doesnt work with AAD #26
Comments
|
@ravikd744 Did you use the release jar on the repo? If so, please redownload the jar - it was just updated. |
|
Hi Rahul, its the same error! :( Would you be able to add a sample notebook into the databricks folder for Azure Single Instance using AAD? thanks! |
|
@ravikd744 can you try also adding the |
|
Hi Arvind, I added the adal4j and restarted the cluster, no difference :(
Should I be adding any specific import statements to make it work? |

|
@cchighman for advice |
|
Hi Everyone, there is a similar issue #28 reported on the old connector. I included the additional jars as suggested in that thread, but to no success. I havent removed the existing mssql jars on the databricks, not sure if this connector requires or uses the mssql-jdbc-6.4.0.jre8.jar
|

|
What version of Spark are you running ? |
|
Also, if you had installed libraries or versions previously on this cluster, I've found its not too resilient by just uninstalling an offending library and reinstalling a different version. I've had the best success spinning up a new cluster and installing the libraries of interest fresh. I suggest giving that a shot, if for anything as a control, to test against the current cluster. |
|
@arvindshmicrosoft |
|
Hi Chris, i am running databricks runtime 6.6 (Spark 2.4.5). Sure, let me try with a new cluster. Do you believe, i should remove the mssql jar and add it again? Does this connector rely on the mssql jar? |
|
I just tried doing pip install adal, and authenticate using a service principal. it works. In addition, it works with no issues for sql auth, i guess because there is no ADAL involved. I have issues only with the Active Directory Password. I saw in some thread, where they suggested it could be related to the logger class referenced in the jar. Does it give a clue? |
|
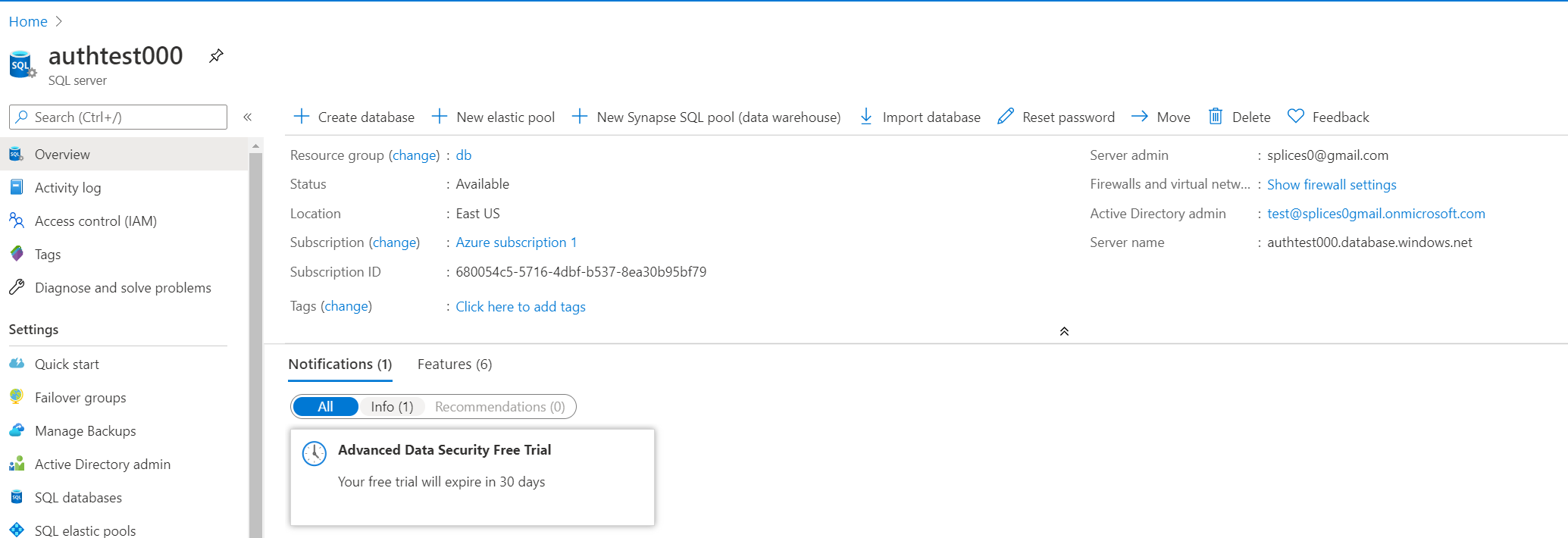
@ravikd744 @shivsood @arvindshmicrosoft @rajmera3 Even when uninstalling, it doesn't necessarily fix itself. Your best bet is to work from a fresh cluster. If after following the steps below you still run into the issue, please post your driver logs and we'll see if we can take a closer look. I created a new Azure AD tenant, removed all security defaults, a new serverless SQL server, and applied the associated Active Directory Admin:
I began with a fresh cluster:
Installed two libraries (not sure about the other two which come by default):
I executed a query in Databricks without any other requirements, except for creating a table.
