatNullAs=EmptyString] DOMString fgColor;
[CEReactions, ImplementedAs=linkColorForBindings] attribute [TreatNullAs=EmptyString] DOMString linkColor;
[CEReactions] attribute [TreatNullAs=EmptyString] DOMString vlinkColor;
[CEReactions] attribute [TreatNullAs=EmptyString] DOMString alinkColor;
[CEReactions] attribute [TreatNullAs=EmptyString] DOMString bgColor;
readonly attribute HTMLCollection anchors; /* [SameObject] */
readonly attribute HTMLCollection applets; /* [SameObject] */
void clear();
void captureEvents();
void releaseEvents();
[Replaceable] readonly attribute HTMLAllCollection all; /* [SameObject] */
};这个算法被描述为一个 state machine,state 为插入模式(insertion modes)。完整算法可以参看 w3c 的定义:https://www.w3.org/TR/html5/syntax.html#html-parser
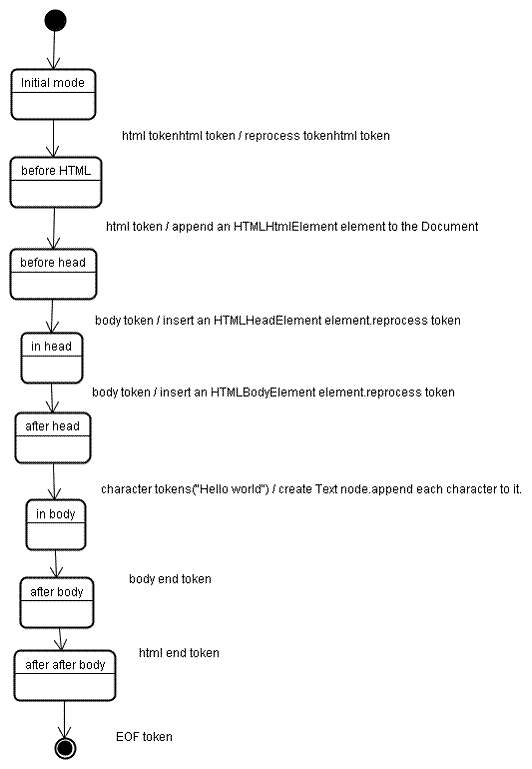
具体过程是,在 tree construction 阶段的输入是来自 tokenization 的 tokens 排序的阶段。最开始的状态是 initial mode。接收 html token 会变成 before html mode,并且在那个模式里重新处理 token。这会创建一个 HTMLHtmlElement 元素添加到 Document 对象的 root 上。
接下来状态会变成 before head。然后创建 HTMLHeadElement,如果 head 里有 token 就会被添加到这个 tree 里。状态会有 in head 和 after head。
再后面会创建 HTMLBodyElement,添加到树中,状态转成 in body,里面的 html token 会被转成对应的 DOM element 被添加到 body 的 node 中。当收到 body end token 会让状态切换成 after body。接着就是收到 html end tag,转成 after after body 状态,接到 end of file token 会结束 parsing。
构建 DOM 的几个关键的类
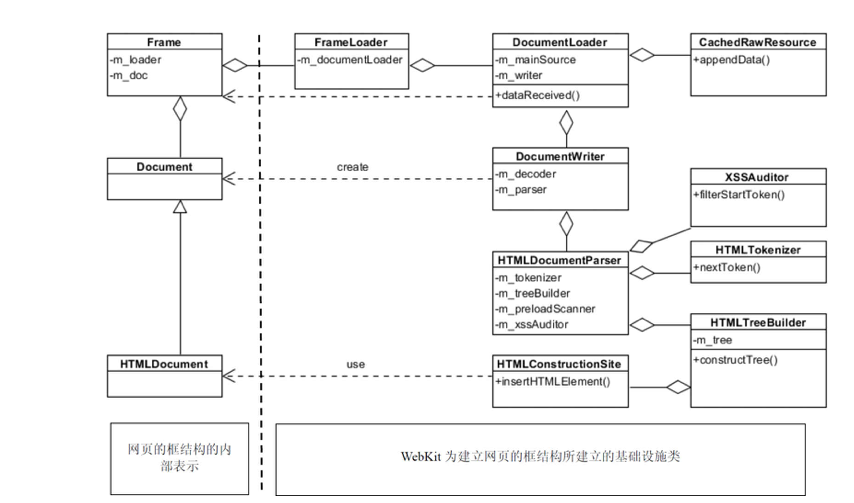
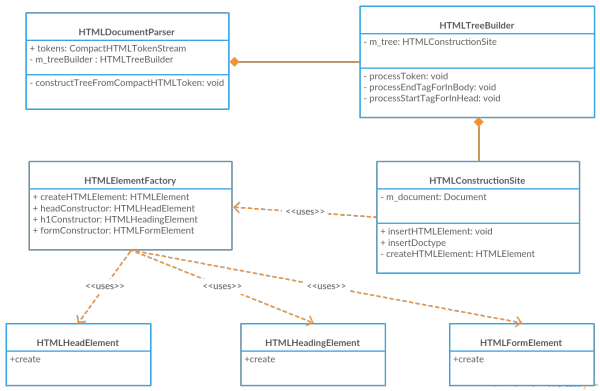
- HTMLDocumentParser:管理类,解析 html 文本使用词法分析器成 HTMLTokenizer 类,最后输出到 HTMLTreeBuilder。
- HTMLTreeBuilder:负责 DOM 树的建立,对 tokens 分类处理,创建一个个节点对象,使用 HTMLConstructionSite 类将这些创建好的节点构建为 DOM 树。
- HTMLConstructionSite:不同的标签类型在不同位置会有不同的函数来构建 DOM 树。m_document 代表根节点,即 javascript 里的 window.document 对象。
- HTMLElementFactory:一个工厂类对不同类型的标签创建不同的 html 元素,同时建立父子兄弟关系。
构建 DOM 树的过程如下图:
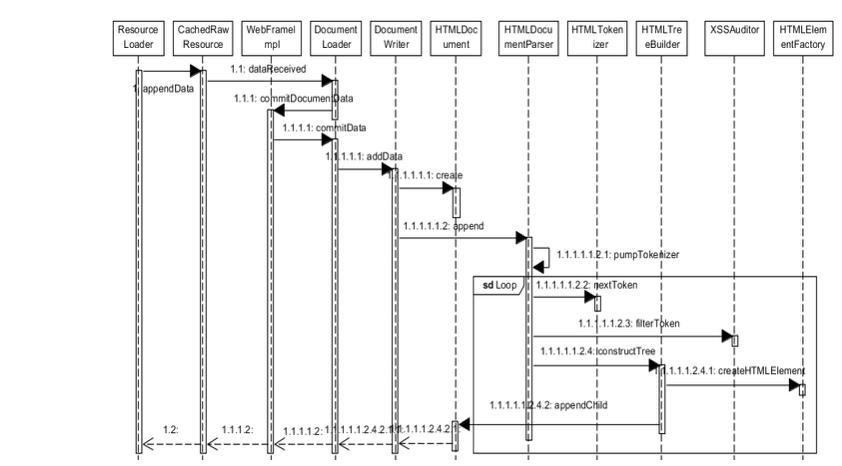
举个例子:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>转成 DOM Tree 如下:
通过 DocumentLoader 这个类里的 startLoadingMainResource 加载 url
FetchRequest fetchRequest(m_request, FetchInitiatorTypeNames::document,
mainResourceLoadOptions);
m_mainResource =
RawResource::fetchMainResource(fetchRequest, fetcher(), m_substituteData);DocumentLoader 的 commitData 会去处理 dataReceived 的数据块
void DocumentLoader::commitData(const char* bytes, size_t length) {
ensureWriter(m_response.mimeType()); //会初始化 HTMLDocumentParser 实例化 document 对象
if (length)
m_dataReceived = true;
m_writer->addData(bytes, length); //给 Parser 解析,这里的bytes就是返回来的 html 文本代码
}
//ensureWriter 里有个判断,如果 m_writer 已经初始化就不处理,所以 parser 只会初始化一次
void DocumentLoader::ensureWriter(const AtomicString& mimeType, const KURL& overridingURL) {
if (m_writer)
return;
}DOM Tree 已经被 W3 标准化了 Document Object Model (DOM) Technical Reports 在 DOM Level 3 里 IDL 的定义在 IDL Definitions
Node 是 DOM 模型的基础类,根据标签的不同可以分成多个类,详细的定义可以看 NodeType,最主要的是 Document,Element 和 Text 三类。下图列出了 Node 节点相关继承关系图:
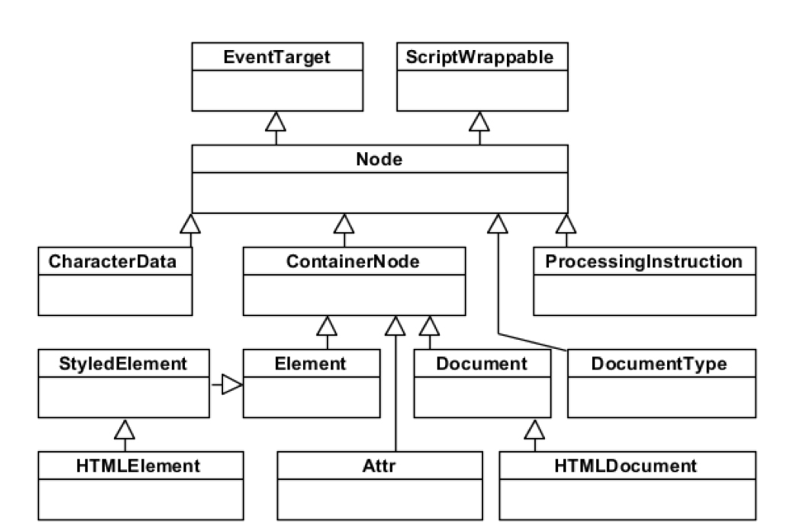
在构建树时是由 Insertion Mode 来控制,这个规则是完全按照 w3c 指定,可以参看:http://www.whatwg.org/specs/web-apps/current-work/multipage/parsing.html#the-insertion-mode 。构建树级别时是根据堆栈来的,碰到 StartTag 的 token 就会在 m_opnElements 里压栈,碰到 EndTag 的 token 就会出栈。 w3c 对于 Element 的堆栈也有规范:https://html.spec.whatwg.org/multipage/parsing.html#the-stack-of-open-elements 。通过 ContainerNode::parserAddChild 接口添加 Node 到 DOM Tree 中。
需要注意的是有些标签属于 Format 标签不参与嵌套关系属于平级,是不会被加入到 m_openElements 里。这些标签的定义可以参看:https://html.spec.whatwg.org/multipage/parsing.html#list-of-active-formatting-elements
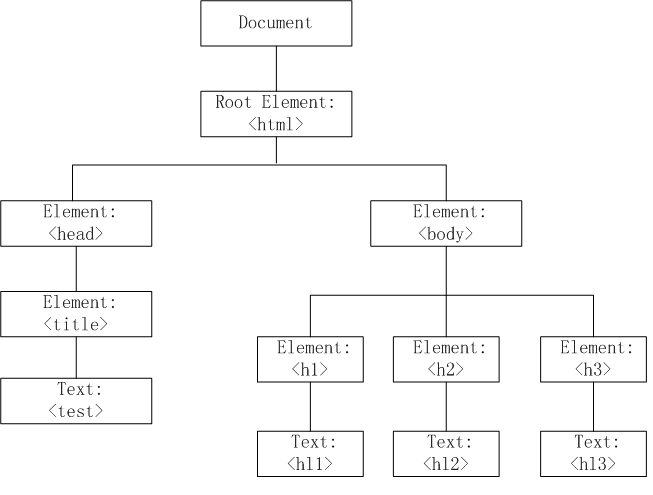
DOM Node 的数据结构
由 HTMLElementFactory 类的 createHTMLElement 来创建,然后通过 Hash map 来记录,key 为 tag name,value 为对应的 element。不同 tag 有不同的 HTMLElement 派生类,类继承图如下:
从 Token 的构建节点。是 HTMLDocumentParser 类调用了 HTMLTreeBuilder 类的 processToken 函数来处理的,该函数在 WebCore/html/parser/HTMLTreeBuilder.cpp 文件里。 constructtreefromToken
void HTMLTreeBuilder::processToken(AtomicHTMLToken&& token)
{
switch (token.type()) {
case HTMLToken::Uninitialized:
ASSERT_NOT_REACHED();
break;
case HTMLToken::DOCTYPE:
m_shouldSkipLeadingNewline = false;
processDoctypeToken(WTFMove(token));
break;
case HTMLToken::StartTag:
m_shouldSkipLeadingNewline = false;
processStartTag(WTFMove(token));
break;
case HTMLToken::EndTag:
m_shouldSkipLeadingNewline = false;
processEndTag(WTFMove(token));
break;
case HTMLToken::Comment:
m_shouldSkipLeadingNewline = false;
processComment(WTFMove(token));
return;
case HTMLToken::Character:
processCharacter(WTFMove(token));
break;
case HTMLToken::EndOfFile:
m_shouldSkipLeadingNewline = false;
processEndOfFile(WTFMove(token));
break;
}
}将节点构建成 DOM Tree,还有给 Tree 的元素节点创建属性节点都是 HTMLConstructionSite 这个类来做的,它会通过 insert 类函数一次将 Token 类型创建的 HTMLElement 对象加入到 DOM Tree。这个类会会先创建一个 html 根节点 HTMLDocument 对象和一个栈 HTMLElementStack 变量,栈里存放没有遇到 EndTag 的 所有 StartTag。根据这个栈来建立父子关系。
void HTMLConstructionSite::insertHTMLHtmlStartTagBeforeHTML(AtomicHTMLToken* token) {
HTMLHtmlElement* element = HTMLHtmlElement::create(*m_document);
attachLater(m_attachmentRoot, element);
m_openElements.pushHTMLHtmlElement(HTMLStackItem::create(element, token)); //push 到 HTMLStackItem 栈里
executeQueuedTasks();
}
//通过 attachLater 创建 task
void HTMLConstructionSite::attachLater(ContainerNode* parent,
Node* child,
bool selfClosing) {
HTMLConstructionSiteTask task(HTMLConstructionSiteTask::Insert);
task.parent = parent;
task.child = child;
task.selfClosing = selfClosing;
//判断是否到达最深,512是最深
if (m_openElements.stackDepth() > maximumHTMLParserDOMTreeDepth &&
task.parent->parentNode())
task.parent = task.parent->parentNode();
queueTask(task);
}
//executeQueued 添加子节点
void ContainerNode::parserAppendChild(Node* newChild) {
if (!checkParserAcceptChild(*newChild))
return;
AdoptAndAppendChild()(*this, *newChild, nullptr);
}
notifyNodeInserted(*newChild, ChildrenChangeSourceParser);
}
//添加前会先检查是否支持子元素
void ContainerNode::appendChildCommon(Node& child) {
child.setParentOrShadowHostNode(this);
if (m_lastChild) {
child.setPreviousSibling(m_lastChild);
m_lastChild->setNextSibling(&child);
} else {
setFirstChild(&child);
}
setLastChild(&child);
}闭标签会把元素 pop 出来
m_tree.openElements()->popUntilPopped(token->name());parser 一个 html 代码的时候如果是符合规范的那么就都好说,不幸的是很多 html 代码都不规范,所以 parser 需要做些容错。下面列出一些 WebKit 容错的例子
