-
Notifications
You must be signed in to change notification settings - Fork 3k
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
[Quant tool] Handle input models with pre-quantized weights (#22633)
### Description Allows the QDQ quantizer to handle input models that already have some pre-quantized weights. In this case, the qdq quantizer will properly skip/handle the pre-quantized weights. Also handles an operator (e.g., Conv) with a pre-quantized weight and a float bias. The tool will read the pre-quantized weight's quantization scale to compute the bias's scale (`bias_scale = input_scale * weight_scale`). Input model (pre-quantized Conv weight): 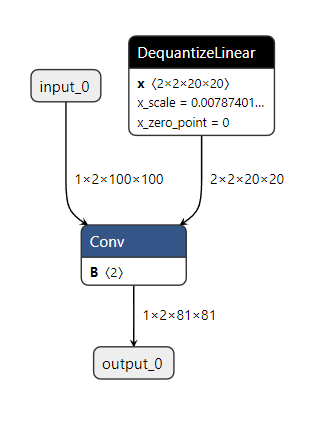 Output QDQ model (everything is quantized):  ### Motivation and Context Customers may use external tools to quantize some weights (e.g., int4 for Conv/MatMul). The qdq quantizer should still be able to quantize the rest of the model (float weights and activations) in this case.
- Loading branch information
1 parent
a3edfbf
commit f4f8eb0
Showing
3 changed files
with
342 additions
and
11 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.