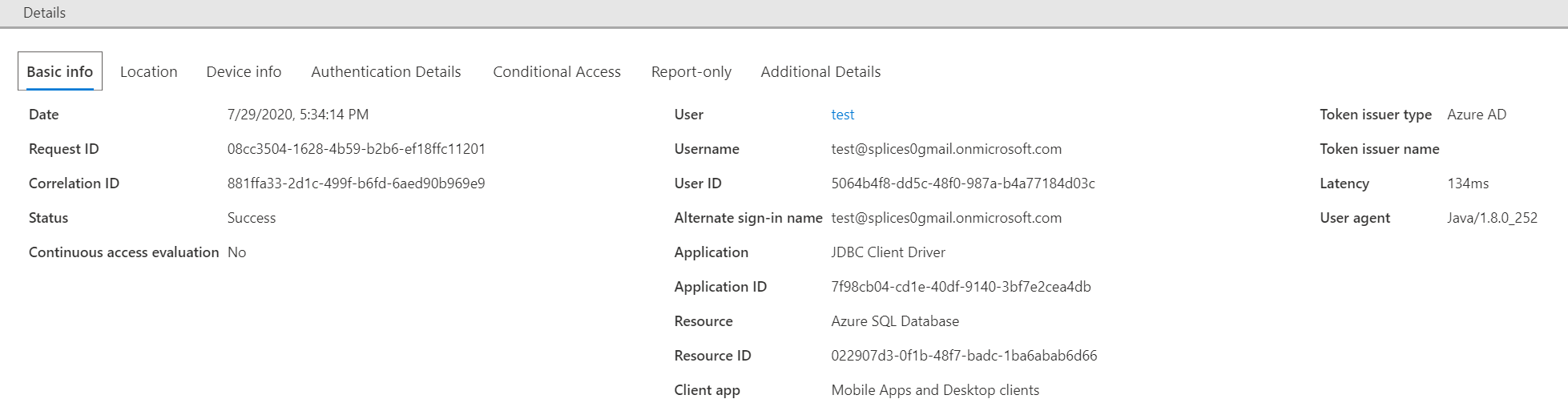
** Afterwards, I'm able to observe the login from Azure AD noting a JDBC driver login **
** The authentication details are CloudOnlyPassword **
|




|
|
@ravikd744 @shivsood @arvindshmicrosoft @rajmera3 This confirms the requirements previously needed from the older Azure SQL connector for AAD auth only apply in that case because it was handling its own connection implementation with the driver directly. Because this connector is pass-thru to Spark, we are now relying on Spark's handling of the mssql JDBC driver versioning, which aligns us nicely since Spark is what is installed onto Databricks. If you are coming from the previous Azure SQL Connector and have manually installed drivers onto that cluster for AAD compatibility, you will definitely need to remove those drivers. After removing those drivers, if you don't have the previous ones to revert to, it may render your cluster somewhat unusable for this purpose. With this new connector, you should be able to simply install and go on a cluster using the default drivers (New or existing cluster that hasn't had its drivers modified) or a cluster which previously used modified drivers for the older Azure SQL connector provided the modified drivers were removed and the previous default drivers restored. We may want to call this out in the README for those migrating. |
|
Hi Chris, I tried the exact steps as you described. unfortunately, its not different. thanks! |
Is the exception returned still "java.lang.NoClassDefFoundError: com/microsoft/aad/adal4j/AuthenticationException" or is it something related to authentication failure? |
|
If its tied to auth failure, getting MFA disabled can be tricky at first. I disabled security defaults, added a one-time bypass, white-listed the cluster IP for skipping MFA requirement, and made sure Azure SQL server settings allowed connections from Azure resources. I also whitelisted the cluster host IP in Azure SQL Server firewall settings. Chances are you dont need to go through nearly this much, it's just not my area of expertise. Going to "Enterprise Applications" in Azure Active Directory and looking at the "Sign-in" attempts should show you failure scenarios that can help guide you towards getting auth working this way if its indeed an auth error at this point. You'll find the request is actually from "Mobile Apps and Desktop Client" as the type from the screenshot I posted above. So, security defaults or conditional access policies may apply. |
|
@ravikd744 Logging into SSMS using Azure Active Directory was my control where if it worked there, it should absolutely work with the JDBC driver via Spark interface. |
|
Hi Chris,
It’s still the same nockassdeffounderror on ADAL4j authentication exception.