一些网站会用 替代
,处理的代码如下:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}stray table 是一个 table 包含了一个不在 table cell 的 table。
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>WebKit 的处理
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);这样会处理成两个同级 table
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>将一个 form 放到另一个 form 里。那么第二个 form 会被忽略
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}同一个类型里只允许嵌套 20 个 tag。
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}这些都会在 end() 是调用
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;所有的 CSS 都是由 CSSStyleSheet 集合组成,CSSStyleSheet 是有多个 CSSRule 组成,每个 CSSRule 由 CSSStyleSelector 选择器和 CSSStyleDeclaration 声明组成。CSSStyleDeclaration 是 CSS 属性的键值集合。
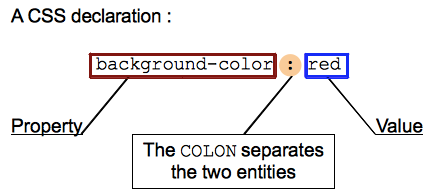
使用大括号包起来。
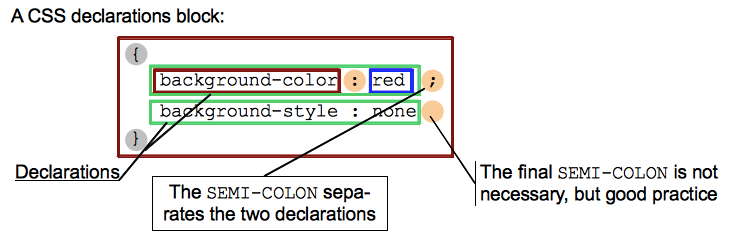
在 CSS declarations block 前加上 selector 来匹配页面上的元素。selector 和 declarations block 在一起被称作 ruleset,简称 rule。
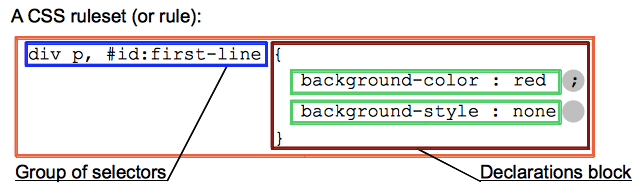
selector 可以分为以下类别
- Simple selectors:简单选择器,通过 class 或 id 类匹配一个或多个元素。
- Attribute selectors:属性选择器,通过属性匹配。
- Pseudo-classes:伪类,匹配确定状态的比如鼠标悬停元素,当前选中或未选中的复选框, DOM 树中一父节点的第一个子节点的元素。比如 a:visited 表示访问过的链接, a:hover 表示鼠标在上面的链接。
- Pseudo-elements:伪元素,匹配处于确定位置的一个或多个元素,比如每个段落的第一个字,某个元素之前生成的内容。比如 [href^=http]::after { content: '->'} 表示属性是 herf 值的开头是 http 的元素内容后面添加 -> 符号。
- Combinators:组合器,组合多个选择器用于特定的选择的方法。比如只选择 div 的直系子节点段落。比如 A > B 那么 B 是 A 的直接子节点。
- Multiple selectors:多用选择器,将一组声明应用于由多个选择器选择的所有元素。
Attribute selectors 属性选择器是针对 data-* 这样的数据属性进行选择的,尝试匹配精确属性值的 Presence and value attribute selector 分为下面几种
- [attr]:不论值是什么选择所有 attr 属性的元素。
- [attr=val]:按照 attr 属性的值为 val 的所有元素。
- [attr~=val]:attr 属性的值包含 val 值的所有元素,val 以空格间隔多个值。
还有 Substring value attribute selector 这样的伪正则选择器:
- [attr|=val]:匹配选择以 val 或 val- 开头的元素,-一般用来处理语言编码。
- [attr^=val]:匹配选择以 val 开头的元素。
- [attr$=val]:匹配选择以 val 结尾的元素。
- [attr*=val]:匹配选择包含 val 的元素。
Combinators 组合器有以下几种
- A,B: 匹配 A B 的任意元素。
- A B:B 是 A 的后代节点,可以是直接的子节点或者是子节点的子节点。
- A > B:B 是 A 的直接子节点。
- A + B:B 是 A 的兄弟节点。
- A ~ B:B 是 A 兄弟节点中的任意一个。
CSS rule 只是 CSS statements 的一种。 其它类型是 @-规则,在 CSS 里使用 @-规则来传递元数据,条件信息或其它描述信息。@ 符号后面跟一个描述符来表明用哪种规则,再后面是 CSS declarations block,结束是 ; 符号。
- @charset:元数据
- @import:元数据
- @media:嵌套语句,只在运行浏览器的设备匹配条件时才会运用 @-规则里的内容。
- @supports:嵌套语句,只有浏览器确实支持采用应用 @-规则里的内容。
- @document:嵌套语句,只有当前页面匹配条件采用运用 @-规则的内容。
- @font-face:描述性信息
比如
@import 'starming.css';表示向当前的 CSS 导入了 starming.css 文件。再举个例子:
@media (min-width: 801px) {
body {
margin:0 auto;
width:800px;
}
}这个表示页面宽度超过801像素时才会运用 @-规则里的内容。
有些属性是 Shorthand 属性,比如 font,background,padding,border和 margin。他们允许一行里设置多个属性。 比如
maring: 20px 10px 10px 20px; 等效于
margin-top: 20px;
margin-right: 10px;
margin-bottom: 10px;
margin-left: 20px;再比如 background 属性
background: black url(starming-bg.png) 20px 20px repeat-x fixed;和下面的属性设置等效
background-color: black;
background-image: url(starming-bg.png);
background-position: 20px 20px;
background-repeat: repeat-x;
background-scroll: fixed;- absolute units 绝对单位:px,mm,cm,in:pixel 像素,millimeters 毫米,centimeters 厘米,inches 英寸。pt,pc:Points (1/72 of an inch) 点,picas (12 points.) 十二点活字。
- 相对单位:em:1em 的计算值默认为 16px。但是要注意 em 单位会继承父元素的字体大小。ex,ch:支持的不是很好。rem:REM(root em),跟 em 工作方式一样,不同的是总是等于默认基础字体大小。vw,vh:视图宽度的 1/100 和视图高度的 1/100,但是支持没有 rem 那么好。
- 无单位的值:在某些情况下无单位的值是可以存在的,比如设置 margin: 0; 就是可以的,还有 p { line-height: 1.5 } 这里的值类似一个简单的乘法因子,比如 font-size 为16px的话,行高就为24px。
- 百分比:相对于父容器所占的百分比,注意如果 font-size 使用百分比是指新的大小相对于父容器的字体大小,和 em 类似,所以 200% 和 2em 类似。
- 颜色:有165个不同关键字可用,具体见 https://developer.mozilla.org/en-US/docs/Web/CSS/color_value#Color_keywords ,还可以使用类似 background-color: #0000ff; 这样的十六进制表示颜色,还有 RGB 表示 background-color: rgb(0,0,255); 。还支持background-color: hsl(240,100%,50%); 这种 HSL 的表示,值依次是色调,值范围是0到360,饱和度0表示没有颜色,明度里0表示全黑,100%表示全白。HSL 是采用圆柱体可视化颜色的工作方式,Wikipedia 上有详细说明:https://en.wikipedia.org/wiki/HSL_and_HSV#Basic_principle
- 透明度:可以通过 rgba 和 hsla 来表示,比如 background-color: hsla(240,100%,50%,0.5); 。还可以通过 CSS 属性 opacity 来指定透明度。
- 函数:只要是一个名字后面用括号包含一个或多个值之间用逗号分隔就是一个函数,比如 background-color: rgba(255,0,0,0.5); transform: translate(50px, 60px); background-image: url('myimage.png');
可以通过 w3c 提供的服务 http://jigsaw.w3.org/css-validator/ 来验证,w3c 还提供了 html 的验证服务 https://validator.w3.org/#validate_by_uri
CSS 语法 BNF
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator selector ] ]
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
WebKit 会使用 Flex 和 Bison 来解析这个 BNF 文件。CSS 文件会被解析成 StyleSheet object,每个 object 包含 CSS rules object,这些 object 包含 selector 和 declaration 还要其它对应于 CSS 语法的 object。接下来进行会进行 CSSRule 的匹配过程,去找能够和 CSSRule Selector 部分匹配的 HTML 元素。
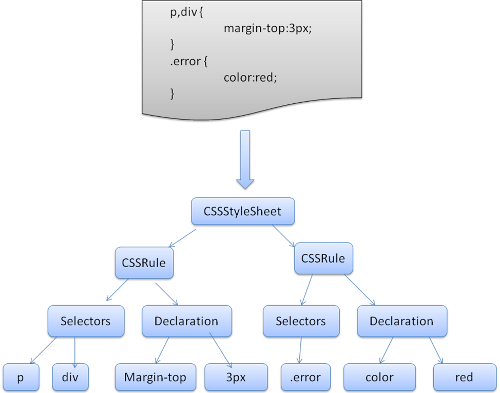
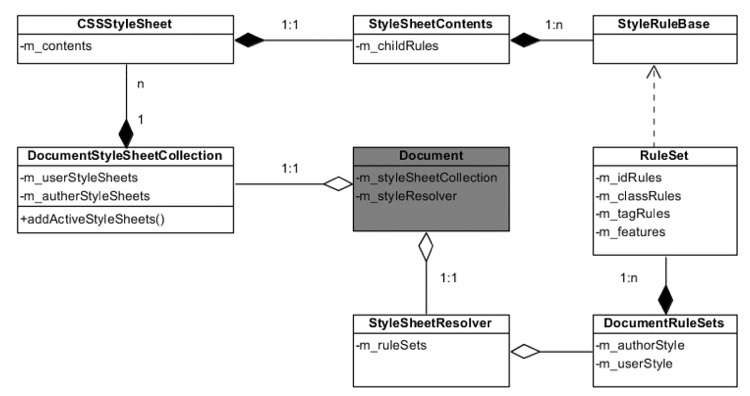
StyleSheetResolver 负责组织用来为 DOM 里的元素匹配的规则,里面包含了一个 DocumentRuleSets 的类,这个类是用来表示多个 RuleSet 的。
CSS 文档结构的类图如下:
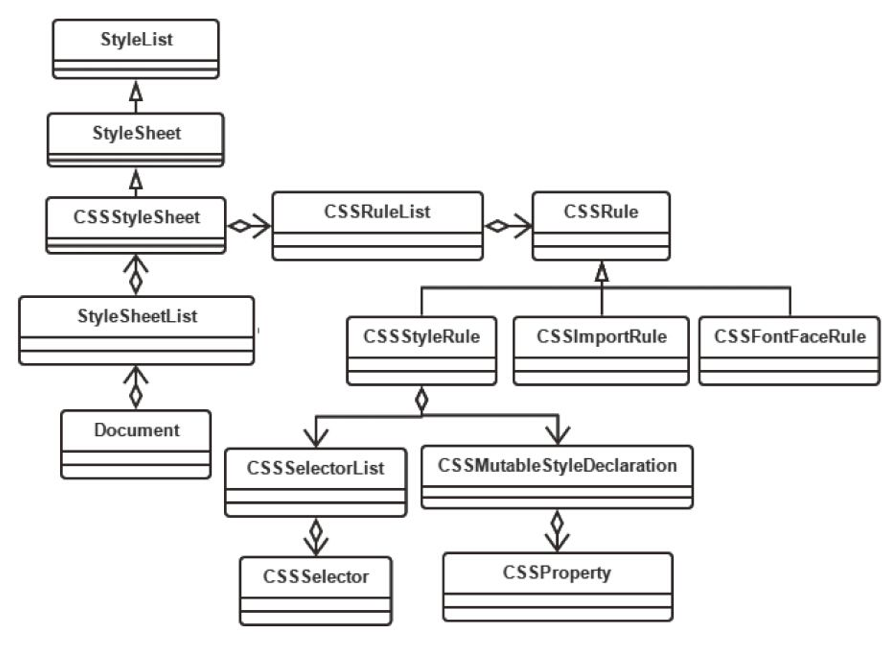
RuleSet 有很多类型,下图是 StyleRuleBase 相关继承关系
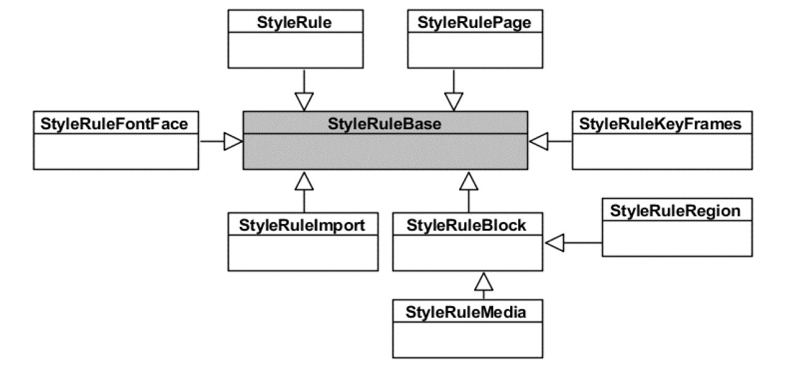
- StyleRule:常用的都是这个类型
- StyleRuleImport:对应的是 @import
- StyleRuleMedia:对应的是 @media
- StyleRuleFontFace:对应的 @font-face
- StyleRulePage:对应的 @page
- StyleRuleKeyFrames:对应的 @-webkit-key-frames
- StyleRuleRegion:分区域排版
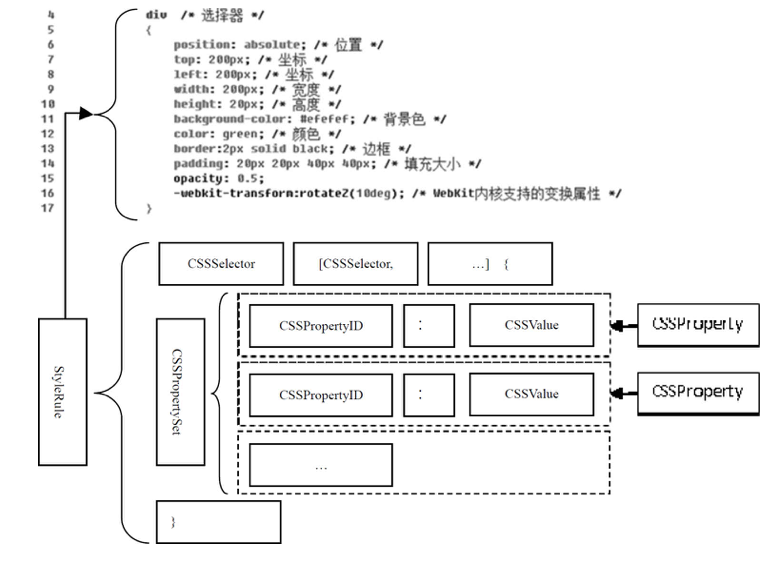
WebKit 解析的入口函数是 CSSParser::parseSheet。解析过程如下图:
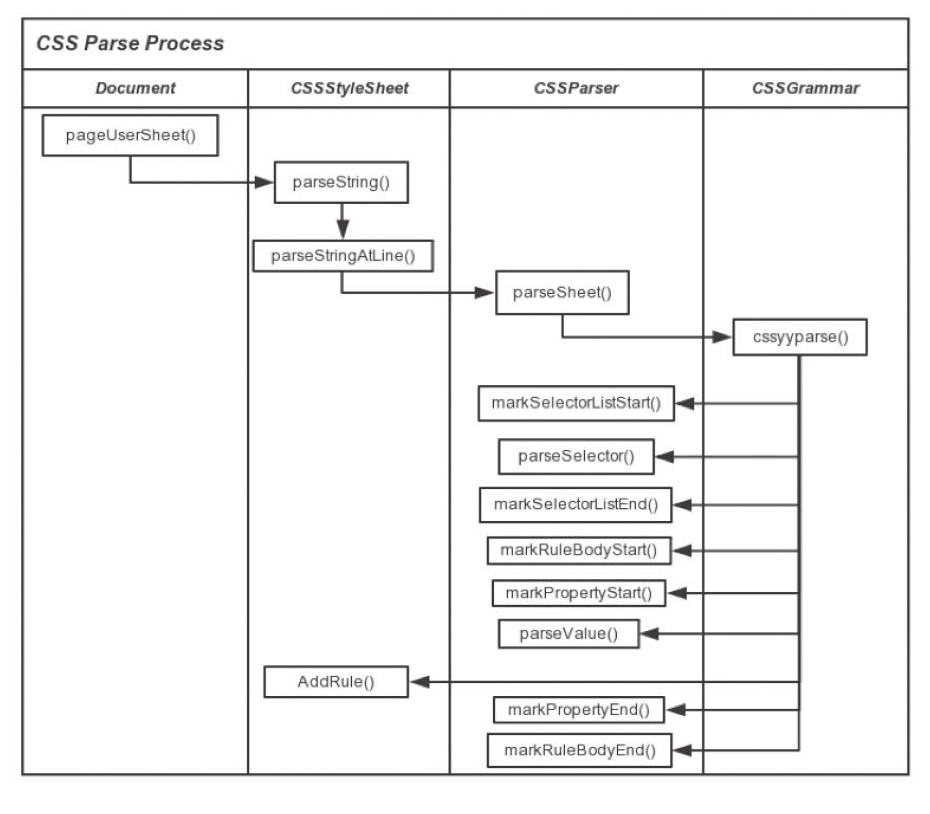
字符串转 tokens
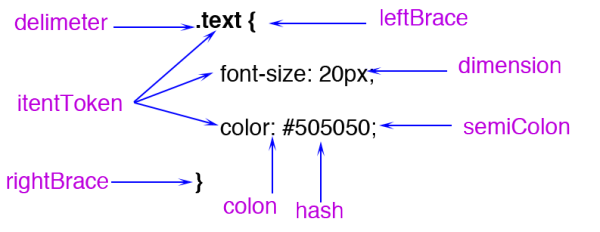
将 tokens 转成 styleRule。每个 styleRule 包含 selectors 和 properties。 定义 matchType
enum MatchType {
Unknown,
Tag, //比如 div
Id, // #id
Class, // .class
PseudoClass, // :nth-child(2)
PseudoElement, // ::first-line
PagePseudoClass, //
AttributeExact, // E[attr="value"]
AttributeSet, // E[attr]
AttributeHyphen, // E[attr|="value"]
AttributeList, // E[attr~="value"]
AttributeContain, // E[attr*="value"]
AttributeBegin, // E[attr^="value"]
AttributeEnd, // E[attr$="value"]
FirstAttributeSelectorMatch = AttributeExact,
};定义 selectors 的 Relation 类型
enum RelationType {
SubSelector, // No combinator
Descendant, // "Space" combinator
Child, // > combinator
DirectAdjacent, // + combinator
IndirectAdjacent, // ~ combinator
// Special cases for shadow DOM related selectors.
