🚨 This repository contains the code for reproducing the main experiments of our work "Federated Online Adaptation for Deep Stereo", CVPR 2024
by Matteo Poggi and Fabio Tosi, University of Bologna

Note: 🚧 Kindly note that this repository is currently in the development phase. We are actively working to add and refine features and documentation. We apologize for any inconvenience caused by incomplete or missing elements and appreciate your patience as we work towards completion.

We introduce a novel approach for adapting deep stereo networks in a collaborative manner. By building over principles of federated learning, we develop a distributed framework allowing for demanding the optimization process to a number of clients deployed in different environments. This makes it possible, for a deep stereo network running on resourced-constrained devices, to capitalize on the adaptation process carried out by other instances of the same architecture, and thus improve its accuracy in challenging environments even when it cannot carry out adaptation on its own. Experimental results show how federated adaptation performs equivalently to on-device adaptation, and even better when dealing with challenging environments.
🖋️ If you find this code useful in your research, please cite:
@inproceedings{Poggi_2024_CVPR,
author = {Poggi, Matteo and Tosi, Fabio},
title = {Federated Online Adaptation for Deep Stereo},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024}
}
We pre-process the different datasets and organize them in .tar archives. For the sake of storage space, left and right images are converted in jpg format.
You have several options for getting the data to run our code.
(Recommended) If you wish to download pre-processed tar archives, drop us an email and we will share access to all pre-processed archives stored in our OneDrive account (unfortunately, we cannot share public links).
As we might need a while to answer, you can pre-process the data on your own (see below).
Most data required for pre-processing is hosted on Google Drive. To download them, please install gdown
pip install gdown==4.7.3
For KITTI sequences, please imagemagick for converting pngs to jpgs, as well as opencv-python
sudo apt install imagemagick
pip install opencv-python==4.8.1
The scripts for preparing data will download several zip files, unpack them and move files all around. It will take "a while", so just go around and let them cook :)
Missing some of the above dependencies will cause the following scripts to fail.
You can download from Google Drive the DSEC sequences used in our experiments with the following script:
bash prepare_data/download_preprocessed_dsec.sh
It will directly store tar archives under sequences/dsec folder (this requires ~14 GB storage).
Other sequences are too large to host on Google Drive, so we provide scripts to download them from the original sources and process them locally (see below).
Run the following script:
bash prepare_data/prepare_drivingstereo.sh > /dev/null