My credentials are fine for SSMS and I am an admin on the sql with
appropriate vnet endpoints in place.
Thanks!
On Wed, Jul 29, 2020 at 22:22 Christopher Highman ***@***.***> wrote:
@ravikd744 <https://github.com/ravikd744> Logging into SSMS using Azure
Active Directory was my control where if it worked there, it should
absolutely work with the JDBC driver via Spark interface.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#26 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AG32RL6CL6GFXH3OXLRNGLDR6DKP5ANCNFSM4PJCQMUA>
.
--
Sent from Gmail Mobile
|
|
Just to confirm... 1.) You are installing adal by going to Libraries and choosing "PyPi". 2.) You are installing the SQL Spark Connector by going to Libraries and selecting the JAR from releases. 3.) This is a fresh cluster install. If these are true, please provide the cluster logs for the driver. |
|
Yes both are true.
For 2) I downloaded the jar to my local and uploaded it. If it makes a
difference?
I looked at the cluster logs and there is quite a bit to be redacted. Any
easy way to get the logs secure?
On Thu, Jul 30, 2020 at 07:33 Christopher Highman ***@***.***> wrote:
Just to confirm...
1.) You are installing adal by going to Libraries and choosing "PyPi".
2.) You are installing the SQL Spark Connector by going to Libraries and
selecting the JAR from releases.
3.) This is a fresh cluster install.
If these are true, please provide the cluster logs for the driver.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#26 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AG32RL6THN6PTUIRO23HW4DR6FK6XANCNFSM4PJCQMUA>
.
--
Sent from Gmail Mobile
|
|
This may be safer than pasting your entire logs. I would ideally like the initial startup and error logs if those are clean. At minimum, the below would be helpful under your "Environment" settings. Go to your cluster "Spark Cluster UI - Master"
Click "Databricks Shell" under Application
Click "Environment" Tab
Thanks! |



|
I tried to call the ADAL by passing the id and pwd, to get a token. Does it give a clue? import adal aduser="[email protected]" authority_uri = "https://login.microsoftonline.com/c2e31356-f1e7-439e-a071-6a036aacbd93" context = adal.AuthenticationContext(authority_uri) There is a conditional access policy, that prevents non-interactive login. We need to find a way to support the databricks to pass the logged in user token to this jar. Get Token request returned http error: 400 and server response: {"error":"interaction_required","error_description":"AADSTS53003: Access has been blocked by Conditional Access policies. The access policy does not allow token issuance.\r\nTrace ID: 7c721a5e-a7f9-4d38-bca5-43f9261c3200\r\nCorrelation ID: a7a3cc53-6c74-42a6-8ab3-8ceb51955bf1\r\nTimestamp: 2020-07-30 14:42:55Z","error_codes":[53003],"timestamp":"2020-07-30 14:42:55Z","trace_id":"7c721a5e-a7f9-4d38-bca5-43f9261c3200","correlation_id":"a7a3cc53-6c74-42a6-8ab3-8ceb51955bf1","error_uri":"https://login.microsoftonline.com/error?code=53003","suberror":"message_only","claims":"{\"access_token\":{\"capolids\":{\"essential\":true,\"values\":[\"b9ecb45a-5615-4391-8a51-4a7b1eea66e3\",\"9fda8814-c986-4662-bcf8-348795524012\",\"3632fb92-ec48-421b-a2b0-5bd734944321\",\"f241f958-369d-40ef-bc86-585429f5e5d4\",\"54ad26f7-cd6a-4654-bc80-d71dbb251918\"]}}}"} |
@ravikd744 If you are an Active Directory Admin, I would read the docs on "Conditional Access Policies". Otherwise, I would reach out to whomever supports this for you and request the policy to be adjusted. For ActiveDirectoryPassword auth, if you are still getting NoClassDefFound, I would need the before mentioned items in order to help further. You do have to go a bit out of your way just to get Active Directory to accept password authentication. It may be worth just using a Service Principal. |
|
@ravikd744 I second @cchighman in recommending to stay with Service Principal. Since you had mentioned that SPN / secret authentication worked for you, I think that is the pragmatic way to go. |
|
I agree @cchighman @arvindshmicrosoft , i will continue with service principal as a tactical solution. thank you so much and really appreciate your efforts and time for investigating this long. hopefully, i can help to provide some settings for users with similar conditional access infrastructure. |