ShadowPiercingDescendant, // >>> combinator
ShadowDeep, // /deep/ combinator
ShadowPseudo, // ::shadow pseudo element
ShadowSlot // ::slotted() pseudo element
};CSS 的属性是 id 来标识的
enum CSSPropertyID {
CSSPropertyColor = 15,
CSSPropertyWidth = 316,
CSSPropertyMarginLeft = 145,
CSSPropertyMarginRight = 146,
CSSPropertyMarginTop = 147,
CSSPropertyMarkerEnd = 148,
}默认样式,Blink ua全部 CSS 样式:http://yincheng.site/html/chrome-ua-css.html 。w3c 的默认样式是:https://www.w3.org/TR/CSS2/sample.html
接着会生成 hash map,分成四个类型
CompactRuleMap m_idRules; //id
CompactRuleMap m_classRules; //class
CompactRuleMap m_tagRules; //标签
CompactRuleMap m_shadowPseudoElementRules; //伪类选择器CSS 解析完会触发 layout tree ,会给每个可视 Node 创建一个 layout 节点,创建时需要计算 style,这个过程包括找到 selector 和 设置 style。
layout 会更新递归所有 DOM 元素
void ContainerNode::attachLayoutTree(const AttachContext& context) {
for (Node* child = firstChild(); child; child = child->nextSibling()) {
if (child->needsAttach())
child->attachLayoutTree(childrenContext);
}
}然后对每个 node 都会按照 id,class,伪元素和标签顺序取出所有对应的 selector
//id
if (element.hasID())
collectMatchingRulesForList(
matchRequest.ruleSet->idRules(element.idForStyleResolution()),
cascadeOrder, matchRequest);
//class
if (element.isStyledElement() && element.hasClass()) {
for (size_t i = 0; i < element.classNames().size(); ++i)
collectMatchingRulesForList(
matchRequest.ruleSet->classRules(element.classNames()[i]),
cascadeOrder, matchRequest);
}
//伪类
...
//tag 和 selector
collectMatchingRulesForList(
matchRequest.ruleSet->tagRules(element.localNameForSelectorMatching()),
cascadeOrder, matchRequest);
//通配符
...可以看到 id 是唯一的,容易直接取到,class 就需要遍历数组来设置 style。
在 classRules 里会进行检验
if (!checkOne(context, subResult))
return SelectorFailsLocally;
if (context.selector->isLastInTagHistory()) {
return SelectorMatches;
}
//checkOne 的实现
switch (selector.match()) {
case CSSSelector::Tag:
return matchesTagName(element, selector.tagQName());
case CSSSelector::Class:
return element.hasClass() &&
element.classNames().contains(selector.value());
case CSSSelector::Id:
return element.hasID() &&
element.idForStyleResolution() == selector.value();
}如果 Relation 类型是 Descendant 表示是后代,就需要在 checkOne 后处理 relation。
switch (relation) {
case CSSSelector::Descendant:
for (nextContext.element = parentElement(context); nextContext.element;
nextContext.element = parentElement(nextContext)) {
MatchStatus match = matchSelector(nextContext, result);
if (match == SelectorMatches || match == SelectorFailsCompletely)
return match;
if (nextSelectorExceedsScope(nextContext))
return SelectorFailsCompletely;
}
return SelectorFailsCompletely;
case CSSSelector::Child:
//...
}可以看到这个就是 selector 从右到左解释的实现,它会递归所有父节点,再次执行 checkOne ,这样直到找到需要的父节点以及如果需要的父节点的父节点才会停止递归。所以选择器不要写太长,会影响效率。
CSS 解析完,节点会调用 CSSStyleSelector 的 styleForElement 来给节点创建 RenderStyle 实例。RenderObject 需要 RenderStyle 的排版信息。
CSSStyleSelector 会从 CSSRuleList 里将匹配的样式属性取出进行规则匹配,相关类图如下:
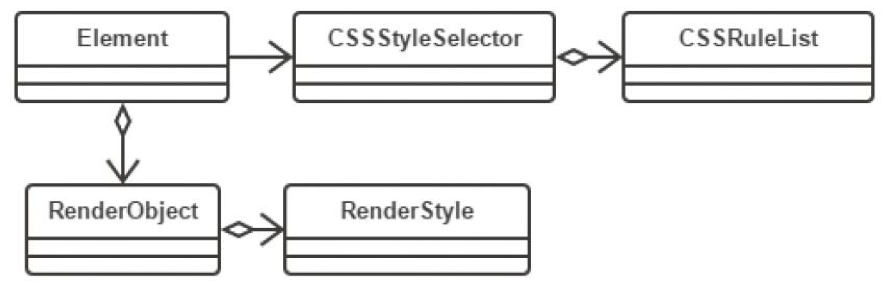
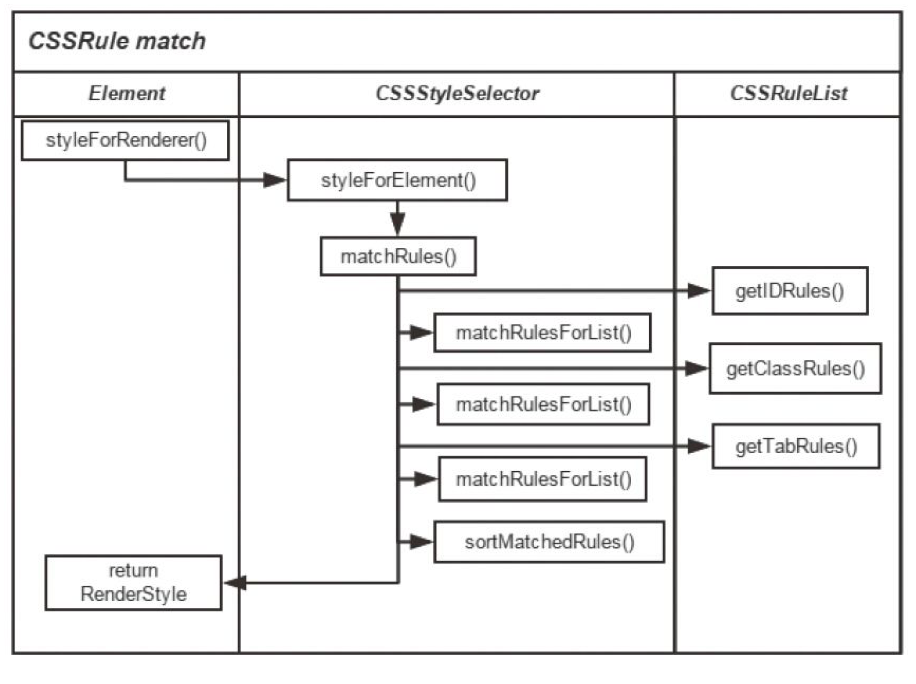
设置的顺序是先设置父节点,在使用默认的 UA 的 style,最后再使用 Author 的 style。
style->inheritFrom(*state.parentStyle())
matchUARules(collector);
matchAuthorRules(*state.element(), collector);在执行每一步时如有一个 styleRule 匹配的话都会放到当前元素的 m_matchedRule 里,然后计算优先级,优先级算法就是从右到左取每个 selector 优先级之和,实现如下
for (const CSSSelector* selector = this; selector;
selector = selector->tagHistory()) {
temp = total + selector->specificityForOneSelector();
}
return total;每个不同类型的 selector 的优先级如下
switch (m_match) {
case Id:
return 0x010000;
case PseudoClass:
return 0x000100;
case Class:
case PseudoElement:
case AttributeExact:
case AttributeSet:
case AttributeList:
case AttributeHyphen:
case AttributeContain:
case AttributeBegin:
case AttributeEnd:
return 0x000100;
case Tag:
return 0x000001;
case Unknown:
return 0;
}
return 0;
}可以看出 id 的优先级最大是 0x010000 = 65536,类,属性,伪类优先级是 0x000100 = 256,标签是 0x000001 = 1
举个优先级计算的例子
/*优先级为257 = 265 + 1*/
.text h1{
font-size: 8em;
}
/*优先级为65537 = 65536 + 1*/
#my-text h1{
font-size: 16em;
}将所有 CSS 规则放到 collector 的 m_matchedRules 里,再根据优先级从小到大排序,这样,越执行到后面优先级越高,可以覆盖前面的。
目前优先级是 ID 选择器大于类型选择器,大于标签选择器,大于相邻选择器,大于子选择器,大于后代选择器。
排序规则
static inline bool compareRules(const MatchedRule& matchedRule1,
const MatchedRule& matchedRule2) {
unsigned specificity1 = matchedRule1.specificity();
unsigned specificity2 = matchedRule2.specificity();
if (specificity1 != specificity2)
return specificity1 < specificity2;
return matchedRule1.position() < matchedRule2.position();
}规则和优先级完后就开始设置元素的 style 了:
applyMatchedPropertiesAndCustomPropertyAnimations(
state, collector.matchedResult(), element);
applyMatchedProperties<HighPropertyPriority, CheckNeedsApplyPass>(
state, matchResult.allRules(), false, applyInheritedOnly, needsApplyPass);
for (auto range : ImportantAuthorRanges(matchResult)) {
applyMatchedProperties<HighPropertyPriority, CheckNeedsApplyPass>(
state, range, true, applyInheritedOnly, needsApplyPass);
}最后的 style 是什么样的,style 会生成一个 ComputedStyle 对象。对象结构如下:
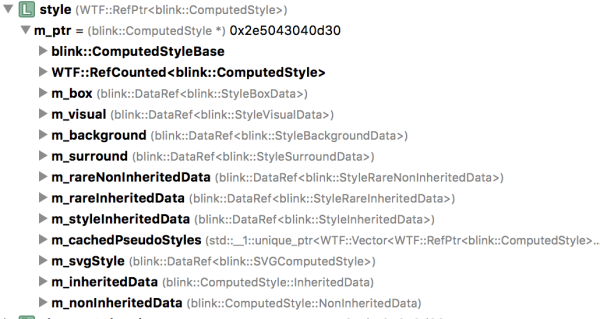
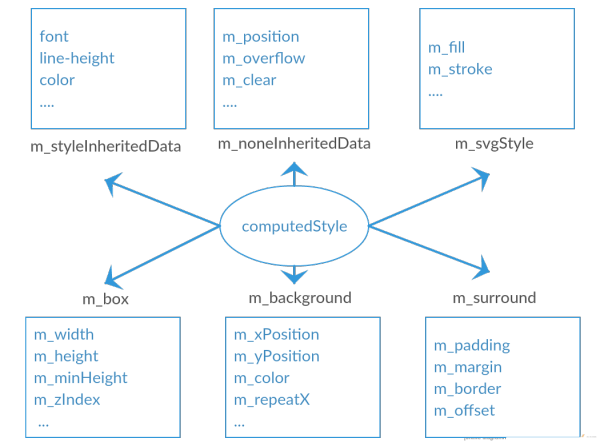
CSS 对象模型 CSSOM 提供了便于 JavaScript 操作 CSS 的接口 CSSStyleSheet。通过这个接口我们可以很容易获取 CSS 的 href,cssRule 这样的信息。
W3C 还定义了 CSSOM View,增加了 Window,Document,Element,HTMLElement 和 MouseEvent 的接口。比如 Window 对 CSSOM View 的支持就可以在 WebCore/page/DOMWindow.idl 里查看到,我摘出和 CSSOM View 相关的规范定义如下:
// Extensions from the CSSOM-View specification (https://drafts.csswg.org/cssom-view/#extensions-to-the-window-interface).
[NewObject] MediaQueryList matchMedia(CSSOMString query);
[Replaceable] readonly attribute Screen screen; // FIXME: Should be [SameObject].
// Browsing context (CSSOM-View).
void moveTo(optional unrestricted float x = NaN, optional unrestricted float y = NaN); // FIXME: Parameters should be mandatory and of type long.
void moveBy(optional unrestricted float x = NaN, optional unrestricted float y = NaN); // FIXME: Parameters should be mandatory and of type long.
void resizeTo(optional unrestricted float width = NaN, optional unrestricted float height = NaN); // Parameters should be mandatory and of type long.
void resizeBy(optional unrestricted float x = NaN, optional unrestricted float y = NaN); // FIXME: Parameters should be mandatory and of type long.
// Viewport (CSSOM-View).
[Replaceable] readonly attribute long innerHeight;
[Replaceable] readonly attribute long innerWidth;
// Viewport scrolling (CSSOM-View).