This will download the left, right and groundtruth folders from the DrivingStereo website, as well as our pre-computed proxy labels from Google Drive.
Then, it will prepare tar archives and will store them under sequences/drivingstereo/ folder (this requires >45 GB storage).
Run the following script:
bash prepare_data/prepare_kitti_raw.sh > /dev/null
This will download the left, right and groundtruth depth folders from KITTI website, as well as our pre-computed proxy labels from Google Drive.
Then, it will convert png color images into jpg and groundtruth depth maps into disparity maps, and will prepare tar archives and store them under `sequences/kitti_raw/`` folder (this requires >25 GB storage)
Download pretrained weights by running:
bash prepare_data/download_madnet2_weights.sh
This will store madnet2.tar checkpoint under weights folder.
At now, we do not plan to release the code for pre-training. If you are interested in training MADNet 2 from scratch, you can insert it in RAFT-Stereo pipeline and use the training_loss defined in madnet2.py. Then replace AdamW with Adam and use the learning rate and scheduling detailed in the supplementary material.
Before running experiments with our code, you need to setup a few dependencies and configuration files.
Federated experiments require up to 4 GPUs (one per client), while one GPU is sufficient for single-domain experiments.
Our code has been tested with CUDA drivers 470.239.06, torch==1.12.1+cu113, torchvision==0.13.1+cu113, opt_einsum==3.3.0, opencv-python==4.8.1, numpy==1.21.6 and webdataset==0.2.60.
Clients and Server's behaviors are defined in .ini config files.
Please refer to cfg/README.md for detailed instructions
python run.py --nodelist cfgs/multiple_clients.ini --server cfgs/server.ini
Arguments:
--nodelist: list of config files for client(s) running during the experiments
--server: config file for the server to be used in federated experiments
--verbose: prints stats for any client running (if disabled, only the listening client will print stats)
--seed: RNG seed
Please note that the performance of federated adaptation may change from run to run and depends on your hardware (e.g., after refactoring, we tested the code on a different machine and bad3 in most cases improved by 0.10-0.20% roughly)
To run a single client:
python run.py --nodelist cfgs/single_client.ini
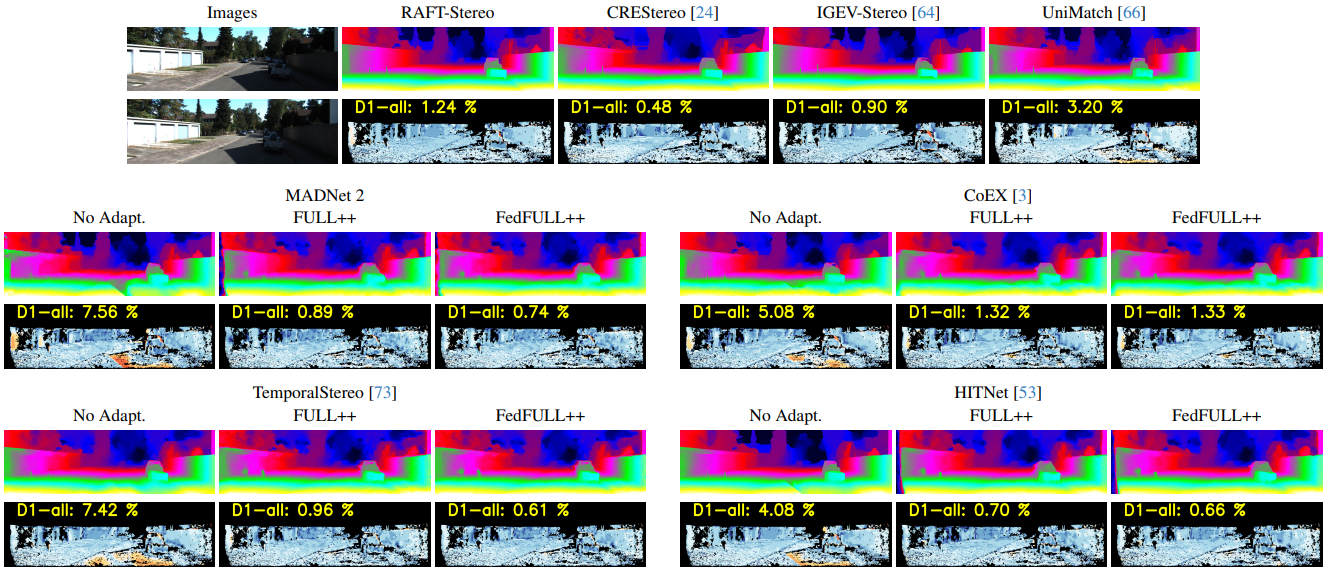
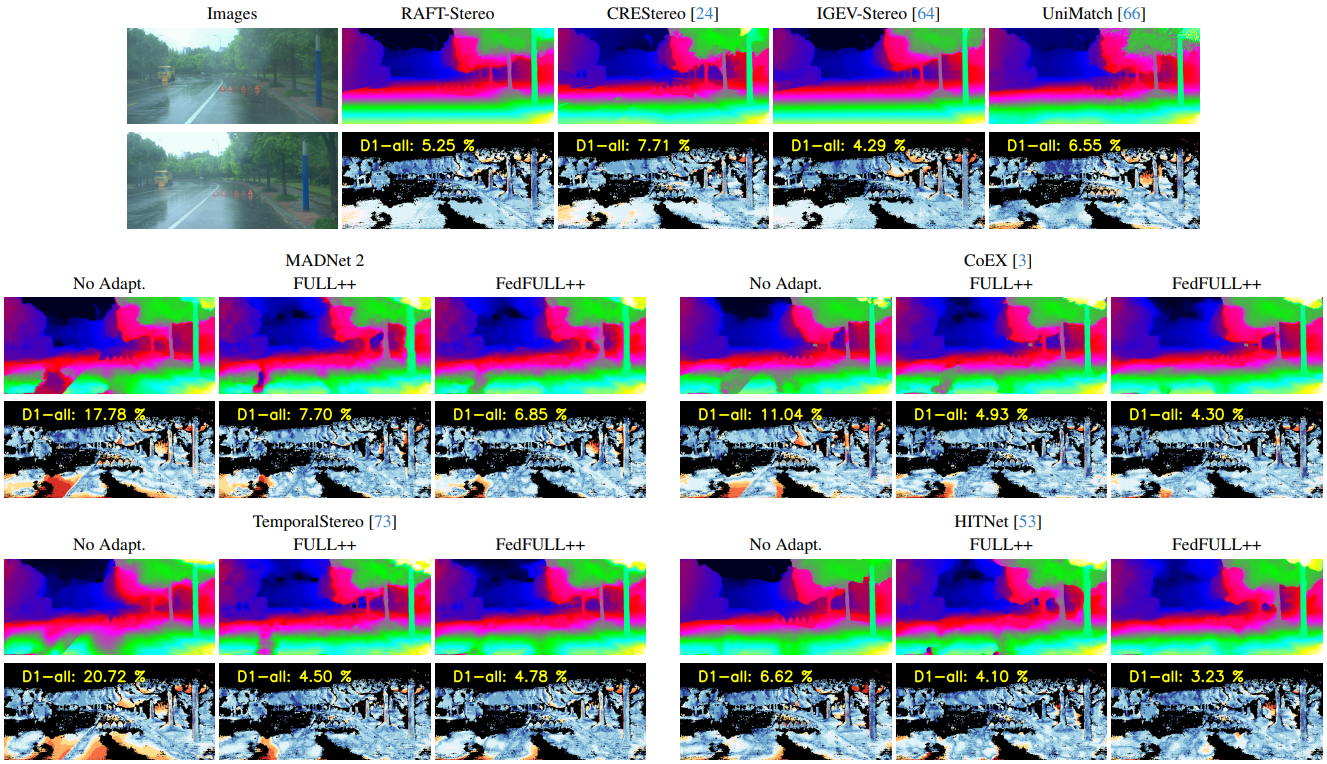
In this section, we present illustrative examples that demonstrate the effectiveness of our proposal.
KITTI - Residential sequence
DrivingStereo - Rainy sequence
DSEC - Night#4 sequence

For questions, please send an email to [email protected] or [email protected]
We would like to extend our sincere appreciation to the authors of the following projects for making their code available, which we have utilized in our work:
- We would like to thank the authors of RAFT-Stereo, CREStereo-PyTorch, IGEV-Stereo, UniMatch, CoEX, PyTorch-HITNet and TemporalStereo for providing their code, which has been instrumental in our experiments.