|
This issue exists because this package packs in a SQL Server driver, but not ADAL4J. So when the driver jar is loaded and then needs ADAL4J, it expects to find it in the same place, and it fails. There is a simple set of steps to fix this issue if youre stuck on it, but this dependency problem should have a top down fix :) Steps to fix the issue:
connectionProperties = {
"Driver": "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}This works, repeatably. :) |
|
Hi @cchighman, @arvindshmicrosoft , Is it possible to support the Service principal authentication within the spark connector with a new authentication type? The service principal authentication is currently like : We have to install the Python ADAL library and import ADAL modules to generate the access token to append the access token to the connector. It will be cleaner, if the connector takes 3 parameters and use its own MSAL library to get the access token, something like, Any suggestions? thanks! |
Hi, @thereverand I am raising a Microsoft Support Ticket, hopefully they can remove the jdbc driver from the base image used in databricks altogether or they package the ADAL along with the sql driver. But, this would be the regular jdbc driver, not sure if @cchighman plan to package the spark connector to the base image in the future. thanks! |
|
Because the Databricks installation happens to install with a copy of the MS SQL JDBC driver and Spark also natively supports JDBC, we don't have a need to maintain a separate connector which is aware JDBC exists. The previous connector had its own implementation but it was redundant. Everything you specify as an "option" gets passed directly to MSSQL's JDBC driver via Spark. I wasn't able to identify a problem you're running into at the moment, @ravikd744, outside of wondering whether it would be possible to use less options with the query. The documentation on the README does a pretty good job of sharing the pass-thrus to JDBC. In the PR for AAD Support, I also pasted a pretty exhaustive list of items I found as well. If you are still running into a problem getting AAD support to work, please let me know. Christopher |
|
Hi @cchighman , i have an issue unrelated to the connector, my databricks workspace does not have a network route to go out to PyPi repo, so i had to manually download the wheels related to adal and PyJWT used by the adal library. The behavior is inconsistent, sometimes databricks when loading the adal lib, tries to go out to pypi repo to download the PyJWT lib even though the wheel is available in the DBFS along with the adal lib. I was hoping if the adal within the connector reaches out to AAD for the token, then we dont need to get a Py ADAL context and manage the token. I am not sure if i am explaining it correctly. |
|
I am not running on DataBricks but experienced the same issue: In my case it was due to hadoop including a very old version of the mssql driver. To fix it: This is probably the same jar DataBricks includes by default which is why |
|
Solved. See @thereverand and @idc101 answers |
|
@idc101 Can I ask how you are running that rm command? I've got this exactly issue yet I'm not quite sure how to remove the old versions of the mssql driver from the cluster. |
In the case of Azure Databricks, you can use Init Scripts to run this. |
|
@amk-cgill In my case I am running Spark on Kubernetes so in my Dockerfile: However in general you need to find that jar in your spark/hadoop distribution and delete it somehow. As @arvindshmicrosoft says for DataBricks this is best done in an Init Script. |
|
Putting the solution here so nobody else spends half a week of their time trying to fix what is really a lack of documentation on Microsoft's part. High level steps:
A snippet of code to verify with: It's unclear if adding the libraries by hand would fix this, but I somewhat doubt it. |
Trying to use sql spark connector to connect to Azure SQL (single instance) from data bricks runtime (6.6) using Active Directory Password auth. I have uploaded adal library into the cluster.