[Replaceable] readonly attribute double scrollX;
[Replaceable, ImplementedAs=scrollX] readonly attribute double pageXOffset;
[Replaceable] readonly attribute double scrollY;
[Replaceable, ImplementedAs=scrollY] readonly attribute double pageYOffset;
[ImplementedAs=scrollTo] void scroll(optional ScrollToOptions options);
[ImplementedAs=scrollTo] void scroll(unrestricted double x, unrestricted double y);
void scrollTo(optional ScrollToOptions options);
void scrollTo(unrestricted double x, unrestricted double y);
void scrollBy(optional ScrollToOptions option);
void scrollBy(unrestricted double x, unrestricted double y);
// Client (CSSOM-View).
[Replaceable] readonly attribute long screenX;
[Replaceable] readonly attribute long screenY;
[Replaceable] readonly attribute long outerWidth;
[Replaceable] readonly attribute long outerHeight;
[Replaceable] readonly attribute double devicePixelRatio;
可以看出 CSSOM View 定义了 Window 的大小,滚动,位置等各种信息。
当 DOM tree 构建过程中,在 HTMLConstruction 的 attachToCurrent 方法里会通过 createRendererIfNeeded 方法构建的另外一个 tree,叫 Render tree。构成这个 tree 的元素都是 RenderObject。RenderObject 会记录各个 node 的 render 信息,比如 RenderStyle,Node 和 RenderLayer 等。当 WebKit 创建 DOM Tree 的同时也会创建 RenderObject 对象,DOM Tree 动态加入一个新节点时也会创建相应的 RenderObject 对象。
整个 tree 的创建过程都是由 NodeRenderingContext 类来完成。下图是如何创建 RenderObject 对象和构建 RenderObject Tree 的。
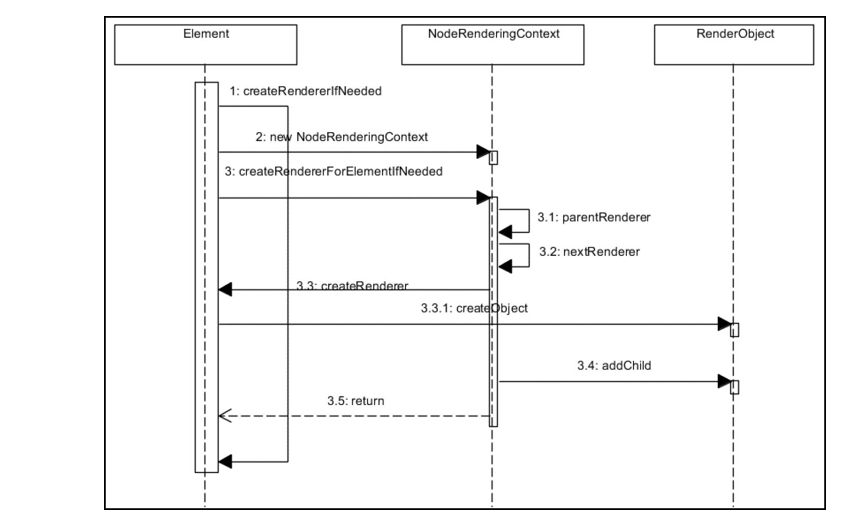
RenderObject 需要知道 CSS 相关属性,会引用在 CSS 解析过程中生成的 CSSStyleSelector 提供的 RenderStyle。RenderObject 的创建过程如下:
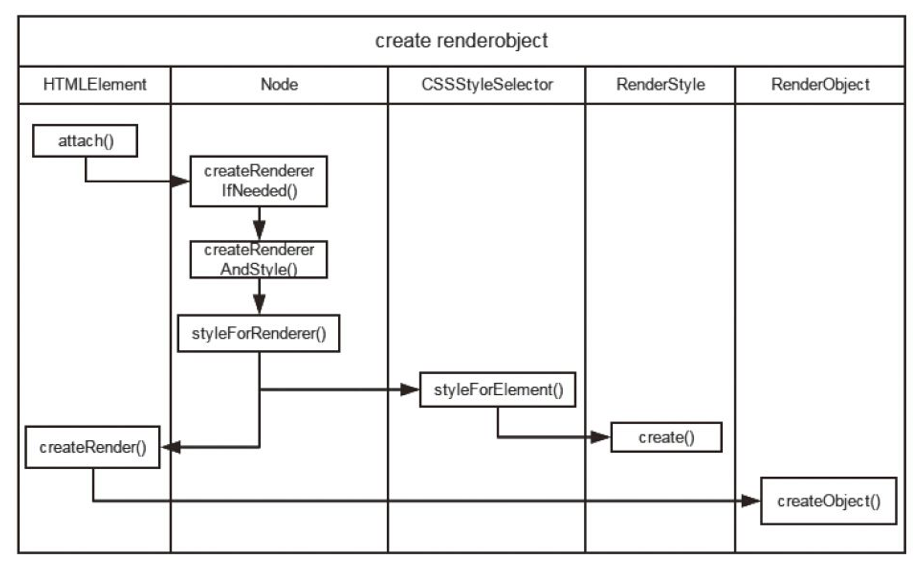
RenderObject 被创建时创建时相关的类如下图所示:
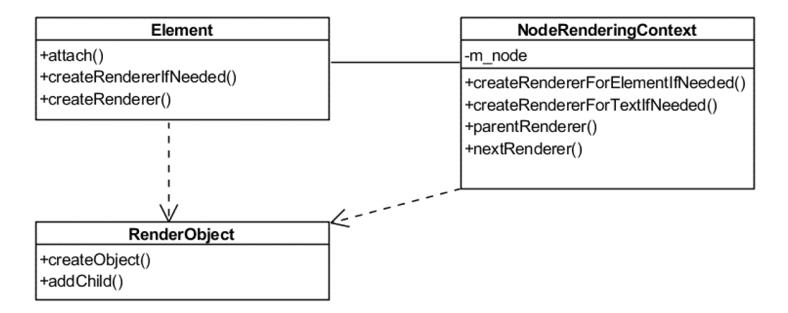
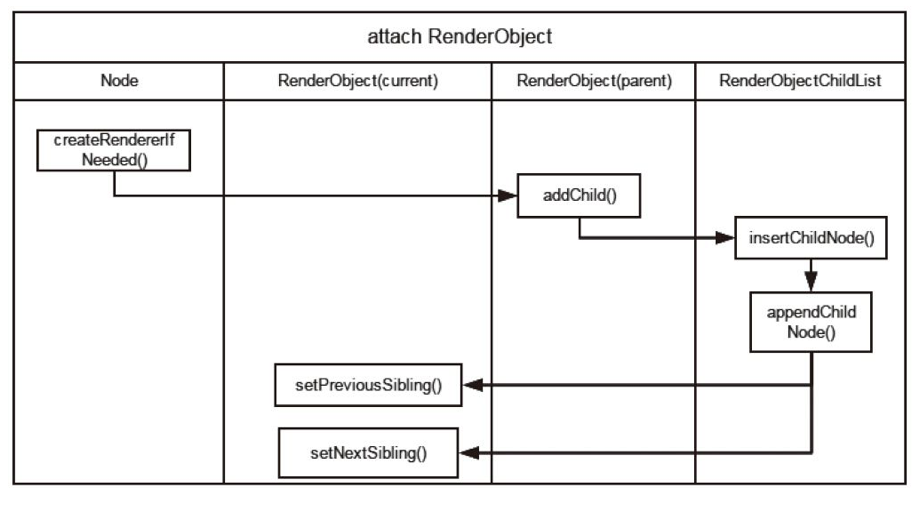
RenderObject 树和 DOM 树一样也有很多类型,下面是 RenderObject 基类和子类示意图:
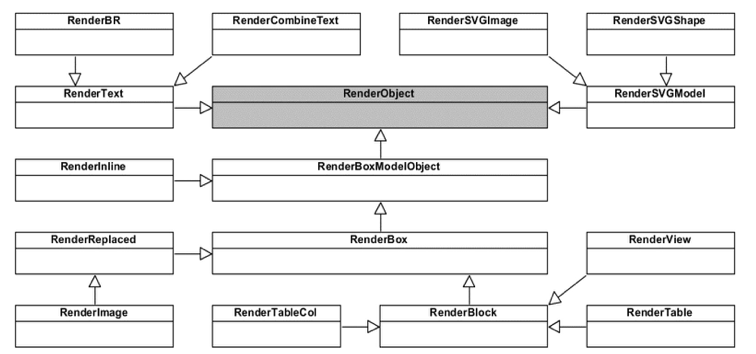
RenderObject 核心对象关系图如下:
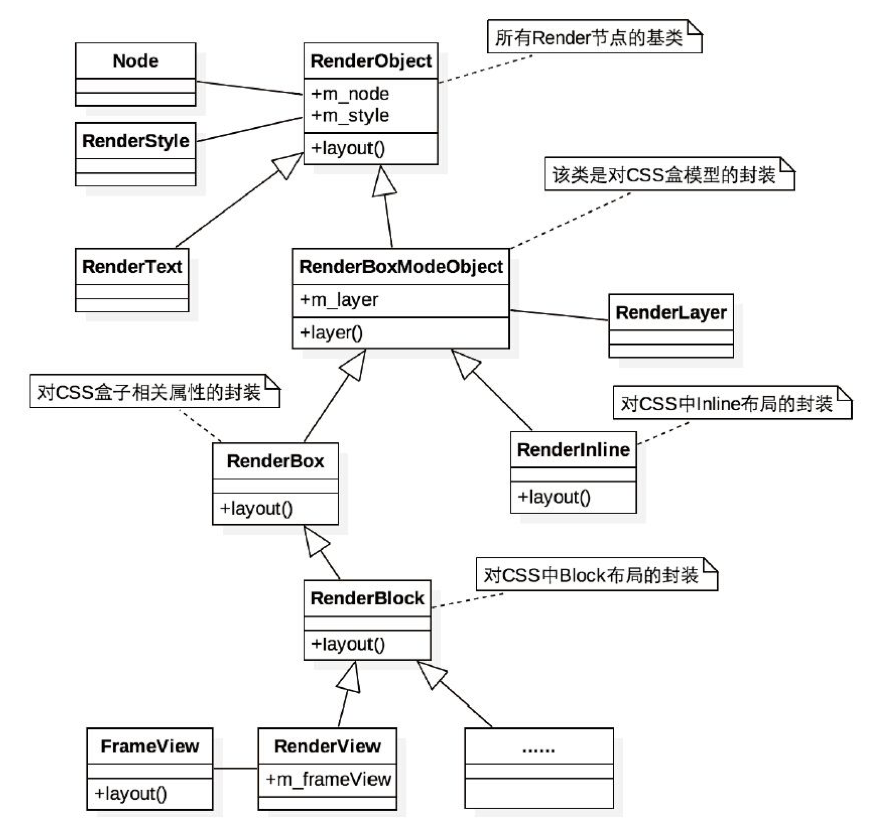
RenderBox 类是 Box 模型的类,包含了外边距,内边距,边框等信息。
RenderObject 的继承关系图如下:
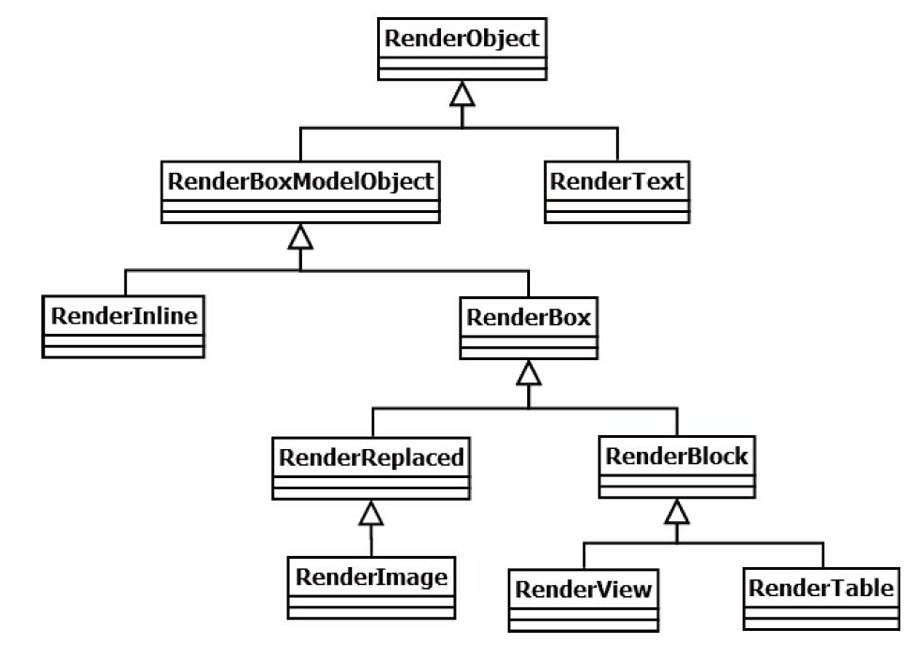
RenderObject 的一些主要虚函数
- parent(),firstChild(),nextSibling(),previousSibling(),addChild(),removeChild() 这些遍历和修改 RenderObject 树的函数。
- layout(),style(),enclosingBox() 这些计算和获取布局的函数。
- isASubClass 类似这样判断那种子类类型的函数。
- paint(),repaint() 这样讲内容绘制传入绘制结果对象的坐标和绘图函数。
RenderObject 用来构建 Render Tree 的相关方法
RenderElement* parent() const { return m_parent; }
bool isDescendantOf(const RenderObject*) const;
RenderObject* previousSibling() const { return m_previous; }
RenderObject* nextSibling() const { return m_next; }
// Use RenderElement versions instead.
virtual RenderObject* firstChildSlow() const { return nullptr; }
virtual RenderObject* lastChildSlow() const { return nullptr; }
RenderObject* nextInPreOrder() const;
RenderObject* nextInPreOrder(const RenderObject* stayWithin) const;
RenderObject* nextInPreOrderAfterChildren() const;
RenderObject* nextInPreOrderAfterChildren(const RenderObject* stayWithin) const;
RenderObject* previousInPreOrder() const;
RenderObject* previousInPreOrder(const RenderObject* stayWithin) const;
WEBCORE_EXPORT RenderObject* childAt(unsigned) const;
RenderObject* firstLeafChild() const;
RenderObject* lastLeafChild() const;RenderObject 用来布局相关的方法
bool needsLayout() const
{
return m_bitfields.needsLayout() || m_bitfields.normalChildNeedsLayout() || m_bitfields.posChildNeedsLayout()
|| m_bitfields.needsSimplifiedNormalFlowLayout() || m_bitfields.needsPositionedMovementLayout();
}
bool selfNeedsLayout() const { return m_bitfields.needsLayout(); }
bool needsPositionedMovementLayout() const { return m_bitfields.needsPositionedMovementLayout(); }
bool needsPositionedMovementLayoutOnly() const
{
return m_bitfields.needsPositionedMovementLayout() && !m_bitfields.needsLayout() && !m_bitfields.normalChildNeedsLayout()
&& !m_bitfields.posChildNeedsLayout() && !m_bitfields.needsSimplifiedNormalFlowLayout();
}
bool posChildNeedsLayout() const { return m_bitfields.posChildNeedsLayout(); }
bool needsSimplifiedNormalFlowLayout() const { return m_bitfields.needsSimplifiedNormalFlowLayout(); }
bool normalChildNeedsLayout() const { return m_bitfields.normalChildNeedsLayout(); }RenderBoxModelObject 是 RenderObject 的子类,是对 CSS Box 的封装,里面定义了 CSS Box 的各个接口。
RenderBox 是 RenderBoxModelObject 的子类,会重载 RenderObject 和 RenderBoxModelObject 的一些方法。
RenderBlock 是 RenderBox 的子类,封装 CSS 里 Block 的元素,里面有布局 Inline,block,和定位相关的方法,有删除,插入 Float 浮动节点还有计算浮动节点位置等方法,绘制相关的比如绘制 Float 节点,绘制 outline,绘制选择区等方法。
RenderView 继承自 RenderBlock,Render Tree 的根节点,是 Tree 布局和渲染的入口。
RenderInlineBox 是 RenderBoxModelObject 的子类,会封装 CSS 里的 Inline 元素。里面的方法主要处理 Inline 的自动换多行情况。对多行的处理 RenderInlineBox 会有个 RenderInlineBoxList 类的 m_lineBoxes 持有有多个 InlineBox 的行元素。RenderBox 和 InlineBox 的关系类图如下:
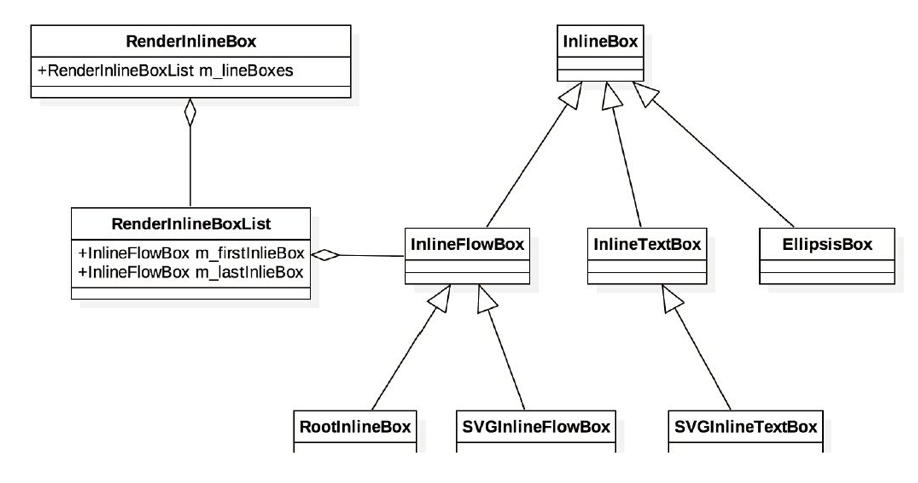
RenderText 继承 RenderObject,提供处理文字相关功能。相关的类图如下:
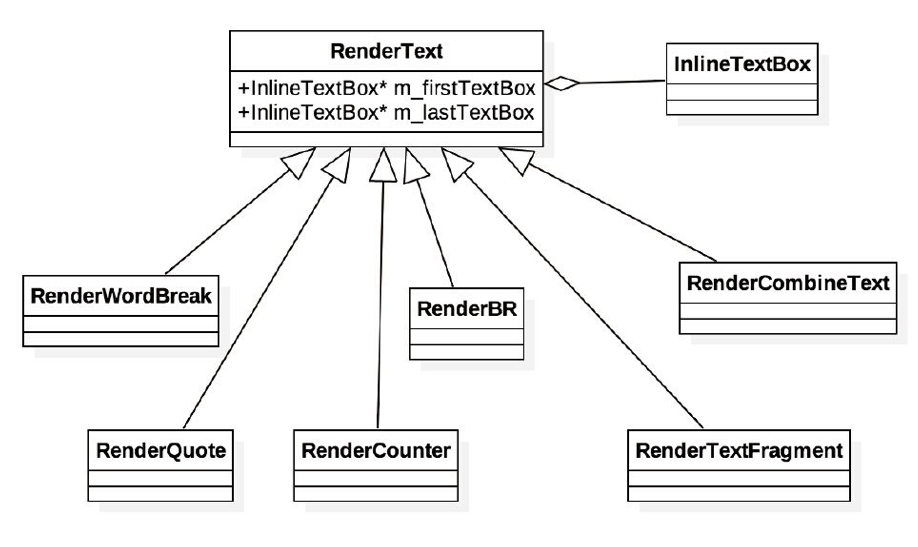
RenderStyle 来自 CSS,保存了 Render Tree 绘制需要的所有内容,StyleResolver 就是负责将 CSS 转成 RenderStyle。StyleResolver 类根据元素的信息,例如标签名和类别等,保存到新建的 RenderStyle 对象中,它们最后被 RenderObject 类所管理和使用。
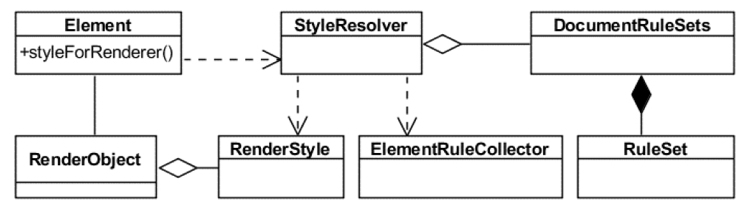
规则的匹配是由 ElementRuleCollector 类计算获得,根据元素属性信息,从 DocumentRuleSets 类里获得规则集合按照 ID,Class,Tag 等信息获得元素的样式,具体的过程如下:
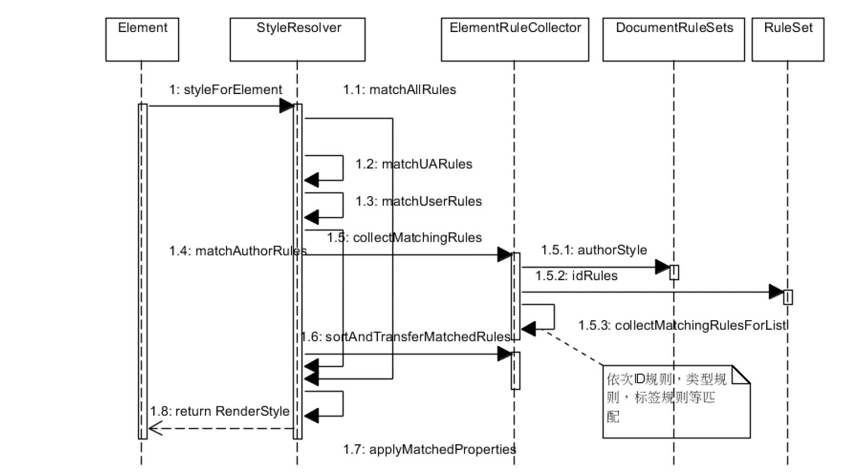
PassRefPtr<RenderStyle> styleForElement(Element*, RenderStyle* parentStyle = 0, StyleSharingBehavior = AllowStyleSharing,
RuleMatchingBehavior = MatchAllRules, RenderRegion* regionForStyling = 0);
......
PassRefPtr<RenderStyle> pseudoStyleForElement(PseudoId, Element*, RenderStyle* parentStyle);
PassRefPtr<RenderStyle> styleForPage(int pageIndex);
PassRefPtr<RenderStyle> defaultStyleForElement();
PassRefPtr<RenderStyle> styleForText(Text*);
static PassRefPtr<RenderStyle> styleForDocument(Document*, CSSFontSelector* = 0); StyleResolver 是 Document 的子对象。当 CSS 发生变化(style 发生变化)就会调用 recalcStyle,recalcStyle 调用 Element::StyleForRender,Element::StyleForRender 调用 styleForElement。
具体代码实现如下:
//保存 element
initElement(element);
initForStyleResolve(element, defaultParent);
....
//规则匹配
MatchResult matchResult;
if (matchingBehavior == MatchOnlyUserAgentRules)
matchUARules(matchResult);
else
matchAllRules(matchResult, matchingBehavior != MatchAllRulesExcludingSMIL);
//将规则和 element 做映射
applyMatchedProperties(matchResult, element);
//matchUARules
void StyleResolver::matchUARules(MatchResult& result, RuleSet* rules)
{
m_matchedRules.clear();
result.ranges.lastUARule = result.matchedProperties.size() - 1;
//收集匹配规则
collectMatchingRules(rules, result.ranges.firstUARule, result.ranges.lastUARule, false);
//规则排序
sortAndTransferMatchedRules(result);
}matchUARules 的 RuleSet 代表 CSS 规则,比如
p { background : red; } RuleSet 的成员变量
class RuleSet ... {
.....
AtomRuleMap m_idRules;
AtomRuleMap m_classRules;
AtomRuleMap m_tagRules;
AtomRuleMap m_shadowPseudoElementRules;
...
};sortAndTransferMatchedRules 是为了保证正确的匹配顺序。
RuleSet 来自浏览器定义的默认 RuleSet,也可来自写页面定义的 Author RuleSet,对于 Element 还有自身的规则。只有继承 StyledElement 的内联 CSS 的 Element 才能够有 RuleSet。实现是在 StyledElement::rebuildPresentationAttributeStyle 里实现的。
void StyledElement::rebuildPresentationAttributeStyle()
{
.....
RefPtr<StylePropertySet> style;
if (cacheHash && cacheIterator->value) {
style = cacheIterator->value->value;
presentationAttributeCacheCleaner().didHitPresentationAttributeCache();
} else {
style = StylePropertySet::create(isSVGElement() ? SVGAttributeMode : CSSQuirksMode);
unsigned size = attributeCount();
for (unsigned i = 0; i < size; ++i) {
const Attribute* attribute = attributeItem(i);
collectStyleForPresentationAttribute(*attribute, style.get());
}
}
// ImmutableElementAttributeData doesn't store presentation attribute style, so make sure we have a MutableElementAttributeData.
ElementAttributeData* attributeData = mutableAttributeData();
attributeData->m_presentationAttributeStyleIsDirty = false;
attributeData->setPresentationAttributeStyle(style->isEmpty() ? 0 : style);
....关于 AuthorStyle 用 StyleResolver::m_authorStyle 来保存 html 里所有 style tag 和 link 的外部 css。当 CSS 被改变或者页面大小变化时会调用 Document::styleResolverChanged 函数,接着调用 DocumentStyleCollection::updateActiveStyleSheets,最后调用 StyleResolver::appendAuthorStyleSheets。
其实并不是一一对应的,比如说 head 标签或者 display 属性为 none 的就不会在 Render tree 中。
有些 render object 有对应的 DOM node,但是不在 tree 的相同位置,比如 floats 和 absolutely position 的元素,他们会放在 tree 的其它地方,会映根据设置的 frame 直接射到对应的位置。如下图,虚线表示他们能够对应的:
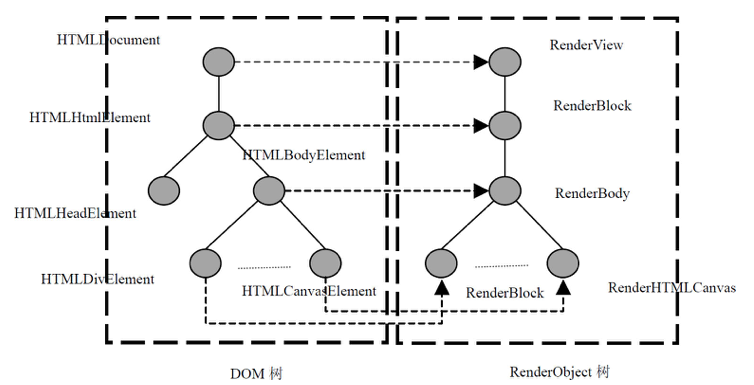
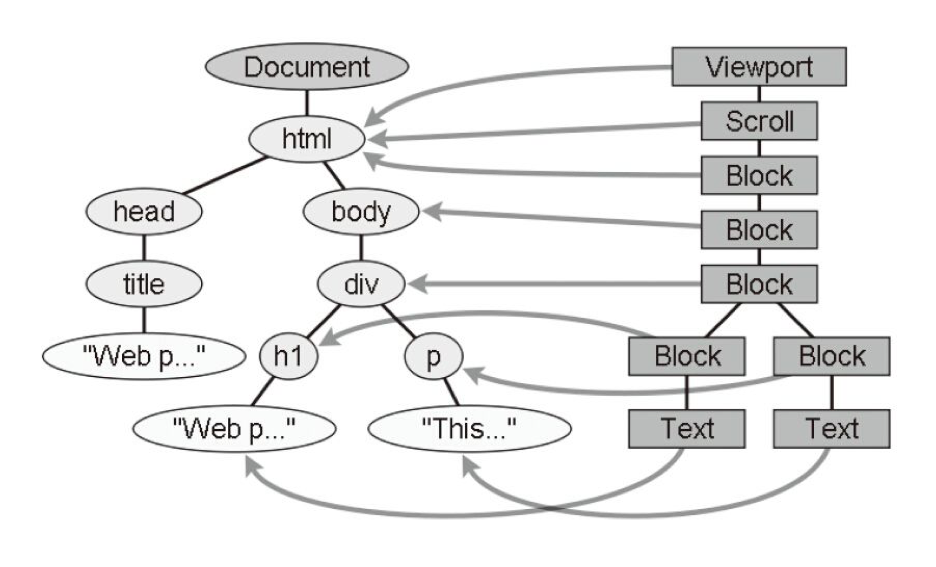
上图可以看到一般的 Element 比如 HTMLBodyElement 和 HTMLDivElement 对应的都是 RenderBlock。
解决样式和创建一个 renderer 称作 attachment,每个 Element 有一个 attach 方法,Render Tree 的创建就是从这里开始,attachment 是同步的,Element 节点插入 DOM tree 会调用新 node 的 attach 方法。在处理 html 和 body 标签时会创建 Render Tree 的 root。root Render Object 对应了 CSS 里的 containing block,top block 会包含所有的其它 block。Render Object 通过 RenderObject::CreateObject 静态方法创建,创建时会计算出 Element 的 CSSStyle。 浏览器 window 显示区域 viewport,在 WebKit 里叫做 RenderView。
RenderLayer Tree 是基于 RenderObject Tree 建立的,它们是多个 RenderObject 对应一个 RenderLayer 的关系。在创建完 RenderObject Tree WebKit 还会创建 RenderLayer Tree,根节点是 RenderView 实例,根据一些条件来判断是否需要创建一个新的 RenderLayer 对象,再设置 RenderLayer 对象的父对象和兄弟对象。RenderLayer 需要满足一定条件才会创建,下面是那些需要创建新 RenderLayer 对象的条件:
- HTMLElement 节点对应的 RenderBlock 节点。
- 有设置 relative,absolute,transform 的 CSS position 属性的。
- 透明效果的 RenderObject 节点。
- 节点有 overflow, apha mask 或反射效果的 RenderObject 节点。
- 设置了 CSS filter 属性的节点。
- 使用 Canvas 或 WebGL 的 RenderObject 节点。
- Video 节点对应的 RenderObject 节点。
RenderObject Tree 和 RenderLayer Tree 的关系如下图:
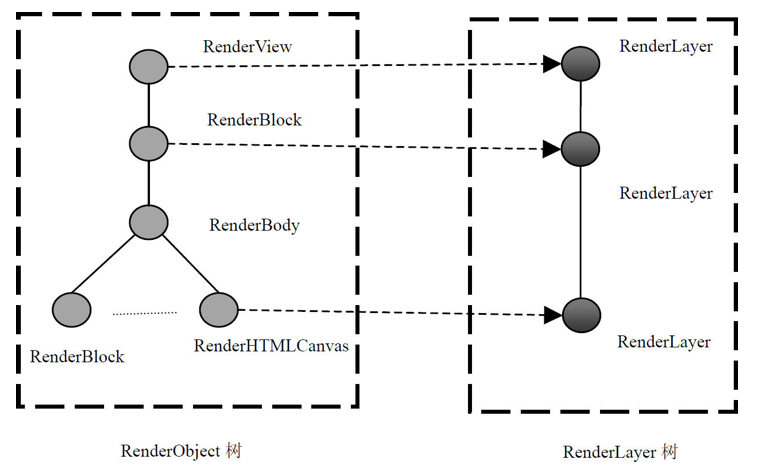

构建 render tree 需要计算每个 render object 的视觉特性。是通过计算每个 element 的 style 属性来做到的。
这个样式包含了各种来源的 style sheets,有 inline style element 和 html 里视觉属性设置比如 bgcolor 这样的属性,后面这些都会转为 CSS style 的属性。来源还有浏览器默认的 style sheets,这个 style sheets 可以是用户自定义的。
我们先看看 style 计算可能会有一些什么样问题
- Style 的数据是个非常大的结构,因为里面有大量的 style 属性这样会有内存问题。
- 如果没有优化为每个 element 查找合适的规则会导致性能问题。为每个 element 到整个规则列表查找合适的规则是个巨大消耗。Selectors 可能会有个很复杂的结构,比如 div div div div {...} 这样的话匹配时会有很多遍历来匹配。
- 应用规则涉及到比较复杂的层级规则。
下面来说下如何解决这些问题
WebKit 的 nodes 是 style objects(RenderStyle),这些 objects 可以被 nodes 在某些情况下共享,这些 nodes 可以是兄弟节点或表兄弟节点。有下面这些情况是可以 style 共享的
- element 必须有相同的鼠标状态
- 都没有 id
- tag 名能匹配上
- class 属性能匹配上
- 一组映射的属性是相同的
- 链接状态能匹配上
- focus 状态能匹配上
- 任何 element 都不会被属性 selectors 影响
- elements 不能有 inline style 属性
- 不要使用兄弟 selectors
WebKit 会把 style objects 和 DOM 的 node 相关联。通过正确的顺序将所有逻辑规则值转成计算值,比如百分比会被转换成绝对单位,rule tree 可以使节点之间共享这些值,避免多次计算,同时节省内存。所有匹配的规则都会存在一个 tree 里。tree 的最下面的 node 有着最高的优先级。Rule tree 是当 node style 需要的时候才会去根据规则计算的。
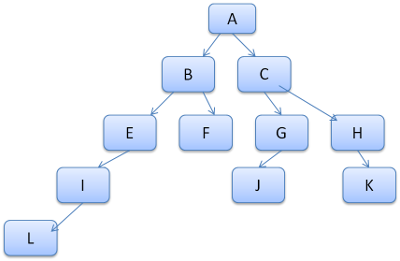
通过上图看看设置 rule tree 的好处吧,如果我们要找到 B - E - I 的规则我们能够省掉很多工作,因为我们已经计算了 A - B - E - I。
一些样式的信息是可以一开始就确定的,比如 border 和 color。所有属性分为可继承和不可继承两种,如果是需要继承需要特别指定,默认都是不可继承的。
rule tree 帮着我们缓存全部的 structs,这样的好处是如果下面的 node 没有可用的 struct,那么可以使用上一级 node 的缓存里的来用。
当确定要为某个 element 计算 style context 时,我们首先计算 rule tree 的路径或者使用一个已经存在的。接着我们开始在我们新的 style context 里应用路径里的规则去填充 structs。
从路径下面的 node 开始,然后往上直到 struct 完成。如果 struct 没有符合的 rule node,那么往 rule tree 上面 node 找,知道找到就可以直接使用,这样就是被优化了,整个 struct 都是共享的。
如果没有找到一个为这个 struct 的 rule node 定义,那么先检查是否是可继承的,如果是就使用父 struct 的 context。如果这个条件也没满足那么就使用默认的值。
如果一个 element 有兄弟节点指向相同的 tree node,那么全部 style context 可以被共享。
看个例子
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>下面是 CSS 的定义
div {margin:5px;color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}这里有两个 structs 需要填充, color struct 和 margin struct。color struct 只包含一个值, margin struct 有四个。下面是 rule tree
context tree:
假设到第二个 div 标签时,我们会创建一个 style context 给这个 node 并且填充 style struct。我们找到 1,2和6这个 rule 是满足的,而且在 rule tree 里已经存在了一个这样的路径,我们只需要把 F 添加到这个 node 里。这样形成一个 context tree 来保存这些对应关系。
现在需要填充 style struct,先从 margin struct 开始,比如 rule tree 里最后 node F 没有添加到 margin struct 里,我们可以往 rule tree 的上面找,找到并且使用之,最后我们找到 node B 这个是最近的一个有 margin struct 的 node。
已经定义了 color struct,那么就不能使用缓存的 struct,这样就不用往 rule tree 上级 node 去找,接着就把值转成 RGB 什么的并且缓存到这个 node 里。
对于第二个 span element,它会指向 rule G,就像前一个 span 一样。如果兄弟 node 都是指向同一个 rule node,那么它们是可以共享整个 style context 的。
如果是继承的 struct 会在 context tree 上进行缓存,color 属性是可继承的。
下面是不同的 style rules 的来源:
- CSS rules,来自于 style sheets 或者在 style elements 里
p {color:blue}- Inline style 属性
<p style="color:blue" />- HTML 视觉属性
<p bgcolor="blue">后面两个属于容易匹配 element,可以使用 element 作为 map 的 key。解析 style sheet 后,通过 selector rules 会添加一些 has maps。有 id 的 map,有 class name 的 map,还有 tag name 的 map。如果 selector 是 id 那么 rule 会添加到 id map 里。
如果是 class name 那么会添加到 class map 里。
这个操作更容易匹配 rule。完全没必要去查找每个声明,我们可以从对应的 element 的 map 里提取相关的 rule。
下面举个例子
p.error {color:red}
#messageDiv {height:50px}
div {margin:5px}第一个 rule 会被加到 class map 里。第二个会加入到 id map 里,第三个会被添加到 tag map 里。
对于下面的 HTML
<p class="error">an error occurred </p>
<div id=" messageDiv">this is a message</div>我们会先试着找 p 这个 element 的 rules,在 class map 里能找到 error 这个 key 里有 rule p.error。div 这个 element 可以在 id map 和 tag map 里找到。下面看看 div 的这个 rule
table div {margin:5px}selector 都是从右到左来查找的,先在 tag map 里找 div,然后再看看左边是 table tag,所以不吻合。
一个 style 属性可以被定义在多个 style sheets 里,那么应用 rules 的顺序就显得非常的重要,在 CSS 的定义里把这个顺序叫做 cascade 排序,意思是从低到高。
- 浏览器的设置
- 用户的设置
- 网页里普通的设置
- 网页里重要的设置
- 用户重要的设置
selector 的 specifity 在 w3c 里有定义 https://www.w3.org/TR/CSS2/cascade.html#specificity
计算方法如下
- style attribute 数量 =a
- ID attribute 数量 =b
- 其它的 attribute 和 pseudo-classes 数量 =c
- element names 和 pseudo-element 数量 =d
举个例子
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
<HEAD>
<STYLE type="text/css">
#x97z { color: red }
</STYLE>
</HEAD>
<BODY>
<P ID=x97z style="color: green">
</BODY>从例子可以看出 p element 的 color 会是 green,因为 style attribute 会覆盖 Style element 里的设置,因为它有更高的 specificity。
这些 rules 匹配后就需要对其排序了,WebKit 使用的是冒泡排序,通过重写 > 操作符
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}当 renderer 创建完并添加到 tree 里时是没有位置和高这些信息的,需要计算,WebKit 计算位置大小等信息的过程称为布局计算。
HTML 使用的是流式布局模型,那么就表示大多数情况一次就可以按照从左到右从顶到底算出布局需要的值。需要注意的是 HTML tables 需要的次数可能不仅一次。
Layout 是个递归的过程,以 FrameView::layout 为起始,调用 Render Tree 根节点的 layout,对应 HTML 里的 element,Layout 持续递归 frame hierarchy 计算每个 renderer 的几何信息。root 的 position 是0,0,把浏览器里可见的部分尺寸叫做 viewport。每个 renderer 都有 layout 或 reflow 方法,每个 renderer 都会去调用子视图的 layout 方法。FrameView::layout 可以被布局 WebViewCore::layout 方法触发。
完成上面那些过程后就会开始布局,上面的过程达到开始布局 FrameView::layout 的方法堆栈如下
FrameView:: layout( bool allowSubtree) // 栈 顶
Document:: implicitClose()
FrameLoader:: checkCallImplicitClose()
FrameLoader:: checkCompleted()
FrameLoader:: finishedParsing()
Document:: finishedParsing()
HTMLParser:: finished()
HTMLTokenizer:: end()
HTMLTokenizer:: finish()
Document:: finishParsing()
FrameLoader:: endIfNotLoadingMainResource()
FrameLoader:: end()
DocumentLoader:: finishedLoading()
FrameLoader:: finishedLoading()
MainResourceLoader:: didFinishLoading()
ResourceLoader:: didFinishLoading( WebCore:: ResourceHandle * h)layout 会先暂停 layout 定时器的实现,然后更新样式,获取到 RenderView 然后调用它的 layout 方法开始布局,具体相关的代码如下:
void FrameView::layout(bool allowSubtree)
{
ASSERT_WITH_SECURITY_IMPLICATION(!frame().document()->inRenderTreeUpdate());
LOG(Layout, "FrameView %p (%dx%d) layout, main frameview %d, allowSubtree=%d", this, size().width(), size().height(), frame().isMainFrame(), allowSubtree);
//判断是否已在 layout 过程中,避免多次 layout
if (isInRenderTreeLayout()) {
LOG(Layout, " in layout, bailing");
return;
}
if (layoutDisallowed()) {
LOG(Layout, " layout is disallowed, bailing");
return;
}
// Protect the view from being deleted during layout (in recalcStyle).
Ref<FrameView> protectedThis(*this);
// Many of the tasks performed during layout can cause this function to be re-entered,
// so save the layout phase now and restore it on exit.
SetForScope<LayoutPhase> layoutPhaseRestorer(m_layoutPhase, InPreLayout);
// Every scroll that happens during layout is programmatic.
SetForScope<bool> changeInProgrammaticScroll(m_inProgrammaticScroll, true);
bool inChildFrameLayoutWithFrameFlattening = isInChildFrameWithFrameFlattening();
if (inChildFrameLayoutWithFrameFlattening) {
if (!m_frameFlatteningViewSizeForMediaQuery) {
LOG_WITH_STREAM(MediaQueries, stream << "FrameView " << this << " snapshotting size " << ScrollView::layoutSize() << " for media queries");
m_frameFlatteningViewSizeForMediaQuery = ScrollView::layoutSize();
}
startLayoutAtMainFrameViewIfNeeded(allowSubtree);
//获取 root。这个 root 就是 RenderView 对象
RenderElement* root = m_layoutRoot ? m_layoutRoot : frame().document()->renderView();
if (!root || !root->needsLayout())
return;
}
TraceScope tracingScope(LayoutStart, LayoutEnd);
#if PLATFORM(IOS)
if (updateFixedPositionLayoutRect())
allowSubtree = false;
#endif
//也是避免多次触发,会把 layoutTimer 先停止
m_layoutTimer.stop();
m_delayedLayout = false;
m_setNeedsLayoutWasDeferred = false;
//我们不应该在 painting 时进入 layout
ASSERT(!isPainting());
if (isPainting())
return;
InspectorInstrumentationCookie cookie = InspectorInstrumentation::willLayout(frame());
AnimationUpdateBlock animationUpdateBlock(&frame().animation());
if (!allowSubtree && m_layoutRoot)
convertSubtreeLayoutToFullLayout();
ASSERT(frame().view() == this);
ASSERT(frame().document());
Document& document = *frame().document();
ASSERT(document.pageCacheState() == Document::NotInPageCache);
//对样式先进行更新
{
SetForScope<bool> changeSchedulingEnabled(m_layoutSchedulingEnabled, false);
if (!m_nestedLayoutCount && !m_inSynchronousPostLayout && m_postLayoutTasksTimer.isActive() && !inChildFrameLayoutWithFrameFlattening) {
// This is a new top-level layout. If there are any remaining tasks from the previous
// layout, finish them now.
SetForScope<bool> inSynchronousPostLayoutChange(m_inSynchronousPostLayout, true);
performPostLayoutTasks();
}
m_layoutPhase = InPreLayoutStyleUpdate;
// Viewport-dependent media queries may cause us to need completely different style information.
auto* styleResolver = document.styleScope().resolverIfExists();
if (!styleResolver || styleResolver->hasMediaQueriesAffectedByViewportChange()) {
LOG(Layout, " hasMediaQueriesAffectedByViewportChange, enqueueing style recalc");
document.styleScope().didChangeStyleSheetEnvironment();
// FIXME: This instrumentation event is not strictly accurate since cached media query results do not persist across StyleResolver rebuilds.
InspectorInstrumentation::mediaQueryResultChanged(document);
}
document.evaluateMediaQueryList();
// If there is any pagination to apply, it will affect the RenderView's style, so we should
// take care of that now.
applyPaginationToViewport();
// Always ensure our style info is up-to-date. This can happen in situations where
// the layout beats any sort of style recalc update that needs to occur.
document.updateStyleIfNeeded();
// If there is only one ref to this view left, then its going to be destroyed as soon as we exit,
// so there's no point to continuing to layout
if (hasOneRef())
return;
// Close block here so we can set up the font cache purge preventer, which we will still
// want in scope even after we want m_layoutSchedulingEnabled to be restored again.
// The next block sets m_layoutSchedulingEnabled back to false once again.
}
m_layoutPhase = InPreLayout;
RenderLayer* layer = nullptr;
bool subtree = false;
RenderElement* root = nullptr;
++m_nestedLayoutCount;
{
SetForScope<bool> changeSchedulingEnabled(m_layoutSchedulingEnabled, false);
autoSizeIfEnabled();
//重新设置 RenderView 对象,准备开始 layout
root = m_layoutRoot ? m_layoutRoot : document.renderView();
if (!root)
return;
subtree = m_layoutRoot;
if (!m_layoutRoot) {
auto* body = document.bodyOrFrameset();
if (body && body->renderer()) {
if (is<HTMLFrameSetElement>(*body) && !frameFlatteningEnabled()) {
body->renderer()->setChildNeedsLayout();
} else if (is<HTMLBodyElement>(*body)) {
if (!m_firstLayout && m_size.height() != layoutHeight() && body->renderer()->enclosingBox().stretchesToViewport())
body->renderer()->setChildNeedsLayout();
}
}
#if !LOG_DISABLED
if (m_firstLayout && !frame().ownerElement())
LOG(Layout, "FrameView %p elapsed time before first layout: %.3fs\n", this, document.timeSinceDocumentCreation().value());
#endif
}
m_needsFullRepaint = !subtree && (m_firstLayout || downcast<RenderView>(*root).printing());
if (!subtree) {
ScrollbarMode hMode;
ScrollbarMode vMode;
calculateScrollbarModesForLayout(hMode, vMode);
if (m_firstLayout || (hMode != horizontalScrollbarMode() || vMode != verticalScrollbarMode())) {
if (m_firstLayout) {
setScrollbarsSuppressed(true);
m_firstLayout = false;
m_firstLayoutCallbackPending = true;
m_lastViewportSize = sizeForResizeEvent();
m_lastZoomFactor = root->style().zoom();
// Set the initial vMode to AlwaysOn if we're auto.
if (vMode == ScrollbarAuto)
setVerticalScrollbarMode(ScrollbarAlwaysOn); // This causes a vertical scrollbar to appear.
// Set the initial hMode to AlwaysOff if we're auto.
if (hMode == ScrollbarAuto)
setHorizontalScrollbarMode(ScrollbarAlwaysOff); // This causes a horizontal scrollbar to disappear.
Page* page = frame().page();
if (page && page->expectsWheelEventTriggers())
scrollAnimator().setWheelEventTestTrigger(page->testTrigger());
setScrollbarModes(hMode, vMode);
setScrollbarsSuppressed(false, true);
} else
setScrollbarModes(hMode, vMode);
}
LayoutSize oldSize = m_size;
m_size = layoutSize();
if (oldSize != m_size) {
LOG(Layout, " layout size changed from %.3fx%.3f to %.3fx%.3f", oldSize.width().toFloat(), oldSize.height().toFloat(), m_size.width().toFloat(), m_size.height().toFloat());
m_needsFullRepaint = true;
if (!m_firstLayout) {
RenderBox* rootRenderer = document.documentElement() ? document.documentElement()->renderBox() : nullptr;
auto* body = document.bodyOrFrameset();
RenderBox* bodyRenderer = rootRenderer && body ? body->renderBox() : nullptr;
if (bodyRenderer && bodyRenderer->stretchesToViewport())
bodyRenderer->setChildNeedsLayout();
else if (rootRenderer && rootRenderer->stretchesToViewport())
rootRenderer->setChildNeedsLayout();
}
}
m_layoutPhase = InPreLayout;
}
layer = root->enclosingLayer();
SubtreeLayoutStateMaintainer subtreeLayoutStateMaintainer(m_layoutRoot);
RenderView::RepaintRegionAccumulator repaintRegionAccumulator(&root->view());
ASSERT(m_layoutPhase == InPreLayout);
m_layoutPhase = InRenderTreeLayout;
forceLayoutParentViewIfNeeded();
ASSERT(m_layoutPhase == InRenderTreeLayout);
#ifndef NDEBUG
RenderTreeNeedsLayoutChecker checker(*root);
#endif
//从 RenderView 这个根级开始进行 layout。
root->layout();
ASSERT(!root->view().renderTreeIsBeingMutatedInternally());
#if ENABLE(TEXT_AUTOSIZING)
if (frame().settings().textAutosizingEnabled() && !root->view().printing()) {
float minimumZoomFontSize = frame().settings().minimumZoomFontSize();
float textAutosizingWidth = frame().page() ? frame().page()->textAutosizingWidth() : 0;
if (int overrideWidth = frame().settings().textAutosizingWindowSizeOverride().width())
textAutosizingWidth = overrideWidth;
LOG(TextAutosizing, "Text Autosizing: minimumZoomFontSize=%.2f textAutosizingWidth=%.2f", minimumZoomFontSize, textAutosizingWidth);
if (minimumZoomFontSize && textAutosizingWidth) {
root->adjustComputedFontSizesOnBlocks(minimumZoomFontSize, textAutosizingWidth);
if (root->needsLayout())
root->layout();
}
}
#endif
ASSERT(m_layoutPhase == InRenderTreeLayout);
m_layoutRoot = nullptr;
// Close block here to end the scope of changeSchedulingEnabled and SubtreeLayoutStateMaintainer.
}
m_layoutPhase = InViewSizeAdjust;
bool neededFullRepaint = m_needsFullRepaint;
if (!subtree && !downcast<RenderView>(*root).printing()) {
adjustViewSize();
// FIXME: Firing media query callbacks synchronously on nested frames could produced a detached FrameView here by
// navigating away from the current document (see webkit.org/b/173329).
if (hasOneRef())
return;
}
m_layoutPhase = InPostLayout;
m_needsFullRepaint = neededFullRepaint;
// Now update the positions of all layers.
if (m_needsFullRepaint)
root->view().repaintRootContents();
root->view().releaseProtectedRenderWidgets();
ASSERT(!root->needsLayout());
layer->updateLayerPositionsAfterLayout(renderView()->layer(), updateLayerPositionFlags(layer, subtree, m_needsFullRepaint));
updateCompositingLayersAfterLayout();
m_layoutPhase = InPostLayerPositionsUpdatedAfterLayout;
m_layoutCount++;
#if PLATFORM(COCOA) || PLATFORM(WIN) || PLATFORM(GTK)
if (AXObjectCache* cache = root->document().existingAXObjectCache())
cache->postNotification(root, AXObjectCache::AXLayoutComplete);
#endif
#if ENABLE(DASHBOARD_SUPPORT)
updateAnnotatedRegions();
#endif
#if ENABLE(IOS_TOUCH_EVENTS)
document.setTouchEventRegionsNeedUpdate();
#endif
updateCanBlitOnScrollRecursively();
handleDeferredScrollUpdateAfterContentSizeChange();
handleDeferredScrollbarsUpdateAfterDirectionChange();
if (document.hasListenerType(Document::OVERFLOWCHANGED_LISTENER))
updateOverflowStatus(layoutWidth() < contentsWidth(), layoutHeight() < contentsHeight());
frame().document()->markers().invalidateRectsForAllMarkers();
if (!m_postLayoutTasksTimer.isActive()) {
if (!m_inSynchronousPostLayout) {
if (inChildFrameLayoutWithFrameFlattening)
updateWidgetPositions();
else {
SetForScope<bool> inSynchronousPostLayoutChange(m_inSynchronousPostLayout, true);
performPostLayoutTasks(); // Calls resumeScheduledEvents().
}
}
if (!m_postLayoutTasksTimer.isActive() && (needsLayout() || m_inSynchronousPostLayout || inChildFrameLayoutWithFrameFlattening)) {
// If we need layout or are already in a synchronous call to postLayoutTasks(),
// defer widget updates and event dispatch until after we return. postLayoutTasks()
// can make us need to update again, and we can get stuck in a nasty cycle unless
// we call it through the timer here.
m_postLayoutTasksTimer.startOneShot(0_s);
}
if (needsLayout())
layout();
}
InspectorInstrumentation::didLayout(cookie, *root);
DebugPageOverlays::didLayout(frame());
--m_nestedLayoutCount;
}RenderView 的 layout 里会调用 layoutContent 方法。这个方法的实现如下:
void RenderView::layoutContent(const LayoutState& state)
{
UNUSED_PARAM(state);
ASSERT(needsLayout());
RenderBlockFlow::layout();
if (hasRenderNamedFlowThreads())
flowThreadController().layoutRenderNamedFlowThreads();
#ifndef NDEBUG
checkLayoutState(state);
#endif
}可以发现这个方法实现很简单,里面主要是通过 RenderBlockFlow 来进行 layout 的。RenderBlockFlow 是 RenderBlock 的子类,layout 方法是在 RenderBlock 里实现,里面直接调了 layoutBlock 方法,这个方法是在 RenderBlockFlow 里重载实现的。下面看看 RenderBlockFlow 的实现吧:
void RenderBlockFlow::layoutBlock(bool relayoutChildren, LayoutUnit pageLogicalHeight)
{
ASSERT(needsLayout());
//当不需要布局子节点同时能 simplifiedLayout 重新布局成功
if (!relayoutChildren && simplifiedLayout())
return;
LayoutRepainter repainter(*this, checkForRepaintDuringLayout());
//重新计算逻辑宽度
if (recomputeLogicalWidthAndColumnWidth())
relayoutChildren = true;
rebuildFloatingObjectSetFromIntrudingFloats();
//先保留一份以前的高度为后面做对比用
LayoutUnit previousHeight = logicalHeight();
// FIXME: should this start out as borderAndPaddingLogicalHeight() + scrollbarLogicalHeight(),
// for consistency with other render classes?
//然后将 logicalHeight 设置为 0,避免累加以前的。
setLogicalHeight(0);
bool pageLogicalHeightChanged = false;
checkForPaginationLogicalHeightChange(relayoutChildren, pageLogicalHeight, pageLogicalHeightChanged);
const RenderStyle& styleToUse = style();
LayoutStateMaintainer statePusher(view(), *this, locationOffset(), hasTransform() || hasReflection() || styleToUse.isFlippedBlocksWritingMode(), pageLogicalHeight, pageLogicalHeightChanged);
preparePaginationBeforeBlockLayout(relayoutChildren);
if (!relayoutChildren)
relayoutChildren = namedFlowFragmentNeedsUpdate();
// We use four values, maxTopPos, maxTopNeg, maxBottomPos, and maxBottomNeg, to track
// our current maximal positive and negative margins. These values are used when we
// are collapsed with adjacent blocks, so for example, if you have block A and B
// collapsing together, then you'd take the maximal positive margin from both A and B
// and subtract it from the maximal negative margin from both A and B to get the
// true collapsed margin. This algorithm is recursive, so when we finish layout()
// our block knows its current maximal positive/negative values.
//
// Start out by setting our margin values to our current margins. Table cells have
// no margins, so we don't fill in the values for table cells.
bool isCell = isTableCell();
if (!isCell) {
initMaxMarginValues();
setHasMarginBeforeQuirk(styleToUse.hasMarginBeforeQuirk());
setHasMarginAfterQuirk(styleToUse.hasMarginAfterQuirk());
setPaginationStrut(0);
}
LayoutUnit repaintLogicalTop = 0;
LayoutUnit repaintLogicalBottom = 0;
LayoutUnit maxFloatLogicalBottom = 0;
if (!firstChild() && !isAnonymousBlock())
setChildrenInline(true);
//Inline 和 Block 的不同布局处理
if (childrenInline())
layoutInlineChildren(relayoutChildren, repaintLogicalTop, repaintLogicalBottom);
else
layoutBlockChildren(relayoutChildren, maxFloatLogicalBottom);
// Expand our intrinsic height to encompass floats.
LayoutUnit toAdd = borderAndPaddingAfter() + scrollbarLogicalHeight();
if (lowestFloatLogicalBottom() > (logicalHeight() - toAdd) && createsNewFormattingContext())
setLogicalHeight(lowestFloatLogicalBottom() + toAdd);
if (relayoutForPagination(statePusher) || relayoutToAvoidWidows(statePusher)) {
ASSERT(!shouldBreakAtLineToAvoidWidow());
return;
}
// Calculate our new height. 计算新高
LayoutUnit oldHeight = logicalHeight();
LayoutUnit oldClientAfterEdge = clientLogicalBottom();
// Before updating the final size of the flow thread make sure a forced break is applied after the content.
// This ensures the size information is correctly computed for the last auto-height region receiving content.
if (is<RenderFlowThread>(*this))
downcast<RenderFlowThread>(*this).applyBreakAfterContent(oldClientAfterEdge);
updateLogicalHeight();
LayoutUnit newHeight = logicalHeight();
if (oldHeight != newHeight) {
if (oldHeight > newHeight && maxFloatLogicalBottom > newHeight && !childrenInline()) {
// One of our children's floats may have become an overhanging float for us. We need to look for it.
for (auto& blockFlow : childrenOfType<RenderBlockFlow>(*this)) {
if (blockFlow.isFloatingOrOutOfFlowPositioned())
continue;
if (blockFlow.lowestFloatLogicalBottom() + blockFlow.logicalTop() > newHeight)
addOverhangingFloats(blockFlow, false);
}
}
}
//前面保留的先前高度和重新计算后的高度比较有变化就重新布局子结点
bool heightChanged = (previousHeight != newHeight);
if (heightChanged)
relayoutChildren = true;
layoutPositionedObjects(relayoutChildren || isDocumentElementRenderer());
//Add overflow from children (unless we're multi-column, since in that case all our child overflow is clipped anyway).
computeOverflow(oldClientAfterEdge);
statePusher.pop();
fitBorderToLinesIfNeeded();
if (view().layoutState()->m_pageLogicalHeight)
setPageLogicalOffset(view().layoutState()->pageLogicalOffset(this, logicalTop()));
updateLayerTransform();
// Update our scroll information if we're overflow:auto/scroll/hidden now that we know if
// we overflow or not.
updateScrollInfoAfterLayout();
// FIXME: This repaint logic should be moved into a separate helper function!
// Repaint with our new bounds if they are different from our old bounds.
bool didFullRepaint = repainter.repaintAfterLayout();
if (!didFullRepaint && repaintLogicalTop != repaintLogicalBottom && (styleToUse.visibility() == VISIBLE || enclosingLayer()->hasVisibleContent())) {
// FIXME: We could tighten up the left and right invalidation points if we let layoutInlineChildren fill them in based off the particular lines
// it had to lay out. We wouldn't need the hasOverflowClip() hack in that case either.
LayoutUnit repaintLogicalLeft = logicalLeftVisualOverflow();
LayoutUnit repaintLogicalRight = logicalRightVisualOverflow();
if (hasOverflowClip()) {
// If we have clipped overflow, we should use layout overflow as well, since visual overflow from lines didn't propagate to our block's overflow.
// Note the old code did this as well but even for overflow:visible. The addition of hasOverflowClip() at least tightens up the hack a bit.
// layoutInlineChildren should be patched to compute the entire repaint rect.
repaintLogicalLeft = std::min(repaintLogicalLeft, logicalLeftLayoutOverflow());
repaintLogicalRight = std::max(repaintLogicalRight, logicalRightLayoutOverflow());
}
LayoutRect repaintRect;
if (isHorizontalWritingMode())
repaintRect = LayoutRect(repaintLogicalLeft, repaintLogicalTop, repaintLogicalRight - repaintLogicalLeft, repaintLogicalBottom - repaintLogicalTop);
else
repaintRect = LayoutRect(repaintLogicalTop, repaintLogicalLeft, repaintLogicalBottom - repaintLogicalTop, repaintLogicalRight - repaintLogicalLeft);
if (hasOverflowClip()) {
// Adjust repaint rect for scroll offset
repaintRect.moveBy(-scrollPosition());
// Don't allow this rect to spill out of our overflow box.
repaintRect.intersect(LayoutRect(LayoutPoint(), size()));
}
// Make sure the rect is still non-empty after intersecting for overflow above
if (!repaintRect.isEmpty()) {
repaintRectangle(repaintRect); // We need to do a partial repaint of our content.
if (hasReflection())
repaintRectangle(reflectedRect(repaintRect));
}
}
clearNeedsLayout();
}以上方法里有两个分支,一个是 layoutInlineChildren 一个是 layoutBlockChildren。由于 Inline 属于动态调整高度所以比 Block 的实现要负责很多,layoutInlineChildren 方式是 Inline 布局的入口。
Parsing 完成会触发 Layout Tree。Layout Tree 的目的就是存储需要绘制的数据,Layout 就是处理 Nodes 在页面上的大小和位置。Chrome,firefox和 android 使用的是Skia 开源 2D 图形库做底层 Paint 引擎。
void Document::finishedParsing() {
updateStyleAndLayoutTree();
}每个 Node 都会创建一个 LayoutObject,
LayoutObject* newLayoutObject = m_node->createLayoutObject(style);
parentLayoutObject->addChild(newLayoutObject, nextLayoutObject);Layout Tree 创建完成就开始计算 layout 的值,比如宽,margin 等。Block 类型节点的位置计算实现是在 RenderBlock 里的 layoutBlockChild 方法里实现的,该方法主要是先确定节点的 top 坐标,然后计算布局变化后 margin,float 和 分页等对 top 值的影响确定影响后的 top 坐标,最后使用 determineLogicalLeftPositionForChild 得到 left 坐标。具体实现如下:
void RenderBlockFlow::layoutBlockChild(RenderBox& child, MarginInfo& marginInfo, LayoutUnit& previousFloatLogicalBottom, LayoutUnit& maxFloatLogicalBottom)
{
LayoutUnit oldPosMarginBefore = maxPositiveMarginBefore();
LayoutUnit oldNegMarginBefore = maxNegativeMarginBefore();
// The child is a normal flow object. Compute the margins we will use for collapsing now.
child.computeAndSetBlockDirectionMargins(*this);
// Try to guess our correct logical top position. In most cases this guess will
// be correct. Only if we're wrong (when we compute the real logical top position)
// will we have to potentially relayout.
LayoutUnit estimateWithoutPagination;
//估算 top 坐标,estimateLogicalTopPosition 会先获取 RenderBlock 的高来作为初始的 top,再根据 margin 分页和 float 来调整 top 坐标
LayoutUnit logicalTopEstimate = estimateLogicalTopPosition(child, marginInfo, estimateWithoutPagination);
// Cache our old rect so that we can dirty the proper repaint rects if the child moves.
LayoutRect oldRect = child.frameRect();
LayoutUnit oldLogicalTop = logicalTopForChild(child);
#if !ASSERT_DISABLED
LayoutSize oldLayoutDelta = view().layoutDelta();
#endif
// Position the child as though it didn't collapse with the top.
//先设置布局前 top 坐标
setLogicalTopForChild(child, logicalTopEstimate, ApplyLayoutDelta);
estimateRegionRangeForBoxChild(child);
RenderBlockFlow* childBlockFlow = is<RenderBlockFlow>(child) ? &downcast<RenderBlockFlow>(child) : nullptr;
bool markDescendantsWithFloats = false;
if (logicalTopEstimate != oldLogicalTop && !child.avoidsFloats() && childBlockFlow && childBlockFlow->containsFloats())
markDescendantsWithFloats = true;
else if (UNLIKELY(logicalTopEstimate.mightBeSaturated()))
// logicalTopEstimate, returned by estimateLogicalTopPosition, might be saturated for
// very large elements. If it does the comparison with oldLogicalTop might yield a
// false negative as adding and removing margins, borders etc from a saturated number
// might yield incorrect results. If this is the case always mark for layout.
markDescendantsWithFloats = true;
else if (!child.avoidsFloats() || child.shrinkToAvoidFloats()) {
// If an element might be affected by the presence of floats, then always mark it for
// layout.
LayoutUnit fb = std::max(previousFloatLogicalBottom, lowestFloatLogicalBottom());
if (fb > logicalTopEstimate)
markDescendantsWithFloats = true;
}
if (childBlockFlow) {
if (markDescendantsWithFloats)
childBlockFlow->markAllDescendantsWithFloatsForLayout();
if (!child.isWritingModeRoot())
previousFloatLogicalBottom = std::max(previousFloatLogicalBottom, oldLogicalTop + childBlockFlow->lowestFloatLogicalBottom());
}
child.markForPaginationRelayoutIfNeeded();
bool childHadLayout = child.everHadLayout();
//对子节点进行布局
bool childNeededLayout = child.needsLayout();
if (childNeededLayout)
child.layout();
// Cache if we are at the top of the block right now.
bool atBeforeSideOfBlock = marginInfo.atBeforeSideOfBlock();
//保证 top 坐标和子节点布局后能够同步
// Now determine the correct ypos based off examination of collapsing margin
// values.
LayoutUnit logicalTopBeforeClear = collapseMargins(child, marginInfo);
// Now check for clear.
LayoutUnit logicalTopAfterClear = clearFloatsIfNeeded(child, marginInfo, oldPosMarginBefore, oldNegMarginBefore, logicalTopBeforeClear);
bool paginated = view().layoutState()->isPaginated();
if (paginated)
logicalTopAfterClear = adjustBlockChildForPagination(logicalTopAfterClear, estimateWithoutPagination, child, atBeforeSideOfBlock && logicalTopBeforeClear == logicalTopAfterClear);
//经过上面的子节点布局完后重新计算得到新高
setLogicalTopForChild(child, logicalTopAfterClear, ApplyLayoutDelta);
// Now we have a final top position. See if it really does end up being different from our estimate.
// clearFloatsIfNeeded can also mark the child as needing a layout even though we didn't move. This happens
// when collapseMargins dynamically adds overhanging floats because of a child with negative margins.
if (logicalTopAfterClear != logicalTopEstimate || child.needsLayout() || (paginated && childBlockFlow && childBlockFlow->shouldBreakAtLineToAvoidWidow())) {
if (child.shrinkToAvoidFloats()) {
// The child's width depends on the line width. When the child shifts to clear an item, its width can
// change (because it has more available line width). So mark the item as dirty.
child.setChildNeedsLayout(MarkOnlyThis);
}
if (childBlockFlow) {
if (!child.avoidsFloats() && childBlockFlow->containsFloats())
childBlockFlow->markAllDescendantsWithFloatsForLayout();
child.markForPaginationRelayoutIfNeeded();
}
}
if (updateRegionRangeForBoxChild(child))
child.setNeedsLayout(MarkOnlyThis);
// In case our guess was wrong, relayout the child.
child.layoutIfNeeded();
// We are no longer at the top of the block if we encounter a non-empty child.
// This has to be done after checking for clear, so that margins can be reset if a clear occurred.
if (marginInfo.atBeforeSideOfBlock() && !child.isSelfCollapsingBlock())
marginInfo.setAtBeforeSideOfBlock(false);
// Now place the child in the correct left position
//计算获得 left 坐标。determineLogicalLeftPositionForChild 会先去计算 border-left 和 padding-left 然后计算 margin-left 来确定 left 坐标。最后通过 setLogicalLeftForChild 将确认的 left 坐标记录下。
determineLogicalLeftPositionForChild(child, ApplyLayoutDelta);
// Update our height now that the child has been placed in the correct position.
setLogicalHeight(logicalHeight() + logicalHeightForChildForFragmentation(child));
if (mustSeparateMarginAfterForChild(child)) {
setLogicalHeight(logicalHeight() + marginAfterForChild(child));
marginInfo.clearMargin();
}
// If the child has overhanging floats that intrude into following siblings (or possibly out
// of this block), then the parent gets notified of the floats now.
if (childBlockFlow && childBlockFlow->containsFloats())
maxFloatLogicalBottom = std::max(maxFloatLogicalBottom, addOverhangingFloats(*childBlockFlow, !childNeededLayout));
LayoutSize childOffset = child.location() - oldRect.location();
if (childOffset.width() || childOffset.height()) {
view().addLayoutDelta(childOffset);
// If the child moved, we have to repaint it as well as any floating/positioned
// descendants. An exception is if we need a layout. In this case, we know we're going to
// repaint ourselves (and the child) anyway.
if (childHadLayout && !selfNeedsLayout() && child.checkForRepaintDuringLayout())
child.repaintDuringLayoutIfMoved(oldRect);
}
//渲染
if (!childHadLayout && child.checkForRepaintDuringLayout()) {
child.repaint();
child.repaintOverhangingFloats(true);
}
if (paginated) {
if (RenderFlowThread* flowThread = flowThreadContainingBlock())
flowThread->flowThreadDescendantBoxLaidOut(&child);
// Check for an after page/column break.
LayoutUnit newHeight = applyAfterBreak(child, logicalHeight(), marginInfo);
if (newHeight != height())
setLogicalHeight(newHeight);
}
ASSERT(view().layoutDeltaMatches(oldLayoutDelta));
}判断值的类型是固定值还是百分比的方法
switch (length.type()) {
case Fixed:
return LayoutUnit(length.value()); //返回 LayoutUnit 封装的数据 1px = 1 << 6 = 64 unit
case Percent:
//maximumValue 是传进来的最大值
return LayoutUnit(
static_cast<float>(maximumValue * length.percent() / 100.0f));
}计算 margin 的值
// CSS 2.1: "If both 'margin-left' and 'margin-right' are 'auto', their used
// values are equal. This horizontally centers the element with respect to
// the edges of the containing block."
const ComputedStyle& containingBlockStyle = containingBlock->styleRef();
if (marginStartLength.isAuto() && marginEndLength.isAuto()) {
LayoutUnit centeredMarginBoxStart = std::max(
LayoutUnit(),
(availableWidth - childWidth) / 2);
marginStart = centeredMarginBoxStart;
marginEnd = availableWidth - childWidth - marginStart;
return;
}Box Model 里
m_frameRect.setWidth(width);
m_marginBox.setStart(marginLeft);经过计算后的 Render Tree 具有布局信息,比如下面的 html 代码:
<html>
<body>
<p>First line.<br>Second one.</p>
</body>
</html>布局计算后带布局信息的 Render Tree 如下:
RenderBlock {HTML} at (0, 0) size 640x480
|—— RenderBody {BODY} at (0, 80) size 640x480 [bgcolor=# FFFFFF]
| |—— RenderBlock {P} at (0, 0) size 640x80
| | |—— RenderText {#text} at (0, 0) size 48x24 "First line."
| | |—— RenderBR {BR} at (20, 20) size 0x0
| | |—— RenderText {#text} at (0, 24) size 48x24 "Second one."
- block:生成一个 block box
- inline:生成一个或多个 inline boxes
- none:不生成 box
默认是 inline 的,但是浏览器会设置其它默认值,比如说 div 就是 block 的,完整的定义可以参看 w3c 定义的:http://www.w3.org/TR/CSS2/sample.html
有三种方案
- Normal:由 render tree 来决定的位置。
- Float:会先按照正常流程来排列,然后再尽可能的往左或往右移动。
- Absolute:让其在 render tree 的位置和 DOM tree 不一样
定位方案是根据 position 属性和 float 属性来决定的,static 和 relative 就是正常的排列, absolute 和 fixed 就是 absolute 定位。
对于 float 的处理,首先需要判断宽度是否需要 fit content
bool LayoutBox::sizesLogicalWidthToFitContent(
const Length& logicalWidth) const {
if (isFloating() || isInlineBlockOrInlineTable())
return true;
...
}如果是 float 或者 inline-block ,宽度靠内容来撑,行内的内容会将间隔控制成一个空格,前后空格和多余空格都会忽略。
对于 float:left 的计算
//logicalRightOffsetForPositioningFloat 剩余空间如果不小于 floatLogicalLeft 时循环结束
while (logicalRightOffsetForPositioningFloat(
logicalTopOffset, logicalRightOffset, &heightRemainingRight) -
floatLogicalLeft <
floatLogicalWidth) {
//下移
logicalTopOffset +=
std::min<LayoutUnit>(heightRemainingLeft, heightRemainingRight);
//新的 floatLogicalLeft
floatLogicalLeft = logicalLeftOffsetForPositioningFloat(
logicalTopOffset, logicalLeftOffset, &heightRemainingLeft);
}
}
//看看 floatLogicalLeft 是否大于 left 的 offset 和 padding left 的差值
floatLogicalLeft = std::max(
logicalLeftOffset - borderAndPaddingLogicalLeft(), floatLogicalLeft);Block box:在浏览器的 window 里有自己的矩形
Inline box:没有自己的 block,但是会在一个 block 里
Block 是按照垂直排列,Inline 是按照水平来排列
Inline boxes 会被包含在 line boxes 里,lines 的高度至少和最高的 box 一样,甚至更高,当 boxes 用的是 baseline,这意味着多个元素底部对齐。如果容器宽度不够,inline 会变成多 lines。
下面举个例子看看 Inline 类型的例子,比如有如下的 html:
<p>First line.<br>Second one.</p>这段 html 的 Render Tree 如下:
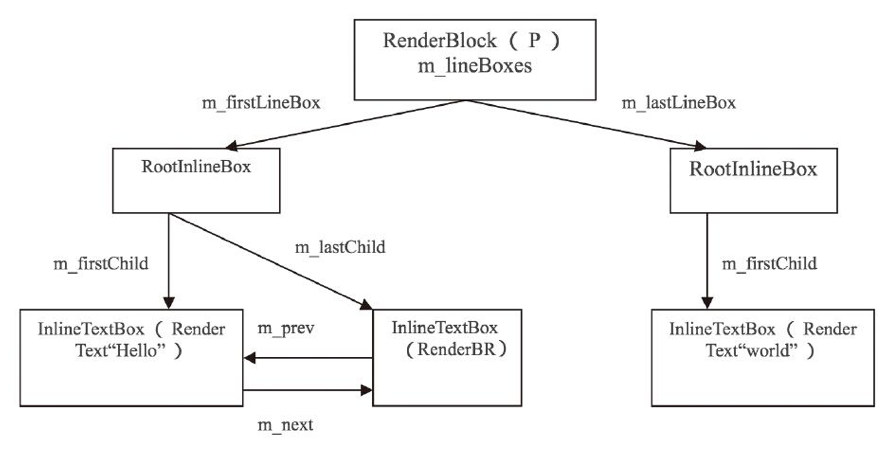
Relative:相对定位,先按照正常的定位然后根据设置的值再移动。
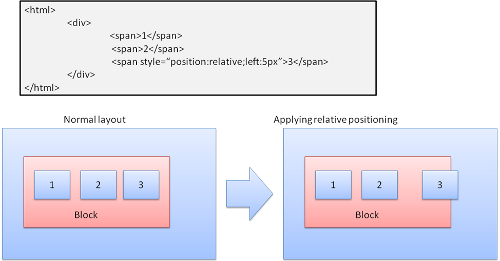
Float:会被移动到左边或右边侧

Absolute 和 fixed:不会参与 normal flow,只按照精确定位,尺寸值相对于容器,对于 fixed 来说,是相对于 view port 的。fixed box 不会随着 document 的滚动而移动。
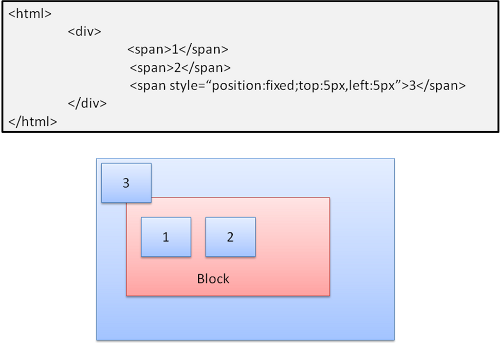
分层可以通过指定 CSS 的 z-index 属性。它表示了 box 的第三个维度,位置按照 z 轴来。这些 box 会被分成 stacks,叫做 stacking contexts,每个栈顶的 box 更靠近用户。stack 根据 z-index 的属性排序。
<STYLE type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</STYLE>
<P>
<DIV style="z-index: 3;background-color:red; width: 1in; height: 1in; "></DIV>
<DIV style="z-index: 1;background-color:green;width: 2in; height: 2in;"></DIV>
</p>效果如下:

可以看到层级是按照 z-index 来排的。
border 及以内区域使用 m_frameRect 对象表示。不同方法通过不同的计算能够获取到不同的值比如 clientWidth 的计算方法是
// More IE extensions. clientWidth and clientHeight represent the interior of
// an object excluding border and scrollbar.
LayoutUnit LayoutBox::clientWidth() const {
return m_frameRect.width() - borderLeft() - borderRight() -
verticalScrollbarWidth();
}offsetWidth 是 frameRect 的宽度
// IE extensions. Used to calculate offsetWidth/Height.
LayoutUnit offsetWidth() const override { return m_frameRect.width(); }
LayoutUnit offsetHeight() const override { return m_frameRect.height(); }Margin 区域是用 LayoutRectOutsets
LayoutUnit m_top;
LayoutUnit m_right;
LayoutUnit m_bottom;
LayoutUnit m_left;位置的计算,即 x 和 y 是通过下面两个函数计算得到
// 根据 margin 得到 y 值
LayoutUnit logicalTopBeforeClear =
collapseMargins(child, layoutInfo, childIsSelfCollapsing,
childDiscardMarginBefore, childDiscardMarginAfter);
// 得到 x 值
determineLogicalLeftPositionForChild(child);计算是个递归过程,由子元素到父元素。这样做的原因是有的父元素的高是由子元素撑起的,需要先知道子元素才能够推出父元素。