import adal
dbname = "G_Test"
servername = "jdbc:sqlserver://" + "samplesql.database.windows.net:1433"
database_name = dbname
url = servername + ";" + "database_name=" + dbname + ";"
table_name = "dbo.cap"
aduser="[email protected]"
adpwd="mypwd"
dfCountry = spark.read
.format("com.microsoft.sqlserver.jdbc.spark")
.option("url", url)
.option("dbtable", table_name)
.option("authentication", "ActiveDirectoryPassword")
.option("hostNameInCertificate", "*.database.windows.net")
.option("user", aduser)
.option("password", adpwd)
.option("encrypt", "true").load()
Getting Authentication Exception:
in
17 .option("user", aduser)
18 .option("password", adpwd)
---> 19 .option("encrypt", "true").load()
20
21
/databricks/spark/python/pyspark/sql/readwriter.py in load(self, path, format, schema, **options)
170 return self._df(self._jreader.load(self._spark._sc._jvm.PythonUtils.toSeq(path)))
171 else:
--> 172 return self._df(self._jreader.load())
173
174 @SInCE(1.4)
/databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py in call(self, *args)
1255 answer = self.gateway_client.send_command(command)
1256 return_value = get_return_value(
-> 1257 answer, self.gateway_client, self.target_id, self.name)
1258
1259 for temp_arg in temp_args:
/databricks/spark/python/pyspark/sql/utils.py in deco(*a, **kw)
61 def deco(*a, **kw):
62 try:
---> 63 return f(*a, **kw)
64 except py4j.protocol.Py4JJavaError as e:
65 s = e.java_exception.toString()
/databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name)
326 raise Py4JJavaError(
327 "An error occurred while calling {0}{1}{2}.\n".
--> 328 format(target_id, ".", name), value)
329 else:
330 raise Py4JError(
Py4JJavaError: An error occurred while calling o510.load.
: java.lang.NoClassDefFoundError: com/microsoft/aad/adal4j/AuthenticationException
at com.microsoft.sqlserver.jdbc.SQLServerConnection.getFedAuthToken(SQLServerConnection.java:3609)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.onFedAuthInfo(SQLServerConnection.java:3580)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.processFedAuthInfo(SQLServerConnection.java:3548)
at com.microsoft.sqlserver.jdbc.TDSTokenHandler.onFedAuthInfo(tdsparser.java:261)
at com.microsoft.sqlserver.jdbc.TDSParser.parse(tdsparser.java:103)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.sendLogon(SQLServerConnection.java:4290)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.logon(SQLServerConnection.java:3157)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.access$100(SQLServerConnection.java:82)
at com.microsoft.sqlserver.jdbc.SQLServerConnection$LogonCommand.doExecute(SQLServerConnection.java:3121)
at com.microsoft.sqlserver.jdbc.TDSCommand.execute(IOBuffer.java:7151)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.executeCommand(SQLServerConnection.java:2478)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.connectHelper(SQLServerConnection.java:2026)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.login(SQLServerConnection.java:1687)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.connectInternal(SQLServerConnection.java:1528)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.connect(SQLServerConnection.java:866)
at com.microsoft.sqlserver.jdbc.SQLServerDriver.connect(SQLServerDriver.java:569)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$1.apply(JdbcUtils.scala:64)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$1.apply(JdbcUtils.scala:55)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCRDD$.resolveTable(JDBCRDD.scala:56)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCRelation$.getSchema(JDBCRelation.scala:210)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:35)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:350)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:311)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:297)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:203)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:380)
at py4j.Gateway.invoke(Gateway.java:295)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:251)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.ClassNotFoundException: com.microsoft.aad.adal4j.AuthenticationException
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
... 36 more
The text was updated successfully, but these errors were encountered: